个人微信公众号,专注于机器学习公式推导代码实现、计算机视觉、深度学习、步态识别、视觉slam、激光slam。

前言
根据上一节的介绍,我们已经有了匹配好的点对,然后我们就可以根据点对估计相机的运动。这里由于相机的原理不同,我们要分情况讨论:
- 如果是单目相机,此时我们仅知道2D的像素坐标,要根据两组2D点估计相机运动,这种情况要用对极几何来解决。
- 如果是双目或者RGB-D相机,此时我们知道深度信息,也就是我们可以通过3D点来估算运动,这种情况用ICP解决。
- 如果我们知道一些3D点和相机的投影位置,此时我们用PnP解决。
2D-2D:对极几何
对于单目相机,假设我们已经从两张图像中得到了一张匹配正确的点对,将问题可以抽象成下图所示。我们希望求取两帧图像为,
之间的运动,设第一帧到第二帧的运动为
,
,两个相机的中心为
,
。点
在
中的特征点为
,点
在
中的特征点为
。
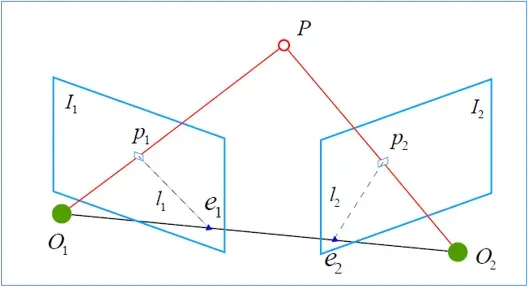
对极几何主要涉及以下几个元素:
-
基线(baseline):两个相机中心的连线
称为基线。
-
对极点(epipolar):
是对极点,是基线和两个成像平面的交点,也就是对极点在一幅视图中另一个相机中心的像;这里在解释一下,
是右边的相机中心
在左边相机的像点,同样
是左边相机中心
在右边相机的像点。
-
对极平面(epipolar plane):任何过基线的平面都被才称为对极平面,两个相机的中心
,以及其在两个相机的像点
,这5点必定在同一个对极平面上。当三维点
-
对极线(epipolar line):对极平面和成像平面的交线
,
,所有的对极线相交于极点。
上面我们了解了一些简单的几何知识,但有一个地方要注意一下,如果没有特征匹配,我们就无法确定在具体在极线的哪个位置。遇到这种的情况此时就需要在极线上搜索以获取正确的匹配,这种情况我们后面在讨论。
我们用从代数的方法来分析上图的几何关系。设在第一帧的坐标系下,设的空间位置为
根据之前我们讲解的相机模型,可知像素点,
的像素坐标为
其中为相机的内参矩阵,
,
为两个坐标系的相机运动。
我们使用齐次坐标来表示像素点。使用齐次坐标主要是为了表达投影关系,例如,和
成投影关系,它们在齐次坐标的意义下相等。这种关系成为尺度意义下相等,则有:
根据投影关系可有
我们使用归一化平面坐标,则有
继续整理,带入化简可有
两边同时左乘(简单回忆一下
),则有
两边同时左乘,则有
到了这里要注意一下,向量与向量
、
都垂直。所以在和
做内积,将严格为零。所以有
将,
带入可得
上面两个式子称为对极约束。它的几何意义为,
,
三者共面。我们令中间部分两个矩阵为基础矩阵(Fundamental Matrix)和本质矩阵(Essential Matrix),进一步化简则有
我们根据上面的代数推导,所以相机位姿估计步骤为:
1.根据配对点的像素位置求出
或者
。
2.根据
,
。
本质矩阵
本质矩阵有如下特点:
-
它是
的矩阵,有9个未知数;
-
由于对极约束是等式为零的约束,所以对
-
可以证明,本质矩阵的奇异值一定是
的形式。
-
由于平移和旋转各有3个自由度,故
我们通常使用八点法来求解
,
,它们的归一化坐标为
,
。由对极约束,则有
我们把矩阵展开,写成向量形式:
将其整理成关于的线性形式,则有
同理可得,我们将上面线性形式扩展成8个特征点的形式,其中表示第
个特征点,整理可得:
根据上面的线性方程组,这样就解出了本质矩阵。我们接下来的工作就是通过本质矩阵
,恢复出相机的运动
,
。
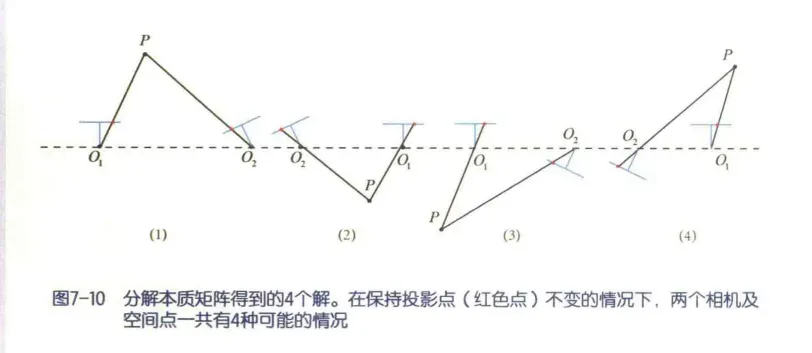
设的SVD的分解为
其中为正交阵,
为奇异值矩阵。对于任意一个
,分解到
,
有四种可能的解。我们把任意一个点带入到四种解中,如果两个相机都为正的深度,即为正确的解。
单应矩阵
单应矩阵(Homography)描述的是两个平面之间的映射关系。若场景中的特征点都落在同一平面上,则可以通过单应性进行运动估计。我们还是和前面一样,进行简单的数学推导。假设我们使用同一相机在不同的位姿下拍摄同一平面,如图所示:
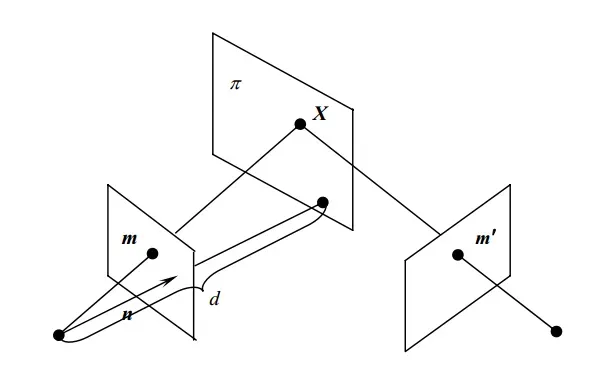
其中平面表示两个相机的成像平面,设平面
在第一个相机坐标系下的单位法向量为
,第一个相机中心到平面
的距离为
,则
即为
同样使(
是三维点
在第一相机坐标系下的坐标)经过旋转和平移到第二个相机坐标系下为
,则
将上式整理化简,则
故我们就得到了同一平面在不同相机坐标系下的单应矩阵
矩阵为第一个相机坐标系变换到第二个相机坐标所得,我们还需将其转化为成像平面
。设
,
为
在两图像的像点坐标,
其中为相机内参矩阵,整理上式进行单应变换则有
故同一平面得到的两个图像间的单应矩阵为
关于矩阵的求解,它和本质矩阵的方式类似,最后都是将
矩阵分解为
和
,通过先验信息得到正确的解。
当特征点共面或者相机发生纯旋转时,基础矩阵的自由度下降,这就出现了所谓的退化(degenerate)。现实中的数据总包含一些噪声,这时候如果继续使用过八点法求解基础矩阵,基础矩阵多余出来的自由度将会主要由噪声决定。为了能够避免退化现象造成的影响,通常我们会同时估计基础矩阵
,选择重投影误差比较小的那个座位最终的运动估计矩阵。
我们简单总结一下基础矩阵,本质矩阵
和单应矩阵之间的关系:
的信息,
- 若相机只有旋转而没有平移的情况下,此时
实践:对极约束求解相机运动
我们还是使用OpenCV提供的接口,最后分解出和
。代码如下:
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/calib3d/calib3d.hpp>
