一、项目准备
1. 问题导入
图像分类是根据图像的语义信息将不同类别图像区分开来,是计算机视觉中重要的基本问题。本实践使用卷积神经网络VGG19模型构建深度学习模型,自动提取高质量的特征,来解决海洋鱼类识别的问题。
2. 数据集简介
本次实验使用的是台湾电力公司、台湾海洋研究所和垦丁国家公园在2010年10月1日至2013年9月30日期间,在中国台湾南湾海峡、兰屿岛和胡比湖的水下观景台收集的鱼类图像数据集。
该数据集包括23类鱼种,共27370张鱼的图像,本次实验将取其中的90%作为训练集,剩下的10%作为测试集。

这是数据集的下载链接:Fish4Knowledge 23种鱼类数据集 – AI Studio
3. VGG模型
- VGG 是由 Simonyan 和 Zisserman 在论文 “Very Deep Convolutional Networks for Large Scale Image Recognition” 中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组 (Visual Geometry Group) 的缩写。
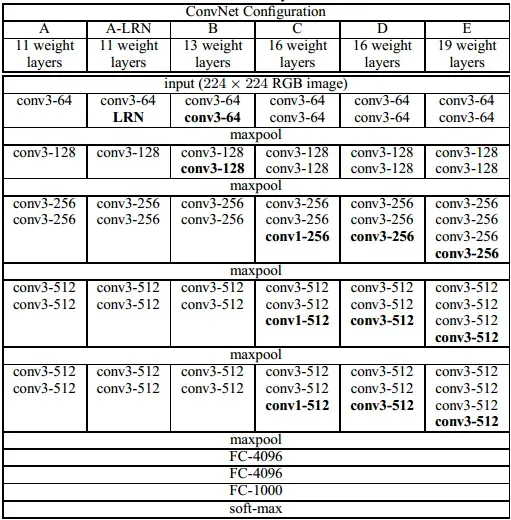
- VGG 中根据卷积核大小和卷积层数目的不同,可分为 A、A-LRN、B、C、D、E 共6个配置 (ConvNet Configuration),其中以 D 和 E 两种配置较为常用,分别称为 VGG16 和 VGG19。本实验使用的是VGG19模型(模型结构如下图 type E 所示)。
二、实验步骤
0. 前期准备
- 导入模块
注意:本案例仅适用于
PaddlePaddle 2.0+版本
import os
import zipfile
import random
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import paddle
from paddle import nn
from paddle import metric as M
from paddle.io import DataLoader, Dataset
from paddle.nn import functional as F
from paddle.optimizer import Adam
from paddle.optimizer.lr import NaturalExpDecay
- 设置超参数
BATCH_SIZE = 64 # 每批次的样本数
EPOCHS = 8 # 训练轮数
LOG_GAP = 150 # 输出训练信息的间隔
INIT_LR = 3e-4 # 初始学习率
LR_DECAY = 0.75 # 学习率衰减率
SRC_PATH = "./data/data14492/fish_image23.zip" # 压缩包路径
DST_PATH = "./data" # 解压路径
DATA_PATH = DST_PATH + "/fish_image" # 实验数据集路径
INFER_PATH = "./work/infer.jpg" # 预测数据集路径
MODEL_PATH = "VGG19.pdparams" # 模型参数保存路径
LAB_DICT = {'fish_1': 'Dascyllus reticulatus', 'fish_2': 'Plectroglyphidodon dickii',
'fish_3': 'Chromis chrysura', 'fish_4': 'Amphiprion clarkii',
'fish_5': 'Chaetodon lunulatus', 'fish_6': 'Chaetodon trifascialis',
'fish_7': 'Myripristis kuntee', 'fish_8': 'Acanthurus nigrofuscus',
'fish_9': 'Hemigymnus fasciatus', 'fish_10': 'Neoniphon sammara',
'fish_11': 'Abudefduf vaigiensis', 'fish_12': 'Canthigaster valentini',
'fish_13': 'Pomacentrus moluccensis', 'fish_14': 'Zebrasoma scopas',
'fish_15': 'Hemigymnus melapterus', 'fish_16': 'Lutjanus fulvus',
'fish_17': 'Scolopsis bilineata', 'fish_18': 'Scaridae',
'fish_19': 'Pempheris vanicolensis', 'fish_20': 'Zanclus cornutus',
'fish_21': 'Neoglyphidodon nigroris', 'fish_22': 'Balistapus undulatus',
'fish_23': 'Siganus fuscescens'} # 用于将文件名和标签相对应
1. 数据准备
- 解压数据集
由于数据集中的数据是以压缩包的形式存放的,因此我们需要先解压数据压缩包。
if not os.path.isdir(DATA_PATH):
z = zipfile.ZipFile(SRC_PATH, "r") # 打开压缩文件,创建zip对象
z.extractall(path=DST_PATH) # 解压zip文件至目标路径
z.close()
print("数据集解压完成!")
