使用线性回归了解因果推理中的偏差和方差
讨论遗漏变量、混杂变量、不相关变量和多重共线性
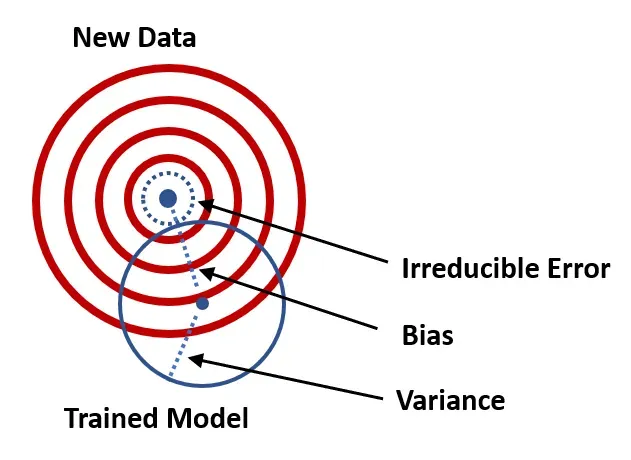
在我之前的文章因果推理:计量经济学模型与 A/B 测试中,我们讨论了如何使用计量经济学模型,即线性回归来研究处理变量和响应变量之间的因果关系,同时控制其他协变量。在本文中,我们将讨论设计线性回归时的一些常见问题——省略重要变量并包括不相关变量。[0]
在讨论这些问题之前,我们需要熟悉系数估计的偏差和方差。
- 偏差测量拟合值与估计值的真实值之间的差异。如果线性回归的治疗效果有偏差,这意味着我们的因果效应不准确。
- 方差衡量估计值(它们是随机变量)围绕其期望值的分布。方差越大,估计的精度越低。
Omitting Important Variables
我们都应该知道,我们不应该忽略线性回归中的重要变量。这种行为的后果将使模型无法正确解释响应变量(也称为欠拟合),并可能做出错误的因果推理陈述。
让我们更深入地研究一下它会对我们的模型造成多大的损害。
最简单的线性回归如下所示。响应变量(即 Y)可以解释为解释变量(例如,截距、X1、X2、X3、…)的线性组合,而 ε 是表示拟合响应值与实际响应值之间差异的误差项响应值。误差项的正态性假设对于线性回归模型是可选的,但建议用于因果推理任务。[0]

根据您希望如何设置成本函数,我们可以通过普通最小二乘法 (OLS) 或最大似然估计 (MLE) 来驱动封闭形式的解决方案。[0]
接下来,让我们重写图 1 中的等式,将解释变量分解为模型中的处理变量(即 T)和其他解释变量(即 X),以便更容易调查忽略重要变量会造成多大的损害处理变量的系数估计量(即α)。
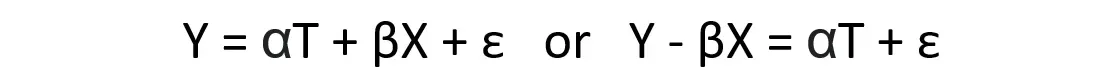
从图 3 和图 2 中的第二个方程,我们可以将“α_hat”的拟合值表示如下,
假设我们发现图 3 的线性回归模型中省略了一个重要变量(即 Z)。正确的模型应该是
其中 γ 是省略变量 Z 的系数。
为了调查我们将图 4 中的处理变量的系数估计搞砸的严重程度,我们将图 4 中的 Y 替换为图 5 中的正确模型。现在我们有
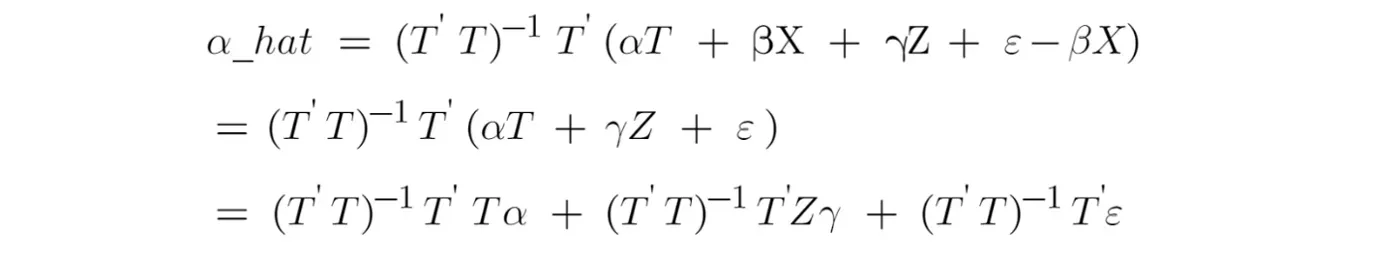
图 6 中的第一项可以简化为 α,因为
图 6 中的第三项应该等于 0,因为在我们建立线性模型时,假设误差项应该与解释变量无关。此外,第三项的期望值也将为 0,因为假设误差项的期望值也为 0。