using namespace std;
using namespace cv;
void find_feature_matches(
const Mat &img_1, const Mat &img_2,
std::vector<KeyPoint> &keypoints_1,
std::vector<KeyPoint> &keypoints_2,
std::vector<DMatch> &matches);
void pose_estimation_2d2d(
std::vector<KeyPoint> keypoints_1,
std::vector<KeyPoint> keypoints_2,
std::vector<DMatch> matches,
Mat &R, Mat &t);
// 像素坐标转相机归一化坐标
Point2d pixel2cam(const Point2d &p, const Mat &K);
int main(int argc, char **argv) {
if (argc != 3) {
cout << "usage: pose_estimation_2d2d img1 img2" << endl;
return 1;
}
//-- 读取图像
Mat img_1 = imread(argv[1], CV_LOAD_IMAGE_COLOR);
Mat img_2 = imread(argv[2], CV_LOAD_IMAGE_COLOR);
assert(img_1.data && img_2.data && "Can not load images!");
vector<KeyPoint> keypoints_1, keypoints_2;
vector<DMatch> matches;
find_feature_matches(img_1, img_2, keypoints_1, keypoints_2, matches);
cout << "一共找到了" << matches.size() << "组匹配点" << endl;
//-- 估计两张图像间运动
Mat R, t;
pose_estimation_2d2d(keypoints_1, keypoints_2, matches, R, t);
//-- 验证E=t^R*scale
Mat t_x =
(Mat_<double>(3, 3) << 0, -t.at<double>(2, 0), t.at<double>(1, 0),
t.at<double>(2, 0), 0, -t.at<double>(0, 0),
-t.at<double>(1, 0), t.at<double>(0, 0), 0);
cout << "t^R=" << endl << t_x * R << endl;
//-- 验证对极约束
Mat K = (Mat_<double>(3, 3) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1);
for (DMatch m: matches) {
Point2d pt1 = pixel2cam(keypoints_1[m.queryIdx].pt, K);
Mat y1 = (Mat_<double>(3, 1) << pt1.x, pt1.y, 1);
Point2d pt2 = pixel2cam(keypoints_2[m.trainIdx].pt, K);
Mat y2 = (Mat_<double>(3, 1) << pt2.x, pt2.y, 1);
Mat d = y2.t() * t_x * R * y1;
cout << "epipolar constraint = " << d << endl;
}
return 0;
}
void find_feature_matches(const Mat &img_1, const Mat &img_2,
std::vector<KeyPoint> &keypoints_1,
std::vector<KeyPoint> &keypoints_2,
std::vector<DMatch> &matches) {
//-- 初始化
Mat descriptors_1, descriptors_2;
// used in OpenCV3
Ptr<FeatureDetector> detector = ORB::create();
Ptr<DescriptorExtractor> descriptor = ORB::create();
// use this if you are in OpenCV2
// Ptr<FeatureDetector> detector = FeatureDetector::create ( "ORB" );
// Ptr<DescriptorExtractor> descriptor = DescriptorExtractor::create ( "ORB" );
Ptr<DescriptorMatcher> matcher = DescriptorMatcher::create("BruteForce-Hamming");
//-- 第一步:检测 Oriented FAST 角点位置
detector->detect(img_1, keypoints_1);
detector->detect(img_2, keypoints_2);
//-- 第二步:根据角点位置计算 BRIEF 描述子
descriptor->compute(img_1, keypoints_1, descriptors_1);
