1. 摘要
首先,为了激发对真实世界遮挡和变异姿势下的FER的研究,我们为该领域注释了几个带有姿势和遮挡属性的野外FER数据集。其次,我们提出了一个新的区域注意网络(RAN),以适应性地捕捉面部区域对于遮挡和姿势变化的FER的重要性。RAN将骨干卷积神经网络产生的不同数量的区域特征汇总并嵌入到一个紧凑的固定长度的表示中。最后,受面部表情主要由面部动作单元定义这一事实的启发,我们提出了一个区域偏向损失,以鼓励对最重要区域的高关注权重。我们在我们建立的测试数据集和四个流行的数据集上验证了我们的RAN和区域偏向损失。FERPlus, AffectNet, RAF-DB, 和SFEW。广泛的实验表明,我们的RAN和区域偏置损失在很大程度上改善了FER在遮挡和不同姿势下的性能。我们的方法在FERPlus、AffectNet、RAF-DB和SFEW上也取得了最先进的结果。代码和收集的测试数据将公开提供。
2. 引言
首先,为了研究遮挡和姿势变量FER问题,我们从FERPlus和AffectNet中建立了六个真实世界的测试数据集,Occlusion-FERPlus, Pose-FERPlus, Occlusion-AffectNet, Pose-AffectNet, Occlusion-RAFDB, Pose-RAF-DB。遮挡测试数据集由人工标注,遮挡类型包括戴面具/眼镜、左/右的物体、上脸的物体、下脸的物体。姿势变化测试数据集是由最近的头部姿势估计工具箱自动标注的。
其次,我们提出了区域注意网络(RAN),以捕捉面部区域对遮挡和姿势变化的FER的重要性。RAN由一个特征提取模块、一个自我注意模块和一个关系注意模块组成。后面的两个模块分别旨在学习粗略的注意力权重,并通过全局背景来完善它们。给定一些面部区域,我们的RAN以端到端的方式学习每个区域的注意力权重,并将其基于CNN的特征聚集到一个紧凑的固定长度的表示中。