因此,图 6 中的方程可以简化为:
情景 1:遗漏变量 Z 与处理变量 T 相关。我们称这种变量为混杂变量,因为它们与响应变量和处理变量都相关。
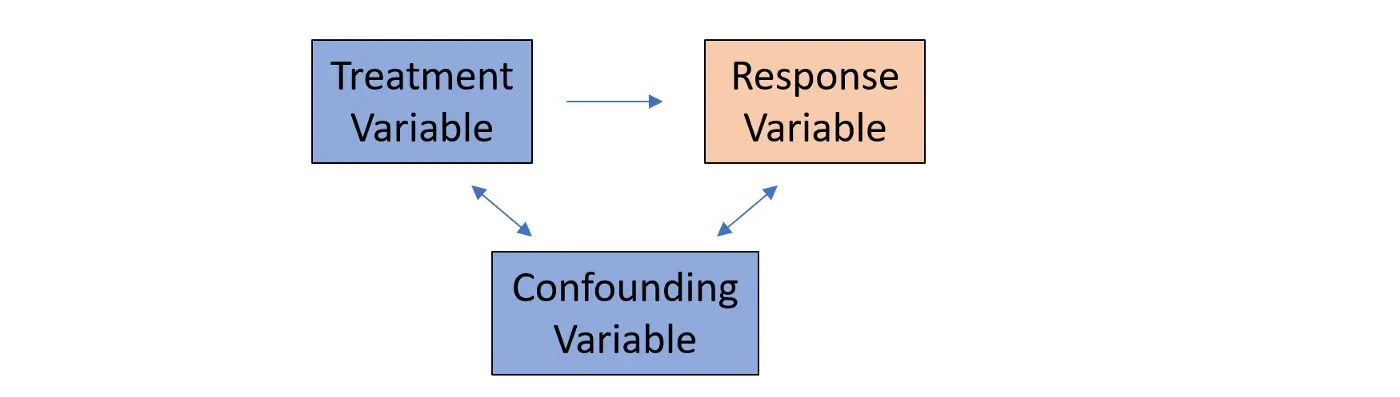
当遗漏变量 Z 与处理变量 T 相关并且可以有意义地解释响应变量时,则图 8 中的第二项不再为 0。因此,处理效果的 OLS 估计量不再是无偏的,我们可能会使如果省略变量 Z,则错误的因果推理陈述。
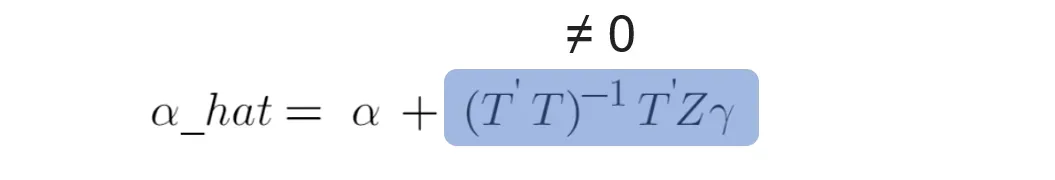
如果线性回归模型中省略了混杂变量 Z,则处理变量将成为内生变量,因为“无法解释的”变量 Z 泄漏到误差项中,则处理变量将与误差项相关。在这种情况下,处理变量的估计值会出现偏差(即内生性偏差)。
场景 2:遗漏变量 Z 与处理变量 T 不相关。
当遗漏变量与回归模型中的处理变量不相关时,图 8 中的第二项将为 0。因此,处理效果的 OLS 估计量继续无偏。
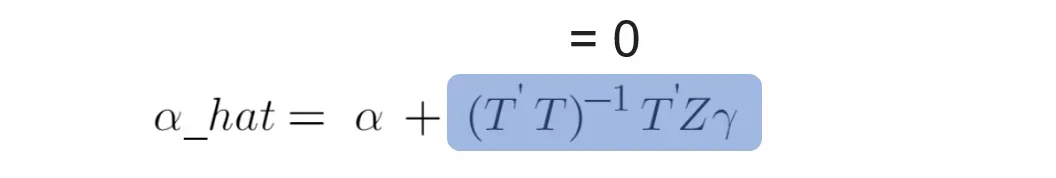
但是,如果忽略这些变量,仍然要付出代价。即使遗漏变量 Z 与处理变量 T 不相关,变量 Z 仍然起到解释响应变量的作用,排除变量 Z 会将这个“无法解释”的部分归入误差项 ε 中,并使误差的方差变大。因此,所有估计量(包括治疗效果)的方差会更大(见图 12)。
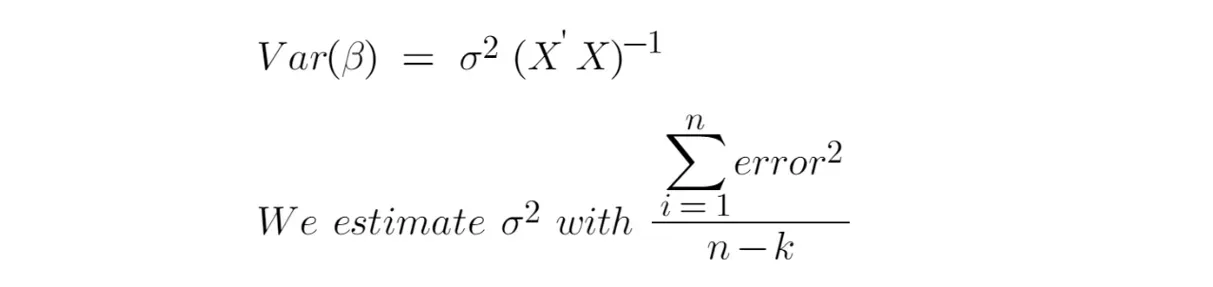
换句话说,如果遗漏变量与处理变量不相关,虽然处理效果仍然是无偏的,但处理效果的方差会变大,假设检验的t值会变小,那么p值会是因此,我们可能会错误地得出结论,认为治疗效果在统计上不显着(即假阴性)。
Including Irrelevant Variables
似乎可以通过将所有相关变量包含在线性回归模型中来轻松解决遗漏变量的问题。但是在模型中包含不相关的变量可能会导致其他问题。
从 Jeffrey Wooldridge 的教科书《计量经济学导论》中,在 Gauss-Markov 假设下,以自变量的样本值为条件,我们可以将方差公式(图 12)改写如下:
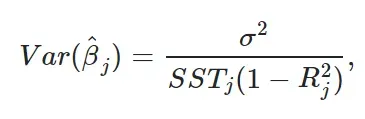
其中j代表一个具体的解释变量j。 SST_j 是解释变量 j 的总样本变异,
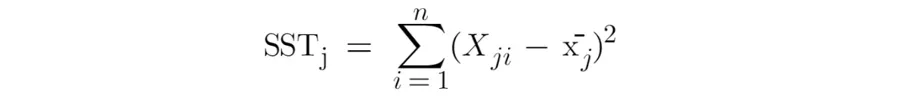
