1 概述
1.1 题目
2017CVPR:普适对抗扰动 (Universal adversarial perturbations)
1.2 方法
要点如下:
1)展示了对于给定的一个前沿神经网络分类器,只需要一个普适且极小的扰动就可以引发高概率的自然图像误分类;
2)提出了一种计算通用扰动的系统算法,并表明最先进的深度神经网络非常容易受到这种扰动的影响,而人眼几乎可以察觉;
3)进一步实证分析了这些普适扰动,并表明它们在神经网络中的良好泛化性能;
4)普适扰动的存在揭示了分类器的高维决策边界之间的重要几何相关性。进一步概述了在输入空间中存在单个方向的潜在安全漏洞,攻击者可能利用这些方向破坏大多数自然图像上的分类器。
1.3 代码
Tensorflow:https://github.com/LTS4/universal
Torch:https://github.com/NetoPedro/Universal-Adversarial-Perturbations-Pytorch
1.4 Bib
@inproceedings{Moosavi:2017:17651773,
author = {Seyed-Mohsen Moosavi-Dezfooli and Alhussein Fawzi and Omar Fawzi and Pascal Frossard},
title = {Universal adversarial perturbations},
booktitle = {{IEEE} Conference on Computer Vision and Pattern Recognition},
pages = {1765--1773},
year = {2017}
}
2 普适扰动
令表示图像在空间
上的分布,
是一个用于获取图像
评估标签
的分类器。本文的目的是寻找一个扰动向量
,其能够愚弄
在大部分满足
的数据点上的判断:
