背景:
- 随着软件系统复杂性的增加,有效测试⽅法的需求也在上升。传统的测试⽤例⽣成⽅法通常⽆法满⾜快速开发周期和复杂代码库的需求
- 开发人员使用生成式人工智能可以以两倍的速度完成编码任务,这可能意味着生成的代码量将会相应增加。这意味着 QA 工程师必须提高测试和验证代码是否存在安全漏洞的能力。生产更多代码,意味着需要更多测试
- 自动化可以帮助 QA 工程师提高生产力并增加测试覆盖率,但生成式 AI 能否创建具有业务意义的测试场景并降低风险仍是一个悬而未决的问题。
- 虽然生成式人工智能和测试自动化可以帮助创建测试脚本,但拥有了解测试内容的才能和主题专业知识将变得更加重要,这也是质量保证工程师越来越重要的责任。随着生成式人工智能的测试生成能力不断提高,它将迫使 QA 工程师向左侧移动,以便更好地进行测试。
- 敏捷开发团队除了寻求和验证生产率和测试覆盖率之外,还能在哪些方面寻求和验证生成式人工智能的能力?一个重要的衡量标准是,生成式人工智能能否更快地发现缺陷和其他编码问题,以便开发人员在它们阻碍 CI/CD 管道或导致生产问题之前加以解决。生成式 AI 集成到 CI/CD 管道中,可确保一致且快速的测试,并提供有关代码更改的快速反馈,
- 可以增加测试用例的数量并更快地发现问题,团队也应该使用生成式人工智能来提高测试场景的有效性。人工智能可以通过扩大每个测试场景的测试范围并提高其准确性来持续维护和改进测试。生成式 AI 通过自适应学习、根据实时应用程序变化自动演化测试场景
- 技术更替:确保轻松更换模型、提示和测量,而无需完全重写软件,从而确保他们的策略延用到更高效率的model,我们只需要修改代码路径、拼接方式简单的代码既可以继承上个model场景
名词解释:
一、什么是LLM Agent
1、定义:LLM 代理是一种人工智能系统,它利用大型语言模型 (LLM) 作为其核心计算引擎,展示文本生成之外的功能,包括进行对话、完成任务、推理,并可以展示一定程度的自主行为。
2、LLM Agent是通过prompt工程控制agent的响应和回复的。prompt中会设计角色、指令、权限、对上下文的响应和回复等。
3、LLM Agent根据设计阶段授予的功能,agent从纯粹的被动到高度主动的自主行为。
4、足够的(提示)prompt+知识。agent从对话式聊天机器人到实现:目标驱动工作流程和任务自动化。
举例: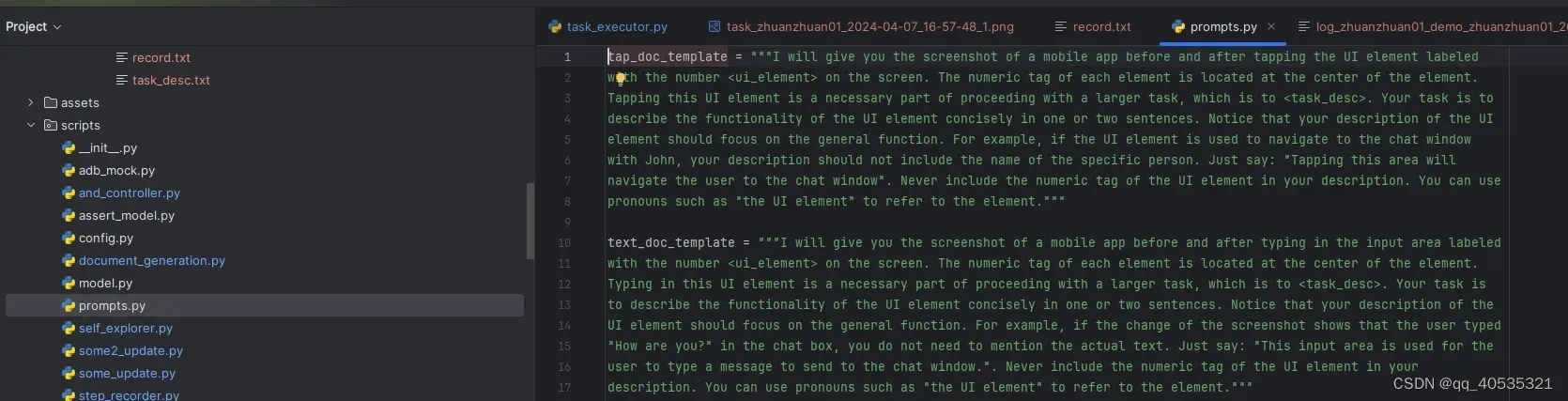
5、大模型的推理能力,让agent可以在人工监督下管理相对独立的工作流程:分析目标,项目规划,执行,回顾过去的工作,迭代细化。
