文章目录
-
- 1. 快速上手
-
- 1.1 注册账号
- 1.2 搭建环境
- 1.3 快速代码示例
- 2. Embedding——案例:解决情感分析问题(Zero-Shot)
-
- 2.1 定义
- 2.2 传统的二分类方法:朴素贝叶斯
- 2.2 传统方法的挑战:特征工程与模型调参
-
- 2.2.1 特征工程
- 2.2.2 模型调参
- 2.3 大语言模型特征工程解决方案
- 2.4 大数据集上案例
-
- 2.4.1 案例1
- 2.4.2 案例2
- 2.4.3 总结
- 3. Completion——案例:客服、聊天机器人、情感分析问题(Few-Shots)
-
- 3.1 AI客服
- 3.2 聊天机器人
- 3.3 情感分析问题
- 3.4 Embedding案例改造
-
- 3.4.1 案例1
- 3.4.2 案例2
- 4. 模型比较
-
- 4.1 预训练模型
- 4.2 Fasttext、T5模型效果
-
- 4.2.1 Fasttext 效果测试
- 4.2.2 T5 效果测试
- 5. Embedding进阶——案例:文本分类问题
-
- 5.1 数据处理
-
- 5.1.1 加载数据
- 5.1.2 获取Embedding
- 5.2 训练模型
- 5.3 相关指标说明
- 5.4 练习:Amazon食物评论数据评分分类
- 6. Completion进阶(ChatCompletion)——案例:聊天机器人
-
- 6.1 对话补全接口——ChatCompletion
- 6.2 应用实例:聊天机器人
-
- 6.2.1 封装代码
- 6.2.2 聊天机器人的成本
-
- 6.2.2.1 通过 API 计算 Token 数量
- 6.2.2.1 通过 Tiktoken 库计算 Token 数量
- 6.2.3 搭建界面(Gradio)
- 6.2.4 部署发布(HuggingFace)
- 6.2.5 练习:限制 Token 数量
- 7. Embedding 与 Completion 结合——案例:文本聚类与摘要
-
- 7.1 基于 Embedding 向量进行文本聚类
- 7.2 使用 Prompt 对文本进行总结
- 7.3 扩展:利用文本摘要支持无限轮数的聊天
- 8. 其余接口与模型——案例:文本改写和内容审核
-
- 8.1 文本改写
-
- 8.1.1 选用适当提示语
- 8.1.2 精确控制生成内容(logit_bias 参数)
- 8.1.3 使用英文减少 Token 的使用
- 8.1.4 练习:文本改写应用
- 8.2 OpenAI 模型
-
- 8.2.1 模型介绍
- 8.2.2 特殊模型 gpt-3.5-turbo-instruct ——插入文本内容
- 8.3 Moderate 接口——内容审核
这里的笔记均来自于极客时间的《AI大模型之美》课程,原课程中的代码大部分已无法正常运行并且已过时,这里我对其中的内容和代码进行了总结和优化,如果对原专栏感兴趣的朋友可以直接去相关专栏中学习:地址
1. 快速上手
1.1 注册账号
使用OpenAI需要注册一个OpenAI的账号,但目前OpenAI还未向中国开放,使用境内的邮箱和支付方式均无法成功注册账号,可以在网上搜索下相关途径或者在万能的淘宝看一下。
账号注册完成后,可以通过 API key page 页面进入管理API Keys页面。
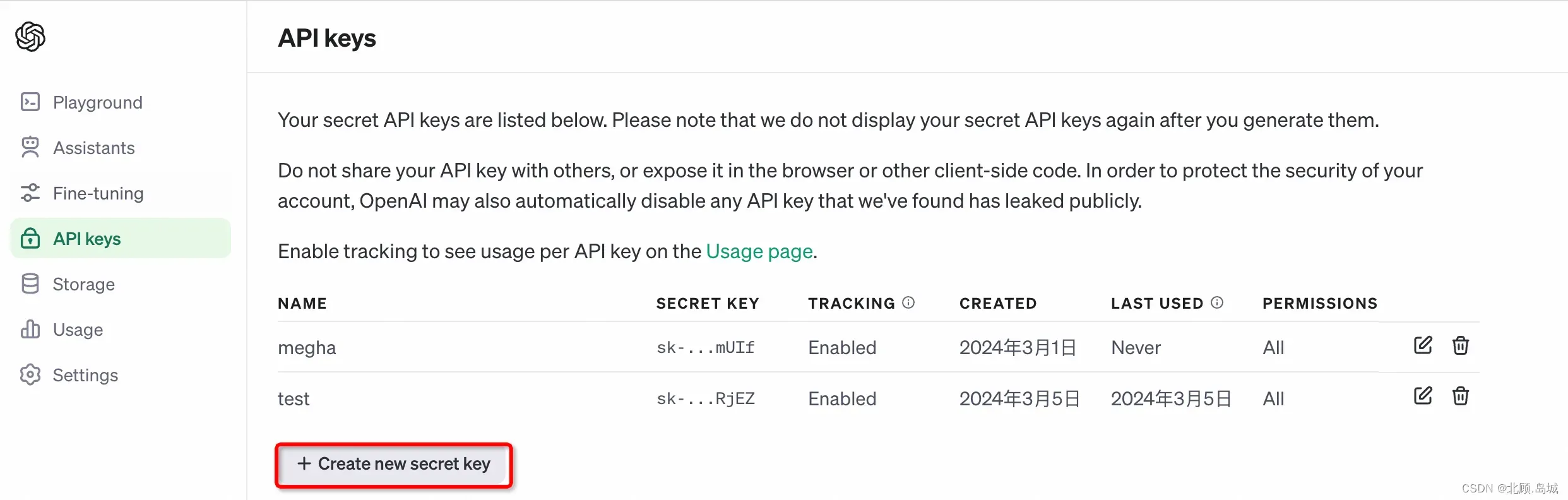
点击下面的 “+Create new secret key” 可以创建一个新的API Key。生成的Secret key需要保存在一个安全的地方,后续调用OpenAI的接口都需要使用这个Key。
1.2 搭建环境
环境可以直接使用Google免费提供的Colab环境:地址
Colab已经是一个Python Notebook的环境,不过还是需要安装OpenAI的库,以及设定我们申请的API Key。只需要在Notebook开始部分,执行下面的代码即可:
!pip install openai
%env OPENAI_API_KEY=[申请的API Key]
1.3 快速代码示例
(1)例子1:生成商品信息
下面代码调用了OpenAI的Completion接口为一个在1688上找到的中文商品名称做三件事情:
- 为这个商品写一个适合在亚马逊上使用的英文标题。
- 给这个商品写5个卖点。
- 估计一下,这个商品在美国卖多少钱比较合适。
同时,我们希望返回的结果是JSON格式的,并且上面的三个事情用title、selling_points 和 price_range 三个字段返回。
from openai import OpenAI
import os
client = OpenAI(
# This is the default and can be omitted
api_key=os.environ["OPENAI_API_KEY"],
)
COMPLETION_MODEL = "gpt-3.5-turbo-instruct"
prompt = """
Consideration product : 工厂现货PVC充气青蛙夜市地摊热卖充气玩具发光蛙儿童水上玩具
1. Compose human readable product title used on Amazon in english within 20 words.
2. Write 5 selling points for the products in Amazon.
3. Evaluate a price range for this product in U.S.
Output the result in json format with three properties called title, selling_points and price_range
"""
def get_response(prompt):
completions = client.completions.create(
model=COMPLETION_MODEL,
prompt=prompt,
max_tokens=512,
n=1,
stop=None,
temperature=0.0,
)
message = completions.choices[0].text
return message
print(get_response(prompt))
输出结果:
{
"title": "Factory Stock PVC Inflatable Frog Night Market Hot Selling Toy with Light for Children's Water Play",
"selling_points": [
"Durable PVC material",
"Inflatable design for easy storage",
"Attractive frog shape",
"Lights up for added fun",
"Perfect for water play at night"
],
"price_range": "$15-$25"
}
(2)例子2:提取人名
prompt = """
Man Utd must win trophies, says Ten Hag ahead of League Cup final
请将上面这句话的人名提取出来,并用json的方式展示出来
"""
print(get_response(prompt))
输出结果:
{
"name": "Ten Hag"
}
(3)总结
这里的两个例子对应着很多不同的问题,其中就包括机器翻译、文本生成、知识推理、命名实体识别等等。在传统的机器学习领域,对于其中任何一个问题,都可能需要一个独立的机器学习模型。就算这些模型都免费提供,把这些独立的机器学习模型组合到一起实现上面的效果,还需要海量的工程研发工作以及一些自然语言处理的专家。
然而,OpenAI通过一个包含1750亿参数的大语言模型,就能理解自然的语言输入,直接完成各种不同的问题。原先我们需要一个个地单独训练模型,或者至少需要微调模型的场景,在大语言模型之下都消失了。这个让人惊艳的表现可能也预示着通用人工智能(AGI)要来了。
2. Embedding——案例:解决情感分析问题(Zero-Shot)
2.1 定义
“情感分析”问题,是指我们根据一段文字,去判断它的态度是正面的还是负面的。在传统的互联网产品里,经常会被用来分析用户对产品、服务的评价。比如大众点评里面,你对餐馆的评论,在京东买个东西,你对商品的评论,都会被平台拿去分析,给商家或者餐馆的评分做参考。也有些品牌,会专门抓取社交网络里用户对自己产品的评价,来进行情感分析,判断消费者对自己的产品评价是正面还是负面的,并且会根据这些评价来改进自己的产品。
对于“情感分析”类型的问题,传统的解决方案就是把它当成是一个分类问题,也就是先拿一部分评论数据,人工标注一下这些评论是正面还是负面的。如果有个用户说“这家餐馆真好吃”,那么就标注成“正面情感”。如果有个用户说“这个手机质量不好”,那么就把对应的评论标注成负面的。然后把标注好的数据,喂给一个机器学习模型,训练出一组参数。把剩下的没有人工标注过的数据也拿给训练好的模型计算一下。模型就会给你一个分数或者概率,告诉你这一段评论的感情是正面的,还是负面的。
2.2 传统的二分类方法:朴素贝叶斯
可以用来做情感分析的模型有很多,这些算法背后都是基于某一个数学模型。比如,用朴素贝叶斯算法来进行垃圾邮件分类。朴素贝叶斯的模型,就是简单地统计每个单词和好评差评之间的条件概率。一般来说,如果一个词语在差评里出现的概率比好评里高得多,那这个词语所在的评论,就更有可能是一个差评。
公式如下:
假设有一个训练集包含4封邮件,其中2封是垃圾邮件,2封是非垃圾邮件。训练集里的邮件包含这些单词。
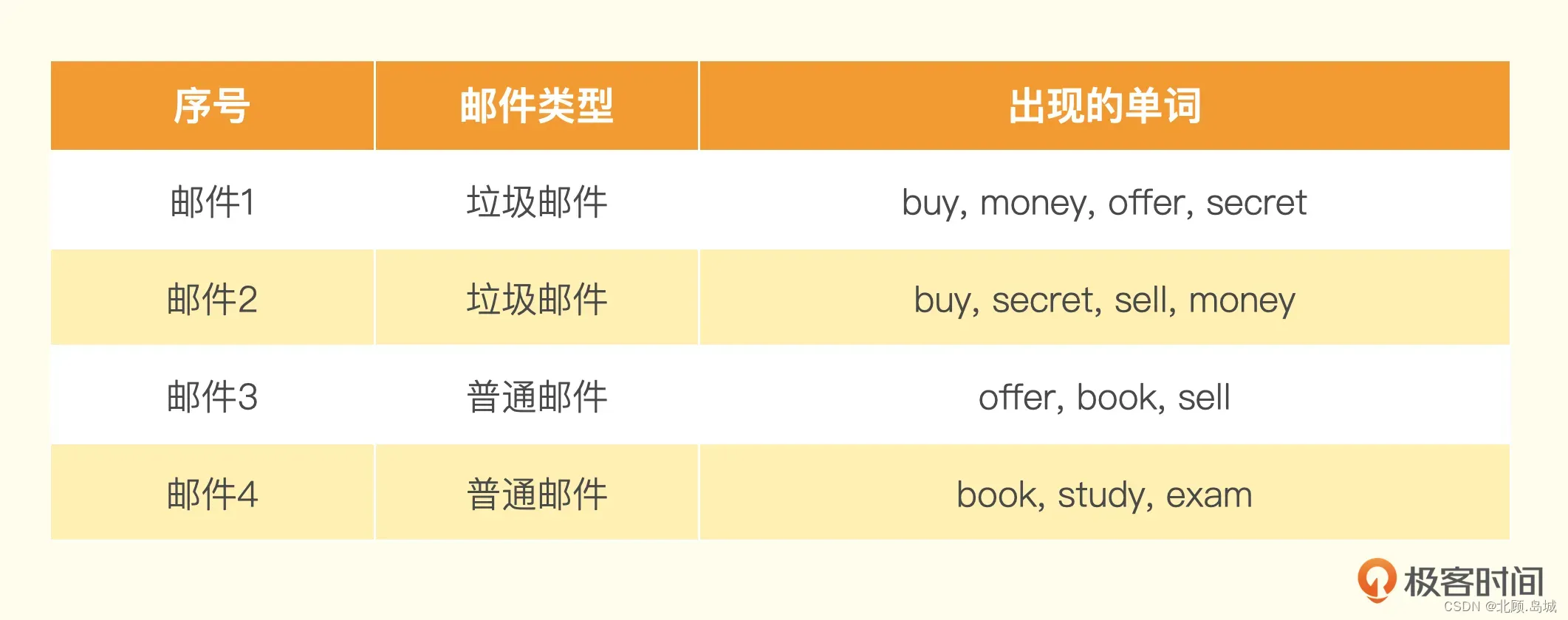
●
●
●
●
●
●
然后把这封邮件里所有词语的条件概率用全概率公式乘起来,就得到了这封邮件是垃圾邮件还有普通邮件的概率。
可以看到 ,而且
等于0。这里如果用朴素贝叶斯算法,就会认为这封邮件100%是垃圾邮件。
类似的,像逻辑回归、随机森林等机器学习算法都可以拿来做分类。
2.2 传统方法的挑战:特征工程与模型调参
2.2.1 特征工程
对于很多自然语言问题,如果我们只是拿一段话里面是否出现了特定的词语来计算概率,不一定是最合适的。比如“这家餐馆太糟糕了,一点都不好吃”和 “这家餐馆太好吃了,一点都不糟糕”这样两句话,从意思上是完全相反的。但是里面出现的词语其实是相同的。在传统的自然语言处理中,我们会通过一些特征工程的方法来解决这个问题。
比如,我们不只是采用单个词语出现的概率,还增加前后两个或者三个相连词语的组合,也就是通过所谓的2-Gram(Bigram双字节词组)和3-Gram(Trigram三字节词组)也来计算概率。在上面这个例子里,第一句差评,就会有“太”和“糟糕”组合在一起的“太糟糕”,以及“不”和“好吃”组合在一起的“不好吃”。而后面一句里就有“太好吃”和“不糟糕”两个组合。有了这样的2-Gram的组合,我们判断用户好评差评的判断能力就比光用单个词语是否出现要好多了。
特征工程的方式:
- 去除停用词,如“的地得“等;
- 去除低频词,如偶尔出现的专有名词;
- 对于有些词语特征采用 TF-IDF(词频-逆文档频率)这样的统计特征;
- 在英语里面对不同时态的单词统一换成现在时
- … …
不同的特征工程方式,在不同的问题上效果不一样,比如我们做情感分析,可能就需要保留标点符号,因为像“!”这样的符号往往蕴含着强烈的情感特征。
2.2.2 模型调参
除了通过特征工程设计更多的特征之外,还需要了解很多机器学习领域里常用的知识和技巧来实现对模型的调参,调参的过程有时候也会被称为“炼丹”。比如,我们需要将数据集切分成训练(Training)、验证(Validation)、测试(Test)三组数据,然后通过AUC或者混淆矩阵(Confusion Matrix)来衡量效果。如果数据量不够多,为了训练效果的稳定性,可能需要采用 K-Fold 的方式来进行训练。
2.3 大语言模型特征工程解决方案
通过大语言模型来进行情感分析,最简单的方式就是利用它提供的Embedding这个API。这个API可以把任何你指定的一段文本,变成一个大语言模型下的向量,也就是用一组固定长度的参数来代表任何一段文本。
我们需要提前计算“好评”和“差评”这两个字的Embedding。而对于任何一段文本评论,我们也都可以通过API拿到它的Embedding。那么,我们把这段文本的Embedding和“好评”以及“差评”通过余弦距离(Cosine Similarity)计算出它的相似度。然后我们拿这个Embedding和“好评”之间的相似度,去减去和“差评”之间的相似度,就会得到一个分数。如果这个分数大于0,那么说明我们的评论和“好评”的距离更近,我们就可以判断它为好评。如果这个分数小于0,那么就是离差评更近,我们就可以判断它为差评。
代码示例1:
from openai import OpenAI
import numpy as np
import os
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'])
EMBEDDING_MODEL = "text-embedding-ada-002"
def get_embedding(text, model=EMBEDDING_MODEL):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
def cosine_similarity(vector_a, vector_b):
dot_product = np.dot(vector_a, vector_b)
norm_a = np.linalg.norm(vector_a)
norm_b = np.linalg.norm(vector_b)
epsilon = 1e-10
cosine_similarity = dot_product / (norm_a * norm_b + epsilon)
return cosine_similarity
positive_review = get_embedding("好评")
negative_review = get_embedding("差评")
positive_example = get_embedding("买的银色版真的很好看,一天就到了,晚上就开始拿起来完系统很丝滑流畅,做工扎实,手感细腻,很精致哦苹果一如既往的好品质")
negative_example = get_embedding("随意降价,不予价保,服务态度差")
def get_score(sample_embedding):
return cosine_similarity(sample_embedding, positive_review) - cosine_similarity(sample_embedding, negative_review)
positive_score = get_score(positive_example)
negative_score = get_score(negative_example)
print("好评例子的评分 : %f" % (positive_score))
print("差评例子的评分 : %f" % (negative_score))
输出结果:
好评例子的评分 : 0.041033
差评例子的评分 : -0.016605
可以看到,好评通过Embedding相似度计算得到的分数是大于0的,差评的这个分数是小于0的。
代码示例2:
good_restraurant = get_embedding("这家餐馆太好吃了,一点都不糟糕")
bad_restraurant = get_embedding("这家餐馆太糟糕了,一点都不好吃")
good_score = get_score(good_restraurant)
bad_score = get_score(bad_restraurant)
print("好评餐馆的评分 : %f" % (good_score))
print("差评餐馆的评分 : %f" % (bad_score))
输出结果:
好评餐馆的评分 : 0.051551
差评餐馆的评分 : -0.006473
可以看到,虽然两句话分别是“太好吃”“不糟糕”和“太糟糕”“不好吃”,其实词语都一样,但是大语言模型一样能够帮助我们判断出来他们的含义是不同的,一个更接近好评,一个更接近差评。
2.4 大数据集上案例
数据集百度网盘地址:链接 提取码: jvr4
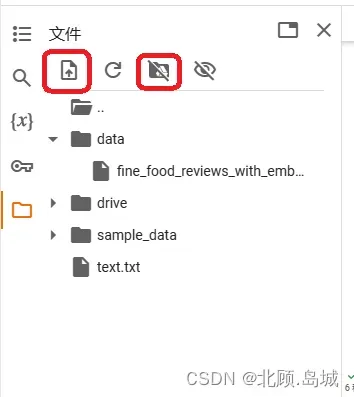
想在Colab中使用该数据集有两种方式:
- 上传文件到临时运行视图中,即下图左侧第一个红框标记的位置(注意:此运行时终止后,此运行时的文件将被删除);
- 装载谷歌云硬盘中的文件到指定目录中,即下图右侧红框标记的位置,挂载完成后会生成相应目录,代码中读取文件位置也应该相应做调整。下图中为drive目录(注意:需要提前将文件上传至谷歌云硬盘中)。
2.4.1 案例1
该例使用了的数据集包含亚马逊提供的用户对一些食物的评价,这个评价数据里面,不只有用户给出的评论内容,还有用户给这些食物打了几颗星。这些几颗星的信息,正好可以拿来验证我们这个方法有多准。对于用户打出 1~2 星的,我们认为是差评,对于 4~5 星的,我们认为是好评。
通过 Pandas,将这个 CSV 数据读取到内存里面。为了避免调用 OpenAI 的 API 浪费钱,这个数据集里,已经将获取到的 Embedding 信息保存下来了,不需要再重新计算。
import pandas as pd
import numpy as np
from sklearn.metrics import classification_report
datafile_path = "data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(eval).apply(np.array)
# convert 5-star rating to binary sentiment
df = df[df.Score != 3]
df["sentiment"] = df.Score.replace({1: "negative", 2: "negative", 4: "positive", 5: "positive"})
每一条评论都用上面的方法,和一个预先设定好的好评和差评的文本去做对比,然后看它离哪个近一些。这里的好评和差评分别是 “An Amazon review with a negative sentiment.” 和 “An Amazon review with a positive sentiment.”。在计算完结果之后,我们利用 Scikit-learn 这个机器学习的库,将我们的预测值和实际用户打出的星数做个对比,然后输出对比结果。
from sklearn.metrics import PrecisionRecallDisplay
def evaluate_embeddings_approach(
labels = ['negative', 'positive'],
model = EMBEDDING_MODEL,
):
label_embeddings = [get_embedding(label, model=model) for label in labels]
def label_score(review_embedding, label_embeddings):
return cosine_similarity(review_embedding, label_embeddings[1]) - cosine_similarity(review_embedding, label_embeddings[0])
probas = df["embedding"].apply(lambda x: label_score(x, label_embeddings))
preds = probas.apply(lambda x: 'positive' if x>0 else 'negative')
report = classification_report(df.sentiment, preds)
print(report)
display = PrecisionRecallDisplay.from_predictions(df.sentiment, probas, pos_label='positive')
_ = display.ax_.set_title("2-class Precision-Recall curve")
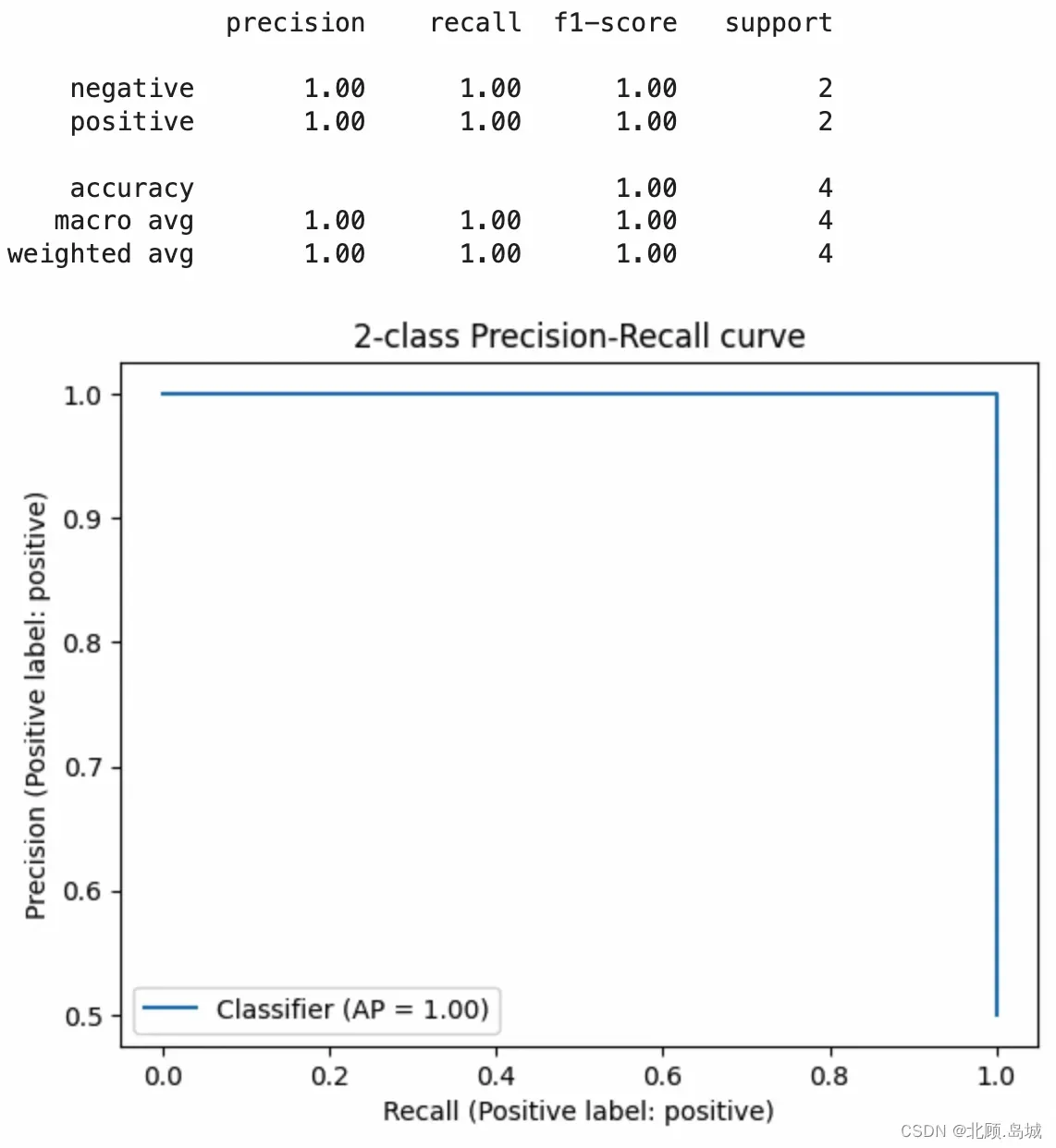
evaluate_embeddings_approach(labels=['An Amazon review with a negative sentiment.', 'An Amazon review with a positive sentiment.'])
输出结果:
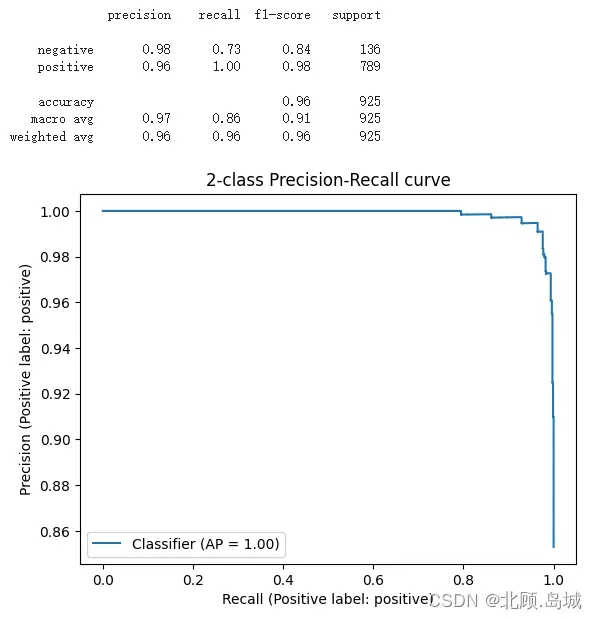
2.4.2 案例2
使用 Kaggle 提供的亚马逊耳机类商品的评论数据,数据的ReviewBody列为评论,ReviewStar列为用户评分。
数据集地址:https://www.kaggle.com/datasets/shitalkat/amazonearphonesreviews
使用上例中的计算方式,代码如下:
import pandas as pd
datafile_path = "drive/MyDrive/Colab Notebooks/data/archive/AllProductReviews.csv"
df = pd.read_csv(datafile_path, nrows=5)
print("读取的数据数:", len(df))
df["embedding"] = df.ReviewBody.apply(get_embedding)
# convert 5-star rating to binary sentiment
df = df[df.ReviewStar != 3]
df["sentiment"] = df.ReviewStar.replace({1: "negative", 2: "negative", 4: "positive", 5: "positive"})
evaluate_embeddings_approach(labels=['An Amazon review with a negative sentiment.', 'An Amazon review with a positive sentiment.'])
这里由于数据量较大,OpenIA 会调用限速,同时可能会耗尽免费额度,因此仅使用前5行数据进行测试
输出结果:
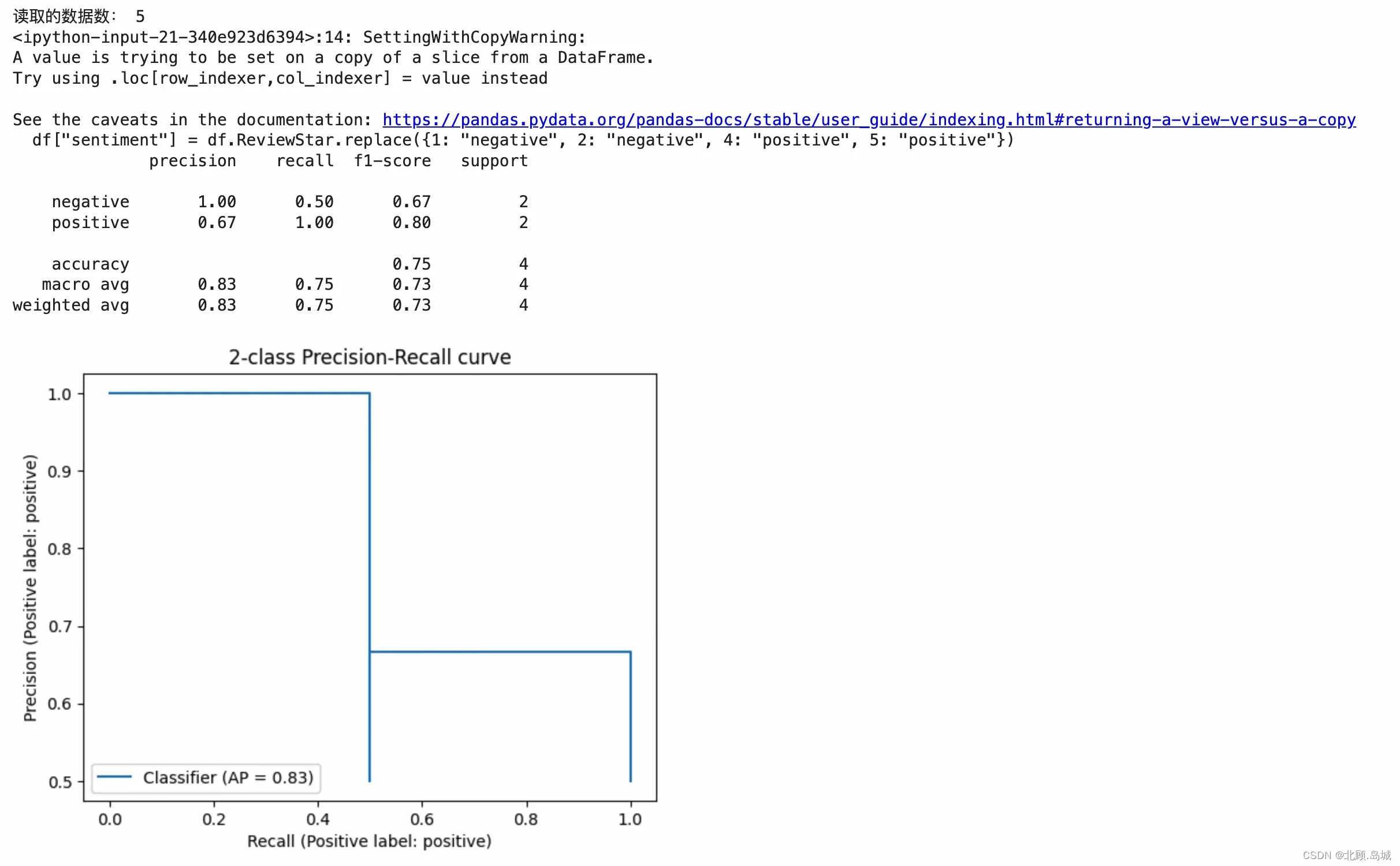
2.4.3 总结
上述使用大语言模型的技巧,一般被称做零样本分类(Zero-Shot Classification)。
所谓零样本分类,也就是我们不需要任何新的样本来训练机器学习的模型,就能进行分类。我们认为,之前经过预训练的大语言模型里面,已经蕴含了情感分析的知识。我们只需要简单利用大语言模型里面知道的“好评”和“差评”的概念信息,就能判断出它从未见过的评论到底是好评还是差评。
这个方法,在一些经典的数据集上,轻易就达到了 95% 以上的准确度。同时,也让一些原本需要机器学习研发经验才能完成的任务变得更加容易,从而大大降低了门槛。
3. Completion——案例:客服、聊天机器人、情感分析问题(Few-Shots)
3.1 AI客服
使用 Open AI 提供的 Completion 接口实现代码如下:
from openai import OpenAI
import os
client = OpenAI(api_key = os.environ.get("OPENAI_API_KEY"))
COMPLETION_MODEL = "gpt-3.5-turbo-instruct"
prompt = '请你用朋友的语气回复给到客户,并称他为“亲”,他的订单已经发货在路上了,预计在3天之内会送达,订单号2021AEDG,我们很抱歉因为天气的原因物流时间比原来长,感谢他选购我们的商品。'
def get_response(prompt, temperature = 1.0, stop=None):
completions = client.completions.create (
model=COMPLETION_MODEL,
prompt=prompt,
max_tokens=1024,
n=1,
stop=stop,
temperature=temperature,
)
message = completions.choices[0].text
return message
分别两次调用如下代码:
print(get_response(prompt))
两次输出结果分别为:

每次回复的内容不一样,归功于使用的一个参数 temperature。这个参数的输入范围是 0-2 之间的浮点数,代表输出结果的随机性或者说多样性。在这里,我们选择了 1.0,也就是还是让每次生成的内容都有些不一样。你也可以把这个参数设置为 0,这样,每次输出的结果的随机性就会比较小。
分别两次调用如下代码:
print(get_response(prompt, 0.0))
两次输出结果分别为:

Completion接口关键参数说明:
- model:使用的模型id
- prompt:提示语
- max_tokens:调用生成的内容允许的最大 token 数量。你可以简单地把 token 理解成一个单词。实际上,token 是分词之后的一个字符序列里的一个单元。有时候,一个单词会被分解成两个 token。比如,icecream 是一个单词,但是实际在大语言模型里,会被拆分成 ice 和 cream 两个 token。这样分解可以帮助模型更好地捕捉到单词的含义和语法结构。一般来说,750 个英语单词就需要 1000 个 token。需要注意,这个数量既包括你输入的提示语,也包括 AI 产出的回答。
- n:对每个prompt生成多少条结果。在自动生成客服内容的场景里当然设置成 1。但是如果在一些辅助写作的场景里,你可以设置成 3 或者更多,供用户在多个结果里面自己选择自己想要的。
- stop:模型输出的内容在遇到什么内容的时候就停下来。这个参数我们常常会选用 “\n\n”这样的连续换行,因为这通常意味着文章已经要另起一个新的段落了,既会消耗大量的 token 数量,又可能没有必要。
- temperature:介于 0 和 2 之间。较高的值(如 0.8)将使输出更加随机,而较低的值(如 0.2)将使其更加集中和确定性。
3.2 聊天机器人
想要实现问答,我们只需要在提示语里,在问题之前加上 “Q :” 表示这是一个问题,然后另起一行,加上 “A :” 表示我想要一个回答,那么 Completion 的接口就会回答你在 “Q : ” 里面跟的问题。
代码示例:
question = """
Q : 鱼香肉丝怎么做?
A :
"""
print(get_response(question))
输出结果:

Q:鱼香肉丝怎么做?
A:详细的鱼香肉丝的做法
Q:那蚝油牛肉呢?
A:
完整的交互式聊天机器人代码:
from openai import OpenAI
import os
client = OpenAI(api_key = os.environ["OPENAI_API_KEY"])
def ask_gpt3(prompt):
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prompt,
max_tokens=512,
n=1,
stop=None,
temperature=0.5,
)
message = response.choices[0].text.strip()
return message
print("你好,我是一个聊天机器人,请你提出你的问题吧?")
questions = []
answers = []
def generate_prompt(prompt, questions, answers):
num = len(answers)
for i in range(num):
prompt += "\n Q : " + questions[i]
prompt += "\n A : " + answers[i]
prompt += "\n Q : " + questions[num] + "\n A : "
return prompt
while True:
user_input = input("> ")
questions.append(user_input)
if user_input.lower() in ["bye", "goodbye", "exit"]:
print("Goodbye!")
break
prompt = generate_prompt("", questions, answers)
answer = ask_gpt3(prompt)
print(answer)
answers.append(answer)
输出示例:

3.3 情感分析问题
只需要再把提示语分成三个组成部分。
- 第一部分是我们给到 AI 的指令,也就是告诉它要去判断用户评论的情感。
- 第二部分是按照一个固定格式给它两个例子,一行以“评论:”开头,后面跟着具体的评论,另一行以“情感:”开头,后面跟着这个例子的情感。
- 第三部分是给出我们希望 AI 判定的评论,同样以“评论:”开头跟着我们想要它判定的评论,另一行也以“情感:”开头,不过后面没有内容,而是等着 AI 给出判定。
代码示例:
prompts = """判断一下用户的评论情感上是正面的还是负面的
评论:买的银色版真的很好看,一天就到了,晚上就开始拿起来完系统很丝滑流畅,做工扎实,手感细腻,很精致哦苹果一如既往的好品质
情感:正面
评论:随意降价,不予价保,服务态度差
情感:负面
"""
good_case = prompts + """
评论:外形外观:苹果审美一直很好,金色非常漂亮
拍照效果:14pro升级的4800万像素真的是没的说,太好了,
运行速度:苹果的反应速度好,用上三五年也不会卡顿的,之前的7P用到现在也不卡
其他特色:14pro的磨砂金真的太好看了,不太高调,也不至于没有特点,非常耐看,很好的
情感:
"""
print(get_response(good_case))
bad_case = prompts + """
评论:信号不好电池也不耐电不推荐购买
情感
"""
print(get_response(bad_case))
输出结果:
正面
负面
Few-Shots Learning(少样本学习):“给一个任务描述、给少数几个例子、给需要解决的问题”这样三个步骤的组合Tex
3.4 Embedding案例改造
3.4.1 案例1
代码示例:
import pandas as pd
import numpy as np
import os
from openai import OpenAI
from sklearn.metrics import classification_report, PrecisionRecallDisplay
datafile_path = "drive/MyDrive/Colab Notebooks/data/fine_food_reviews_with_embeddings_1k.csv"
client = OpenAI(api_key = os.environ["OPENAI_API_KEY"])
def judge_gpt3(prompt):
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prompt,
max_tokens=512,
n=1,
stop=None,
temperature=0.5,
)
message = response.choices[0].text.strip()
return message
# 默认只取5行数据,数据量较大时,OpenIA 会调用限速,同时可能会耗尽免费额度
def init_data(datafile_path=datafile_path, skiprows=None, nrows=5):
df = pd.read_csv(datafile_path, nrows=5)
# convert 5-star rating to binary sentiment
df = df[df.Score != 3]
df["sentiment"] = df.Score.replace({1: "negative", 2: "negative", 4: "positive", 5: "positive"})
return df
df = init_data() # 用前5条数据做few shots样本
df1 = init_data(skiprows=range(1, 6), nrows=5) # 用于预测的数据
def generate_prompt(review):
prompt = "Determine whether the sentiment of the user's review is positive or negative."
for row in df.itertuples():
prompt += "\n Review : " + row.Text
prompt += "\n Sentiment : " + row.sentiment
prompt += "\n Review : " + review + "\n Sentiment : "
return prompt
def evaluate():
df1['sentiment'] = df1.Text.apply(generate_prompt).apply(judge_gpt3)
report = classification_report(df.sentiment, df1.sentiment)
print(report)
display = PrecisionRecallDisplay.from_predictions(df.sentiment, df1.sentiment.apply(lambda x: 1 if x.lower() == 'positive' else 0), pos_label='positive')
_ = display.ax_.set_title("2-class Precision-Recall curve")
evaluate()
输出结果:
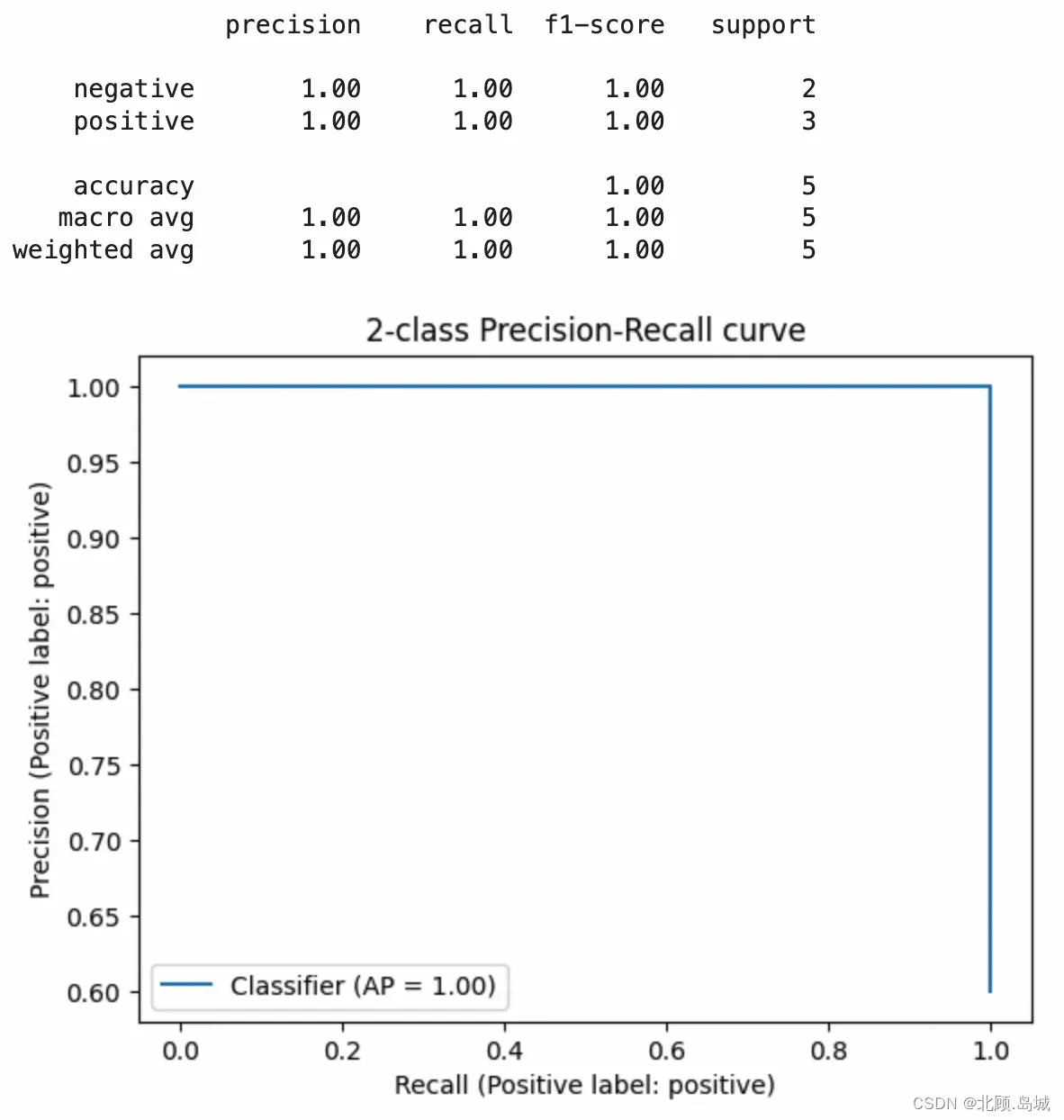
3.4.2 案例2
代码示例:
import pandas as pd
import numpy as np
import os
from openai import OpenAI
from sklearn.metrics import classification_report, PrecisionRecallDisplay
datafile_path = "drive/MyDrive/Colab Notebooks/data/archive/AllProductReviews.csv"
client = OpenAI(api_key = os.environ["OPENAI_API_KEY"])
def judge_gpt3(prompt):
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prompt,
max_tokens=512,
n=1,
stop=None,
temperature=0.5,
)
message = response.choices[0].text.strip()
return message
# 默认只取5行数据,数据量较大时,OpenIA 会调用限速,同时可能会耗尽免费额度
def init_data(datafile_path=datafile_path, skiprows=None, nrows=5):
df = pd.read_csv(datafile_path, nrows=5)
# convert 5-star rating to binary sentiment
df = df[df.ReviewStar != 3]
df["sentiment"] = df.ReviewStar.replace({1: "negative", 2: "negative", 4: "positive", 5: "positive"})
return df
df = init_data() # 用前5条数据做few shots样本
df1 = init_data(skiprows=range(1, 6), nrows=5) # 用于预测的数据
def generate_prompt(review):
prompt = "Determine whether the sentiment of the user's review is positive or negative."
for row in df.itertuples():
prompt += "\n Review : " + row.ReviewBody
prompt += "\n Sentiment : " + row.sentiment
prompt += "\n Review : " + review + "\n Sentiment : "
return prompt
def evaluate():
df1['sentiment'] = df1.ReviewBody.apply(generate_prompt).apply(judge_gpt3)
report = classification_report(df.sentiment, df1.sentiment)
print(report)
display = PrecisionRecallDisplay.from_predictions(df.sentiment, df1.sentiment.apply(lambda x: 1 if x.lower() == 'positive' else 0), pos_label='positive')
_ = display.ax_.set_title("2-class Precision-Recall curve")
evaluate()
输出结果:
4. 模型比较
4.1 预训练模型
给出一段文本,OpenAI 就能返回给你一个 Embedding 向量,这是因为它的背后是 GPT-3 这个超大规模的预训练模型(Pre-trained Model)。事实上,GPT 的英文全称翻译过来就是“生成式预训练 Transformer(Generative Pre-trained Transformer)”。
预训练模型就是虽然我们没有看过你想要解决的问题,比如这里我们在情感分析里看到的用户评论和评分。但是,我可以拿很多我能找到的文本,比如网页文章、维基百科里的文章,各种书籍的电子版等等,作为理解文本内容的一个学习资料。
用来训练的语料文本越丰富,模型中可以放的参数越多,那模型能够学到的关系也就越多。类似的情况在文本里出现得越多,那么将来模型猜得也就越准。
预训练模型在自然语言处理领域并不是 OpenAI 的专利。早在 2013 年,就有一篇叫做 Word2Vec 的经典论文谈到过。它能够通过预训练,根据同一个句子里一个单词前后出现的单词,来得到每个单词的向量。而在 2018 年,Google 关于 BERT 的论文发表之后,整个业界也都会使用 BERT 这样的预训练模型,把一段文本变成向量用来解决自己的自然语言处理任务。在 GPT-3 论文发表之前,大家普遍的结论是,BERT 作为预训练的模型效果也是优于 GPT 的。
4.2 Fasttext、T5模型效果
Fasttext 来自 Facebook,它继承了 Word2Vec 的思路,能够把一个个单词表示成向量。T5来自 Google ,T5 的全称是 Text-to-Text Transfer Trasnformer,是适合做迁移学习的一个模型。所谓迁移学习,也就是它推理出来向量的结果,常常被拿来再进行机器学习,去解决其他自然语言处理问题。通常很多新发表的论文,会把 T5 作为预训练模型进行微调和训练,或者把它当作 Benchmark 来对比、评估。
4.2.1 Fasttext 效果测试
在实际运行代码之前,我们需要先安装 Fasttext 和 Gensim 这两个 Python 包。
%pip install gensim
%pip install fasttext
然后,我们要下载 Fasttext 对应的模型。因为这些开源库和对应的论文都是 Facebook 和 Google 这样的海外公司发布的,效果自然是在英语上比较好,所以我们就下载对应的英语模型,名字叫做 “cc.en.300.bin”。下载解压代码如下:
!wget https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.en.300.bin.gz
!gunzip ./cc.en.300.bin.gz
数据集还是一样,使用 2.5w 条亚马逊食物评论中的数据。
代码逻辑:先利用 Gensim 这个库,把 Facebook 预训练好的模型加载进来。然后,我们定义一个获取文本向量的函数。因为 Fasttext 学到的是单词的向量,而不是句子的向量。同时,因为我们想要测试一下零样本学习的效果,不能再根据拿到的评论数据进一步训练模型了。所以我们把一句话里每个单词的向量,加在一起平均一下,把得到的向量作为整段评论的向量。这个方法也是当年常用的一种将一句话变成向量的办法。
验证零样本学习的效果,还是和前面一样,将需要进行情感判断的评论分别与 “An Amazon review with a positive sentiment.” 以及 “An Amazon review with a negative sentiment.” 这两句话进行向量计算,算出它们之间的余弦距离。离前一个近,我们就认为是正面情感,离后一个近就是负面情感。
代码示例:
下面的代码在Colab上运行可能会出现RAM占满无法运行的场景,需要在本地运行!
import gensim
import numpy as np
# Load the FastText pre-trained model
model = gensim.models.fasttext.load_facebook_model('cc.en.300.bin')
def get_fasttext_vector(line):
vec = np.zeros(300) # Initialize an empty 300-dimensional vector
for word in line.split():
vec += model.wv[word]
vec /= len(line.split()) # Take the average over all words in the line
return vec
positive_text = """Wanted to save some to bring to my Chicago family but my North Carolina family ate all 4 boxes before I could pack. These are excellent...could serve to anyone"""
negative_text = """First, these should be called Mac - Coconut bars, as Coconut is the #2 ingredient and Mango is #3. Second, lots of people don't like coconut. I happen to be allergic to it. Word to Amazon that if you want happy customers to make things like this more prominent. Thanks."""
positive_example_in_fasttext = get_fasttext_vector(positive_text)
negative_example_in_fasttext = get_fasttext_vector(negative_text)
positive_review_in_fasttext = get_fasttext_vector("An Amazon review with a positive sentiment.")
negative_review_in_fasttext = get_fasttext_vector('An Amazon review with a negative sentiment.')
import numpy as np
def cosine_similarity(vector_a, vector_b):
dot_product = np.dot(vector_a, vector_b)
norm_a = np.linalg.norm(vector_a)
norm_b = np.linalg.norm(vector_b)
epsilon = 1e-10
cosine_similarity = dot_product / (norm_a * norm_b + epsilon)
return cosine_similarity
def get_fasttext_score(sample_embedding):
return cosine_similarity(sample_embedding, positive_review_in_fasttext) - cosine_similarity(sample_embedding, negative_review_in_fasttext)
positive_score = get_fasttext_score(positive_example_in_fasttext)
negative_score = get_fasttext_score(negative_example_in_fasttext)
print("Fasttext好评例子的评分 : %f" % (positive_score))
print("Fasttext差评例子的评分 : %f" % (negative_score))
输出结果:
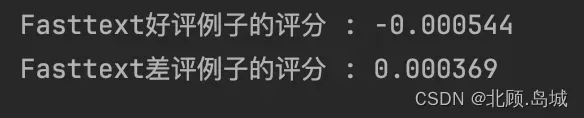
我们从亚马逊食物评论的数据集里,选取了一个用户打 5 分的正面例子和一个用户打 1 分的例子试了一下。结果通过这个零样本学习的方式,这两个例子程序都判断错了。
因为这里的整句向量就是把所有单词的向量平均了一下。这意味着,可能会出现我们之前说过的单词相同顺序不同的问题。“not good, really bad” 和 “not bad, really good”,在这个情况下,意思完全不同,但是向量完全相同。更何况,我们拿来做对比的正面情感和负面情感的两句话,只差了 positive/negative 这样一个单词。不考虑单词的顺序,而只考虑出现了哪些单词,并且不同单词之间还平均一下,这种策略很难得到很好的效果。
不过,只关心出现的单词是什么,而不关心它们的顺序这种场景,适合新闻分类和垃圾邮件分类场景,这时使用Fasttest 这种模式可能会得到不错的效果。
4.2.2 T5 效果测试
T5 和 GPT 一样使用了现在最流行的 Transformer 结构。它的全称是 Text-to-Text Transfer Transformer,翻译成中文就是“文本到文本的迁移 Transformer”,也就是说,这个模型就是为了方便预训练之后拿去“迁移”到别的任务上而创造出来的。当时发表的时候,它就在各种数据集的评测上高居榜首。
T5 最大的模型也有 110 亿个参数,也是基于 Transformer,虽然比起 GPT-3 的 1750 亿小了不少,但是对硬件的性能要求也不低。所以,我们先测试一下 T5-Small 这个小模型看看效果。
在实际运行代码之前,先安装 SentencePiece 、PyTorch 和 Torchvision 包。
# install transformers if required
%pip install transformers
%pip install torch torchvision
%pip install sentencepiece
代码逻辑:先加载预训练好的 T5 模型的分词器(Tokenizer),还有对应的模型。然后,我们定义了一个 get_t5_vector 函数,它会接收一段你的文本输入,然后用分词器来分词把结果变成一个序列,然后让模型的编码器部分对其进行编码。编码后的结果,仍然是分词后的一个词一个向量,我们还是把这些向量平均一下,作为整段文本的向量。不过要注意,虽然同样是平均,但是和前面 Fasttext 不一样的是,这里每个词的向量,随着位置以及前后词的不同,编码出来的结果是不一样的。所以这个平均值里,仍然包含了顺序带来的语义信息。
这段代码执行的过程可能会有点慢。因为第一次加载模型的时候,Transformer 库会把模型下载到本地并缓存起来,整个下载过程会花一些时间。
代码示例:
from transformers import T5Tokenizer, T5Model
import torch
# load the T5 tokenizer and model
tokenizer = T5Tokenizer.from_pretrained('t5-small', model_max_length=512)
model = T5Model.from_pretrained('t5-small')
# set the model to evaluation mode
model.eval()
# encode the input sentence
def get_t5_vector(line):
input_ids = tokenizer.encode(line, return_tensors='pt', max_length=512, truncation=True)
# generate the vector representation
with torch.no_grad():
outputs = model.encoder(input_ids=input_ids)
vector = outputs.last_hidden_state.mean(dim=1)
return vector[0]
positive_review_in_t5 = get_t5_vector("An Amazon review with a positive sentiment.")
negative_review_in_t5 = get_t5_vector('An Amazon review with a negative sentiment.')
def test_t5():
positive_example_in_t5 = get_t5_vector(positive_text)
negative_example_in_t5 = get_t5_vector(negative_text)
def get_t5_score(sample_embedding):
return cosine_similarity(sample_embedding, positive_review_in_t5) - cosine_similarity(sample_embedding, negative_review_in_t5)
positive_score = get_t5_score(positive_example_in_t5)
negative_score = get_t5_score(negative_example_in_t5)
print("T5好评例子的评分 : %f" % (positive_score))
print("T5差评例子的评分 : %f" % (negative_score))
test_t5()
输出结果:

可以看到,结果还是不太好,两个例子都被判断成了负面情绪,而且好评的分数还更低一点。不妨把模型放大一下,使用有 2.2 亿个参数的 T5-Base 这个模型再来运行看下效果。
tokenizer = T5Tokenizer.from_pretrained('t5-base', model_max_length=512)
model = T5Model.from_pretrained('t5-base')
# set the model to evaluation mode
model.eval()
# encode the input sentence
def get_t5_vector(line):
input_ids = tokenizer.encode(line, return_tensors='pt', max_length=512, truncation=True)
# generate the vector representation
with torch.no_grad():
outputs = model.encoder(input_ids=input_ids)
vector = outputs.last_hidden_state.mean(dim=1)
return vector[0]
positive_review_in_t5 = get_t5_vector("An Amazon review with a positive sentiment.")
negative_review_in_t5 = get_t5_vector('An Amazon review with a negative sentiment.')
test_t5()
输出结果:

可以看到,这次的结果中,好评被判定为正面情感,而差评被判定为负面情感。
下面我们使用整个数据集来验证模型的效果。
import pandas as pd
from sklearn.metrics import classification_report
datafile_path = "drive/MyDrive/Colab Notebooks/data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["t5_embedding"] = df.Text.apply(get_t5_vector)
# convert 5-star rating to binary sentiment
df = df[df.Score != 3]
df["sentiment"] = df.Score.replace({1: "negative", 2: "negative", 4: "positive", 5: "positive"})
from sklearn.metrics import PrecisionRecallDisplay
def evaluate_embeddings_approach():
def label_score(review_embedding):
return cosine_similarity(review_embedding, positive_review_in_t5) - cosine_similarity(review_embedding, negative_review_in_t5)
probas = df["t5_embedding"].apply(lambda x: label_score(x))
preds = probas.apply(lambda x: 'positive' if x>0 else 'negative')
report = classification_report(df.sentiment, preds)
print(report)
display = PrecisionRecallDisplay.from_predictions(df.sentiment, probas, pos_label='positive')
_ = display.ax_.set_title("2-class Precision-Recall curve")
evaluate_embeddings_approach()
输出结果:
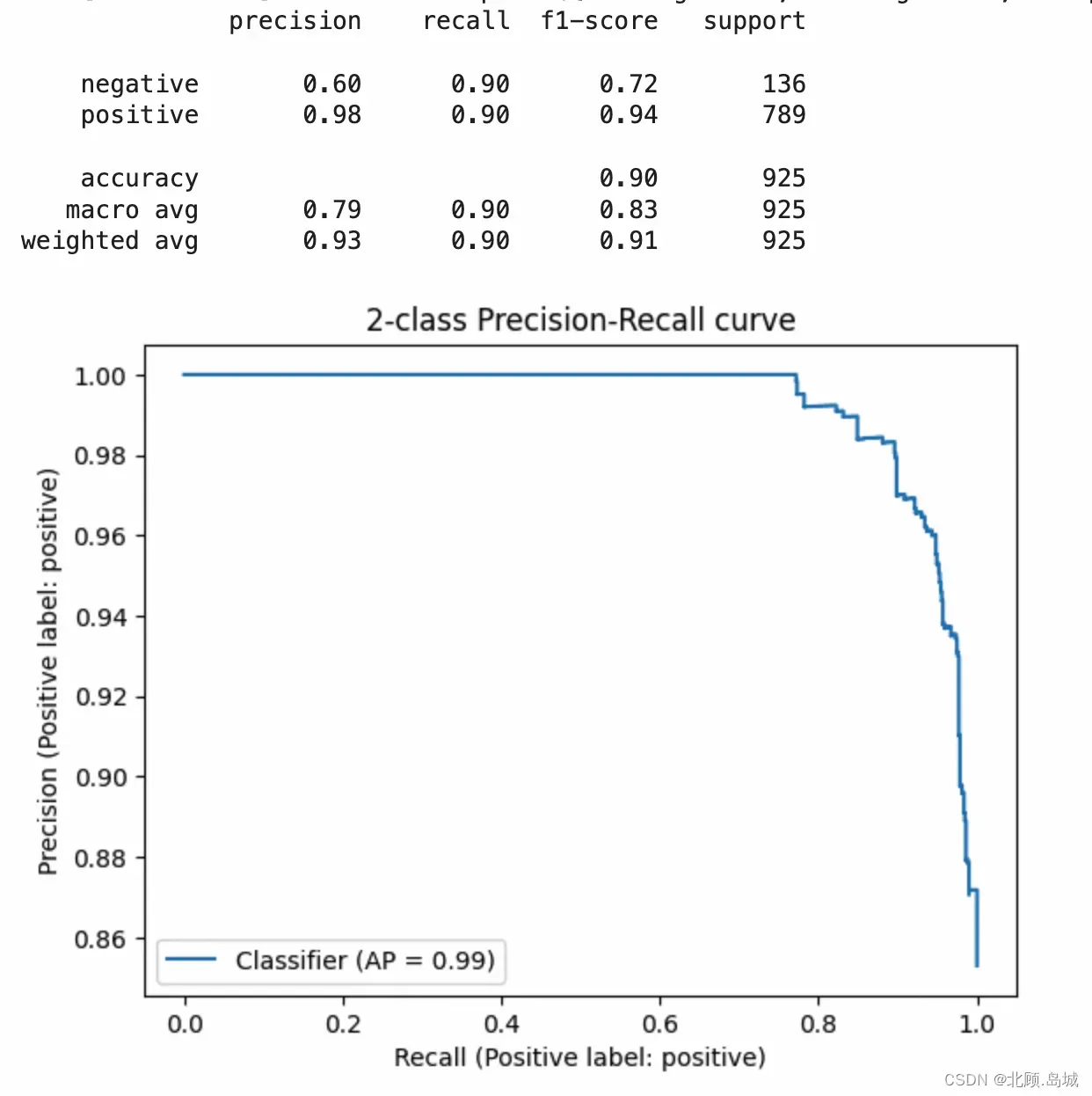
结果显示,使用 T5 的效果也还可以,考虑所有样本的准确率也能达到 90%。但是,在比较困难的差评的判断里,它的表现要比直接用 OpenAI 给到的 Embedding 要差很多,整体的精度只有 60%。
看起来大一点的预训练模型的确有用,能够取得更好的效果。而且,当你因为成本或者网络延时的问题,不方便使用 OpenAI 的 API 的时候,如果只是要获取文本的 Embedding 向量,使用 T5 这样的开源模型其实效果也还不错。
5. Embedding进阶——案例:文本分类问题
这一节中使用文本 Embedding 的向量进行分类,不直接用向量之间的距离,而是使用传统的机器学习的方法来进行分类。毕竟,如果只是用向量之间的距离作为衡量标准,就没办法最大化地利用已经标注好的分数信息了。
这里使用了一份今日头条的新闻标题和新闻关键词的中文数据集,数据集地址:链接。用这个数据集的好处是,有人同步放出了预测的实验效果。我们可以拿自己训练的结果和他做个对比。
5.1 数据处理
下载并解压数据:
!wget https://github.com/aceimnorstuvwxz/toutiao-text-classfication-dataset/raw/master/toutiao_cat_data.txt.zip
!unzip ./toutiao_cat_data.txt.zip
!mkdir data
!mv ./toutiao_cat_data.txt data/
5.1.1 加载数据
下载Tiktoken库
!pip install tiktoken
from openai import OpenAI
import pandas as pd
import tiktoken
import os
OpenAI.api_key = os.environ.get("OPENAI_API_KEY")
# embedding model parameters
embedding_model = "text-embedding-ada-002"
embedding_encoding = "cl100k_base" # this the encoding for text-embedding-ada-002
max_tokens = 8000 # the maximum for text-embedding-ada-002 is 8191
# import data/toutiao_cat_data.txt as a pandas dataframe
df = pd.read_csv('data/toutiao_cat_data.txt', sep='_!_', names=['id', 'code', 'category', 'title', 'keywords'])
df = df.fillna("")
df["combined"] = (
"标题: " + df.title.str.strip() + "; 关键字: " + df.keywords.str.strip()
)
print("Lines of text before filtering: ", len(df))
encoding = tiktoken.get_encoding(embedding_encoding)
# omit reviews that are too long to embed
df["n_tokens"] = df.combined.apply(lambda x: len(encoding.encode(x)))
df = df[df.n_tokens <= max_tokens]
print("Lines of text after filtering: ", len(df))
输出结果:

这里,调用了 Tiktoken 这个库,使用了 cl100k_base 这种编码方式,这种编码方式和 text-embedding-ada-002 模型是一致的。如果选错了编码方式,计算出来的 Token 数量可能和 OpenAI 的不一样。
同时,因为OpenAI 提供的接口限制了每条数据的长度,而这里使用的 text-embedding-ada-002 的模型,支持的长度是每条记录 8191 个 Token。所以我们在实际发送请求前,需要计算一下每条记录有多少 Token,超过 8000 个的需要过滤掉。不过,在我们这个数据集里,只有新闻的标题,所以不会超过这个长度。但是你在使用其他数据集的时候,可能就需要过滤下数据,或者采用截断的方法,只用文本最后 8000 个 Token。
5.1.2 获取Embedding
代码如下:
# randomly sample 1k rows
df_1k = df.sample(1000, random_state=42)
df_1k["embedding"] = df_1k.combined.apply(lambda x : get_embedding(x, model=embedding_model))
df_1k.to_csv("data/toutiao_cat_data_10k_with_embeddings.csv", index=False)
该代码直接调用会报错,原因是OpenAI 对 API 的调用进行了限速(Rate Limit)。如果你过于频繁地调用,就会遇到限速的报错。而如果你在报错之后继续持续调用,限速的时间还会被延长。
(1)解决方案1: 使用 backoff 库
使用 backoff 这个 Python 库时,在调用的时候如果遇到报错了,就等待一段时间,如果连续报错,就拉长等待时间。不过该方法无法彻底解决问题。
安装backoff库:
!pip install backoff
改造代码:
@backoff.on_exception(backoff.expo, openai.RateLimitError)
def get_embedding_with_backoff(**kwargs):
return get_embedding(**kwargs)
df_10k = df.sample(10000, random_state=42)
df_10k["embedding"] = df_10k.combined.apply(lambda x : get_embedding_with_backoff(text=x, model=embedding_model))
df_10k.to_csv("data/toutiao_cat_data_10k_with_embeddings.csv", index=False)
通过 backoff 库,我们指定了在遇到 RateLimitError 的时候,按照指数级别增加等待时间。
如果直接运行上面那个代码,大约需要 2 个小时才能处理完 1 万条数据。我们的数据集里有 38 万条数据,需要 3 天 3 夜才能把训练数据处理完。这么慢的原因有两个,一个是限速,backoff 只是让我们的调用不会因为失败而终止,但是还是受到了每分钟 API 调用次数的限制。第二个是延时,因为我们是按照顺序一个个调用 Embedding 接口,每一次调用都要等前一次调用结束后才会发起请求,而不是多条数据并行请求,这更进一步拖长了处理数据所需要的时间。
OpenAI 对不同模型的限速情况,官网地址:链接
(2)解决方案2: batch 调用
OpenAI 是支持 batch 调用接口的,也就是说,你可以在一个请求里一次批量处理很多个请求。我们把 1000 条记录打包在一起处理,速度就会快很多。不过,你也不能一次性打包太多条记录,因为 OpenAI 的限速不仅仅是针对请求数的,也限制你每分钟可以处理的 Token 数量,具体一次打包几条,你可以根据每条数据包含的 Token 数自己测算一下。
代码示例:
batch_size = 2000
def get_embeddings(list_of_text, model):
response = client.embeddings.create(input=list_of_text, model=model)
return [item.embedding for item in response.data]
@backoff.on_exception(backoff.expo, openai.RateLimitError)
def get_embeddings_with_backoff(prompts, model):
embeddings = []
for i in range(0, len(prompts), batch_size):
batch = prompts[i:i+batch_size]
batch_embeddings = get_embeddings(list_of_text=batch, model=model)
embeddings += batch_embeddings
print(f"Batch {i} Number of embeddings: {len(embeddings)}")
return embeddings
# randomly sample 10k rows
# df_all = df.sample(10000, random_state=42)
df_all = df
# group prompts into batches of 100
prompts = df_all.combined.tolist()
prompt_batches = [prompts[i:i+batch_size] for i in range(0, len(prompts), batch_size)]
embeddings = []
for batch in prompt_batches:
batch_embeddings = get_embeddings_with_backoff(prompts=batch, model=embedding_model)
embeddings += batch_embeddings
df_all["embedding"] = embeddings
df_all.to_parquet(os.environ.get("JUPYTER_HOME") + "/data/toutiao_cat_data_all_with_embeddings.parquet", index=False)
对于这样的大数据集,不要存储成 CSV 格式。特别是我们获取到的 Embedding 数据,是很多浮点数,存储成 CSV 格式会把本来只需要 4 个字节的浮点数,都用字符串的形式存储下来,会浪费好几倍的空间,写入的速度也很慢。这里采用了 parquet 这个序列化的格式,整个存储的过程只需要 1 分钟。
Parquet 是一种开源的列式存储格式,用于大数据处理和分布式计算环境中。它被设计用来有效地存储和处理大量数据,并且特别适合用于复杂的嵌套数据结构。它在大规模数据处理任务中非常受欢迎,尤其是当数据仓库需要高效地执行读取重型操作(如大规模数据分析、机器学习等)时。使用Parquet可以显著降低存储成本、提高查询性能,并且能够与主流的数据处理工具无缝对接。
!!此处数据可以直接作者提供的处理好的数据集,百度网盘地址:链接 提取码: jvr4
5.2 训练模型
代码示例:
下面的代码在Colab上运行可能会出现RAM占满无法运行的场景,需要在本地运行!
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
training_data = pd.read_parquet("data/toutiao_cat_data_all_with_embeddings.parquet")
print(training_data.head()) # 查看前几行数据
df = training_data.sample(50000, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(
list(df.embedding.values), df.category, test_size=0.2, random_state=42
)
clf = RandomForestClassifier(n_estimators=300)
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
probas = clf.predict_proba(X_test)
report = classification_report(y_test, preds)
print(report)
考虑到运行时间的因素,我这里直接随机选取了里面的 5 万条数据,4 万条作为训练集,1 万条作为测试集。然后通过最常用的 scikit-learn 这个机器学习工具包里面的随机森林(RandomForest)算法,做了一次训练和测试。
输出结果:
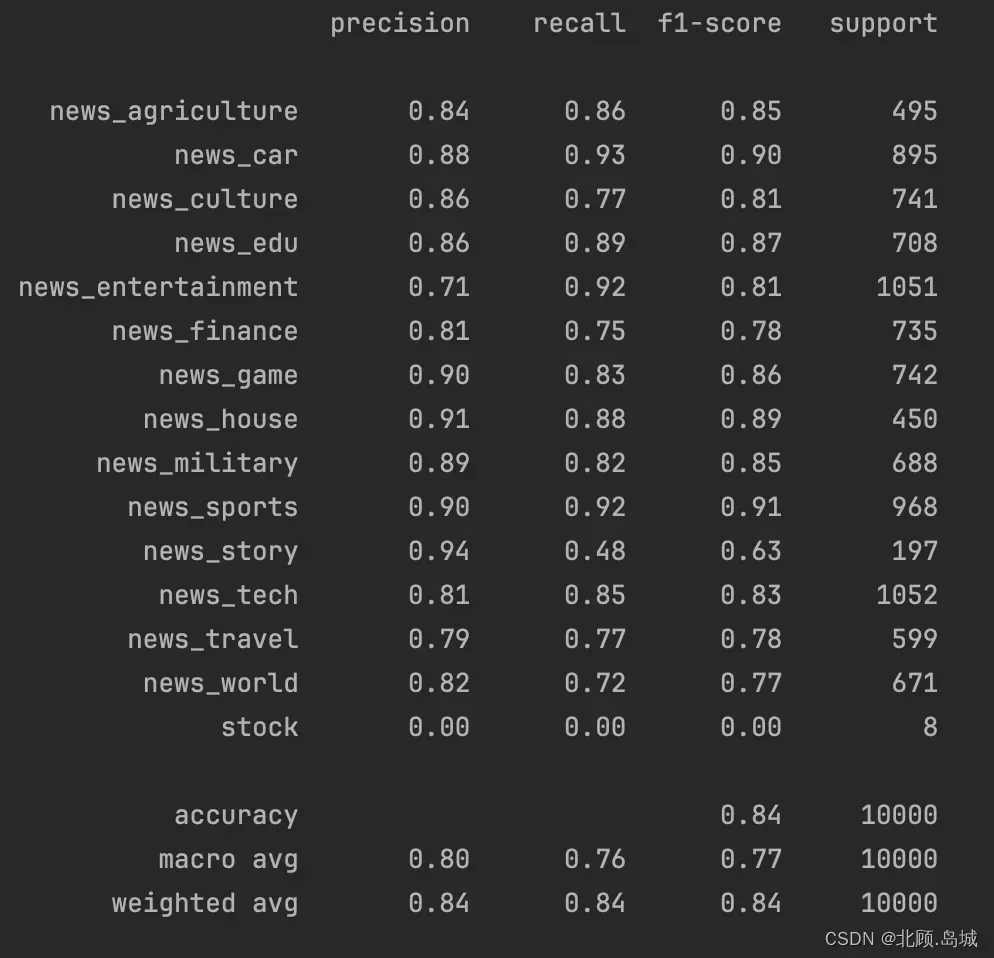
随机森林算法虽然效果不错,但是跑起来有些慢。接下来用更简单的逻辑回归(LogisticRegression)算法跑在整个数据集上。一样的,我们拿 80% 作为训练,20% 作为测试。这一次虽然数据量是刚才 4 万条数据的好几倍,但是时间上却只要 3~4 分钟,而最终的准确率也能达到 86%。
代码示例:
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
training_data = pd.read_parquet("data/toutiao_cat_data_all_with_embeddings.parquet")
df = training_data
X_train, X_test, y_train, y_test = train_test_split(
list(df.embedding.values), df.category, test_size=0.2, random_state=42
)
clf = LogisticRegression()
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
probas = clf.predict_proba(X_test)
report = classification_report(y_test, preds)
print(report)
输出结果:
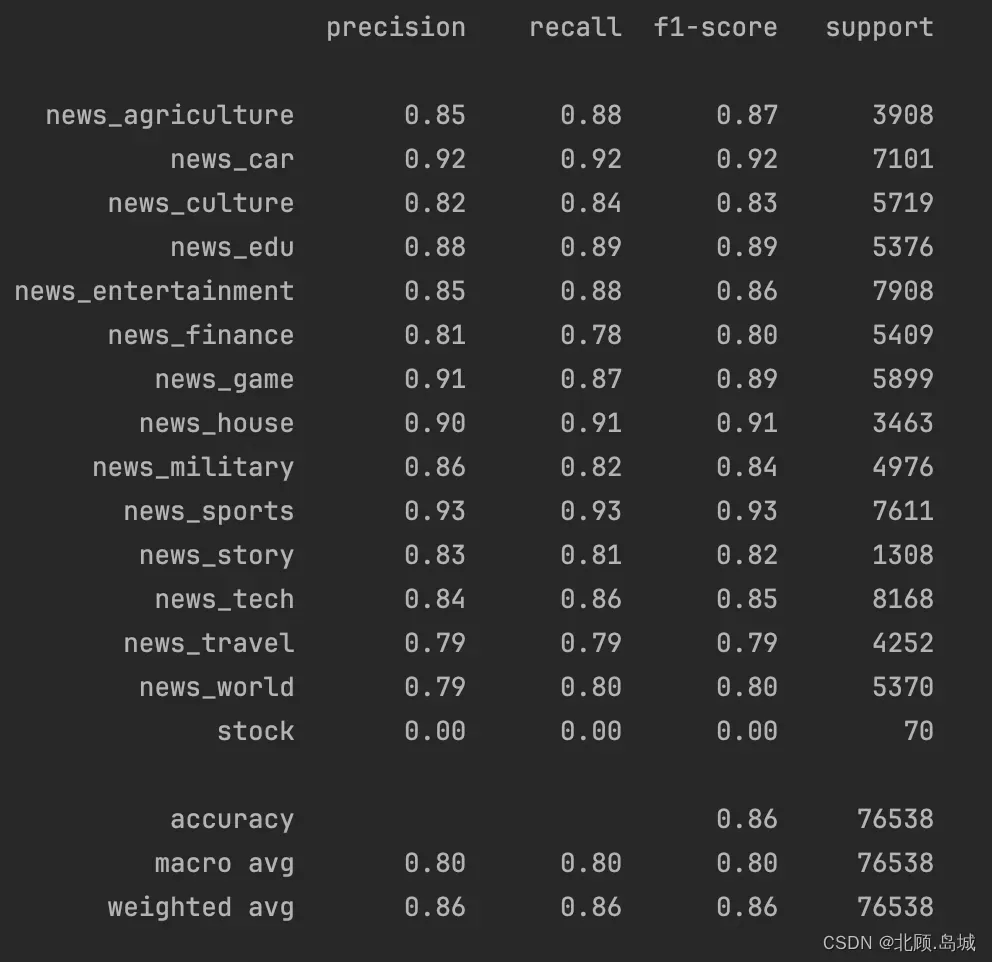
可以看到,通过 OpenAI 的 API 获取到的 Embedding 通过一些简单的线性模型,就能获得很好的分类效果。既不需要提前储备很多自然语言处理的知识,对数据进行大量的分析和清理;也不需要搞一块昂贵的显卡,去使用各类深度学习模型。只要 1~2 个小时,我们就能在一个几十万条文本的数据集上训练出一个非常不错的分类模型。
这个结果已经比我们下载数据集的 GitHub 页面里看到的效果好了,那个的准确率只有约 84%。
下载数据集测试结果地址:链接
5.3 相关指标说明
上面的代码输出的报告的每一行都有四个指标,分别是准确率(Precision)、召回率(Recall)、F1 分数,以及支持样本量(Support)。以上述的新闻标题的数据集为例:
- 准确率,代表模型判定属于这个分类的标题里面判断正确的有多少,有多少真的是属于这个分类的。比如,模型判断里面有 100 个都是农业新闻,但是这 100 个里面其实只有 83 个是农业新闻,那么准确率就是 0.83。
- 召回率,代表模型判定属于这个分类的标题占实际这个分类下所有标题的比例,也就是没有漏掉的比例。比如,模型判断 100 个都是农业新闻,而这 100 个的确都是农业新闻。准确率已经 100% 了。但是,实际一共有 200 条农业新闻。所以有 100 条其实被放到别的类目里面去了,因此在农业新闻这个类目下的召回率,就只有 100/200 = 50%。
- F1 分数,是准确率和召回率的调和平均数,也就是 F1 Score = 2/ (1/Precision + 1/Recall)。模型效果的好坏,既要考虑准确率,又要考虑召回率,综合考虑这两项得出的结果,就是 F1 分数(F1 Score)。当准确率和召回率都是 100% 的时候,F1 分数也是 1。如果准确率是 100%,召回率是 80%,那么算下来 F1 分数就是 0.88。F1 分数也是越高越好。
- 支持的样本量,是指数据里面,实际是这个分类的数据条数有多少。一般来说,数据条数越多,这个分类的训练就会越准确。
报告里一个类目占一行,每一行都包含对应的这四个指标。最下面的三行数据,是整个拿来测试的数据集:
- accuracy 只有一个指标,虽然它在 F1 Score 这个列里,但是并不是 F1 分数的意思。而是说模型总共判断对的分类 / 模型测试的样本数,也就是模型的整体准确率。
- macro average,中文名叫做宏平均,宏平均的三个指标,就是把上面每一个分类算出来的指标加在一起平均一下。它主要是在数据分类不太平衡的时候,帮助我们衡量模型效果怎么样。
宏平均例子:做情感分析时可能 90% 都是正面情感,10% 是负面情感。这个时候预测正面情感效果很好,比如有 90% 的准确率,但是负面情感预测很差,只有 50% 的准确率。如果看整体数据,其实准确率还是非常高的,毕竟负面情感的例子很少。但是我们的目标可能就是找到有负面情绪的客户和他们沟通、赔偿。那么整体准确率对我们就没有什么用了。而宏平均,会把整体的准确率变成 (90%+50%)/2 = 70%。这就不是一个很好的预测结果了,需要进一步优化。宏平均对于数据样本不太平衡,有些类目样本特别少,有些特别多的场景特别有用。
- weighted average 是加权平均,也就是我们把每一个指标,按照分类里面支持的样本量加权,算出来的一个值。无论是 Precision、Recall 还是 F1 Score 都要这么按照各个分类加权平均一下。
5.4 练习:Amazon食物评论数据评分分类
之前用过 Amazon1000 条食物评论的情感分析数据,在那个数据集里其实已经使用过获取到并保存下来的 Embedding 数据了,但是当时把 5 个不同的分数分成了正面、负面和中性,还去掉了相对难以判断的“中性”评价。这里使用 Embedding 结合随机森林和逻辑回归模型训练一个能把从 1 分到 5 分的每一个级别都区分出来的机器学习模型。
随机森林代码示例:
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
datafile_path = "drive/MyDrive/Colab Notebooks/data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(eval).apply(np.array)
X_train, X_test, y_train, y_test = train_test_split(
list(df.embedding.values), df.Score, test_size=0.2, random_state=42
)
clf = RandomForestClassifier(n_estimators=300)
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
probas = clf.predict_proba(X_test)
report = classification_report(y_test, preds)
print(report)
输出结果:
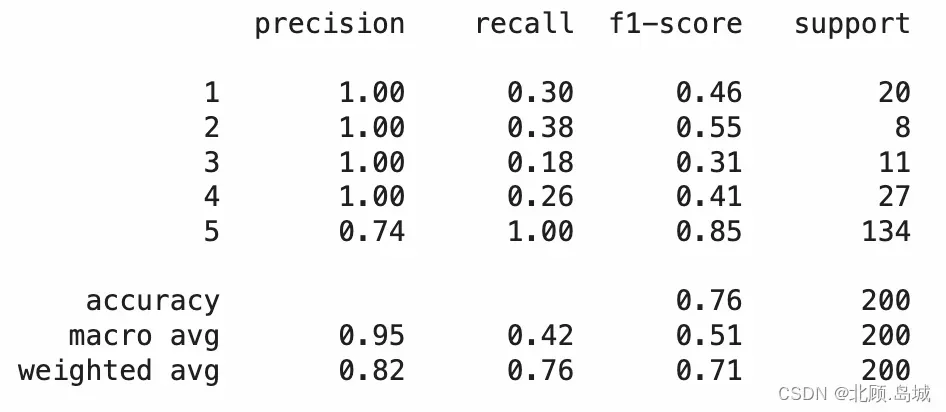
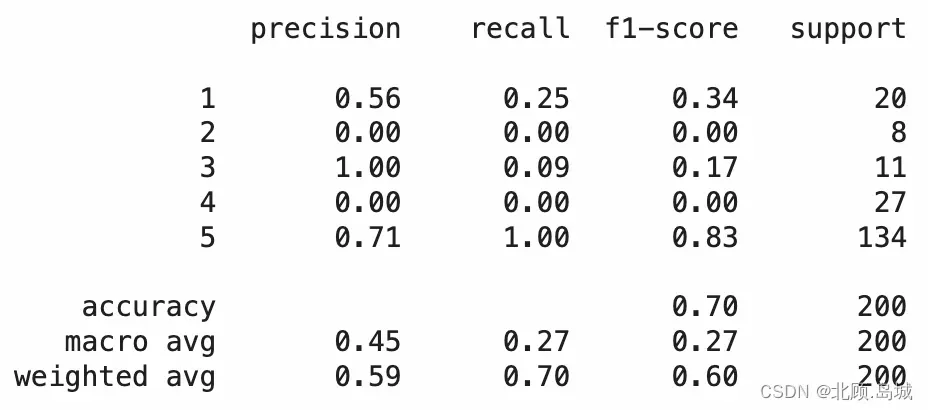
逻辑回归模型代码示例:
from sklearn.linear_model import LogisticRegression
datafile_path = "drive/MyDrive/Colab Notebooks/data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(eval).apply(np.array)
X_train, X_test, y_train, y_test = train_test_split(
list(df.embedding.values), df.Score, test_size=0.2, random_state=42
)
clf = LogisticRegression()
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
probas = clf.predict_proba(X_test)
report = classification_report(y_test, preds)
print(report)
输出结果:
6. Completion进阶(ChatCompletion)——案例:聊天机器人
6.1 对话补全接口——ChatCompletion
from openai import OpenAI
import os
client = OpenAI(
# This is the default and can be omitted
api_key=os.environ["OPENAI_API_KEY"],
)
client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
官网接口文档:链接
该接口需要传入的参数,从一段 Prompt 变成了一个 message 数组,数组的每个元素都有 role 和 content 两个字段。message 参数详细说明:
- message 数组的每个元素都有一个角色 role,role 这个字段一共有三个角色可以选择,其中 system 代表系统,user 代表用户,而 assistant 则代表 AI 的回答。
- 当 role 是 system 的时候,content 里面的内容代表我们给 AI 的一个指令,也就是告诉 AI 应该怎么回答用户的问题。通常,对话首先由 system 消息格式化,然后是交替的user 消息和 assistant 消息。system 消息有助于设置 assistant 的行为。
- 当 role 是 user 或者 assistant 的时候,content 里面的内容就代表用户和 AI 对话的内容。user 消息提供 assistant 响应的请求或评论,assistant 消息存储以前的助理响应。
6.2 应用实例:聊天机器人
6.2.1 封装代码
from openai import OpenAI
import os
client = OpenAI(
# This is the default and can be omitted
api_key=os.environ["OPENAI_API_KEY"],
)
class Conversation:
def __init__(self, prompt, num_of_round):
self.prompt = prompt
self.num_of_round = num_of_round
self.messages = []
self.messages.append({"role": "system", "content": self.prompt})
def ask(self, question):
try:
self.messages.append({"role": "user", "content": question})
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=self.messages,
temperature=0.5,
max_tokens=2048,
top_p=1,
)
except Exception as e:
print(e)
return e
message = response.choices[0].message.content
self.messages.append({"role": "assistant", "content": message})
if len(self.messages) > self.num_of_round*2 + 1:
del self.messages[1:3] # Remove the first round conversation left.
return message
代码说明:
- 上述代码封装了一个 Conversation 类,它的构造函数 init 会接受两个参数,prompt 作为 system 的 content,代表我们对这个聊天机器人的指令,num_of_round 代表每次向 ChatGPT 发起请求的时候,保留过去几轮会话。
- Conversation 类本身只有一个 ask 函数,输入是一个 string 类型的 question,返回结果也是 string 类型的一条 message。
- 每次调用 ask 函数,都会向 ChatGPT 发起一个请求。在这个请求里会把最新的问题拼接到整个对话数组的最后,而在得到 ChatGPT 的回答之后也会把回答拼接上去。如果回答完之后发现会话的轮数超过设置的 num_of_round,就去掉最前面的一轮会话。
测试代码:
prompt = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文
2. 回答限制在100个字以内"""
conv1 = Conversation(prompt, 2)
question1 = "你是谁?"
print("User : %s" % question1)
print("Assistant : %s\n" % conv1.ask(question1))
question2 = "请问鱼香肉丝怎么做?"
print("User : %s" % question2)
print("Assistant : %s\n" % conv1.ask(question2))
question3 = "那蚝油牛肉呢?"
print("User : %s" % question3)
print("Assistant : %s\n" % conv1.ask(question3))
输出:

如果此时我们问它“我问你的第一个问题是什么”,因为我们设置记住的 num_of_round 是 2,所以在上一轮的问题回答完了之后,第一轮的关于“你是谁”的问答已经从 ChatGPT 的对话历史里去掉了。这个时候的第一个问题是“鱼香肉丝怎么做”。
question4 = "我问你的第一个问题是什么?"
print("User : %s" % question4)
print("Assistant : %s\n" % conv1.ask(question4))
输出:

6.2.2 聊天机器人的成本
使用 GPT 时每次都要发送一大段之前的聊天记录给到 OpenAI。这是由 OpenAI 的 GPT-3 系列的大语言模型的原理所决定的。
即使 ChatGPT 的接口是把对话分成了一个数组,但是实际上最终发送给模型的还是拼接到一起的字符串。OpenAI 在它的 Python 库里面提供了一个叫做 ChatML 的格式,它实际做的,就是根据这个定义好特定分隔符的格式,将提供的多轮对话的内容拼接在一起,提交给使用的模型。
ChatML 格式数据示例:
<|im_start|>system
You are ChatGPT, a large language model trained by OpenAI. Answer as concisely as possible.
Knowledge cutoff: 2021-09-01
Current date: 2023-03-01<|im_end|>
<|im_start|>user
How are you<|im_end|>
<|im_start|>assistant
I am doing well!<|im_end|>
<|im_start|>user
How are you now?<|im_end|>
可以看到,在 chatml 的文档里就是通过 <|im_start|>system|user|assistant、<|im_end|> 这些分隔符分割拼装的字符串,可以分析出其中的对话内容。
在使用 ChatGPT 的对话模型时,有一点需要注意,就是在这个需要传送大量上下文的情况下,这个费用会非常高。OpenAI 是通过模型处理的 Token 数量来收费的,但是要注意,这个收费是“双向收费”。它是按照你发送的上下文,加上它返回的内容的总 Token 数来计算花费的 Token 数量的。
6.2.2.1 通过 API 计算 Token 数量
修改一下刚才的代码,ask 函数除了返回回复的消息之外,还会返回这次请求消耗的 Token 数。
class Conversation2:
def __init__(self, prompt, num_of_round):
self.prompt = prompt
self.num_of_round = num_of_round
self.messages = []
self.messages.append({"role": "system", "content": self.prompt})
def ask(self, question):
try:
self.messages.append( {"role": "user", "content": question})
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=self.messages,
temperature=0.5,
max_tokens=2048,
top_p=1,
)
except Exception as e:
print(e)
return e
message = response.choices[0].message.content
num_of_tokens = response.usage.total_tokens
self.messages.append({"role": "assistant", "content": message})
if len(self.messages) > self.num_of_round*2 + 1:
del self.messages[1:3]
return message, num_of_tokens
conv2 = Conversation2(prompt, 2)
questions = [question1, question2, question3, question4]
for question in questions:
answer, num_of_tokens = conv2.ask(question)
print("询问 {%s} 消耗的token数量是 : %d" % (question, num_of_tokens))
输出结果:

可以看到,前几轮的 Token 消耗数量在逐渐增多,但是最后 2 轮是差不多的。这是因为我们只使用过去 2 轮的对话内容向 ChatGPT 发起请求。
6.2.2.1 通过 Tiktoken 库计算 Token 数量
除了上面的方法,也可以使用 Tiktoken 这个 Python 库,将文本分词然后计算 Token 的数量。
不同的 GPT 模型对应着不同的 Tiktoken 的编码器模型。具体情况可以查询:https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
对比代码示例:
import tiktoken
encoding = tiktoken.get_encoding("cl100k_base")
conv2 = Conversation2(prompt, 3)
question1 = "你是谁?"
answer1, num_of_tokens = conv2.ask(question1)
print("总共消耗的token数量是 : %d" % (num_of_tokens))
prompt_count = len(encoding.encode(prompt))
question1_count = len(encoding.encode(question1))
answer1_count = len(encoding.encode(answer1))
total_count = prompt_count + question1_count + answer1_count
print("Prompt消耗 %d Token, 问题消耗 %d Token,回答消耗 %d Token,总共消耗 %d Token" % (prompt_count, question1_count, answer1_count, total_count))
输出结果:

可以看到,我们通过 API 获得消耗的 Token 数与我们通过 Tiktoken 计算得到的总消耗 Token 数有小小的差异。这是因为我们没有计算 OpenAI 去拼接它们内部需要的格式的 Token 数量。
6.2.3 搭建界面(Gradio)
这里使用 Gradio 这个 Python 库来开发聊天机器人的界面的好处如下:
- 无需学习 JavaScript、TypeScript 以及相关的前端框架;
- Gradio 渲染出来的界面可以直接在 Jupyter Notebook 里面显示出来;
- Gradio 已经被目前最大的开源机器学习模型社区 HuggingFace 收购了,可以免费把 Gradio 的应用部署到 HuggingFace 上。
Gradio 官方也有用其他开源预训练模型创建 Chatbot 的教程 https://www.gradio.app/guides/creating-a-chatbot-fast
下载安装 gradio 库:
!pip install gradio
代码逻辑:
- 定义 system 这个系统角色的提示语,创建了一个 Conversation 对象。
- 定义一个 answer 方法,简单封装一下 Conversation 的 ask 方法。主要是通过 history 维护了整个会话的历史记录,并且通过 responses,将用户和 AI 的对话分组,然后将它们两个作为函数的返回值。这个函数的签名是为了符合 Gradio 里 Chatbot 组件的函数签名的需求。
- 通过一段 with 代码,创建对应的聊天界面。Gradio 提供了一个现成的 Chatbot 组件,我们只需要调用它,然后提供一个文本输入框就好了。
代码示例:
import gradio as gr
prompt = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文
2. 回答限制在100个字以内"""
conv = Conversation(prompt, 10)
def answer(question, history=[]):
history.append(question)
response = conv.ask(question)
history.append(response)
responses = list(zip(history[::2], history[1::2]))
return responses, history
with gr.Blocks(css="#chatbot{height:300px} .overflow-y-auto{height:500px}") as demo:
chatbot = gr.Chatbot(elem_id="chatbot")
state = gr.State([])
with gr.Row():
txt = gr.Textbox(container=False, show_label=False, placeholder="Enter text and press enter")
txt.submit(answer, [txt, state], [chatbot, state])
demo.launch()
在 Colab 上执行输出结果:
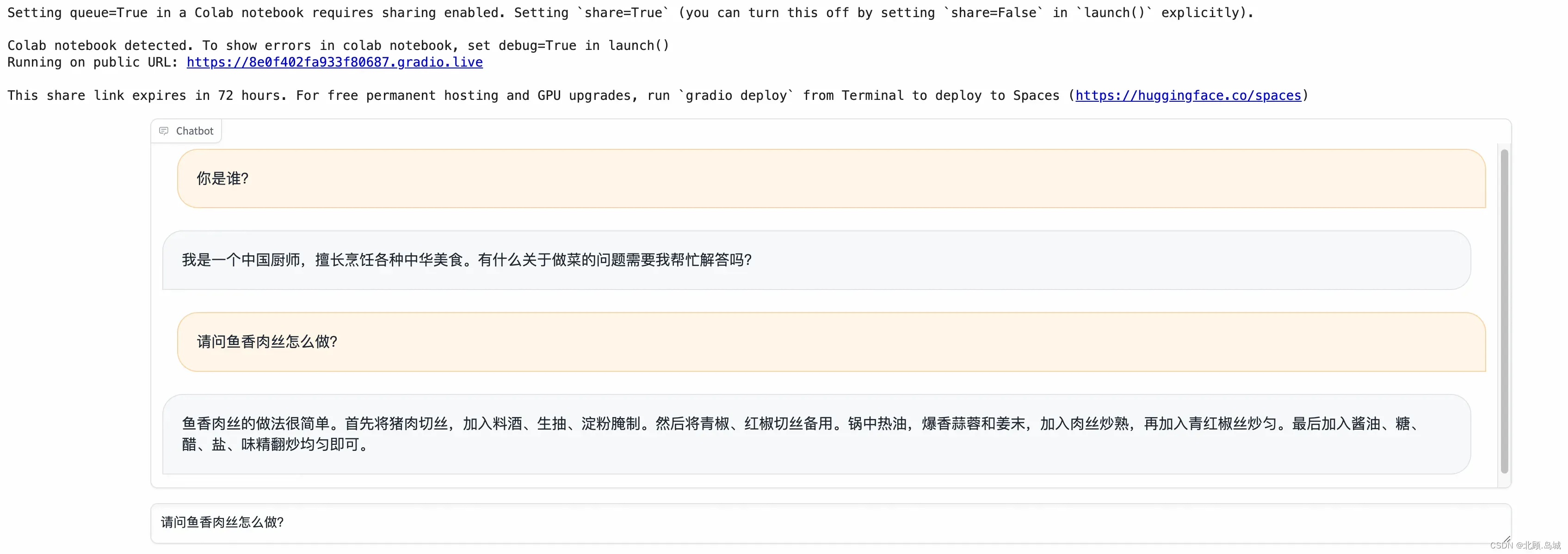
6.2.4 部署发布(HuggingFace)
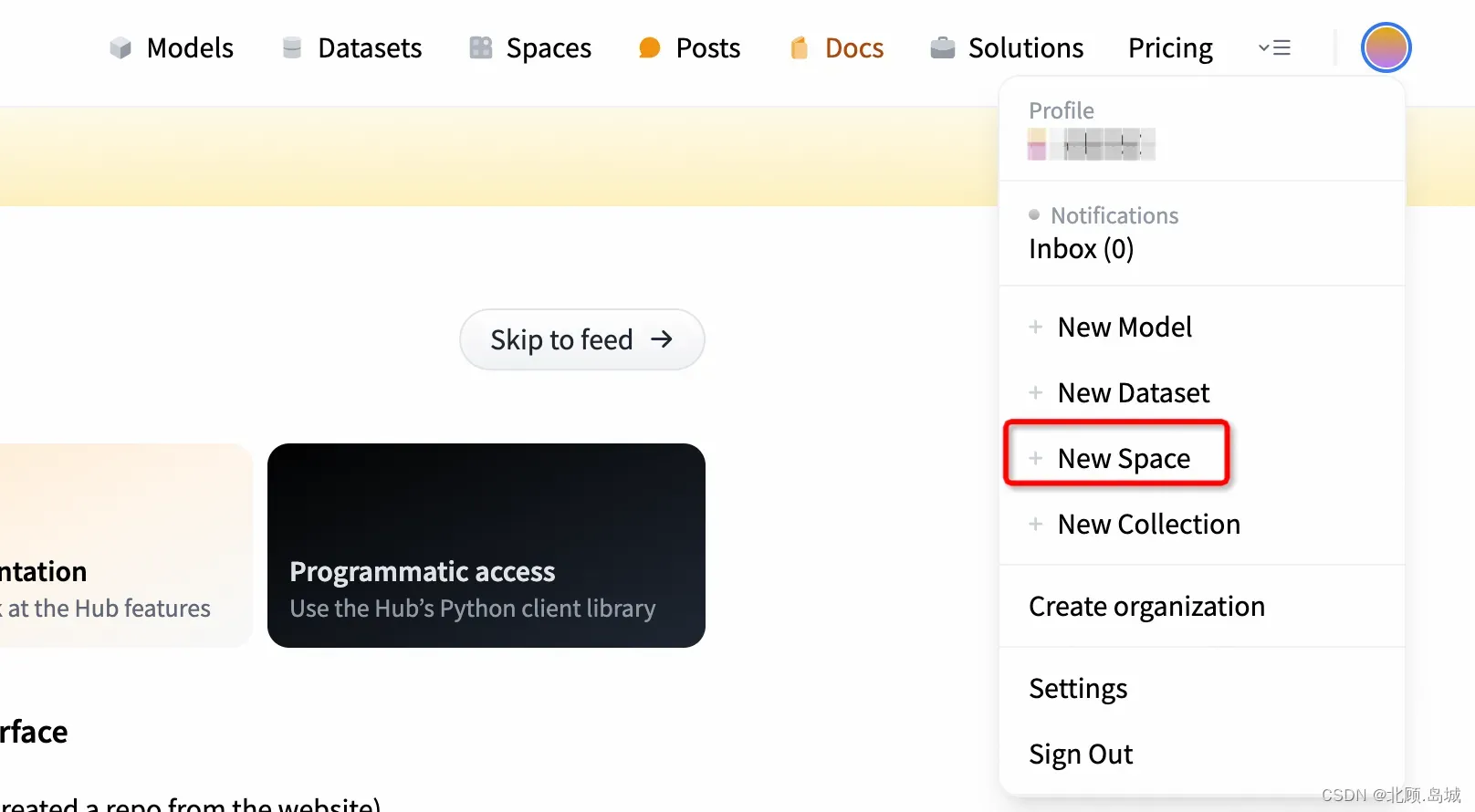
在 HuggingFace 上发布流程如下(地址:链接):
- 注册 HuggingFace 的账号,点击右上角的头像,然后点击 “+New Space” 创建一个新的项目空间。
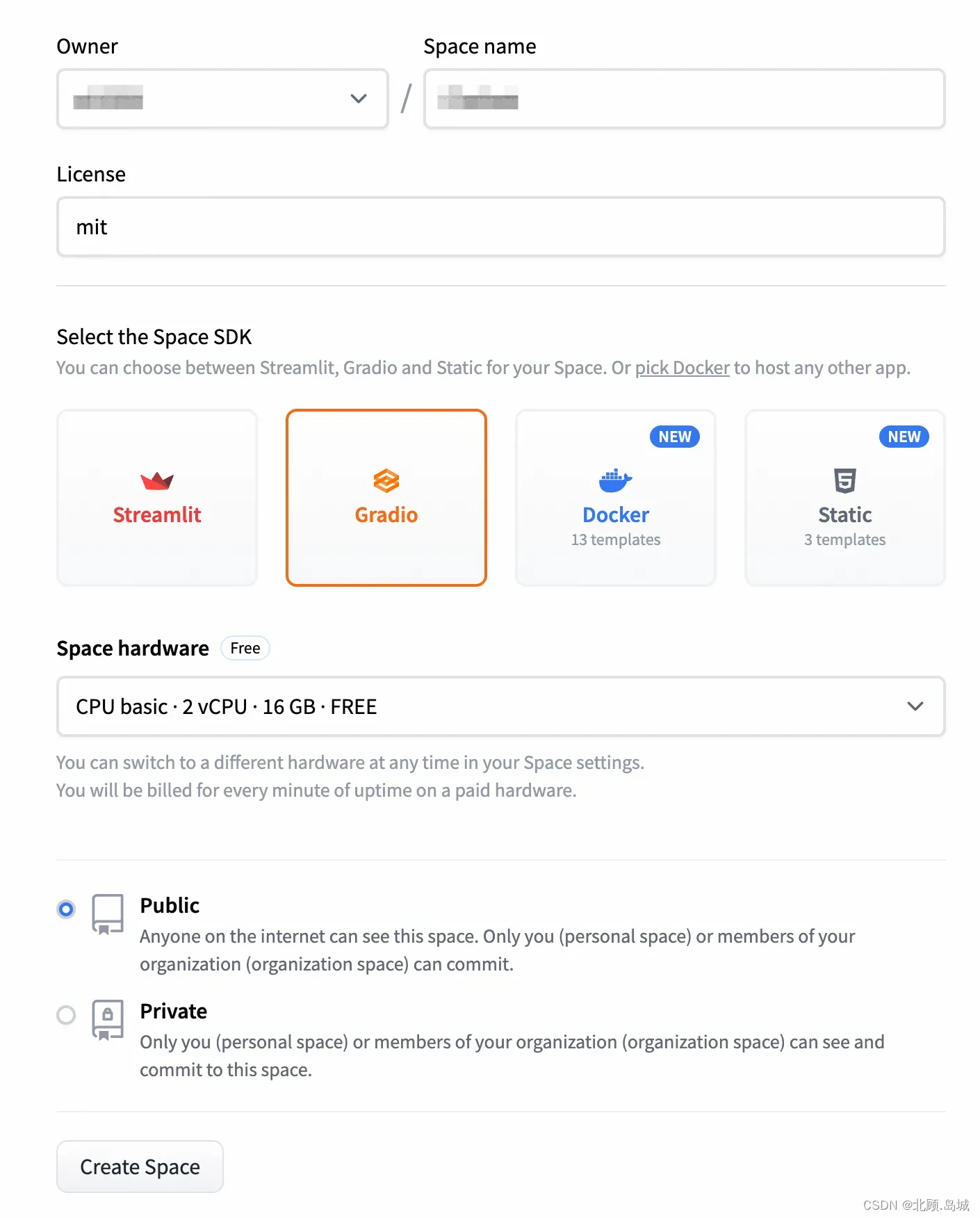
- 选取 Space 名称,然后在 Select the Space SDK 里面选择 Gradio。硬件选择免费的,项目选择 public,让其他人也能够看到。不过要注意,public 的 space 后面上传的代码也能够看到的。
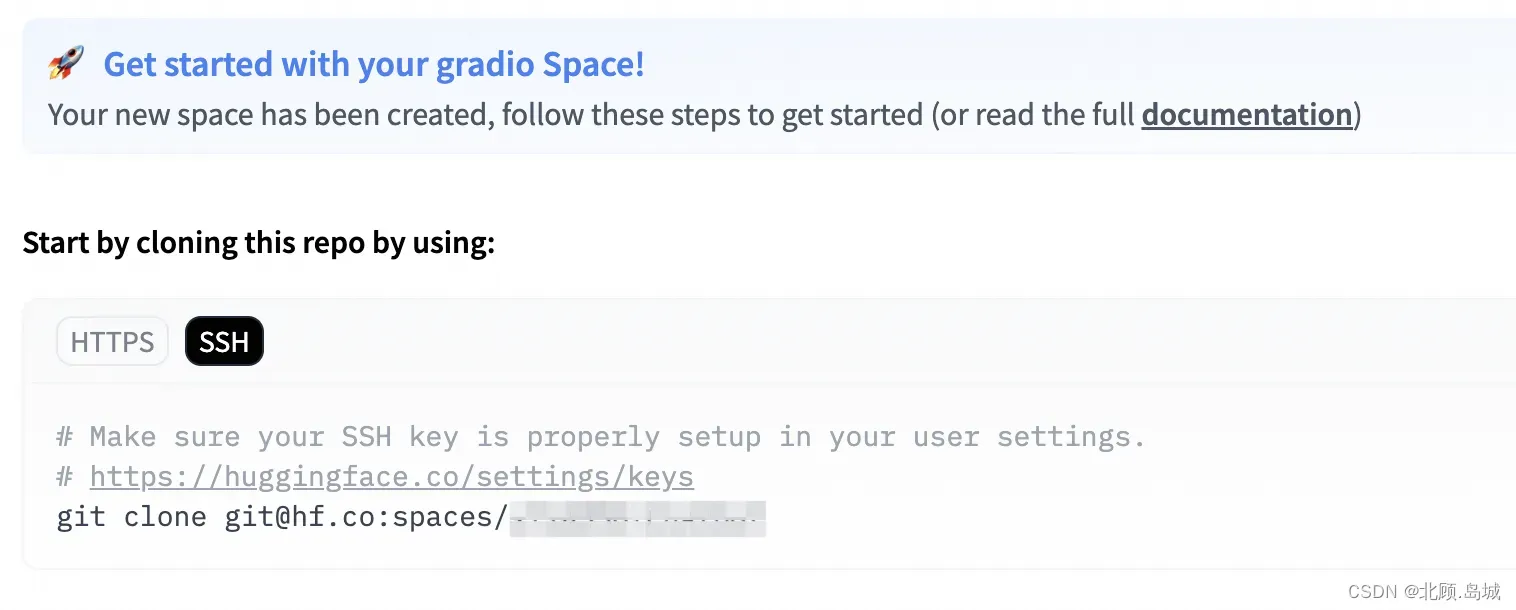
- 创建成功后,会跳转到 HuggingFace 的 App 界面。只需要通过 Git 把当前 space 下载下来,然后提交两个文件就可以了,分别是:
- app.py 包含了我们的 Gradio 应用;
- requirements.txt 包含了这个应用依赖的 Python 包,这里只依赖 OpenAI 这一个包。
app.py 文件内容:
from openai import OpenAI
import gradio as gr
import os
client = OpenAI(
# This is the default and can be omitted
api_key=os.environ["OPENAI_API_KEY"],
)
class Conversation:
def __init__(self, prompt, num_of_round):
self.prompt = prompt
self.num_of_round = num_of_round
self.messages = []
self.messages.append({"role": "system", "content": self.prompt})
def ask(self, question):
try:
self.messages.append({"role": "user", "content": question})
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=self.messages,
temperature=0.5,
max_tokens=2048,
top_p=1,
)
except Exception as e:
print(e)
return e
message = response.choices[0].message.content
self.messages.append({"role": "assistant", "content": message})
if len(self.messages) > self.num_of_round*2 + 1:
del self.messages[1:3] # Remove the first round conversation left.
return message
prompt = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文
2. 回答限制在100个字以内"""
conv = Conversation(prompt, 10)
def answer(question, history=[]):
history.append(question)
response = conv.ask(question)
history.append(response)
responses = list(zip(history[::2], history[1::2]))
return responses, history
with gr.Blocks(css="#chatbot{height:300px} .overflow-y-auto{height:500px}") as demo:
chatbot = gr.Chatbot(elem_id="chatbot")
state = gr.State([])
with gr.Row():
txt = gr.Textbox(container=False, show_label=False, placeholder="Enter text and press enter")
txt.submit(answer, [txt, state], [chatbot, state])
demo.launch()
requirements.txt 文件内容:
openai
代码提交之后,HuggingFace 的页面会自动刷新,可以直接看到对应的日志和 Chatbot 的应用。
注意:git 下载当前 space 时,需要配置相关密钥,这里我使用的是 SSH key 配置。关于 SSH 的配置这里不多赘述。
- 因为代码里是通过环境变量获取 OpenAI 的 API Key 的,所以还要在这个 HuggingFace 的 Space 里设置一下这个环境变量。
- 点击界面里面的 Settings,然后往下找到 Variables and secrets。