普适扰动代表了一个与图像无关的固定扰动,它会导致从数据分布中采样的大多数图像的标签发生变化。我们在这里关注分布
表示自然图像集的情况,因此它包含了大量可变性。在这种情况下去,对大多数图像进行误导的普适小扰动将被发掘。寻找
需要满足以下约束:
1) ;
2)。
这里用于控制
的强度,
用于控制误导率。
算法
令表示服从分布
的图像的集合。基于约束条件和优化目标,算法将在
上迭代并逐步构建普适扰动,如图2。在每次迭代中,计算将当前扰动点
发送到分类器的决策边界的最小扰动
,并将其聚合到普适扰动的当前实例。
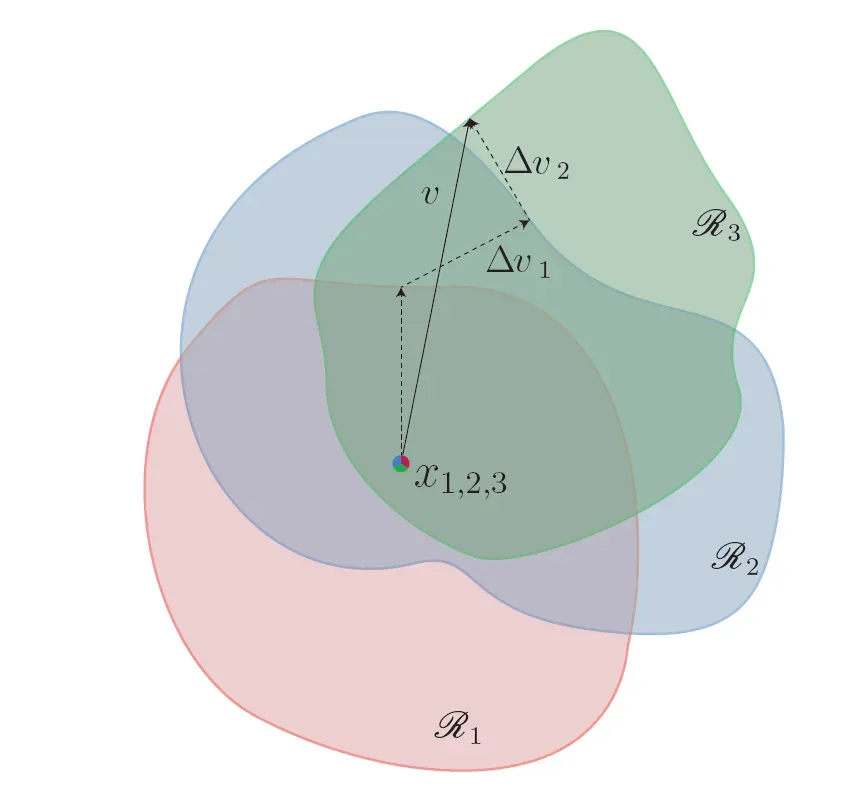
图2:所提出算法在计算普适扰动时的语义表示。点
、
,以及
处于叠加状态,不同的分类区域
展示为不同的颜色。算法的目的便是寻找最小扰动,使得点
移出正确的分类区域
假设当前的通用扰动不能愚弄数据点
,我们通过解决以下优化问题来寻找允许欺骗数据点
的最小范数的额外扰动
:
为了确保满足约束
,更新后的普适扰动进一步投影到半径为
、中心在
的
球上。因此,投影操作被定义为:
然后,更新规则变为
。对数据集
的多次传递将提高普适扰动的质量。算法将在扰动数据集
的愚弄率超过阈值
时停止:
算法1展示了更多的细节。
中的数据点数量
并不需要很大才能计算一个对整体分布
有效的普适扰动。特别的,
可以设置为一个比训练样本小得多的值。

所提算法涉及在每次传递时求解公式1中优化问题的至多个实例,这里采用Deepfool来高效处理该问题。值得注意的是,算法1并不能找到一个最小的愚弄尽可能多的样本点的普适扰动,只能找到一个有足够小范数的扰动。
不同的随机洗牌自然会导致满足所需约束的各种普适扰动
。
3 普适扰动与深度网络
本节分析前沿深度学习分类器应对算法1中普适扰动的健壮性。
第一个实验中,评估不同算法在ILSVRC 2012验证数据集上的普适扰动,并展示愚弄率,即图像标签将在普适扰动后改变的比例。实验将在;
和