descriptor->compute(img_2, keypoints_2, descriptors_2);
//-- 第三步:对两幅图像中的BRIEF描述子进行匹配,使用 Hamming 距离
vector<DMatch> match;
//BFMatcher matcher ( NORM_HAMMING );
matcher->match(descriptors_1, descriptors_2, match);
//-- 第四步:匹配点对筛选
double min_dist = 10000, max_dist = 0;
//找出所有匹配之间的最小距离和最大距离, 即是最相似的和最不相似的两组点之间的距离
for (int i = 0; i < descriptors_1.rows; i++) {
double dist = match[i].distance;
if (dist < min_dist) min_dist = dist;
if (dist > max_dist) max_dist = dist;
}
printf("-- Max dist : %f \n", max_dist);
printf("-- Min dist : %f \n", min_dist);
//当描述子之间的距离大于两倍的最小距离时,即认为匹配有误.但有时候最小距离会非常小,设置一个经验值30作为下限.
for (int i = 0; i < descriptors_1.rows; i++) {
if (match[i].distance <= max(2 * min_dist, 30.0)) {
matches.push_back(match[i]);
}
}
}
Point2d pixel2cam(const Point2d &p, const Mat &K) {
return Point2d
(
(p.x - K.at<double>(0, 2)) / K.at<double>(0, 0),
(p.y - K.at<double>(1, 2)) / K.at<double>(1, 1)
);
}
void pose_estimation_2d2d(std::vector<KeyPoint> keypoints_1,
std::vector<KeyPoint> keypoints_2,
std::vector<DMatch> matches,
Mat &R, Mat &t) {
// 相机内参,TUM Freiburg2
Mat K = (Mat_<double>(3, 3) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1);
//-- 把匹配点转换为vector<Point2f>的形式
vector<Point2f> points1;
vector<Point2f> points2;
for (int i = 0; i < (int) matches.size(); i++) {
points1.push_back(keypoints_1[matches[i].queryIdx].pt);
points2.push_back(keypoints_2[matches[i].trainIdx].pt);
}
//-- 计算基础矩阵
Mat fundamental_matrix;
fundamental_matrix = findFundamentalMat(points1, points2, CV_FM_8POINT);
cout << "fundamental_matrix is " << endl << fundamental_matrix << endl;
//-- 计算本质矩阵
Point2d principal_point(325.1, 249.7); //相机光心, TUM dataset标定值
double focal_length = 521; //相机焦距, TUM dataset标定值
Mat essential_matrix;
essential_matrix = findEssentialMat(points1, points2, focal_length, principal_point);
cout << "essential_matrix is " << endl << essential_matrix << endl;
//-- 计算单应矩阵
//-- 但是本例中场景不是平面,单应矩阵意义不大
Mat homography_matrix;
homography_matrix = findHomography(points1, points2, RANSAC, 3);
cout << "homography_matrix is " << endl << homography_matrix << endl;
//-- 从本质矩阵中恢复旋转和平移信息.
// 此函数仅在Opencv3中提供
recoverPose(essential_matrix, points1, points2, R, t, focal_length, principal_point);
cout << "R is " << endl << R << endl;
cout << "t is " << endl << t << endl;
}
版权声明:本文为博主fish小余儿原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_25763027/article/details/122579005