R2_j 是预测变量 j 在剩余预测变量上回归的决定系数,其中预测变量 j 在左侧,所有其他预测变量在右侧。
以下术语称为方差膨胀因子(VIF)。它是分析线性回归模型中多重共线性程度的有用工具,其中预测变量相互关联。
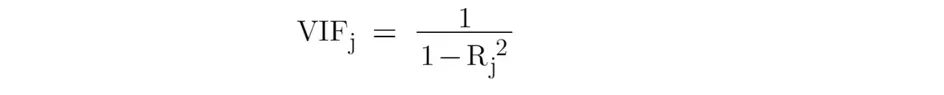
- 当预测变量 j 与其他预测变量不相关时,VIF_j 等于 1。
- 当预测变量 j 可以被其他预测变量解释时,VIF_j 将大于 1。
- 经验法则是,如果 VIF_j 大于 10,则多重共线性很高。
现在让我们考虑以下场景:
场景1:从上一节(图8)中,我们知道如果一个变量与治疗变量高度相关,在线性回归模型中包含这样一个变量很可能会掩盖治疗变量的真实因果效应(即,高偏差)。很明显,我们需要排除这样一个变量。
情景 2:如果一个变量与治疗变量不相关,但与其他解释变量高度相关(即多重共线性)。那么包括这种变量不会增加治疗效果的偏差和方差(见图8和13)。但是,当变量不解释响应变量的变化时(即变量不减少分子,而是减少图 13 中的分母),它会增加其他解释变量的偏差和方差。这是最坏的多重共线性)。在这种情况下,我们将排除这样一个变量。
场景 3:这个场景类似于场景 2,除了这个变量也解释了响应变量的变化。在这种情况下,如果我们更关心遗漏变量的问题而不是多重共线性,那么我们可以将其保留在模型中并忍受多重共线性。我们可能有更大或更小的标准误差(参见图 13,虽然分母随着这个添加的变量变小,但如果添加的变量也有助于解释响应变量,分子也可能变得更小)。在这种情况下,我们需要考虑增加的解释力和多重共线性之间的权衡。
场景 4:如果变量与解释变量和响应变量均不相关,则添加或省略它们应该很重要(就偏差和方差而言)。但是,如果将大量此类变量添加到模型中,它将开始降低模型中的自由度,然后增加估计的方差(参见图 12)。
Final Notes
总之,如果一个遗漏变量或一个不相关变量与治疗变量相关,那么治疗效果就会出现偏差。包括与现有预测变量相关的不相关变量将增加估计的方差,并使估计和预测不那么精确。
还有很多东西要讨论,比如正则化背景下偏差和方差之间的权衡。这将是另一篇文章的主题。敬请关注!
感谢您的阅读!
您可以注册成为会员以解锁对我的文章的完全访问权限,并且可以无限制地访问 Medium 上的所有内容。如果您想在我发布新文章时收到电子邮件通知,请订阅。[0][1]
文章出处登录后可见!