下进行,其相应的
分别为
和
。选择这些数值是为了获得其范数明显小于图像范数的扰动,这样当添加到自然图像时,扰动是不可察觉的。表1展示了实验结果。每个结果都报告在用于计算扰动的集合
和验证集上(在计算通用扰动的过程中不使用)。结果展示了普适扰动有很高的愚弄率。

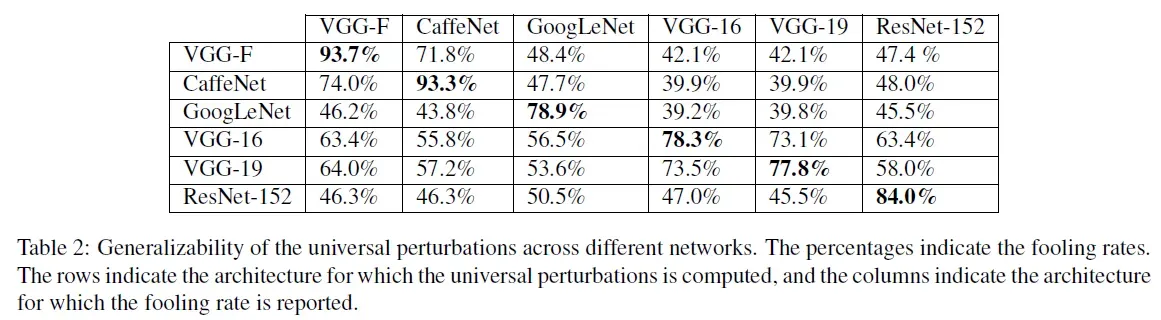
3.1 跨模型普适性
在未知数据点上计算扰动后,可以证明它们跨模型普适的,即在一个特别的网络上如VGG-19训练得到的扰动,依然可以在另一个网络上如GoogleNet上生效。表2展示了跨模型愚弄率。
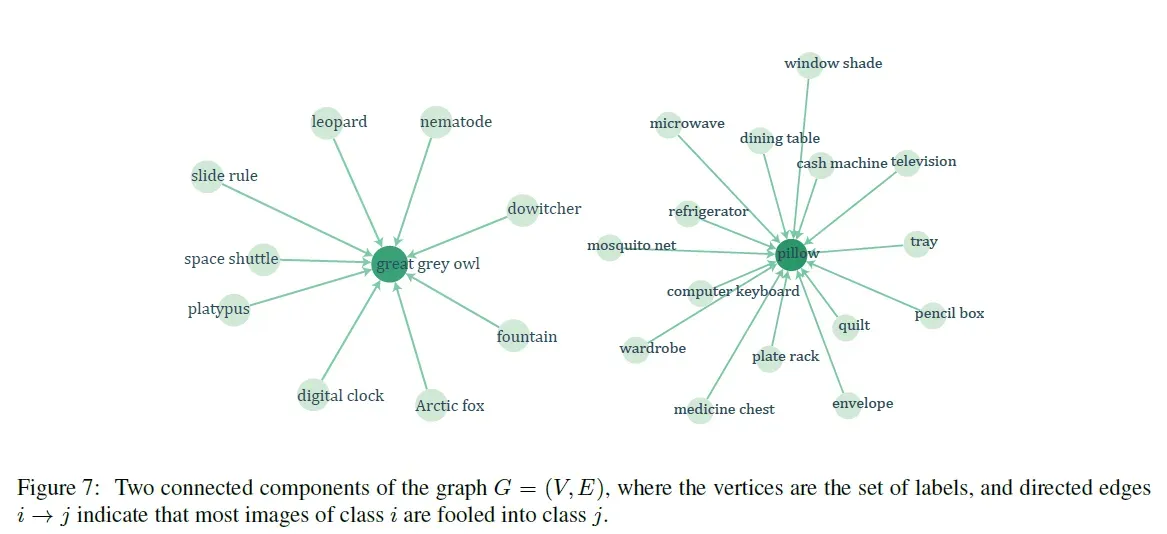
3.2 普适扰动性能的可视化
为了直观展示普适扰动在自然图像上的效用,我们将ImageNet验证集上的标签分布进行了可视化:无向图,其中定点表示标签,边
表示应用扰动后图标标签从
被误导至
,如图7。
3.3 普适扰动的微调
用于检验使用扰动图像进行微调后网络的性能。使用VGG-F架构,并基于修改后的训练集微调网络,其中将普适扰动添加到一小部分清洁的训练样本中:对于每个训练点,以0.5的概率添加通用扰动,并且原始样本以0.5的概率保留。为了解释普适扰动的多样性,10种预计算的不同的普适扰动将被随机选择。网络将在修改后的数据集上进行五次微调。微调时设置及
。结果展示愚弄率有所下降。
4 神经网络的脆弱性
本节用于说明神经网络对于普适扰动的脆弱性。首先和其他类型的扰动进行对比,来说明普适扰动的独特性,包括:
1)随机扰动;
2)对抗扰动;
3)上对抗扰动之和;
4)图像的均值。
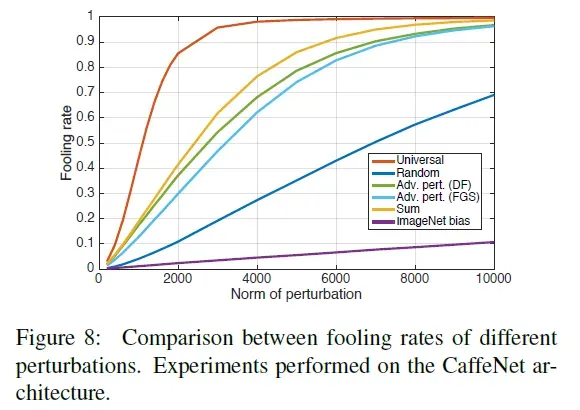
图8展示了不同扰动及
范数下的愚弄率。特别地,普适扰动和随机扰动之间的巨大差异表明,普适扰动利用分类器决策边界不同部分之间的一些几何相关性。 事实上,如果决策边界在不同数据点附近的方向完全不相关 (并且与决策边界的距离无关),则最佳普适扰动的范数将与随机扰动的范数相当。进一步,欺骗特定数据点所需的随机扰动范数精确地表现为