此外,RAN模型对面部图像有两个辅助作用。一方面,裁剪区域可以扩大训练数据,这对那些缺乏挑战性的样本很重要。另一方面,将区域的大小重新调整为原始图像的大小,可以突出细粒度的面部特征。广泛的实验表明,我们的RAN明显提高了FER在遮挡和姿势变化条件下的性能。
第三,由于面部表情主要是由多个面部动作单元定义的,我们提出了一个区域偏差损失(RB-Loss),以鼓励最重要的区域获得高关注权重。我们的RB-Loss对RAN进行了一个简单的约束,即面部区域的最大注意力权重应该大于原始面部图像的权重。实验表明,RB-Loss进一步提高了FER,而没有增加计算成本。我们的FER解决方案在FERPlus、AffectNet、RAFDB和SFEW上取得了最先进的结果,准确率分别为89.16%、59.5%、86.9%和56.4%。
3. 方法
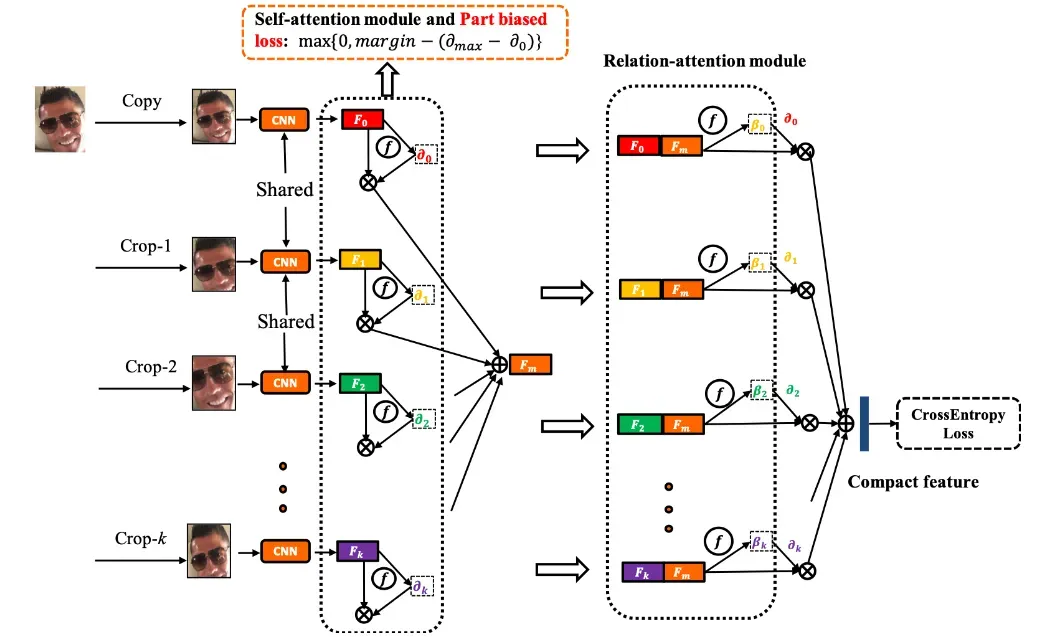
它主要由三个模块组成,即区域裁剪和特征提取模块、自我关注模块和关系关注模块。给定一个人脸图像(经过人脸检测),我们首先用固定位置裁剪或随机裁剪将其裁剪成若干区域。我们将在实验中比较这些策略。然后,这些区域与原始人脸区域一起被送入一个骨干CNN模型进行区域特征提取。随后,自我注意模块使用全连接(FC)层和sigmoid函数为每个区域分配一个注意权重。进一步引入了另一种区域偏向损失(RBLoss)来规范注意力权重,并增强自我注意模块中最有价值的区域。我们将这些区域特征汇总到一个全局表示(图1中的Fm)。然后,关系注意模块在单个区域特征和全局表示的串联上使用类似的注意机制,以进一步捕获内容感知的注意权重。最后,我们利用加权的区域特征和全局表示来预测表情。
3.1 区域注意网络
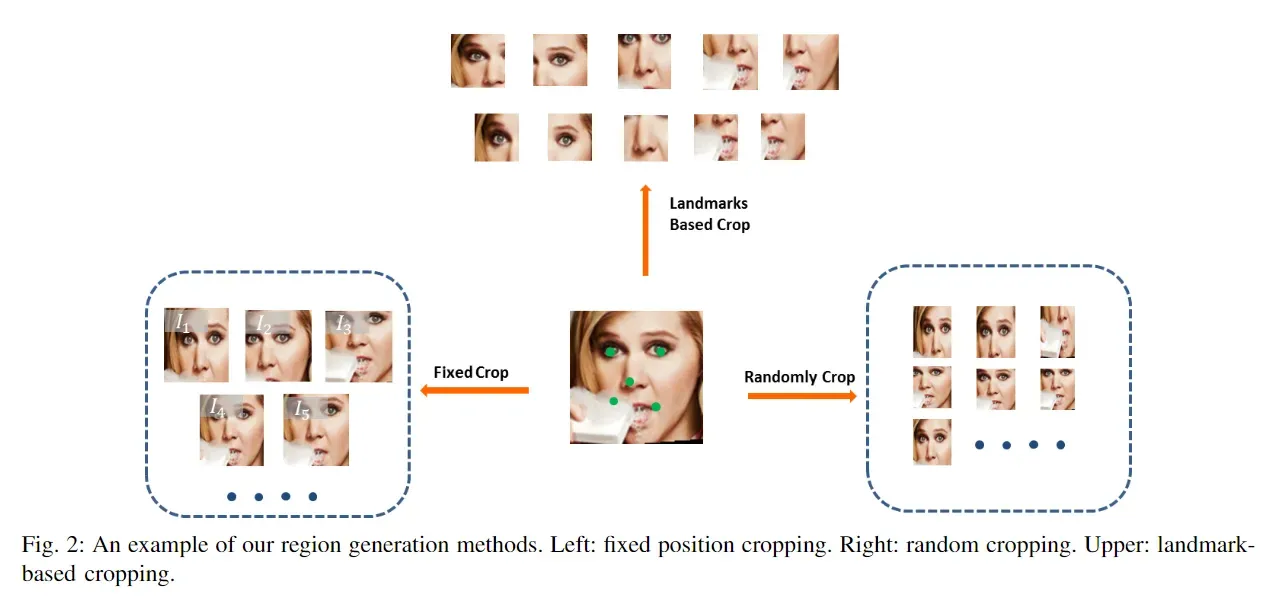