6、精心设计的prompt可以实现无缝的人机协作。
二、LLM Agent的关键能力
1、Agent利用LLM的语言能力理解指令、上下文和目标。可以根据人类提示自主和半自主操作。
2、可以利用工具套件(计算器、API、搜索引擎)来收集信息并采取行动来完成分配的任务。它们不仅仅局限于语言处理,比如公司承接openai的gpt-4-vision,支持图片(Url、base64)的理解
3、可以做逻辑推理类型的任务。例如,chain-of-thought , tree-of-thought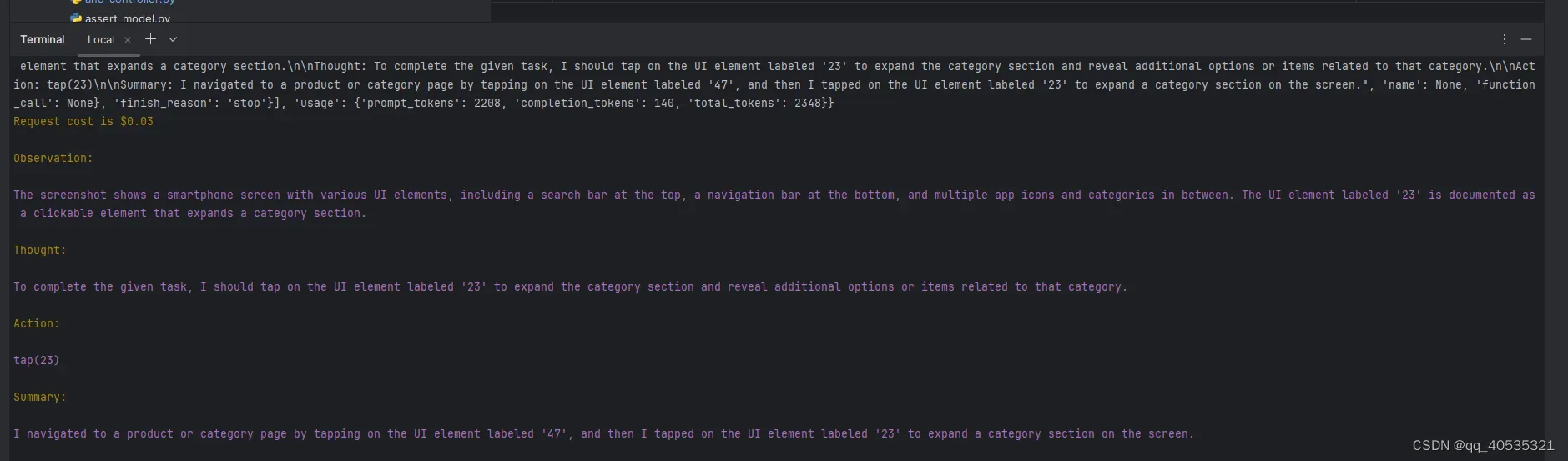
这些逻辑能力配置很简单,取决于你对gpt能力的描述精准度
4、可以量身定制文本:邮件,报告,市场材料,、可以定制视频、音频、PPT、、数据报表、机器人等 几乎大部分人类的工作能力,预期取决于 GPT的反馈速度 和model的代码配置 (思考敏捷 手脚健全)
5、可以自动或半自动的响应用户的需求。(取决于任务配置,比如是否自动执行CI/CD,stage changed,commit等)
6、Agent可以和不同类型的AI系统对接,例如LLM+image generators。换个好使的GPT 对model改动不大
三、人工智能prompt剖析 (一个高效率模型,prompt就是他的思维方式和执行能力)
task任务:任务定义人工智能的预期输出或目标。这可以是回答问题、生成图像或生成创意内容。明确说明任务有助于人工智能系统集中注意力。
instructions指令:指令为人工智能提供如何执行任务的具体指示。这包括所需的输出属性、格式、内容要求和任何约束。指令充当指导人工智能的规则。
context上下文:上下文提供了定位任务的背景信息。示例、图像和其他种子让人工智能模型了解预期的响应。上下文充当灵活的指导而不是严格的规则。
parameters参数:参数是改变 AI 如何处理提示的配置。这包括影响输出的创造性和随机性的温度和 top-p 等设置。
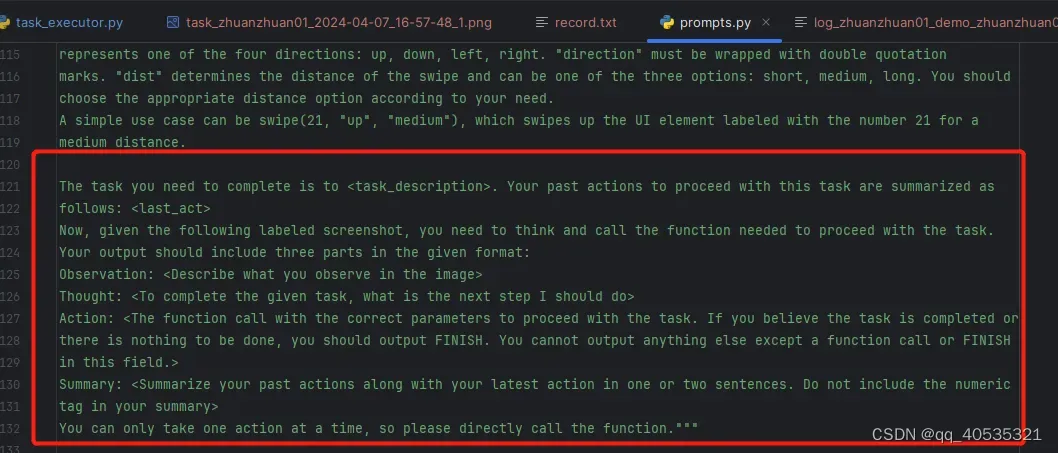
输入数据:对于图像编辑等任务,提示必须包含供 AI 转换的输入数据。语言模型也需要文本输入。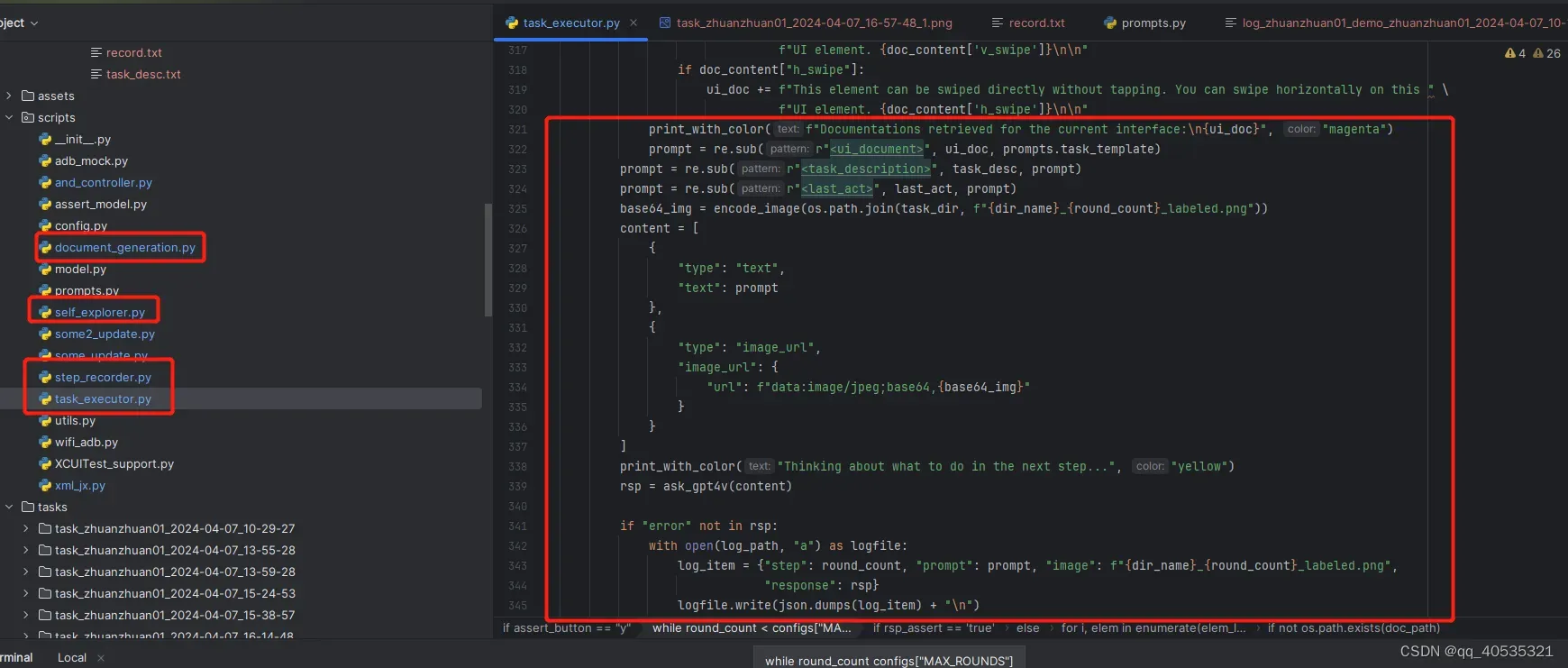
参考我们的appAgent,脚本文件是我们单个任务,每次请求将本地图片解析成base64(因为此时图片是通过adb shell screencap 对当前设备显示截图)加上text,也就是prompt的instructions指令描述,去询问GPT,并要求做规定的回复,同时我们对响应回复进行处理
任务组件包含以下元素:
- 角色——人工智能应该采用的角色
- 命令 – 指挥 AI 的动作动词
- 主题 – 主题重点领域
- 查询 – 要回答的具体问题
说明组成元素包括:
- 输出 – 生成内容的预期属性
- 结构 – 组织格式、部分、流程
- 要做的事 – 可接受的品质和内容
- 不该做的事 – 不可接受的品质和内容
- 要点/想法 – 要包含的具体概念
- 示例 – 说明所需输出的示例
上下文组件涉及以下元素:
- 目标受众 – 内容的预期消费者
- 观点 – 采用的观点
- 目的 – 目标和动机
- 补充信息 – 其他背景详细信息
参数组件包含如下设置:
- 温度 – 创造力/不可预测性水平 (一般用于混沌测试 发散自由探索)
- 长度 – 生成的内容大小
- Top-p – 不可能输出的可能性
- 惩罚 – 阻止不需要的输出
- 模型-使用的AI系统
四、prompt Recipe
可定制字段:特定的内容要求、目标受众、所需的语气、输出长度、创造力水平等。对参数组件可以二次开发
五、基于LLM的Agent构成
Agent=LLM+Prompt Recipe(instructions+Persona)+Tools+Interface+Knowledge+Memory
Prompt Recipe guides how the agent will proceed with the task and how to process the output
Agent must generally interface with a Human,another agent or API
Agent can generate“memories”as well has access to specific domanin knowledge and tools
LLM提供基本的文本生成和理解能力。模型的大小和架构决定了agent的基本能力和局限性。
Prompt激活LLM的技能。通常赋予agent角色、知识、行为和目标
Prompt Recipe通常结合关键指令,上下文和参数,引发代理的响应
记忆
单个用户或单个任务的上下文和记录细节
短期记忆:最近的对话记录或者最近的行动记录
长期记忆:一个外挂数据库记录了事实,对话历史,以及其他相关的细节。
记忆服务与特定用户,在时间维度的体验。使特定用户的上下文对话个性化同时保持多步骤任务的一致性。记忆侧重暂时的用户和任务细节。
知识
知识适用于所有用户的一般专业知识。知识扩展了LLM的内容。
专业知识:针对特定主题或领域定制的特定领域词汇、概念和推理方法来补充LLM
常识知识:增加可能缺乏的一般世界知识