,其中
是输入空间的维度。对于ImageNet分类任务,有
。于大多数数据点而已,这比普适扰动 (
) 大一个量级。因此,随机扰动和普适扰动之间的这种实质性差异表明目前探索的决策边界的几何形状存在冗余。
对于验证集中的每一个图像,获取其对抗扰动向量为
。很明显
与分类器的决策边界在
处正交。因此
得以捕获决策边界在
临近区域的内的局部几何特征。为了量化分类器决策边界不同区域之间的相关性,定义了验证集中
个数据点附近决策边界的法向量矩阵:
对于二分类分类器,决策边界是超平面、
的秩为1,以及所有的法向量都是共线的。为了更普遍地捕捉复杂分类器决策边界中的相关性,我们计算矩阵
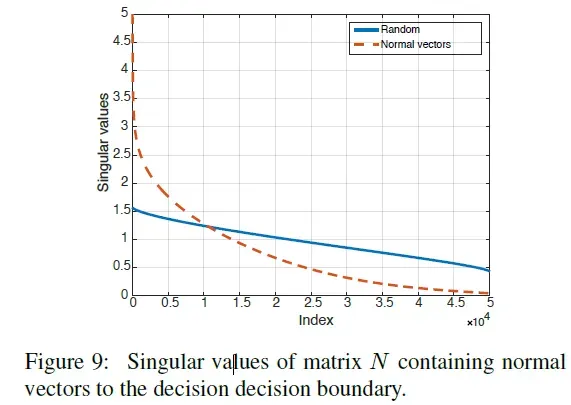
的奇异值。通过CaffeNet计算的矩阵
的奇异值如图9。图中展示了当
列从单位球体中随机均匀采样时获得的奇异值。虽然后者的奇异值衰减缓慢,但
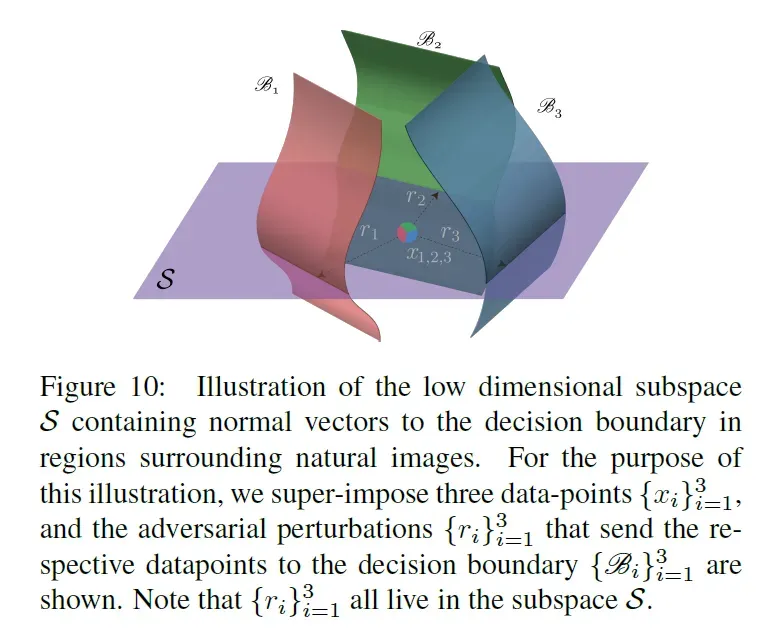
的奇异值衰减很快,这证实了深度网络的决策边界存在大的相关性和冗余。更准确地说,这表明存在低维
子空间
,它包含自然图像周围区域中决策边界的大多数法向量。假设愚弄大多数自然图像的普适扰动的存在是由于存在这样一个低维子空间,该子空间捕获了决策边界不同区域之间的相关性。事实上,这个子空间“收集”了不同区域决策边界的法线,因此属于这个子空间的扰动可能会欺骗数据点。为了验证这个假设,我们选择一个范数
的随机向量,属于由前100个奇异向量跨越的子空间
,并计算不同的图像集的愚弄率 (即一组尚未被用于计算SVD的图像)。这种扰动可以欺骗近38%的图像,从而表明在这个子空间
中的随机方向明显优于随机扰动 (这种扰动只能欺骗10%的数据)。
文章出处登录后可见!