首先图片经过fixed crop或randomly crop或 landmarks Based crop被分成若干个区域,将每个区域经过CNN后得到特征Fi…..Fk
![]()
3.1.1 自注意力模型(Self-attention module)
有了这些区域特征,自我注意模块应用FC层和sigmoid函数来估计粗略的注意权重。在数学上,第i个区域的注意力权重定义为
![]()
q0表示全连接层的参数,f表示sigmoid函数,我们把所有的区域特征和它们的注意力权重总结成一个全局的表示Fm
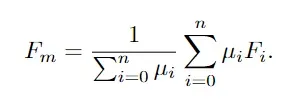
3.1.2 关系注意力模型(Relation-attention module)
自我注意模块通过单个特征和非线性映射来学习权重,这是相当粗略的。由于聚合表征Fm本质上代表了所有面部区域的内容,注意力权重可以通过对区域特征和这个聚合表征Fm之间的关系进行建模来进一步完善
我们使用样本串联和另一个全连接层来估计区域特征的新注意力权重。在关系注意力模块中,第i个区域的新注意力权重被表述为
![]()
其中q1是FC层的参数,f表示sigmoid函数。F i表示区域提取特征将其与整体特征F m
作一个concat操作,然后经过全连接层再经过激活函数,得到结合局部与整体的特征的权重
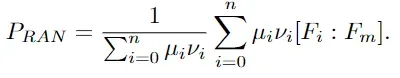
同样将得到特征进行加权求得一个新的全局特征PRAN 这个特征作者在后面与Fm做过对比
3.2 区域偏差损失(Region Biased Loss)
受不同的面部表情主要由不同的面部区域定义这一观察结果的启发,我们对自我注意的注意力权重做了一个直接的约束,即区域偏置损失(RB-Loss)。其使裁剪区域中至少有一个的权重要大于原始人脸特征所占的权重,并有一定的距离。例如,图1中的Crop-2可以比原来的更有鉴别力。形式上,RB-Loss被定义为