- 划分数据集
我们需要按1:9比例划分测试集和训练集,分别生成两个包含数据路径和标签映射关系的列表。
type_num, lab_dict = 0, {} # 方便动物类别在字符型和整型之间转换
train_list, test_list = [], [] # 存放数据的路径及标签的映射关系
file_folders = os.listdir(DATA_PATH) # 统计数据集下的文件夹
for folder in file_folders:
lab_dict[str(type_num)] = LAB_DICT[folder] # 记录标签和数字代号的对应关系
imgs = os.listdir(os.path.join(DATA_PATH, folder))
for idx, img in enumerate(imgs):
path = os.path.join(DATA_PATH, folder, img)
if idx % 10 == 0: # 按照1:9的比例划分数据集
test_list.append([path, type_num])
else:
train_list.append([path, type_num])
type_num += 1
- 数据预处理
我们需要对数据集图像进行缩放和归一化处理。
class MyDataset(Dataset):
''' 自定义的数据集类 '''
def __init__(self, label_list, transform):
'''
* `label_list`: 标签与文件路径的映射列表
* `transform`:数据处理函数
'''
super(MyDataset, self).__init__()
random.shuffle(label_list) # 打乱映射列表
self.label_list = label_list
self.transform = transform
def __getitem__(self, index):
''' 根据位序获取对应数据 '''
img_path, label = self.label_list[index]
img = self.transform(img_path)
return img, int(label)
def __len__(self):
''' 获取数据集样本总数 '''
return len(self.label_list)
def data_mapper(img_path, show=False):
''' 图像处理函数 '''
img = Image.open(img_path)
if show: # 展示图像
display(img)
# 将其缩放为224*224的高质量图像:
img = img.resize((224, 224), Image.ANTIALIAS)
# 把图像变成一个numpy数组以匹配数据馈送格式:
img = np.array(img).astype("float32")
# 将图像矩阵由“rgb,rgb,rbg...”转置为“rr...,gg...,bb...”:
img = img.transpose((2, 0, 1))
# 将图像数据归一化,并转换成Tensor格式:
img = paddle.to_tensor(img / 255.0)
return img
train_dataset = MyDataset(train_list, data_mapper) # 训练集
test_dataset = MyDataset(test_list, data_mapper) # 测试集
- 定义数据提供器
我们需要分别构建用于训练和测试的数据提供器,其中训练数据提供器是乱序、按批次提供数据的。
train_loader = DataLoader(train_dataset, # 训练数据集
batch_size=BATCH_SIZE, # 每批读取的样本数
num_workers=1, # 加载数据的子进程个数
shuffle=True, # 打乱训练数据集
drop_last=False) # 丢弃不完整的样本
test_loader = DataLoader(test_dataset, # 测试数据集
batch_size=BATCH_SIZE, # 每批读取的样本数
num_workers=1, # 加载数据的子进程个数
shuffle=False, # 不打乱测试数据集
drop_last=False) # 不丢弃不完整的样本
2. 网络配置
- 实验模型
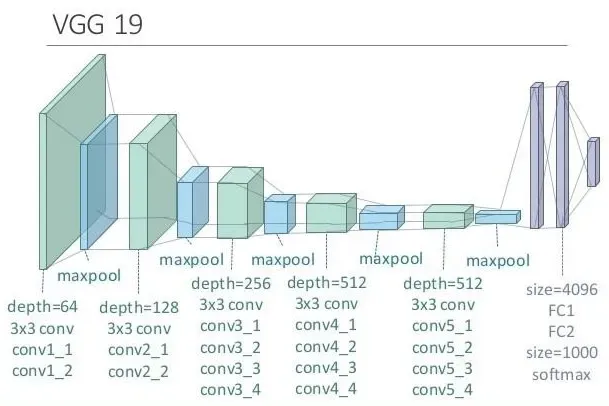
本实验采用的是VGG19模型,VGG19常常被用于分类问题。它包含16个卷积层、5个池化层、3个全连接层。其中,卷积层和全连接层具有权重系数,且它们的总数为19,故该模型被称为VGG19。
class ConvPool(nn.Layer):
''' 卷积-池化组
* `conv_args`(list): 卷积层参数
* `pool_args`(list): 池化层参数
* `conv_num`(int): 卷积层的个数
* `pool_type`(str): 池化类型(Max/Avg)
'''
def __init__(self, conv_args, pool_args, conv_num=1, pool_type="Max"):
super(ConvPool, self).__init__()
# (1) 定义卷积层:
for i in range(conv_num): # 定义conv_num个卷积层
conv = nn.Conv2D(in_channels=conv_args[0], # 输入通道数
