使用机器学习和 Python 进行气候时间序列聚类
以下是如何使用机器学习用几行代码对未标记的时间序列进行分类。

第一节机器学习课程以这样的方式开始:
机器学习场景中有两种任务:分类和回归。
假设你有一张图片,在数学上它只是一个矩阵,你想知道它是猫还是狗的图片。这是一个分类问题,因为您当然是在对输入对象进行分类。
另一方面,给定一个输入对象,您可能希望获得一个实数值。例如,给定房屋的某些特征,您可能想猜测它的价格。
这是一个非常简单的介绍,它对于理解机器学习的内容是有效且富有洞察力的。隐藏的是,当我们考虑所谓的监督机器学习时,这种区别是真实的。
尽管如此,机器学习算法的一个可能不太出名的应用是无监督的,而未标记数据的相应分类操作称为聚类。
给定一个特定的对象,您想对其进行分类,而不知道它可能有什么标签。让我们更清楚一点。
想象一下,你是一个外星人,你在一家杂货店。
即使你是外星人(我不知道这是不是真的 :))你可能会认识到剃须刀片与苹果不同。这意味着即使您对对象的标签一无所知,您也在“分类”对象。
这就是聚类的意义所在。
现在,我们有多种机器学习算法来做聚类工作。最著名的是称为 K 均值。让我们看一下。[0]
1. K-Means Algorithm
好的,首先我要说的是,有些人对K Means的解释非常好,非常详细,这不是我在这篇博文中打算做的。尽管如此,让我了解一下 K 均值算法的步骤。
看下面的GIF:

想象一下,正如我们所说,我们一开始没有任何标签。所以我们只有 N 个数据点。每个数据点由两个值组成:x 和 y。
现在(第一步)我们在这个二维空间内随机定义三个(通常为 k)点。我们称这 k 个数据点为“质心”。
第二步是根据数据点与三个(通常为 k)质心之间的距离对每个数据点进行“分类”。假设这个新点 x,我们有三个质心之间的三个距离值。我们将此距离值称为 d_1、d_2 和 d_3。我们根据 d_1、d_2 和 d_3 的 argmin 将该点分类为 1、2 或 3。例如,如果 d_1
我们要做的下一件事(第三步)是通过考虑分类为 1、2 或 3 的所有点的平均值来更新该质心的值。
第四步是回到第二步进行 L 次,其中 L 是迭代次数。
2. Time Series Clustering
当然,K 均值算法也可以应用于时间序列。我们唯一需要考虑的是数据集的维度是 M,其中 M 是时间序列的长度。无论如何,我们可以做得更好。 :)
首先,Python 中有一个名为 tslearn 的库。他们所做的是将预处理步骤应用于时间序列并将众所周知的算法应用于时间序列。该算法之一是我们目前讨论的聚类算法。[0]
为什么我们不能只应用 K 均值?有一个问题。如果两个时间序列相同,但其中一个偏移了一个单位,即使两个时间序列之间的差异基本为 0,使用均方误差或平均绝对误差等传统方法计算的距离仍然很大。
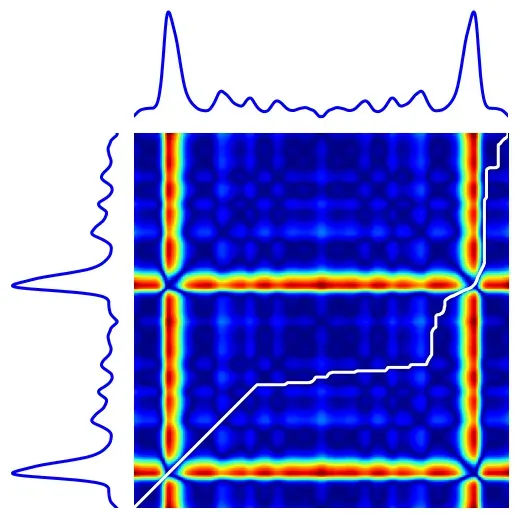
我们不想以传统方式计算距离,而是要计算“最短路径”并将其称为两个时间序列之间的距离。
此操作称为距离时间扭曲,可以在下图或此处的 tslearn 文档中找到其工作原理的实际演示:[0][1]
3. 气候时间序列聚类
在这篇博文中,我们将使用上面解释过的距离时间扭曲算法来使用气候时间序列聚类。特别是,我们将获得世界上一些主要城市的平均温度。我们希望对所有时间序列(2012-2017)具有相似天气的城市进行聚类。
数据集可以在这里找到。可以免费下载它并将其用于商业目的(更多信息在这里)。[0][1]
让我们开始玩吧!
3.0 Import Libraries
3.1 Data Pre Processing
让我们导入数据集并看看:
让我们绘制一个时间序列:
对于我们使用的算法来说,时间序列当然太混乱了:它需要很长时间。为了我们的目的,让我们对数据集进行欠采样:
非常好,一切准备就绪:)
3.2 Clustering
现在,预处理可能有点冗长乏味,但与往常一样,应用模型需要两行代码。
Here it is:
我们决定使用 k=3。
让我们将拟合模型应用于我们的数据集:
让我们定义我们的时间步长数组:
伟大的。让我们绘制结果:
这实际上是信息:
- 第一类的范围很广,但似乎总是小于或等于 310。通常,最低值似乎在 260 左右(250 左右的值似乎是异常值)。
- 第二类的范围更短,但值明显更大:较低和较大的值都大于第一类的对应值
- 第三类恰好与第一类相似,但我们在高温下的值比在低温下的值更多。
我同意这些结论可能不是很明显。其实我作弊了一点:)。在查看三个类的直方图后,我找到了这些解释:
为什么我们说这是信息丰富且不明显?嗯,因为这些城市在趋势和范围方面似乎相似,但在位置方面并不是很接近。
另一方面,如果您只是在位置上执行 K 均值(像这样):
然后我们看到对应的直方图:
这没有多大意义吧?
这是因为,就位置而言,可以以某种方式“聚集”在一起的城市不一定在气候方面具有相同的行为。我们都知道气候比这复杂得多。
6. Conclusions
如果你喜欢这篇文章并且想了解更多关于机器学习的信息,或者你只是想问我一些问题,你可以:
A. 在 Linkedin 上关注我,我在这里发布我所有的故事
B. 订阅我的时事通讯。它将让您随时了解新故事,并让您有机会给我发短信以接收您可能有的所有更正或疑问。
C. 成为推荐会员,因此您不会有任何“本月的最大故事数”,并且您可以阅读我(以及数以千计的其他机器学习和数据科学顶级作家)撰写的有关最新可用技术的任何内容。[0][1][2]
文章出处登录后可见!