程序知识:提供完成任务的专业知识,例如工作流程、分析技术和创意流程。
将记忆和知识实现分开,可以最大限度提高Agent满足不同需求的灵活性。如下:
agent可以将不同的知识源与随着时间的推移而积累的特定用户的记忆存储集成起来。
能够分析agent的推理技能如何随着时间的推移随着其记忆的积累而演变,而其知识保持不变。
之前的情景记忆可能会引入偏见。在保留知识的同时擦除记忆使智能体严格专注于新的任务上下文。
避免由于对话,对知识进行篡改和变化。保持知识库的独立性和可靠性。
总之,将记忆与知识解耦可以提高agent的敏捷性、可解释性和安全性。他们可以处理不同的任务并建立纵向经验。
工具集成
工具集成允许通过API和外部服务完成任务。
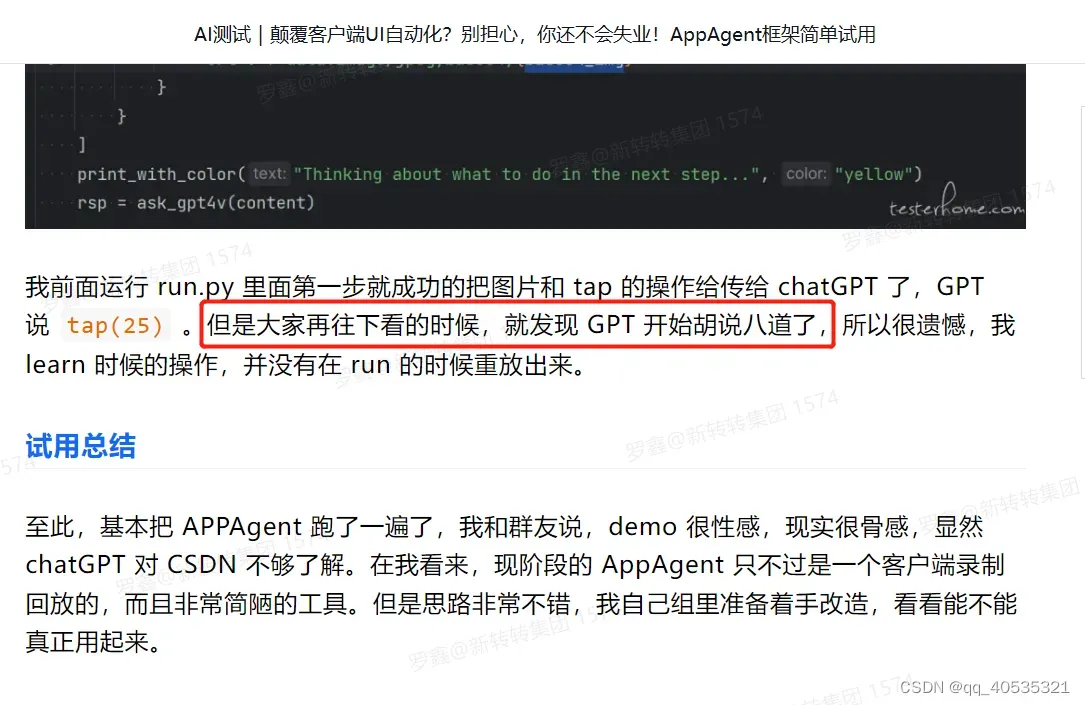
agent能够理解自然语言、推理提示、积累记忆并采取明智的行动。但是,agent的表现和一致性取决于他们收到的提示的质量。我们的Agent就比较受接口失真幻觉的影响,依赖于GPT对图片的理解
六、两种类型的LLM Agents
会话型Agents和任务型Agents,两者在目标、行为和prompt方法都有重要区别。
会话型专注于提供引人入胜的个性化讨论,任务型致力于完成明确定义的目标。
1、Conversational Agents:模拟人类对话 (客服机器人)
主要吸引力:能够在讨论中反映人类的倾向。允许细致入微的上下文交互,会考虑语气、说话风格、领域知识、观点和个性怪癖等因素。agent的开发者可以持续增强记忆、知识整合提高响应能力,持续优化应用。
2、Task-Oriented Agents:目标驱动 (生产常用)
利用模型的能力分析prompt、提取关键参数、指定计划、调用API、通过集成tools执行操作,并生成结果回复。
Prompt 工程把目标型Agents拆分成如下环节:制定战略任务、串联思路、反思过去的工作以及迭代改进的方法。
Groups of task-oriented agents can also coordinate through a centralized prompting interface. This allows assembling teams of AI agents, each with complementary capabilities, to accomplish broad goals. The agents handle distinct sub-tasks while working cohesively towards the overall aim.
是什么让Agent有了自治的能力?
