原文标题 :Transactions in a Big Data World
大数据世界中的交易
为什么 ACID 支持对于模型预测的重现性至关重要?

抽象的。具有 ACID 保证的事务曾经是数据库管理系统的支柱。然而,随着 Streaming 和 NoSQL 的到来,交易被认为过于严格,难以在大数据平台上实现。最终一致性成为此类平台的规范,其中一些分布式节点可能在两者之间不一致——返回不同的值;所有节点在稍后的时间点收敛到相同的值。
然而,大数据平台/框架现在已经成熟到可以看到提供 ACID 支持的平台的复苏,例如 Delta Lake、Hudi、Iceberg。在本文中,我们以大数据世界中的事务为例,提供有关如何在此类场景中实现事务的必要背景。我们展示了一个具体的应用程序,说明 ACID 事务如何在启用数据历史化中发挥关键作用。
Transactions
一个事务可以被认为是由 Begin 和 Commit/Abort 操作封装的一组操作,具有以下属性 (ACID):
- 原子性:要么执行所有操作,要么不执行任何操作。在失败(中止)的情况下,属于事务的任何操作的效果都会被取消(回滚)。
- 一致性:每个事务将系统从一个一致状态移动到另一个一致状态。
- 隔离:为了提高性能,通常会同时执行多个事务。隔离要求这种并发执行的效果等同于串行执行的效果。这是通过确保事务的中间结果在成功完成(提交)之前不会外部化来实现的。
- 持久性:一旦事务提交,它的影响是持久的,即它们不应该被任何系统或软件崩溃破坏。
例如,让我们考虑经典的银行交易 t_b,它涉及将钱从账户 A 转移到另一个账户 B。交易包括两个操作——第一个操作从账户 A 取款,第二个操作将钱存入账户 B。比如说,事务的任何部分执行都会导致不一致的状态。原子性属性确保提款和存款操作要么成功,要么都失败。隔离属性确保帐户 A 和 B 的更改在 t_b 提交之前对其他事务不可见。原子性和隔离性共同保证了系统(账户 A 和 B)的一致性。
负责实现事务的软件通常称为事务管理器 (TM)。我们可以将 TM 的功能分为以下几个部分:
- 并发控制管理器 (CCM):CCM 确保隔离属性。并发控制机制允许以受控方式在并发事务之间共享资源。
- 恢复管理器 (RM):RM 负责在发生故障或软件/硬件崩溃时提供原子性和持久性属性。
- 日志管理器(LM):LM 负责将执行细节写入稳定存储。日志在恢复中发挥重要作用的同时,也用于分析和提高系统性能和效率。
虽然事务已被接受为提供容错和可靠性的标准手段,但当我们尝试将它们应用于分布式环境时,新的挑战出现了。
Distributed Transactions — 2PC
分布式事务由在通过通信网络连接的不同站点执行的操作组成。分布式事务起源于一个站点(也称为主站点/根站点),逐渐涉及其他站点,属于该事务的操作被转发执行。集中式系统和分布式系统中事务处理的主要区别如下:
- 决策制定:提交/中止事务的决策不限于单个 TM。相反,需要根据所有相关站点的 TM 的决定做出集体决定。
- 多点故障:对于集中式系统,系统要么工作要么不工作。但是,在分布式系统中,我们可能会出现部分故障,因为一些相关站点发生故障而其他站点仍在工作。
因此,我们需要一个协议来确保在所有涉及的站点上始终如一地执行相同的决定(提交/中止),而不管部分失败。两阶段提交(2PC)协议可能是解决上述问题最广泛接受的解决方案。主站点的 TM 充当协调者,而所有其他相关站点的 TM 充当参与者的角色。顾名思义,2PC 协议由两个阶段组成。在第一阶段,协调者 TM 向所有参与者 TM 发送 PREPARE 消息。每个参与者 TM 根据是否要提交/中止投票是/否。如果协调器 TM 收到所有参与者 TM 的“是”,那么它通过向所有参与者发送 COMMIT 消息来开始协议的第二阶段。但是,如果它从至少一个参与者 TM 处收到“否”,则它通过向所有参与者 TM 发送 ABORT 消息来启动第二阶段。最后,协调者 TM 等待参与者 TM 的确认以完成第二阶段。
Compensation — Sagas
虽然上述协议适用于紧密耦合的分布式应用程序,但它对长时间运行和松散耦合的应用程序的适用性是有限的。为了确保 ACID 属性(在集中式场景中),需要保持锁定直到事务提交。
这在性能方面不是一个理想的情况,尤其是对于长时间运行的事务而言——锁定必须保持到所有相关(协调器和参与者)站点都准备好提交。
对上述限制的一个优雅解决方案是嵌套事务 [1] 的概念。嵌套事务允许相关站点的 TM 通过以受控方式外部化中间结果在事务在本地完成后立即释放其锁定。基本上,全局事务(提交给根 TM)被划分为多个可以并发执行的子事务。虽然全局事务的 ACID 属性得到保证,但子事务并没有完全隔离,因为它们的结果会暴露给它们的父级。甚至子事务的持久性也无法保证,因为如果其父事务中止,则可能需要取消其效果(在提交之后)。
虽然嵌套事务的概念在一定程度上解决了性能问题,但它仍然需要相关 TM 的一定保证。然而,考虑到松散耦合分布式系统的自治性和异构性要求,这种保证可能并不总是可行的。 Sagas [2] 或 Open Nested Transactions [3] 通过允许子事务产生的中间结果不受任何限制地公开来缓解这个问题。
Sagas 依靠补偿事务的概念 [4] 来确保发生故障时的原子性。基本上,对于每个事务 t,指定一个能够在语义上撤销事务 t 影响的补偿事务 t_c。
在失败的情况下,通过按照各自事务的原始执行顺序的相反顺序执行补偿事务来保证原子性。补偿交易的经典示例是“取消预订”或“取款”,它们分别能够撤销“预订票”或“存款”交易的影响。在这里,请记住,补偿可能并不总是可能的,特别是对于现实生活中的交易。
总而言之,不同级别的补偿可能具有不同的成本。
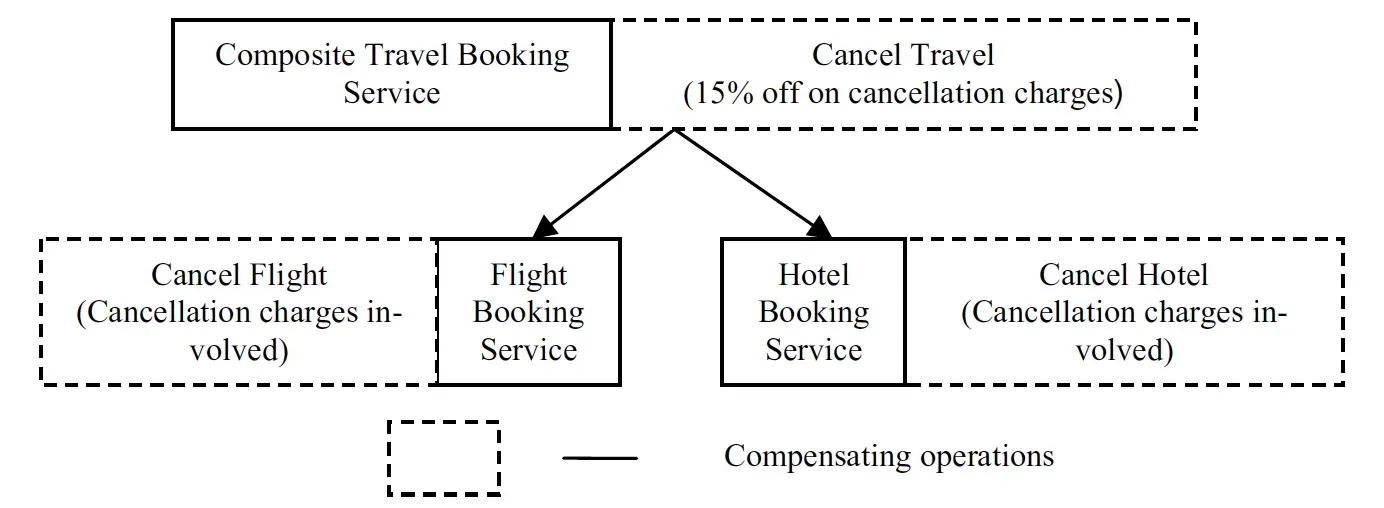