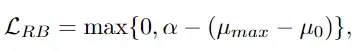
其中 α 是一个超参数作为边界,μ0是复制的人脸图像的注意力权重,μmax 表示所有人脸图像的最大的注意力权重
在训练过程中,将分类损失与区域偏差损失联合优化。提出的 RB-Loss 增强了区域注意的效果,并使得RAN 获得更优的区域和全局表示权值。
4. 实验
CROP的三种策略
Fixed Crop
Fixed Crop: top-left、top-right、center-down(0.75)、center(0.85)、center(0.9)
Landmarks Based Crop
Landmarks Based Crop: MTCNN(左眼、右眼、鼻子、嘴左边角、嘴右边角)
Randomly Crop
Randomly Crop: randomly crop N regions(0.7-0.95)
三种crop性能比较
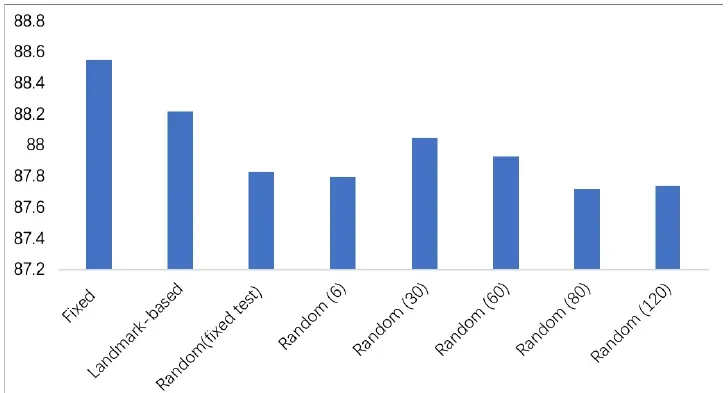
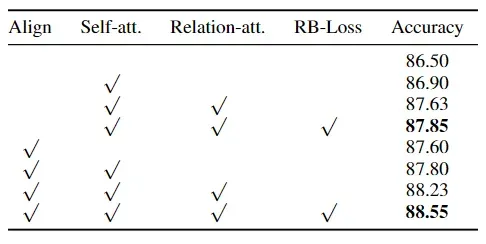
RAN中所有组成部分的实验
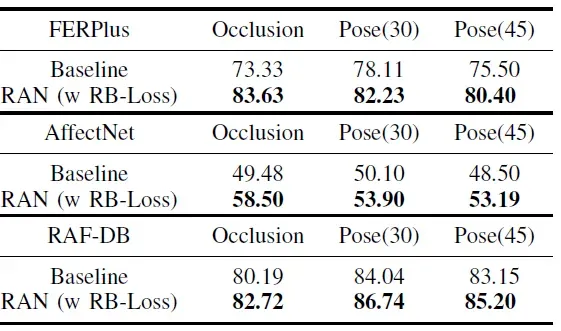
RAN与Baseline在作者创建的数据库的性能比较
RAN与最新的方法在FerPlus上的性能比较
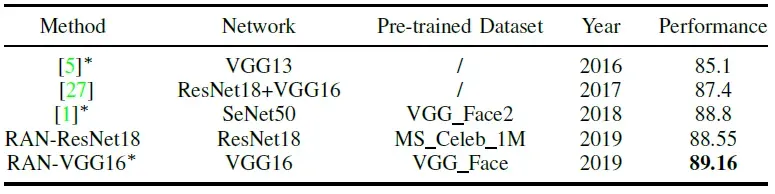
RAN与最新的方法在AffectNet上的性能比较
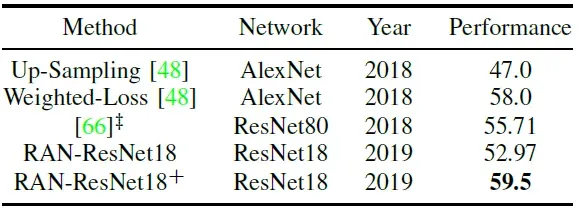
RAN与最新的方法在SFEW上的性能比较
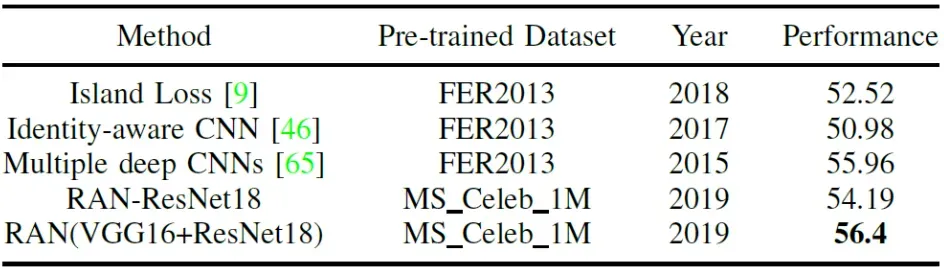
文章出处登录后可见!