out_channels=conv_args[1], # 输出通道数
kernel_size=conv_args[2], # 卷积核大小
stride=conv_args[3], # 卷积步长
padding=conv_args[4]) # 卷积填充大小
conv_args[0] = conv_args[1]
self.add_sublayer("conv_%d" % i, conv)
self.add_sublayer("relu_%d" % i, nn.ReLU())
# (2) 定义池化层:
if pool_type == "Max": # 最大池化
pool = nn.MaxPool2D(kernel_size=pool_args[0], # 池化核大小
stride=pool_args[1], # 池化步长
padding=pool_args[2]) # 池化填充大小
else: # 平均池化
pool = nn.AvgPool2D(kernel_size=pool_args[0], # 池化核大小
stride=pool_args[1], # 池化步长
padding=pool_args[2]) # 池化填充大小
self.add_sublayer("pool", pool)
def forward(self, x):
for prefix, sub_layer in self.named_children():
x = sub_layer(x)
return x
class VGG19(nn.Layer):
def __init__(self, out_dim):
super(VGG19, self).__init__()
self.conv1 = ConvPool([ 3, 64, 3, 1, 1], [2, 2, 0], 2, "Max")
self.conv2 = ConvPool([ 64, 128, 3, 1, 1], [2, 2, 0], 2, "Max")
self.conv3 = ConvPool([128, 256, 3, 1, 1], [2, 2, 0], 4, "Max")
self.conv4 = ConvPool([256, 512, 3, 1, 1], [2, 2, 0], 4, "Max")
self.conv5 = ConvPool([512, 512, 3, 1, 1], [2, 2, 0], 4, "Max")
self.linear = nn.Sequential(nn.Linear(512*7*7, 4096),
nn.ReLU(),
nn.Dropout(0.25),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.25),
nn.Linear(4096, out_dim))
def forward(self, x): # 输入维度:3*224*224
x = self.conv1(x) # 输出维度:64*112*112
x = self.conv2(x) # 输出维度:128*56*56
x = self.conv3(x) # 输出维度:256*28*28
x = self.conv4(x) # 输出维度:512*14*14
x = self.conv5(x) # 输出维度:512*7*7
x = paddle.flatten(x, 1, -1)
y = self.linear(x)
return y
- 实例化模型
model = VGG19(out_dim=type_num)
3. 模型训练
model.train() # 开启训练模式
scheduler = NaturalExpDecay(
learning_rate=INIT_LR,
gamma=LR_DECAY
) # 定义学习率衰减器
optimizer = Adam(
learning_rate=scheduler,
parameters=model.parameters()
) # 定义Adam优化器
loss_arr, acc_arr = [], [] # 用于可视化
for ep in range(EPOCHS):
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
y_data = y_data[:, np.newaxis] # 增加一维维度
y_pred = model(x_data) # 预测结果
acc = M.accuracy(y_pred, y_data) # 计算准确率
loss = F.cross_entropy(y_pred, y_data) # 计算交叉熵
if batch_id != 0 and batch_id % LOG_GAP == 0: # 定期输出训练结果
print("Epoch:%d,Batch:%3d,Loss:%.5f,Acc:%.5f"\
% (ep, batch_id, loss, acc))
acc_arr.append(acc.item())
loss_arr.append(loss.item())
optimizer.clear_grad()
loss.backward()
optimizer.step()
scheduler.step() # 每轮衰减一次学习率
paddle.save(model.state_dict(), MODEL_PATH) # 保存训练好的模型
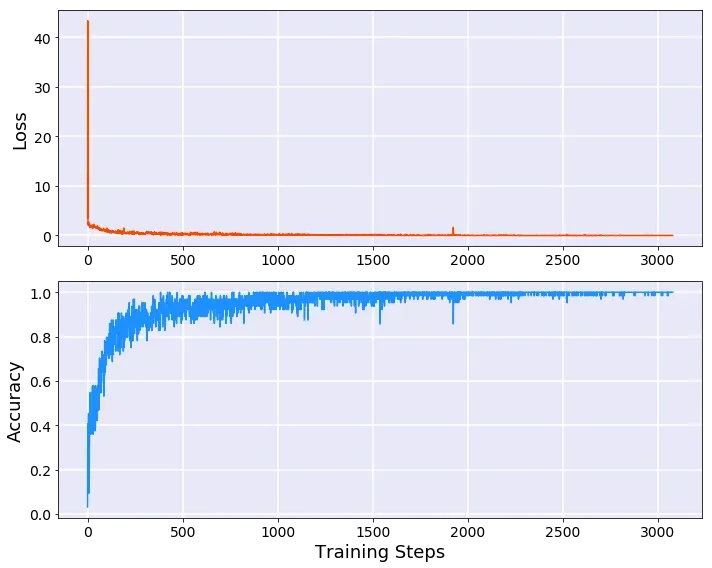
模型训练的结果如下:
Epoch:0,Batch:150,Loss:0.57758,Acc:0.82812