例如,让我们考虑经典的旅行预订场景(图 1)。如果需要对酒店或航班预订进行补偿,则可以通过在酒店或航班预订站点分别调用补偿(取消)操作或在复合旅行预订站点调用补偿操作(取消旅行)来实现。现在,如果我们假设用户是复合旅行预订网站的主要成员,因此可以在所有取消费用上获得 15% 的折扣,那么(从用户的角度来看)调用 Cancel Travel 操作是有益的复合旅游预订网站。
大数据环境中的交易
在本节中,我们将介绍一些提供 ACID 支持的关键数据平台/框架。然后,我们在启用 upsert/merge 操作方面展示了一个具体的应用程序——这对于实现数据历史化至关重要。
Delta Lake 是一个开源框架,可将 ACID 事务引入 Apache Spark 和大数据工作负载。可以下载开源 Delta Lake 并将其与 HDFS 一起使用。该框架允许从任何支持 Apache Spark 数据源的存储系统中读取数据并写入以 Parquet 格式存储数据的 Delta Lake。技术细节参见[5]。[0]
ACID 事务提供了 Delta Lake 的关键“时间旅行”功能,允许在特定时间点探索数据,支持访问和回滚到早期版本的数据——这对于审计和模型预测的可重复性至关重要。
可以在这里使用的替代数据平台/框架包括 Apache Hudi 和 Apache Iceberg。 Hudi 遵循传统的基于“事务日志”的方法,带有时间戳的数据文件和跟踪数据文件中记录更改的日志文件。 Iceberg 使用以下元数据层次结构提供 ACID 支持:[0][1]
- table ‘metadata files’
- 对应于表格快照的“清单列表”
- 定义可以成为多个快照一部分的数据文件组的“清单”
表写入创建一个新快照,该快照可以与并发查询并行运行(返回最后一个快照值)。并发写入遵循乐观并发控制协议,第一个提交的事务成功;导致所有其他冲突的并发事务重新启动。
我们展示了 ACID 事务如何在数据历史化中发挥关键作用。
Data Historization
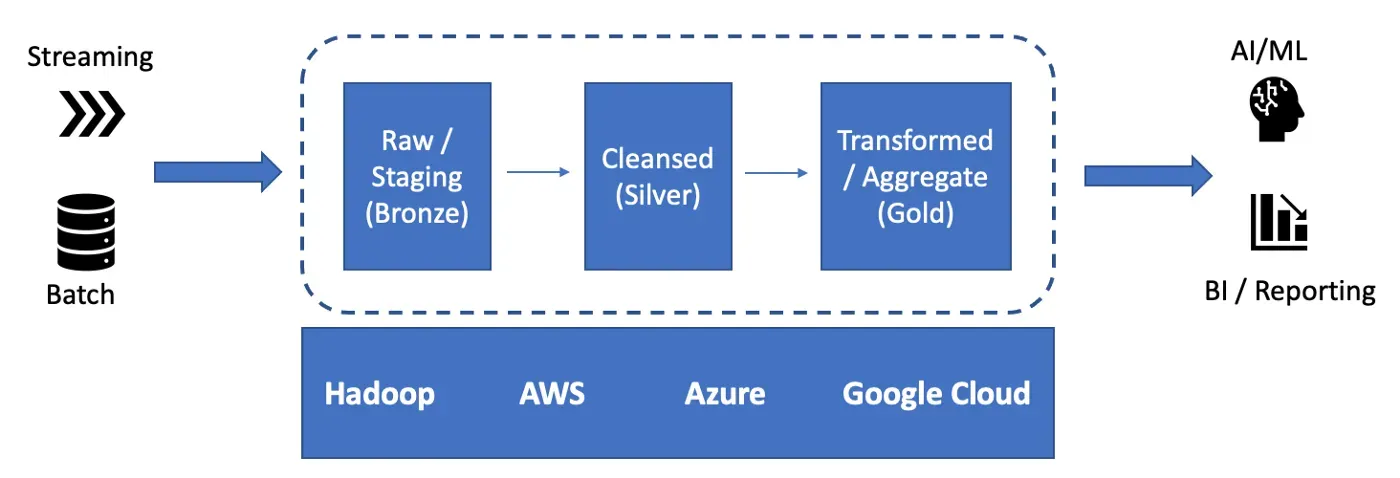
历史化是跟踪数据随时间变化的过程。它适用于数据平台的所有层(图 2):采集到“原始”(青铜)中的源数据,“精炼”(银)中的清理数据,“策划”(金)中的转换数据。
主要有两种数据历史化方法:
- 缓慢变化的维度类型 2 (SCD2):每次一个或多个列值发生变化时,变化历史都会为标识符添加一条新记录。例如,分别在 AWS 和 Oracle 云平台上实现 SCD2 的详细信息,请参阅 [6, 7]。
- 每当来自源系统的数据交付到达时,快照的历史记录都会为标识符添加一条新记录,无论它是否包含更改。
鉴于存储成本低(尤其是原始和暂存层)、易于实施和对迟到数据的鲁棒性,这种方法在大数据环境中越来越受欢迎。
Hybrid approach:
原始/暂存层的快照历史记录:实现一个持久暂存区域,作为源数据交付的永久存档。这允许在源数据被显式建模之前对其进行加载和历史记录,并作为一种保险来防止策展层/聚合数据存储中的建模错误。
将 SCD2 用于策划层/聚合数据存储:
SCD2 仍然是 Curated 层最流行的历史化技术。创建新记录时,之前的记录需要过期。这由多个操作组成(请参阅下面的示例表进行说明):

- 在当前数据集中查找记录,将现有记录的eff_end_data设置为新记录的eff_start_date,并将现有记录的is_current标志设置为’false’
- Insert new record.
Delta Lake / Hudi / Iceberg 及其对 ACID 事务的支持使得以可靠和可扩展的方式执行此类 Upsert (Merge) 操作成为可能。
References
- T.E.B.苔藓。嵌套事务:可靠分布式计算的方法。博士论文,麻省理工学院计算机科学实验室,1981 年。
- H. Garcia-Molina 和 K. Salem。萨加斯。在 Stonebraker,M. ed。数据库系统中的读数,加利福尼亚州旧金山,1987,290–300。
- G. Weikum,A. 执事,W. Schaad,H.-J。谢克。在联合数据库系统中打开嵌套事务。 IEEE 数据工程公告,16(2):4-7,1993 年 6 月。
- D. 比斯瓦斯。 Web 服务组合世界中的补偿。在:语义 Web 服务和 Web 过程组合。 SWSWPC 2004。计算机科学讲义,第 3387 卷。https://doi.org/10.1007/978-3-540-30581-1_7[0]
- M. Armbrust 等。人。 Delta Lake:基于云对象存储的高性能 ACID 表存储。过程。 VLDB 赋予。 13 日,12 日(2020 年 8 月),3411–3424。 https://doi.org/10.14778/3415478.3415560[0]
- D.格林施泰因。在 Amazon EMR 上使用 Apache Spark 和 Apache Hudi 构建渐变维度类型 2 (SCD2),2021 年,https://aws.amazon.com/blogs/big-data/build-slowly-sharing-dimensions-type-2-scd2 -with-apache-spark-and-apache-hudi-on-amazon-emr/[0]
- A.杜武里。 Oracle 云基础设施 (OCI) 数据集成中的渐变维度 (SCD) 类型 2 实施,2020 年,https://blogs.oracle.com/dataintegration/post/slowly-sharing-dimensions-scd-type-2-implementation-in -oracle-cloud-infrastructure-oci-数据集成[0]
文章出处登录后可见!