通常有自制能力的系统,至少有两类agent组成。一个用于生成的agent,一个用于监督的agent。
生成agent根据提示生成回复。
监督agent在必要时审查和重新提示或指示生成agent继续工作。同时提供交互反馈。
多agents的交互,创造了培养自主技能的训练回路。
从本质上讲,自治是从提示生态系统中的agents交互中出现的。
自主技能是通过持续提示培养出来的。
专门的监督agent提供方向、纠正和不断提高挑战。
持续的提示释放了推理、效能和自主决策能力的增长。
结合ZZcase用例库 我们目前的ai生成用例功能进行理解
输入问题描述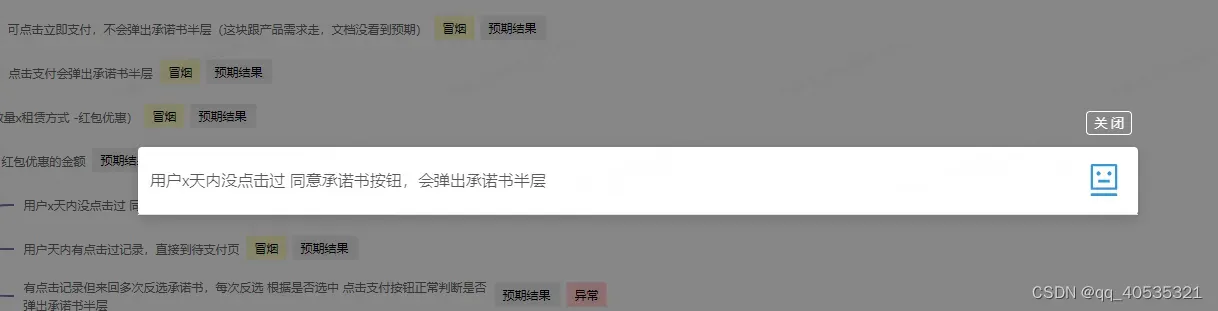
结合代码里写死的prompt 进行拼接
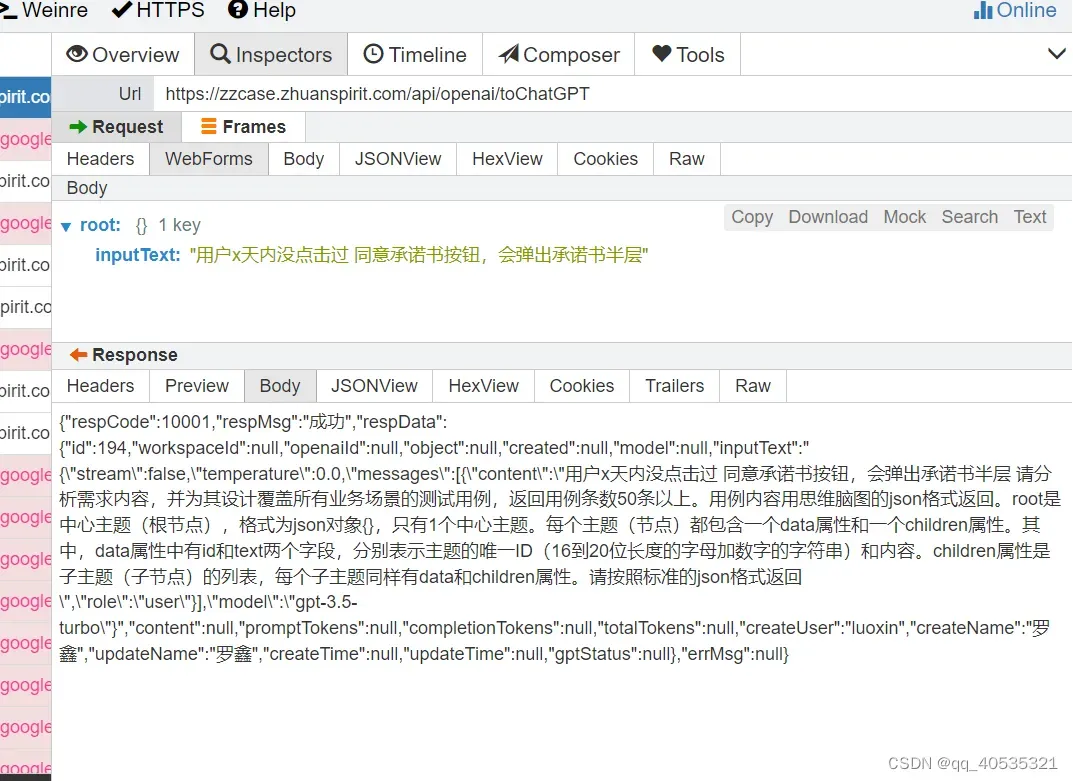
我们只需要解析有data和children标签的json返回,调用创建节点的接口,就可以实现如下思维导图,这是目前的逻辑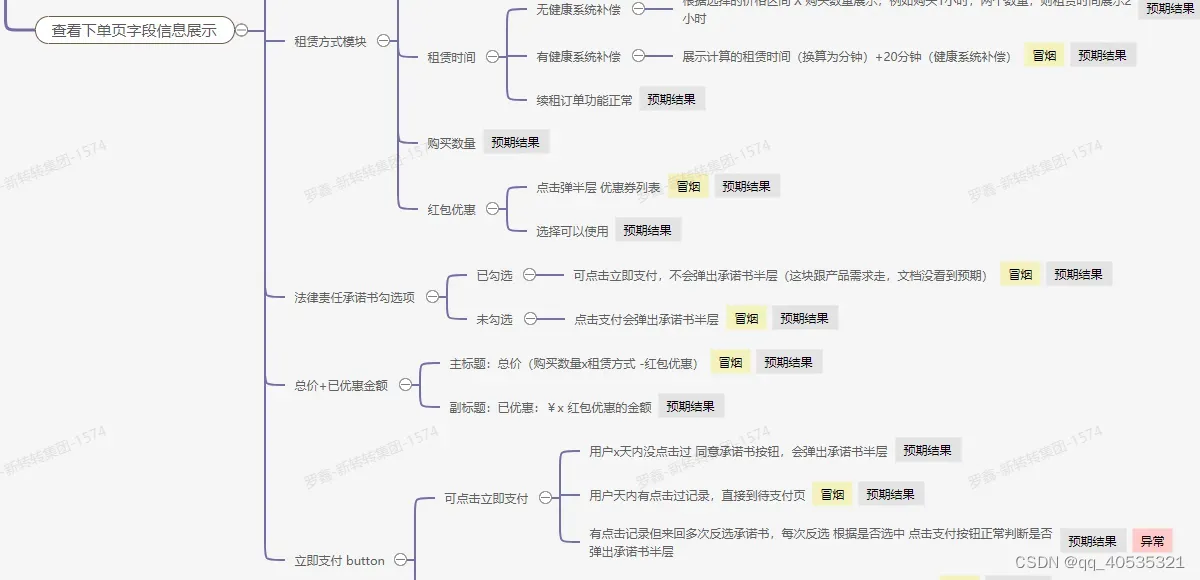
不过目前解析的方法报错,大概率方法需要重写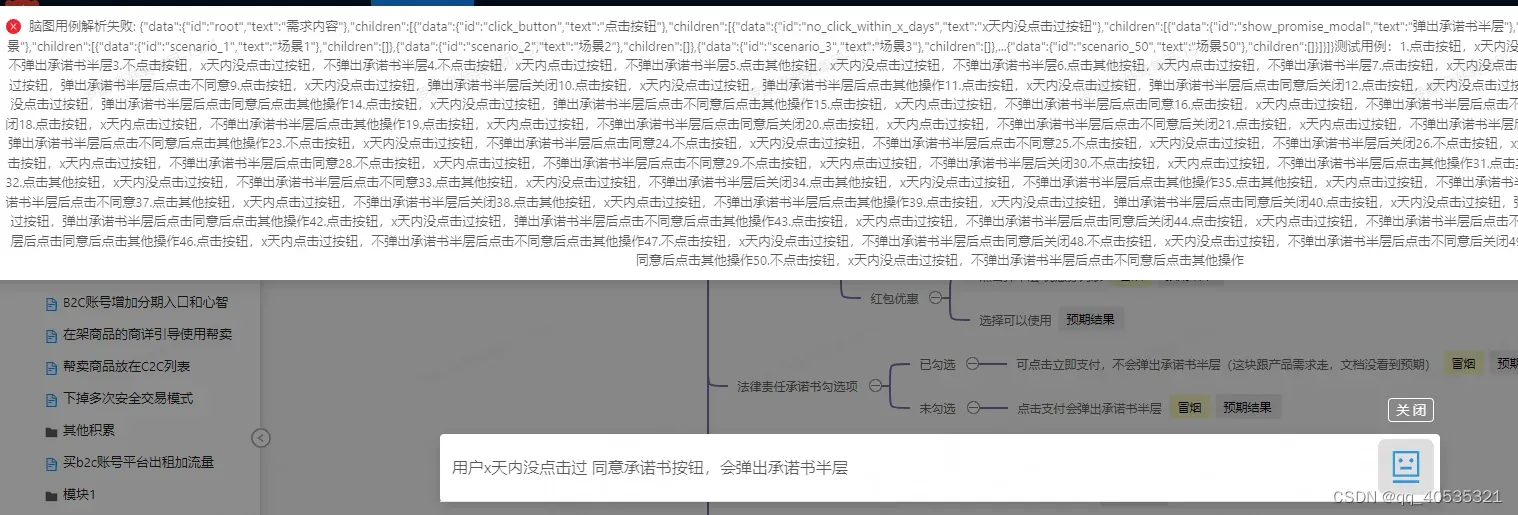
