总体印象:cut和qcut都是用来对数据进行简单的分箱处理,
其不同之处在于
(1) qcut是一个
等频分箱,按照分位数进行分箱,每个箱体里面的
样本量相同,输入的是待切分数据和箱体的个数;而cut是一个等距分箱或者非等距分箱,其输入参数为
bins,描述切分箱体的边界。
1. cut
- 用处
分箱函数,可以指定分箱的边界,因此每个箱体里面的样本量不一定相等 - 输入参数
(1) 待切分的数据
(2) 划分的分箱边界bins=
(3) labels 指定箱子的标签
(4) ordered=True,对label是否有序进行设定,默认是True。当label存在重复值时,必须设定ordered=False
pd.cut(np.array([1, 7, 5, 4, 6, 3]), 3,labels=["B", "A",'C'])
返回
['B', 'C', 'A', 'A', 'C', 'B']
Categories (3, object): ['B' < 'A' < 'C'] 这里有小于符号,表明顺序
- 输出
- out
返回类型(Categorical或Series)取决于输入:如果输入是Series,则为category类型的Series,否则为Categorical类型的Series。当类别数据返回时,容器被表示为类别。
- out
p[1,2,3,4,5,7,11,13,24,35,46,67,65,54,87,111,22,34,32,33,4,4,555,3,4,345,567,432,321,123,342,34,57,89,98,76,54,99]
_,bins=pd.qcut(p,q=4,duplicates='drop',retbins=True)
#按列表来分箱,返回的就是数组
pd.cut(p,bins)
返回
[NaN, (1.0, 8.0], (1.0, 8.0], (1.0, 8.0], (1.0, 8.0], ..., (40.5, 95.75], (95.75, 567.0], (40.5, 95.75], (40.5, 95.75], (95.75, 567.0]]
Length: 38
Categories (4, interval[float64, right]): [(1.0, 8.0] < (8.0, 40.5] < (40.5, 95.75] < (95.75, 567.0]]
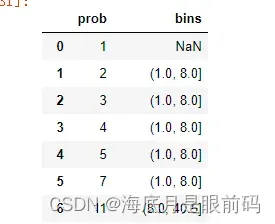
#数据框中的某一列来分箱,返回的就是数据框中的某一列
table=pd.DataFrame()
table['prob']=p
table['bins']=pd.cut(table['prob'],bins)
table
返回
- bins
当retbins为True时,显示箱体 因此当retbins=True时,返回的是两个变量,对于不同的变量采取不同的操作方法
(1) 第一个变量为每个值所属的类别,即所属哪一类区间,采用的方法可以是计算区间里面的个数,即value_counts()
(2) 第二个变量可以直接实例化输出,以数组的形式显示出来
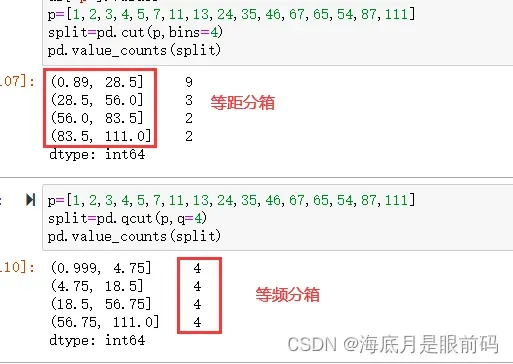
p=[1,2,3,4,5,7,11,13,24,35,46,67,65,54,87,111]
split,bins=pd.cut(p,bins=4,retbins=True)
pd.value_counts(split)
返回
(0.89, 28.5] 9
(28.5, 56.0] 3
(56.0, 83.5] 2
(83.5, 111.0] 2
dtype: int64
_,q=pd.qcut(p,q=4,duplicates='drop',retbins=True)
q
返回
array([ 1. , 4.75, 18.5 , 56.75, 111. ])
2. qcut
- 用处:
根据秩或样本分位数将变量离散到大小相等的桶中,所谓大小相等指的是样本量相同,因为这是位数分箱函数。例如,10分位数对应1000个值生成一个category对象,指示每个数据点的分位数成员 - 输入参数
(1) 切分列表数据
(2)q=分位数的表示,整数(10——十分位数)小数(0.25——四分位数)
(3)duplicates='raise'/'drop'如果bin的边不唯一,抛出ValueError或删除非唯一的边。
(4)retbins=True是否返回(bins,label)。如果容器是作为标量给出的,则会很有用。 - 返回值
与cut的类似
p=[1,2,3,4,5,7,11,13,24,35,46,67,65,54,87,111]
_,q=pd.qcut(p,q=10,duplicates='drop',retbins=True)
则返回array([ 1. , 2.5, 4. , 6. , 11. , 18.5, 35. , 50. , 65. ,
77. , 111. ])
文章出处登录后可见!
已经登录?立即刷新