Epoch:0,Batch:300,Loss:0.22912,Acc:0.93750
Epoch:1,Batch:150,Loss:0.12195,Acc:0.95312
Epoch:1,Batch:300,Loss:0.19877,Acc:0.93750
Epoch:2,Batch:150,Loss:0.07112,Acc:0.98438
Epoch:2,Batch:300,Loss:0.09523,Acc:0.98438
Epoch:3,Batch:150,Loss:0.07677,Acc:0.98438
Epoch:3,Batch:300,Loss:0.01776,Acc:1.00000
Epoch:4,Batch:150,Loss:0.02427,Acc:0.98438
Epoch:4,Batch:300,Loss:0.00211,Acc:1.00000
Epoch:5,Batch:150,Loss:0.00695,Acc:1.00000
Epoch:5,Batch:300,Loss:0.02889,Acc:0.98438
Epoch:6,Batch:150,Loss:0.01456,Acc:0.98438
Epoch:6,Batch:300,Loss:0.00660,Acc:1.00000
Epoch:7,Batch:150,Loss:0.00719,Acc:1.00000
Epoch:7,Batch:300,Loss:0.00266,Acc:1.00000
- 可视化训练过程
fig = plt.figure(figsize=[10, 8])
# 训练误差图像:
ax1 = fig.add_subplot(211, facecolor="#E8E8F8")
ax1.set_ylabel("Loss", fontsize=18)
plt.tick_params(labelsize=14)
ax1.plot(range(len(loss_arr)), loss_arr, color="orangered")
ax1.grid(linewidth=1.5, color="white") # 显示网格
# 训练准确率图像:
ax2 = fig.add_subplot(212, facecolor="#E8E8F8")
ax2.set_xlabel("Training Steps", fontsize=18)
ax2.set_ylabel("Accuracy", fontsize=18)
plt.tick_params(labelsize=14)
ax2.plot(range(len(acc_arr)), acc_arr, color="dodgerblue")
ax2.grid(linewidth=1.5, color="white") # 显示网格
fig.tight_layout()
plt.show()
plt.close()
4. 模型评估
model.eval() # 开启评估模式
test_costs, test_accs = [], []
for batch_id, data in enumerate(test_loader()):
x_data, y_data = data
y_data = y_data[:, np.newaxis] # 增加一维维度
y_pred = model(x_data) # 预测结果
acc = M.accuracy(y_pred, y_data) # 计算准确率
loss = F.cross_entropy(y_pred, y_data) # 计算交叉熵
test_accs.append(acc.item())
test_costs.append(loss.item())
test_loss = np.mean(test_costs) # 每轮测试的平均误差
test_acc = np.mean(test_accs) # 每轮测试的平均准确率
print("Eval \t Loss:%.5f,Acc:%.5f" % (test_loss, test_acc))
模型评估的结果如下:
Eval Loss:0.11719,Acc:0.98067
5. 模型预测
- 处理预测数据
truth_lab = "Dascyllus reticulatus" # 待预测图片的标签
infer_img = data_mapper(INFER_PATH, show=True) # 获取预测图片
infer_img = infer_img[np.newaxis, :, :, :]

- 载入模型并开始预测
model.eval() # 开启评估模式
model.set_state_dict(
paddle.load(MODEL_PATH)
) # 载入预训练模型参数
result = model(infer_img)
infer_lab = lab_dict[ str(np.argmax(result)) ] # 获取推理结果
print("真实标签:%s,预测结果:%s" % (truth_lab, infer_lab))
模型预测的结果如下:
真实标签:Dascyllus reticulatus,预测结果:Dascyllus reticulatus
写在最后
- 如果您发现项目存在问题,或者如果您有更好的建议,欢迎在下方评论区中留言讨论~
- 这是本项目的链接:实验项目 – AI Studio,点击
fork可直接在AI Studio运行~- 这是我的个人主页:个人主页 – AI Studio,来AI Studio互粉吧,等你哦~
- 【友链滴滴】欢迎大家随时访问我的个人博客~
文章出处登录后可见!
已经登录?立即刷新