原文标题 :Creating a Custom Gym Environment for Jupyter Notebooks
婴儿机器人强化学习指南[0]
为 Jupyter Notebooks 创建自定义 Gym 环境
第 1 部分:创建框架

Overview
本文(分为两部分)描述了为强化学习 (RL) 问题创建自定义 OpenAI Gym 环境。[0]
已经有相当多的教程展示了如何创建自定义 Gym 环境(请参阅参考资料部分以获得一些好的链接)。在所有这些示例中,实际上在最常见的 Gym 环境中,它们会产生基于文本的输出(例如 Frozenlake)或出现在单独图形窗口中的基于图像的输出(例如 Lunar Lander)。[0][1][2]
相反,我们将创建一个在 Jupyter 笔记本中生成其输出的自定义环境。环境的图形表示将直接写入笔记本单元并实时更新。此外,它可以在任何测试框架中使用,并与任何实现 Gym 接口的 RL 算法一起使用。
在文章的最后,我们将创建一个自定义的 Gym 环境,可以对其进行定制以生成一系列不同的网格世界供 Baby Robot 探索,并呈现类似于上面显示的封面图像的输出。
Code
本文相关的 Jupyter Notebook 可以在 Github 上找到。这包含设置和运行下面描述的 Baby Robot 自定义 Gym 环境所需的所有代码。[0][1]

Introduction
到目前为止,在我们的强化学习 (RL) 系列中,我们使用定制环境来表示 Baby Robot 发现自己的位置。从一个简单的网格世界开始,我们添加了墙壁和水坑等组件,以增加 Baby Robot 面临的挑战的复杂性。[0]
既然我们已经了解了 RL 的基础知识,并且在我们转向更复杂的问题和算法之前,似乎是时候将 Baby Robot 的环境形式化。如果我们给这个环境一个固定的、定义好的接口,那么我们可以在所有问题中重用相同的环境,并使用多种 RL 算法。当我们继续研究不同的 RL 方法时,这将使事情变得简单得多。
通过采用通用接口,我们可以将该环境放入任何现有的也实现相同接口的系统中。我们需要做的就是决定我们应该使用什么接口。幸运的是,这已经完成了,它被称为 OpenAI Gym 界面。
OpenAI Gym 简介
OpenAI Gym 是一组强化学习 (RL) 环境,其问题范围从简单的网格世界到复杂的物理引擎。[0]
这些环境中的每一个都实现了相同的接口,从而可以轻松地使用一系列不同的 RL 算法测试单个环境。类似地,它可以直接在一系列不同问题上评估单个 RL 算法。
因此,OpenAI Gym 已成为学习和对 RL 算法进行基准测试的事实上的标准。
OpenAI 健身房界面
所有 OpenAI Gym 环境的界面可以分为 3 个部分:
1. 初始化:创建并初始化环境。
2.执行:在环境中重复执行动作。在每一步,环境都会提供信息来描述它的新状态以及由于采取特定行动而获得的奖励。这种情况一直持续到环境信号表明情节已完成。
3. 终止:清理和破坏环境。
示例:CartPole 环境
Gym 中比较简单的问题之一是 CartPole 环境。在这个问题中,目标是向左或向右移动手推车,以使在手推车上保持平衡的杆保持直立。[0]

设置和运行此 Gym 环境的代码如下所示。在这里,我们只是随机选择左或右动作,所以杆子不会停留很长时间!