关于我们的appAgent:AI测试 AppAgent框架 使用手册
更新日志:
目前持续解决GPT失真问题,目前遇到难点持续解决, 我们的 app 内,在空间上(同一页面)和时间上(前后页面)有大量页面元素 的资源ID是完全相同的,而我们抓取页面层级结构通过appium的方法会遇到大量重复数据需要去处理并定位到想要到的唯一的元素,因此如何保证在数据大量重复的同时,在重复的数据中定位并执行用户选择的第几个元素(目前有点bug,循环多次会有GPT放飞自己,暂定本周奢侈品鸿蒙适配完开始优化),同时做到数据文件可以人工抽离,复用(这个目前我们已实现在下个更新合入),是当下核心目标
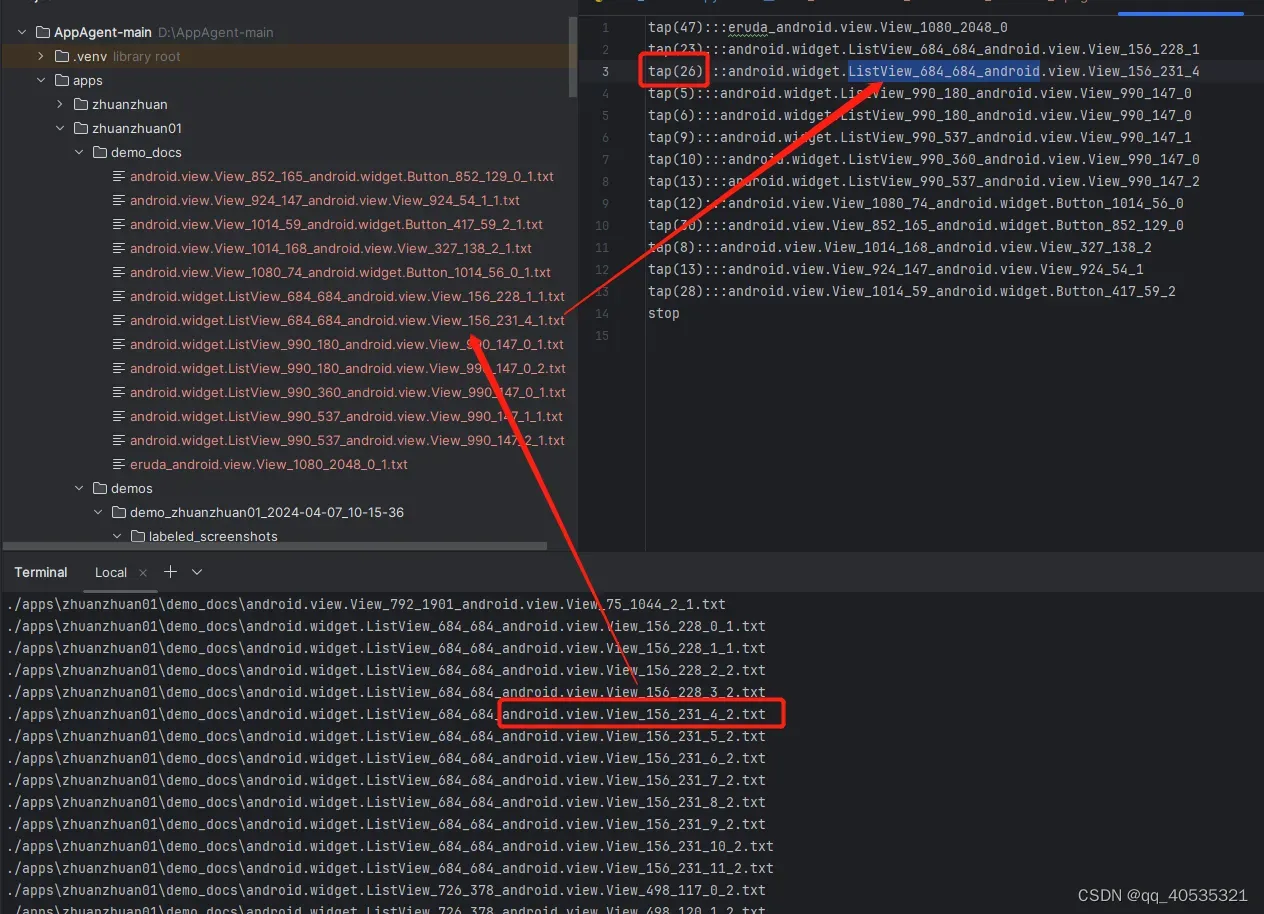
(原型model的adb dump方法会报错 而且十几年前的方法处理不了太多动态页面和类型弹窗,因此底层方法同一替换为appium的page_source,但每次使用需要开启appium的sevice,目前是客户端开启代理,之后配置成代码自启动)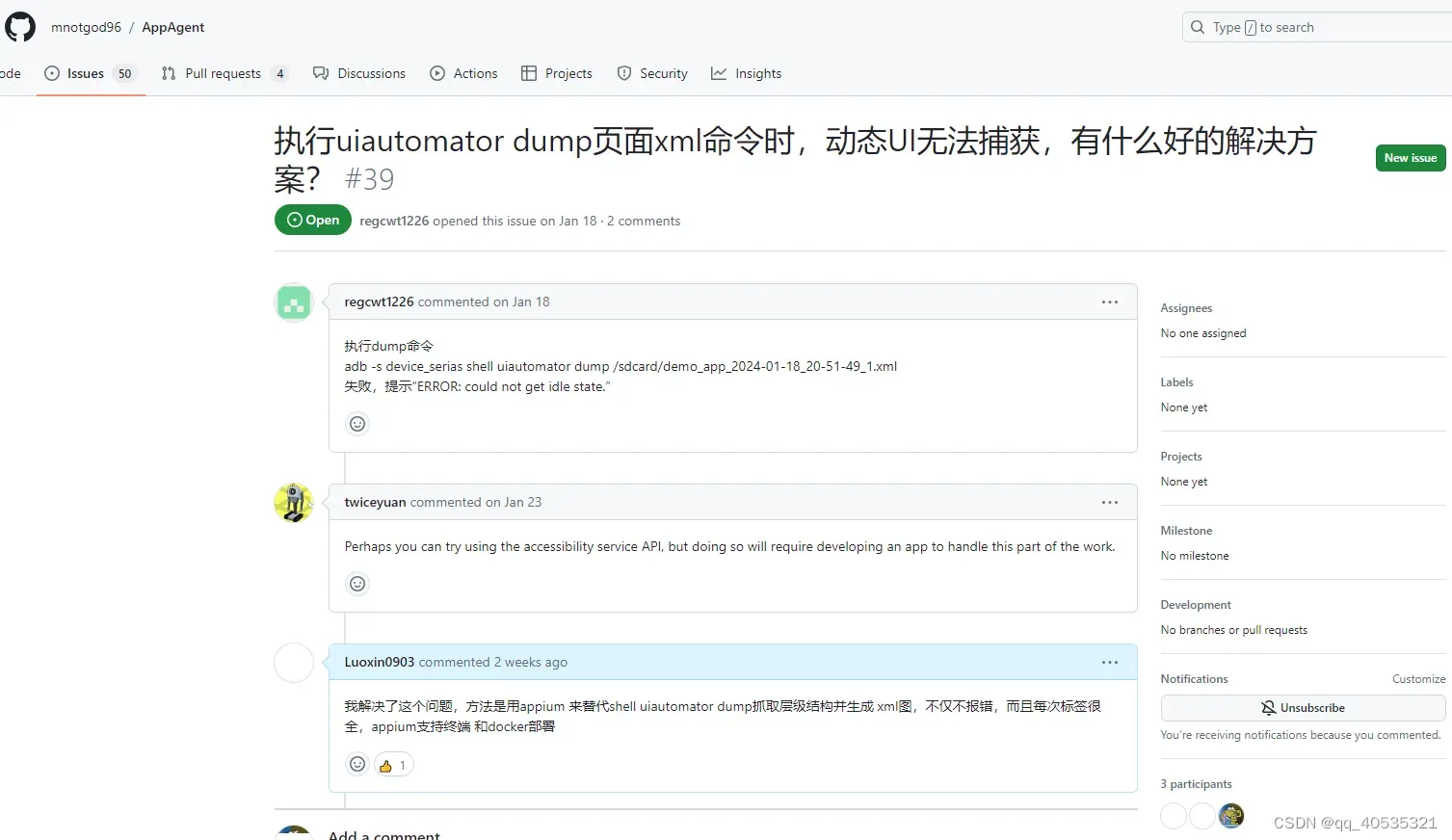