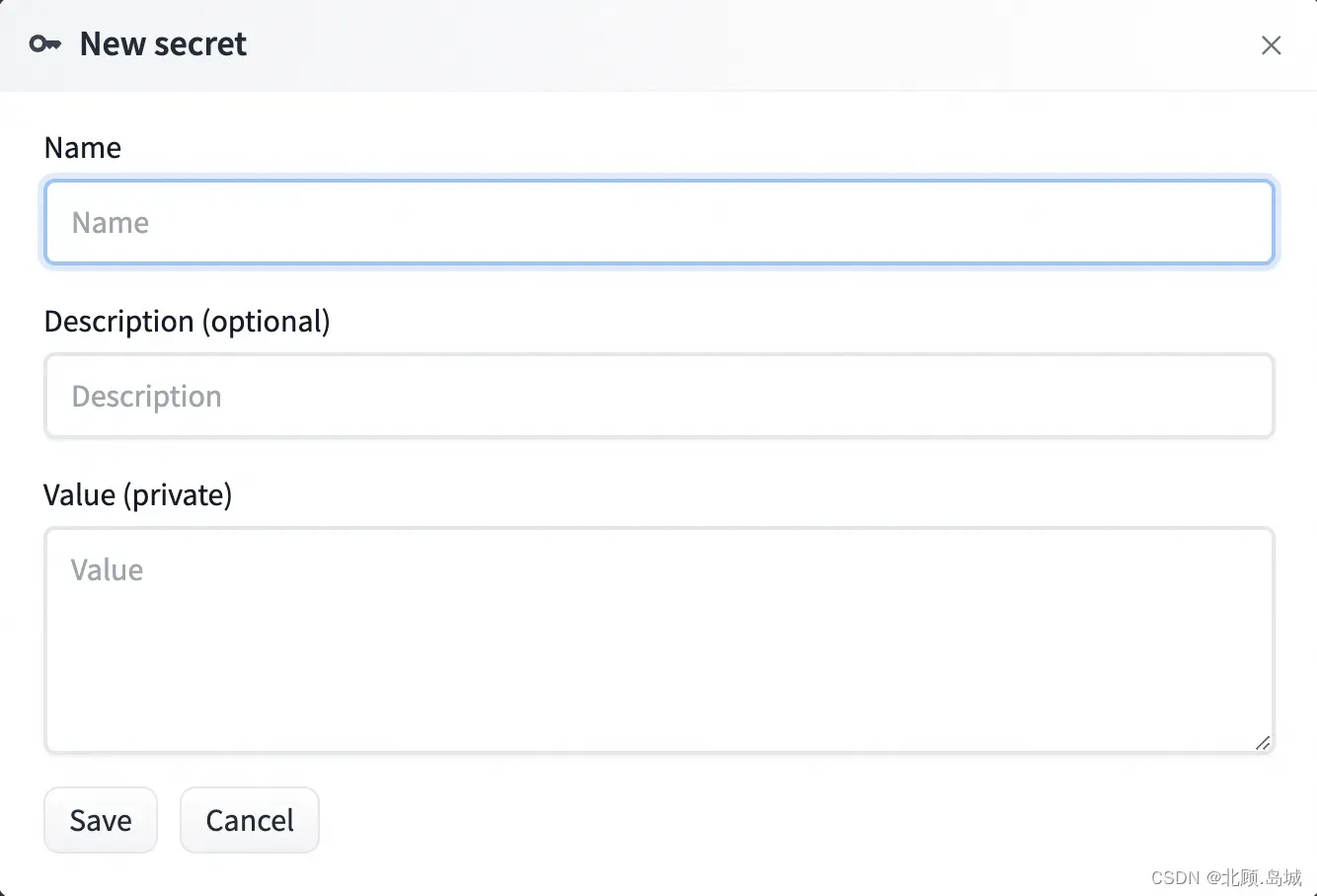
在 Name 这里输入 OPENAI_API_KEY,然后在 Value 里面填入 OpenAI 的密钥。
- 重新点击 App 这个 Tab 页面就可以正常使用了。
6.2.5 练习:限制 Token 数量
针对上面限制轮数的聊天机器人的代码,我们可以改为只限制传入的上下文的 Token 数量,代码如下:
from openai import OpenAI
import os
import tiktoken
client = OpenAI(
# This is the default and can be omitted
api_key=os.environ["OPENAI_API_KEY"],
)
class Conversation:
def __init__(self, prompt, max_num_of_tokens=2048, min_remain_num_of_tokens=256):
self.prompt = prompt
self.max_num_of_tokens = max_num_of_tokens # 模型允许的最大 token 数
self.min_remain_num_of_tokens = min_remain_num_of_tokens # 模型允许的最小剩余 token 数
self.encoding = tiktoken.get_encoding("cl100k_base")
self.messages = []
self.messages.append({"role": "system", "content": self.prompt})
def num_tokens_from_messages(self):
"""Returns the number of tokens used by a list of messages."""
num_tokens = 0
tokens_per_message = 3
for message in self.messages:
num_tokens += tokens_per_message # every message follows <im_start>{role}\n{content}<im_end>\n
for key, value in message.items():
num_tokens += len(self.encoding.encode(value))
num_tokens -= 1
return num_tokens
def ask(self, question):
try:
self.messages.append({"role": "user", "content": question})
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=self.messages,
temperature=0.5,
max_tokens=self.max_num_of_tokens,
top_p=1,
)
except Exception as e:
print(e)
return e
message = response.choices[0].message.content
self.messages.append({"role": "assistant", "content": message})
while self.max_num_of_tokens - self.num_tokens_from_messages() < self.min_remain_num_of_tokens:
del self.messages[1:3] # Remove the first round conversation left.
return message
测试代码如下:
prompt = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文
2. 回答限制在100个字以内"""
conv1 = Conversation(prompt, 512, 64)
question1 = "你是谁?"
print("User : %s" % question1)
print("Assistant : %s\n" % conv1.ask(question1))
question2 = "请问鱼香肉丝怎么做?"
print("User : %s" % question2)
print("Assistant : %s\n" % conv1.ask(question2))
question3 = "那蚝油牛肉呢?"
print("User : %s" % question3)
print("Assistant : %s\n" % conv1.ask(question3))
question4 = "我问你的第一个问题是什么?"
print("User : %s" % question4)
print("Assistant : %s\n" % conv1.ask(question4))
输出结果:

注:除了限制轮数和限制上下文 Token 数之外,还可以通过把上下文进行总结摘要的方式来减少 Token 数量。
7. Embedding 与 Completion 结合——案例:文本聚类与摘要
7.1 基于 Embedding 向量进行文本聚类
文本聚类就是把很多没有标注过的文本,根据它们之间的相似度,自动地分成几类。基于 GPT 系列的模型进行文本聚类很简单,可以通过 Embedding 把文本变成一段向量。然后对于向量可以用一些简单的聚类算法,比如采用最简单的 K-Means 算法。
这里用的数据集是很多老的机器学习教程里常用的 20 newsgroups 数据集,也就是一个带了标注分好类的英文新闻组的数据集。这个数据集不是最自然的自然语言,里面的数据是经过了预处理的,比如去除了标点符号、停用词等等。
数据处理代码逻辑:先把数据下载下来存储成 CSV 文件,然后过滤掉数据里面文本是空的以及 Token 数量太多的情况。
from sklearn.datasets import fetch_20newsgroups
import tiktoken
import pandas as pd
def twenty_newsgroup_to_csv():
newsgroups_train = fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'))
df = pd.DataFrame([newsgroups_train.data, newsgroups_train.target.tolist()]).T
df.columns = ['text', 'target']
targets = pd.DataFrame( newsgroups_train.target_names, columns=['title'])
out = pd.merge(df, targets, left_on='target', right_index=True)
out.to_csv('20_newsgroup.csv', index=False)
twenty_newsgroup_to_csv()
embedding_encoding = "cl100k_base" # this the encoding for text-embedding-ada-002
max_tokens = 8000 # the maximum for text-embedding-ada-002 is 8191
df = pd.read_csv('20_newsgroup.csv')
print("Number of rows before null filtering:", len(df))
df = df[df['text'].isnull() == False]
encoding = tiktoken.get_encoding(embedding_encoding)
df["n_tokens"] = df.text.apply(lambda x: len(encoding.encode(x)))
print("Number of rows before token number filtering:", len(df))
df = df[df.n_tokens <= max_tokens]
print("Number of rows data used:", len(df))
输出结果:

接下来,通过 open ai 的 Embedding 的接口,拿到文本的 Embedding 向量,然后把整个数据存储成 parquet 文件。
import openai, os, backoff
from openai import OpenAI
client = OpenAI(api_key = os.environ["OPENAI_API_KEY"])
embedding_model = "text-embedding-ada-002"
batch_size = 2000
def get_embeddings(list_of_text, model):
response = client.embeddings.create(input=list_of_text, model=model)
return [item.embedding for item in response.data]
@backoff.on_exception(backoff.expo, openai.RateLimitError)
def get_embeddings_with_backoff(prompts, model):
embeddings = []
for i in range(0, len(prompts), batch_size):
batch = prompts[i:i+batch_size]
embeddings += get_embeddings(list_of_text=batch, model=model)
return embeddings
prompts = df.text.tolist()
prompt_batches = [prompts[i:i+batch_size] for i in range(0, len(prompts), batch_size)]
embeddings = []
for batch in prompt_batches:
batch_embeddings = get_embeddings_with_backoff(prompts=batch, model=embedding_model)
embeddings += batch_embeddings
df["embedding"] = embeddings
df.to_parquet("data/20_newsgroup_with_embedding.parquet", index=False)
以下代码比较消耗 Token,你可以不运行。
可以直接下载 embedding 的数据文件,下载代码:
!wget -P data/ https://github.com/xuwenhao/geektime-ai-course/raw/main/data/20_newsgroup_with_embedding.parquet
通常,在做机器学习类的任务的时候,我们往往会把一些中间步骤的数据结果给存下来。这样可以避免在后面步骤写了 Bug 或者参数设错的时候从头开始。这里就把原始数据,以及 Embedding 处理完的数据都存了一份。这样,如果后面的聚类程序要做修改也不需要再花钱让 OpenAI 计算一次 Embedding 了。
用 K-Means 算法来进行聚类的代码逻辑:通过 NumPy 的 stack 函数,把所有的 Embedding 放到一个矩阵里面,设置一下要聚合出来的类的数量,然后运行一下 K-Means 算法的 fit 函数。
因为原本的数据来自 20 个不同的新闻组,那么我们也聚合成 20 个类来评估效果。
import numpy as np
from sklearn.cluster import KMeans
embedding_df = pd.read_parquet("data/20_newsgroup_with_embedding.parquet")
matrix = np.vstack(embedding_df.embedding.values)
num_of_clusters = 20
kmeans = KMeans(n_clusters=num_of_clusters, init="k-means++", n_init=10, random_state=42)
kmeans.fit(matrix)
labels = kmeans.labels_
embedding_df["cluster"] = labels
之后,我们统计一下聚类之后的每个类有多少条各个 newsgroups 分组的数据。然后看看这些数据里面,排名第一的分组是什么。思路如下:
- 通过 groupby 可以把之前的 DataFrame 按照 cluster 进行聚合,统计每个 cluster 里面数据的条数。
- 统计某一个 cluster 里面排名第一的分组名称和数量的时候,我们可以通过 groupby,把数据按照 cluster + title 的方式聚合。
- 再通过 cluster 聚合后,使用 x.nlargest 函数拿到里面数量排名第一的分组的名字和数量。
- 为了方便分析,还把数据里排名第一的去掉之后,又统计了一下排名第二的分组,放在一起看一下。
# 统计每个cluster的数量
new_df = embedding_df.groupby('cluster')['cluster'].count().reset_index(name='count')
# 统计这个cluster里最多的分类的数量
title_count = embedding_df.groupby(['cluster', 'title']).size().reset_index(name='title_count')
first_titles = title_count.groupby('cluster').apply(lambda x: x.nlargest(1, columns=['title_count']))
first_titles = first_titles.reset_index(drop=True)
new_df = pd.merge(new_df, first_titles[['cluster', 'title', 'title_count']], on='cluster', how='left')
new_df = new_df.rename(columns={'title': 'rank1', 'title_count': 'rank1_count'})
# 统计这个cluster里第二多的分类的数量
second_titles = pd.merge(title_count, first_titles, how='left', indicator=True).query('_merge == "left_only"').drop(columns=['_merge'])
second_titles = second_titles.groupby('cluster').apply(lambda x: x.nlargest(1, columns=['title_count']))
second_titles = second_titles.reset_index(drop=True)
new_df = pd.merge(new_df, second_titles[['cluster', 'title', 'title_count']], on='cluster', how='left')
new_df = new_df.rename(columns={'title': 'rank2', 'title_count': 'rank2_count'})
# 将缺失值替换为 0
new_df.fillna(0, inplace=True)
new_df['per_1'] = (new_df['rank1_count'] / new_df['count']).map(lambda x: '{:.2%}'.format(x))
new_df['per_1_2'] = ((new_df['rank1_count'] + new_df['rank2_count'])/ new_df['count']).map(lambda x: '{:.2%}'.format(x))
# 输出结果
from IPython.display import display
display(new_df)
输出结果:
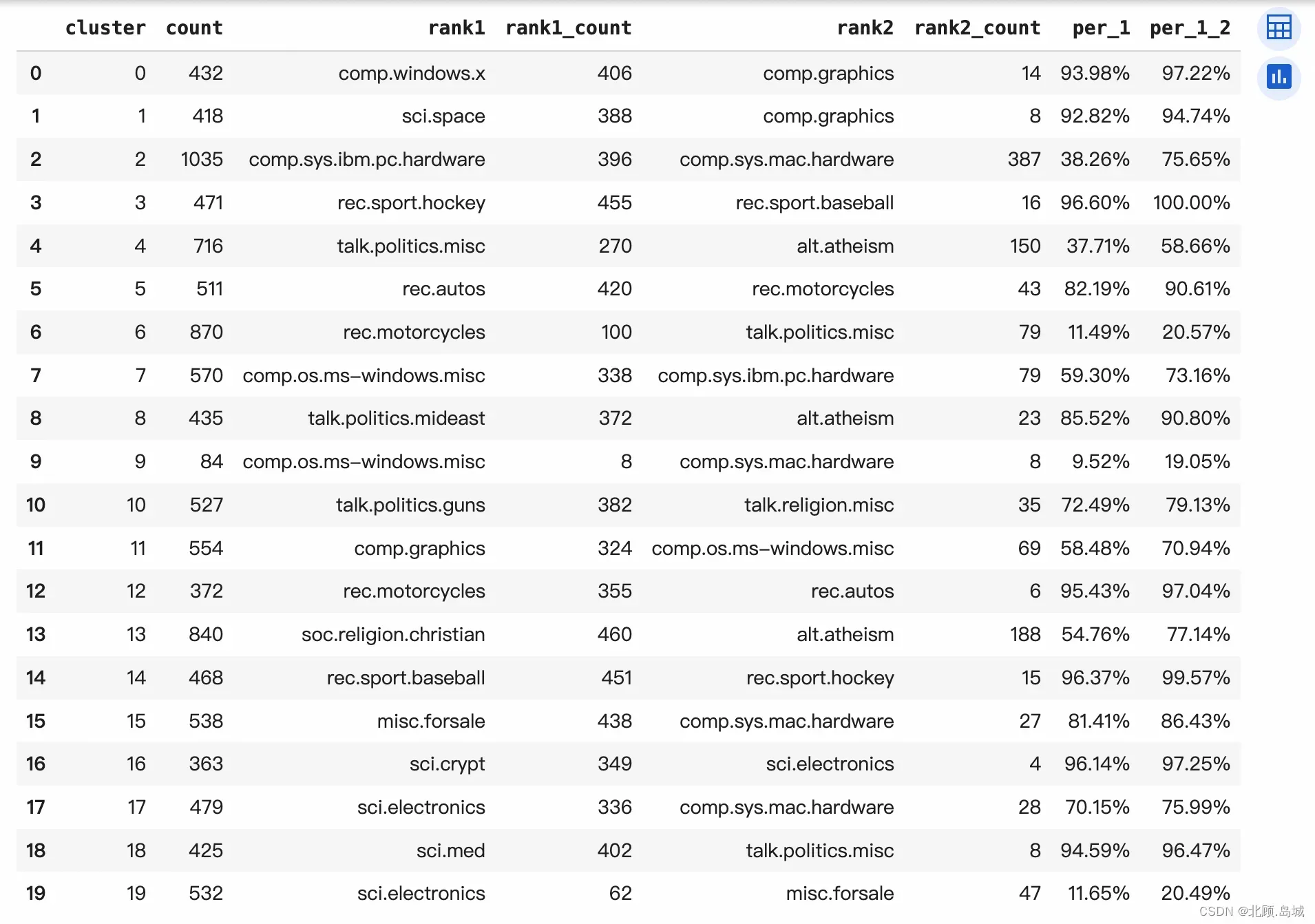
从这个统计数据的结果来看,大部分聚类的结果,能够对应到某一个原本新闻组的分类。
7.2 使用 Prompt 对文本进行总结
对于上面的聚类结果,我们可以随机在每个聚合出来的类里面,挑上 3~5 条,然后请 AI 总结一下该取什么名字,然后再挑一两条文本让 AI 给我们翻译成中文。
代码逻辑:
- 我们随机从聚类结果里的每一个类里面,都挑上 10 条记录,然后分行将这些记录拼在一起。
- 我们给 AI 一段提示语,告诉 AI 这些内容来自新闻组,请 AI 根据它们的共性给这些新闻组的内容取一个 50 个字以内的名字。
- 输出的内容,我们用 Cluster,Cluster 里原先排名第一的分组英文,以及 AI 给出的新闻组名称,对应的输出结果在下面。
代码如下:
from openai import OpenAI
import os
client = OpenAI(api_key = os.environ.get("OPENAI_API_KEY"))
items_per_cluster = 10
COMPLETIONS_MODEL = "gpt-3.5-turbo-instruct"
for i in range(num_of_clusters):
cluster_name = new_df[new_df.cluster == i].iloc[0].rank1
print(f"Cluster {i}, Rank 1: {cluster_name}, Theme:", end=" ")
content = "\n".join(
embedding_df[embedding_df.cluster == i].text.sample(items_per_cluster, random_state=42).values
)
response = client.completions.create(
model=COMPLETIONS_MODEL,
prompt=f'''我们想要给下面的内容,分组成有意义的类别,以便我们可以对其进行总结。请根据下面这些内容的共同点,总结一个50个字以内的新闻组的名称。比如 “PC硬件”\n\n内容:\n"""\n{content}\n"""新闻组名称:''',
temperature=0,
max_tokens=100,
top_p=1,
)
print(response.choices[0].text.replace("\n", ""))
输出结果:

可以看到,机器给出的分类名称大部分是合理的。这里可以挑一些里面的文本内容,看看它们的中文翻译是不是和上面取的名字是一致的。
翻译代码与上述类似,差别如下:
- 在每个分类的抽样数据里只找了 1 条,而不是总结摘要时候选的 10 条。
- 限制了这段文本的 Token 数量不超过 100 个,免得太占地方。
- 输出的内容我们放大了字数到 500 字,确保翻译能提供足够的内容。
items_per_cluster = 1
COMPLETIONS_MODEL = "gpt-3.5-turbo-instruct"
for i in range(num_of_clusters):
cluster_name = new_df[new_df.cluster == i].iloc[0].rank1
print(f"Cluster {i}, Rank 1: {cluster_name}, 抽样翻译:", end=" ")
content = "\n".join(
embedding_df[(embedding_df.cluster == i) & (embedding_df.n_tokens < 100)].text.sample(items_per_cluster, random_state=42).values
)
response = client.completions.create(
model=COMPLETIONS_MODEL,
prompt=f'''请把下面的内容翻译成中文\n\n内容:\n"""\n{content}\n"""翻译:''',
temperature=0,
max_tokens=500,
top_p=1,
)
print(response.choices[0].text.replace("\n", ""))
输出结果:

可以看到,选取的内容和 AI 总结的标题确实较为接近。
7.3 扩展:利用文本摘要支持无限轮数的聊天
前文中的聊天机器人是通过保留一定量对话数或 Token 数来实现的。如果想让 AI 在对话轮数越来越多的时候记住尽量多的上下文,一种方法是将过去几轮的上下文内容,先交给 AI 做一个 100 字的总结。然后,把这个总结也作为对话的 Prompt 信息,告诉 AI 这是聊天的背景,再重新开始新的一轮对话。这个技巧也是使用大语言模型的一种常见模式。
(1)总结聊天记录
代码如下:
history = """User : 你是谁?
Assistant : 我是一个人工智能语言模型,可以回答各种问题,包括做菜的问题。
User : 请问鱼香肉丝怎么做?
Assistant : 鱼香肉丝的做法:
1. 猪里脊肉切丝,加入盐、淀粉、料酒搅拌均匀,腌制10分钟
2. 胡萝卜、青椒、木耳切丝备用
3. 热锅凉油,放入蒜末、姜末煸炒出香味,加入肉丝翻炒至变色
4. 加入胡萝卜、青椒、木耳翻炒,加入酱油、糖、醋、盐、味精、水淀粉搅拌均匀,倒入锅中翻炒均匀即可。
提示:鱼香肉丝的关键是调料的配比,酱油、糖、醋、盐、味精的比例要适合自己的口味。
User : 那蚝油牛肉呢?
Assistant : 蚝油牛肉的做法:
1. 将牛肉切成薄片,加入盐、淀粉、料酒腌制10分钟
2. 葱姜切末,蒜切片,青红椒切丝备用
3. 热锅凉油,放入葱姜末、蒜片煸炒出香味,加入牛肉翻炒至变色
4. 加入蚝油、酱油、糖、水淀粉调味,加入青红椒翻炒均匀即可。
提示:蚝油牛肉的关键是牛肉要切薄,翻炒时火候要快,保证牛肉口感鲜嫩。调味时,蚝油和酱油的比例也要适合自己的口味。
"""
def summarize(text, max_tokens=200):
response = client.completions.create(
model=COMPLETIONS_MODEL,
prompt=text + "\n\n请总结一下上面User和Assistant聊了些什么:\n",
max_tokens=max_tokens,
)
return response.choices[0].text
summarized = summarize(history)
print(summarized)
输出结果:

(2)继续对话
这里使用了之前的 Conversation 类的代码,将之前的几轮对话的内容总结了一下,放在 Prompt 的最前面,然后让 AI 根据已经聊了的内容,继续往下聊。
代码如下:
prompt = summarized + "\n\n请你根据已经聊了的内容,继续对话:"
conversation = Conversation(prompt, 5)
question = "那宫保鸡丁呢?"
answer = conversation.ask(question)
print("User : %s" % question)
print("Assistant : %s\n" % answer)
输出结果:

而如果没有加上 AI 总结的之前的对话,只是让 AI 对话,它会和你聊一些其他的内容。
conversation = Conversation("请你根据已经聊了的内容,继续对话:", 5)
question = "那宫保鸡丁呢?"
answer = conversation.ask(question)
print("User : %s" % question)
print("Assistant : %s\n" % answer)
输出结果:

8. 其余接口与模型——案例:文本改写和内容审核
8.1 文本改写
8.1.1 选用适当提示语
OpenAI 的 GPT 的系列模型是一个生成式的模型,也就是它的用法是你给它一段文字,然后它补全后面的文字。按理来说是没法让它修改一段内容的,但是可以通过一段提示语来解决这个问题。
代码如下:
from openai import OpenAI
import os
client = OpenAI(api_key = os.environ.get("OPENAI_API_KEY"))
def make_text_short(text):
messages = []
messages.append( {"role": "system", "content": "你是一个用来将文本改写得短的AI助手,用户输入一段文本,你给出一段意思相同,但是短小精悍的结果"})
messages.append( {"role": "user", "content": text})
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
temperature=0.5,
max_tokens=2048,
presence_penalty=0,
frequency_penalty=2,
n=3,
)
return response
long_text = """
在这个快节奏的现代社会中,我们每个人都面临着各种各样的挑战和困难。
在这些挑战和困难中,有些是由外部因素引起的,例如经济萧条、全球变暖和自然灾害等。
还有一些是由内部因素引起的,例如情感问题、健康问题和自我怀疑等。
面对这些挑战和困难,我们需要采取积极的态度和行动来克服它们。
这意味着我们必须具备坚韧不拔的意志和创造性思维,以及寻求外部支持的能力。
只有这样,我们才能真正地实现自己的潜力并取得成功。
"""
short_version = make_text_short(long_text)
index = 1
for choice in short_version.choices:
print(f"version {index}: " + choice.message.content)
index += 1
输出结果:

上述代码中使用的参数也有以下几个调整:
- 使用了 n=3 这个参数,也就是让 AI 返回 3 个答案供我们选择。在文本改写类的应用里面,通常不只是直接给出答案,而是会给用户几个选项来选择。
- 引入了两个参数 presence_penalty=0 以及 frequency_penalty=2,它们和 temperature 参数类似,都是来控制输出内容的。
a. presence_penalty,指的是如果一个 Token 在前面的内容已经出现过了,那么在后面生成的时候给它的概率一定的惩罚。这样,AI 就会倾向于聊新的话题和内容。在这里,我们把它设置成了默认值 0。
b. frequency_penalty,指的是对于重复出现的 Token 进行概率惩罚。这样,AI 就会尽量使用不同的表述。在这里我们设成了最大的 2,你也可以设置成最小的 -2。但是那样的话,它就更容易一样的话了。
8.1.2 精确控制生成内容(logit_bias 参数)
如果我们想要在上面生成的内容里面,不允许出现灾害两个字,实现的代码如下:
import tiktoken
encoding = tiktoken.get_encoding('cl100k_base')
token_ids = encoding.encode("灾害")
print(token_ids)
bias_map = {}
for token_id in token_ids:
bias_map[token_id] = -100
def make_text_short(text):
messages = []
messages.append( {"role": "system", "content": "你是一个用来将文本改写得短的AI助手,用户输入一段文本,你给出一段意思相同,但是短小精悍的结果"})
messages.append( {"role": "user", "content": text})
response = client.chat.completions.create(
model="gpt-3.5-turbo", messages=messages, temperature=0.5, max_tokens=2048,
n=3, presence_penalty=0, frequency_penalty=2,
logit_bias = bias_map,
)
return response
short_version = make_text_short(long_text)
index = 1
for choice in short_version.choices:
print(f"version {index}: " + choice.message.content)
index += 1
输出结果:

上述代码中:
- 通过之前使用过的 Tiktoken 库,找到不希望出现的“灾害”这个词对应的 Token,然后给它们都赋了一个 -100 的 bias。
- 把整个的 bias_map 作为参数,传给了 Completion 的 logit_bias 参数。
可以看到,三个回复中都已经没有“灾害”这两个字了。
logit_bias 参数是修改指定 token 出现在补全中的可能性,它的取值范围在 -100 到 100 之间。一般情况下,设置在 1 到 -1 之间就足够了。如果设置成 100 则表示一定要某些字出现,那么整个生成可能会慢到无法忍受。
8.1.3 使用英文减少 Token 的使用
上例中虽然灾害只有两个中文汉字,但是通过 Tiktoken 去处理的时候打印了 4 个 token 的id,表明实际上有 4 个 token。事实上,同样含义的中文,目前消耗的 Token 数量是比英文多的。这里可以把上面的一句话翻译成英文,然后数一下对应同样内容的中英文的 Token 数。
代码如下:
def translate(text):
messages = []
messages.append( {"role": "system", "content": "你是一个翻译,把用户的话翻译成英文"})
messages.append( {"role": "user", "content": text})
response = client.chat.completions.create(
model="gpt-3.5-turbo", messages=messages, temperature=0.5, max_tokens=2048, n=1
)
return response.choices[0].message.content
chinese = long_text
english = translate(chinese)
num_of_tokens_in_chinese = len(encoding.encode(chinese))
num_of_tokens_in_english = len(encoding.encode(english))
print(english)
print(f"chinese: {num_of_tokens_in_chinese} tokens")
print(f"english: {num_of_tokens_in_english} tokens")
输出结果:

可以看到,同样的内容,中文消耗的 Token 数量超过 200,而英文的 Token 数量只有 100 出头。如果在生产环境中使用 OpenAI 的接口,最好还是使用英文的提示语,最多在输出结果的时候,告诉它 “generate Chinese” 之类的,可以极大地节约成本。
8.1.4 练习:文本改写应用
参考上使用 gradio 搭建的聊天机器人,我将这里的文本改写代码和上面的 gradio 实现的聊天机器人代码输入给 gpt,让他帮我使用 gradio 实现一个类似的文本改写应用,gpt 输出的代码如下:
from openai import OpenAI
import gradio as gr
import os
# 初始化OpenAI客户端
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
# 定义文本改写函数
def make_text_short(text):
messages = []
messages.append({"role": "system", "content": "你是一个用来将文本改写得短的AI助手,用户输入一段文本,你给出一段意思相同,但是短小精悍的结果"})
messages.append({"role": "user", "content": text})
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
temperature=0.5,
max_tokens=2048,
presence_penalty=0,
frequency_penalty=2,
)
# 选择第一个改写的版本,你也可以选择其他的或者让用户选择
short_text = response.choices[0].message.content
return short_text
# 使用Gradio创建界面
def gradio_interface():
# 创建一个文本输入框
input_text = gr.Textbox(label="请输入一段长文本", placeholder="请在这里输入文本...")
# 创建一个按钮,用户点击后会触发文本改写
output_text = gr.Textbox(label="改写后的文本")
# 将输入框、按钮、输出框组合成一个界面
interface = gr.Interface(
fn=make_text_short, # 绑定文本改写函数
inputs=input_text, # 设置输入组件
outputs=output_text # 设置输出组件
)
# 启动界面
interface.launch()
# 调用函数以显示界面
gradio_interface()
输出结果:

可以看到,gpt 不仅理解了我们给定的输入命令,还给出了直接可以运行的代码,这里我直接使用 gpt 给出的代码并且没有做任何改动,输出结果已经基本满足了我们的需求。
8.2 OpenAI 模型
8.2.1 模型介绍
OpenAI 的产品更新非常快,所以很可能会出现一个问题,现在使用的某个模型可能很快就不是效果最好或者最新的了。所以,较好的方式还是通过它提供的接口查询它到底有哪些模型。
代码如下:
from openai import OpenAI
import os
import pandas as pd
client = OpenAI(api_key = os.environ.get("OPENAI_API_KEY"))
# list all open ai models
models = client.models.list()
pd = pd.DataFrame(map(dict, client.models.list().data))
display(pd[['id', 'owned_by']])
输出结果:

可以看到,当我写下这篇文章时,输出结果里有20个模型。
输出里没有 gpt-4 的模型可能是因为我的账号只开通了 gpt-3.5 的服务。
详细的模型分类及介绍可参考官网:链接,实际中主要使用的模型分为下面几类:
- GPT-4 家族的模型,其中带日期的模型表示是一个模型快照,也就是模型不会随着时间迁移不断更新。GPT-4 的模型现在还很昂贵,但是准确率较高。
- GPT-3.5 家族的模型。
- 基于 GPT 的基础模型,只适合用于下达单轮的指令,不适合考虑复杂的上下文和进行逻辑推理。如果要微调一个属于自己的模型,可以基于基础模型。
- Embeddings 类模型,一般用来获取 Embedding,再用在其他的机器学习模型的训练,或者语义相似度的比较上。
可以选择几个 Embedding 模型看一下 Embedding 的维度数,感受不同模型的尺寸大小。
代码如下:
from openai import OpenAI
import os
client = OpenAI(api_key = os.environ.get("OPENAI_API_KEY"))
def get_embedding(text, model):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
text = "让我们来算算Embedding"
embedding_ada = get_embedding(text, model="text-embedding-ada-002")
print("embedding-ada: ", len(embedding_ada))
embedding_small = get_embedding(text, model="text-embedding-3-small")
print("embedding_small: ", len(embedding_small))
embedding_large = get_embedding(text, model="text-embedding-3-large")
print("embedding_large: ", len(embedding_large))
输出结果:

8.2.2 特殊模型 gpt-3.5-turbo-instruct ——插入文本内容
gpt-3.5-turbo-instruct 这个模型有个特殊的功能,就是“插入文本”(Inserting Text)。
代码示例:
prefix = """在这个快节奏的现代社会中,我们每个人都面临着各种各样的挑战和困难。
在这些挑战和困难中,有些是由外部因素引起的,例如经济萧条、全球变暖和自然灾害等。\n"""
# 还有一些是由内部因素引起的,例如情感问题、健康问题和自我怀疑等。
suffix = """\n面对这些挑战和困难,我们需要采取积极的态度和行动来克服它们。
这意味着我们必须具备坚韧不拔的意志和创造性思维,以及寻求外部支持的能力。
只有这样,我们才能真正地实现自己的潜力并取得成功。"""
def insert_text(prefix, suffix):
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prefix,
suffix=suffix,
max_tokens=1024,
)
return response
response = insert_text(prefix, suffix)
print(response.choices[0].text)
输出结果:

这里使用了 prompt 参数作为前缀输入,suffix 参数作为后缀。
注意:suffix 参数仅支持 gpt-3.5-turbo-instruct 模型
插入内容时同样需要注意提示语。比如把上面的内容稍微修改,比如去掉 Suffix 一开始的换行符号,插入的文本内容可能就会在我们的预期之外。
prefix = """在这个快节奏的现代社会中,我们每个人都面临着各种各样的挑战和困难。
在这些挑战和困难中,有些是由外部因素引起的,例如经济萧条、全球变暖和自然灾害等。\n"""
# 还有一些是由内部因素引起的,例如情感问题、健康问题和自我怀疑等。
suffix = """面对这些挑战和困难,我们需要采取积极的态度和行动来克服它们。
这意味着我们必须具备坚韧不拔的意志和创造性思维,以及寻求外部支持的能力。
只有这样,我们才能真正地实现自己的潜力并取得成功。"""
response = insert_text(prefix, suffix)
print(response.choices[0].text)
输出结果:

可以看到,输出结果中最后一句不是个完整的句子,而是下句话开头的内容。所以,在使用这种插入文本内容方式的时候,需要考虑好文本之间需要使用什么样的分隔符。
8.3 Moderate 接口——内容审核
因为 OpenAI 可以接受任何自然语言的输入,所有的回复也是通过模型自动生成的。一旦我们的产品依赖于它对外开放,免不了会遇到一些用户输入一些奇怪的内容,比如色情、暴力等等。所以,OpenAI 专门提供了一个免费的 moderate 接口,可以对输入以及返回的内容做检查。如果出现了这样的内容,可以屏蔽这些用户的访问,也可以人工审核一下用户的问题。
代码示例:
from openai import OpenAI
import os
client = OpenAI(api_key = os.environ.get("OPENAI_API_KEY"))
def chatgpt(text):
messages = []
messages.append( {"role": "system", "content": "You are a useful AI assistant"})
messages.append( {"role": "user", "content": text})
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
temperature=0.5,
max_tokens=2048,
top_p=1,
)
message = response.choices[0].message.content
return message
threaten = "你不听我的我就拿刀砍死你"
print(chatgpt(threaten))
输出结果:

可以看到,这里的返回并不是一个日常的对话,而是告知用户,不会回应暴力言论。
把这句话发送到 moderate 的接口看下效果:
threaten = "你不听我的我就拿刀砍死你"
def moderation(text):
response = client.moderations.create(
input=text
)
output = response.results[0]
return output
print(moderation(threaten))
输出结果:
Moderation(
categories=Categories(
harassment=True,
harassment_threatening=True,
hate=False,
hate_threatening=False,
self_harm=False,
self_harm_instructions=False,
self_harm_intent=False,
sexual=False,
sexual_minors=False,
violence=True,
violence_graphic=False,
self-harm=False,
sexual/minors=False,
hate/threatening=False,
violence/graphic=False,
self-harm/intent=False,
self-harm/instructions=False,
harassment/threatening=True),
category_scores=CategoryScores(
harassment=0.8074951171875,
harassment_threatening=0.7048851251602173,
hate=0.0002112001966452226,
hate_threatening=0.00012546319339890033,
self_harm=0.023437051102519035,
self_harm_instructions=0.0010424336651340127,
self_harm_intent=0.016719607636332512,
sexual=0.0001093030659831129,
sexual_minors=1.7262211713386932e-06,
violence=0.9991868138313293,
violence_graphic=0.008071725256741047,
self-harm=0.023437051102519035,
sexual/minors=1.7262211713386932e-06,
hate/threatening=0.00012546319339890033,
violence/graphic=0.008071725256741047,
self-harm/intent=0.016719607636332512,
self-harm/instructions=0.0010424336651340127,
harassment/threatening=0.7048851251602173),
flagged=True)
可以看到,moderate 接口返回内容包含是否应该对输入的内容进行标记的 flag 字段,也包括具体是什么类型的问题的 categories 字段,以及对应每个 categories 的分数的 category_scores 字段。这里我们的输入文本就被标记成了 violence,也就是暴力。
因为这个接口是免费的,所以所有的内容无论是输入还是输出,都可以去调用一下这个接口。而且,即使不使用 ChatGPT 的 AI 功能,只是经营一个在线网站,也可以把用户发送的内容发给这个接口,过滤掉那些不合适的内容。
版权声明:本文为博主作者:北顾.岛城原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/zhuiyisinian/article/details/136481608