在清单 1 中,如上所示,我们标记了 Gym 环境的 3 个阶段。更详细地说,它们中的每一个都执行以下操作:
1. Initialisation
env = gym.make(‘CartPole-v0’)- 创建所需的环境,在本例中为 CartPole 的版本“0”。然后可以使用返回的环境对象“env”来调用通用 Gym 环境接口中的函数。
obs = env.reset()- 在每集开始时调用,这会将环境置于其起始状态并返回对环境的初始观察。
2. Execution
在这里,我们一直运行,直到设置环境“完成”标志以指示剧集已完成。如果代理已达到终止状态或已执行固定数量的步骤,则可能会发生这种情况。
env.render()- 绘制环境的当前状态。对于 CartPole,这将导致打开一个新窗口以显示购物车及其杆的图形视图。在更简单的环境中,例如 FrozenLake 简单的网格世界,会显示文本表示。[0]
action = env.action_space.sample()- 从环境的一组可能动作中选择一个随机动作。
obs, reward, done, info = env.step(action)- 采取行动并从环境中获取有关此行动结果的信息。这包括4条信息:
- ‘obs’:定义环境的新状态。在 CartPole 的情况下,这是关于杆的位置和速度的信息。在网格世界环境中,它将是关于下一个状态的信息,我们在采取行动后最终到达的位置。
- ‘reward’:由于采取行动而获得的奖励金额(如果有)。
- ‘done’:指示我们是否已到达剧集结尾的标志
- “信息”:任何附加信息。一般没有设置。
3. Termination
env.close()- 终止环境。这也将关闭任何可能由渲染函数创建的图形窗口。
创建自定义健身房环境
如前所述,使用 OpenAI Gym 的主要优势在于每个环境都使用完全相同的界面。我们可以将上面“gym.make”行中的环境名称字符串“CartPole-v0”替换为任何其他环境的名称,其余代码可以保持完全相同。
对于任何实现 Gym 接口的自定义环境也是如此。所需要的只是一个继承自 Gym 环境并添加上述功能集的类。
下面显示了我们要创建的自定义“BabyRobotEnv”的初始框架(类名后面的“_v0”表示这是我们环境的零版本。我们将在添加功能时更新它):
在我们自定义环境的这个基本框架中,我们从基础“gym.Env”类继承了我们的类,它为我们提供了创建环境所需的所有主要功能。为此,我们添加了将类转换为我们自己的自定义环境所需的 4 个函数:
- ‘__init__’:类初始化,我们可以在其中设置类所需的任何内容
- ‘step’:实现当 Baby Robot 在环境中迈出一步时会发生什么,并返回描述迈出该步骤的结果的信息。
- ‘reset’:在每一集开始时调用,以将环境恢复到初始状态。
- ‘render’:提供基于图形或文本的环境表示,以允许用户查看事情的进展情况。
我们还没有实现“关闭”功能,因为目前没有要关闭的东西,所以我们可以只依靠基类来做任何需要的清理工作。此外,我们还没有添加任何功能。我们的类满足 Gym 接口的要求,并且可以在 Gym 测试工具中使用,但目前它不会做太多事情!
行动和观察空间
上面的代码定义了自定义环境的框架,但是它还不能运行,因为它目前没有“action_space”来采样随机动作。 “action_space”定义了代理可以在环境中采取的一组动作。这些可以是离散的、连续的或两者的组合。
- 离散动作表示一组互斥的可能动作,例如 CartPole 环境中的左右动作。在任何时间步,您都可以选择左或右,但不能同时选择两者。
- 连续动作是具有关联值的动作,它表示要采取的动作的数量。例如,当转动方向盘时,可以指定一个角度来表示方向盘应该转动多少。
我们正在创建的 Baby Robot 环境就是所谓的网格世界。换句话说,它是一个正方形网格,Baby Robot 可以在其中从一个正方形移动到另一个正方形,以探索和导航环境。此环境中的默认级别将是 3 x 3 网格,起点在左上角,出口在右下角,如图 2 所示:

因此,对于我们正在创建的自定义 BabyRobotEnv,只有 4 种可能的移动动作:北、南、东或西。此外,我们将添加一个“Stay”动作,让 Baby Robot 保持在当前位置。因此,我们总共有 5 个互斥动作,因此我们将动作空间设置为定义 5 个离散值:
self.action_space = gym.spaces.Discrete(5)除了 action_space,所有环境都需要指定一个“observation_space”。这定义了当代理接收到关于环境的观察时提供给代理的信息。
当婴儿机器人在环境中迈出一步时,我们想要返回他的新位置。因此,我们将定义一个观察空间,将网格位置指定为“x”和“y”坐标。
Gym 接口定义了几个不同的“空间”,可以用来指定我们的坐标。例如,如果我们的坐标是连续的、浮点的,我们可以使用 Box 空间。这也可以让我们对可用于“x”和“y”坐标的值的可能范围设置一个限制。此外,我们可以将这些组合起来,使用 Gym 的 Dict 空间形成环境观察空间的单一表达式。[0][1][2]