相较于作者需要开发一个应用程序来处理动捕的建议,调研并选择了成熟的appium内置的方法,毕竟是移动端自动化测试的传家宝,同时支持全端使用。(这个原模型作者已经很久不更新了,而且源码的模型非常简陋 只是一个录制回放工具而且回放效果广受差评,但思路不错,目前俺们持续优化基本代码重写了一半,效果快成型了就差失真小问题)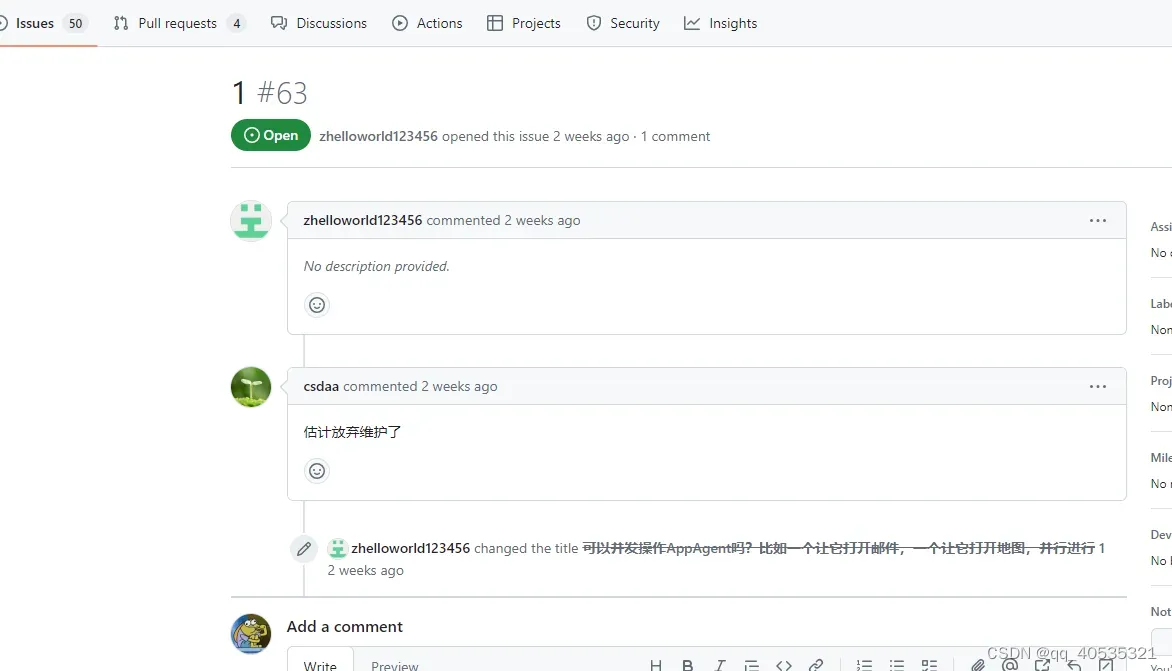
AI赛道的成品工具调研:
Diffblue Cover
-
⽤于⾃动⽣成Java代码的单元测试的AI⼯具。
-
主要特点:使⽤机器学习分析代码并创建测试
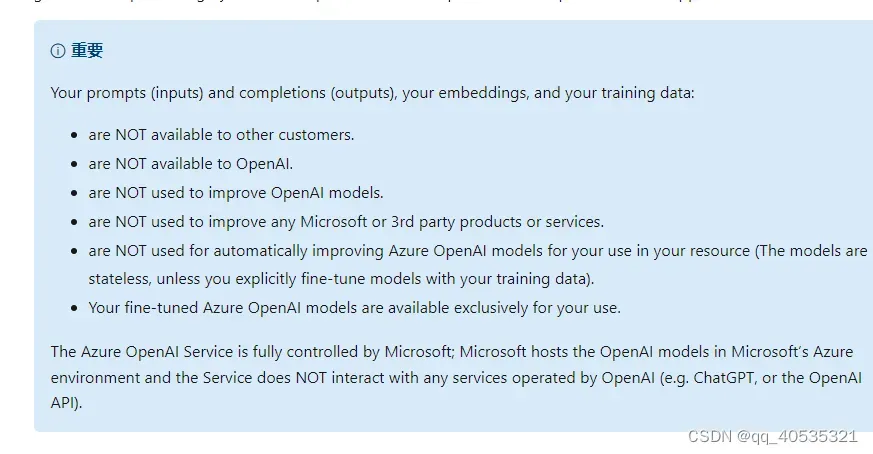
个人评价:成熟的工具,但是涉及源码请求,即使我们架构提供接口有承诺隐私协议 也无法使用,因此代码做入参的工具、插件统统pass
Applitools
-
专注于视觉测试,使⽤AI检测视觉问题的⼯具。
-
主要特点:⽤于Web和移动应⽤的AI驱动的视觉测试。
评价:值得一试,等手头需求不紧张
TestCraft
-
具有AI驱动测试创建和维护功能的⽆代码测试⾃动化平台。
-
主要特点:AI提供的建议、视觉建模、协作功能。
评价:无代码平台,是个好的框架
ReTest
-
AI驱动的回归测试平台。
-
主要特点:⾃动⽣成和维护测试⽤例,减少测试维护⼯作
评价:值得一试,等手头需求不紧张 优先级高,用例梳理是核心目标
Eggplant AI
-
使⽤智能测试⾃动化的AI⼯具。
-
主要特点:⾃学习、预测分析和测试优化。
评价:自学习的promt值得借鉴
Xray(⽤于Jira)
-
与Jira集成的测试管理⼯具,具有AI功能。
-
主要特点:在Jira内进⾏测试⽤例设计和执⾏,AI驱动的分析。
评价:目前公司不直接使用jira,优先级拍后
Parasoft SOAtest
-
具有AI功能的⾃动化测试⼯具。
-
主要特点:API测试、服务虚拟化和AI驱动的分析。
评价:可借鉴抄袭,不可直接使用
Functionize
-
⾯向Web应⽤程序的AI驱动测试平台。
-
主要特点:⾃主测试、⾃愈测试和⾃适应学习。
评价:混沌和发散测试的好靶向,自维护值得借鉴
以上只是第一期目标,后续更新,欢迎大家踊跃参与
版权声明:本文为博主作者:这锅不背0903原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_40535321/article/details/137507173