然而,由于我们只允许从一个方格到下一个方格的整体移动(而不是在方格之间的中间),我们将以整数指定网格坐标。因此,与动作空间一样,我们将使用一组离散的值。但是现在,我们有两个值,而不是只有一个离散值:“x”和“y”坐标中的每一个。对我们来说幸运的是,Gym 界面有这个东西,MultiDiscrete 空间。[0]
在水平方向上,最大“x”位置以网格宽度为界,在垂直“y”方向上以网格高度为界。因此,观察空间可以定义如下:
self.observation_space = MultiDiscrete([ self.width, self.height ])离散空间是从零开始的,所以我们的坐标值将从零到比定义的最大值小一。
通过这些更改,BabyRobotEnv 类的新版本如下所示:
关于新版本的 BabyRobotEnv 类有几点需要注意:
- 我们为 init 函数提供了一个 kwargs 参数,让我们使用参数字典创建我们的实例。在这里,我们只是要提供我们想要制作的网格的宽度和高度,但接下来我们可以使用它来传递其他参数,并且通过使用 kwargs,我们可以避免更改类的接口。
- 当我们从 kwargs 中获取宽度和高度时,如果没有提供参数,在这两种情况下我们都默认为 3。因此,如果在创建环境期间未提供任何参数,我们将得到一个大小为 3×3 的网格。
- 我们现在已经使用“self.x”和“self.y”定义了 Baby Robot 在网格中的位置,我们现在将其作为“reset”和“step”函数的观察结果返回。在这两种情况下,我们都将这些值转换为 numpy 数组,虽然不需要匹配 Gym 接口,但 Stable Baseline 的环境检查器需要它,这将在下一节中介绍。
测试自定义环境
在我们开始添加任何真正的功能之前,有必要确认我们的新环境符合 Gym 界面。为了测试这一点,我们可以使用稳定基线环境检查器来验证我们的类。[0]
此测试不仅测试我们是否已实现 Gym 接口所需的功能,而且还检查动作和观察空间是否设置正确,以及功能响应是否与相关的观察空间匹配。
关于环境检查器需要注意的一点是,除了验证环境是否符合 Gym 标准外,它还检查环境是否适合使用 Stable Baseline 的 RL 算法集运行。作为其中的一部分,它期望观察结果以 numpy 数组的形式返回,这就是为什么它们被添加到上面显示的“reset”和“step”函数中。
要运行检查,只需创建环境实例并将其提供给“check_env”函数即可。如果有任何问题,则会显示警告消息。如果没有输出,那么一切都很好。
from stable_baselines3.common.env_checker import check_env
# create an instance of our custom environment
env = BabyRobotEnv_v1()
# returns nothing if the environment is verified as ok
check_env(env)我们还可以查看环境的动作和观察空间,以确保它们返回预期值:
print(f”Action Space: {env.action_space}”)
print(f”Action Space Sample: {env.action_space.sample()}”)应该给出类似于以下的输出:
Action Space: Discrete(5)
Action Space Sample: 3
- 正如预期的那样,动作空间是一个具有 5 个可能值的离散空间。
- 从动作空间采样的值将是 0 到 4 之间的随机值。
对于观察空间:
print(f"Observation Space: {env.observation_space}")
print(f"Observation Space Sample: {env.observation_space.sample()}")应该给出类似于以下的输出:
Observation Space: MultiDiscrete([3 3])
Observation Space Sample: [0 2]
- 观察空间有一个 MultiDiscrete 类型,它的两个组件每个都有 3 个可能的值(因为我们创建了一个默认的 3×3 网格)。
- 从该网格的观察空间中采样时,“x”和“y”都可以取值 0、1 或 2。
Creating the Environment
你可能已经注意到,在上面的测试中,我们没有像我们为 CartPole 所做的那样使用“gym.make”创建环境,而是通过以下方式简单地创建了它的一个实例:
env = BabyRobotEnv()这在我们自己使用环境时绝对没问题,但是如果我们想将我们的自定义环境注册为适当的 Gym 环境,可以使用“gym.make”创建,那么我们需要采取一些进一步的步骤.
首先,从 Gym 文档中,我们需要设置我们的文件和目录,其结构类似于如下所示:[0]
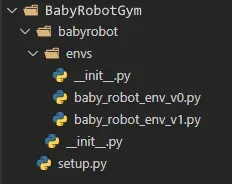
所以我们需要3个目录:
- 保存我们的“setup.py”文件的主目录(在本例中为“BabyRobotGym”)。该文件定义了项目目录的名称并引用了所需的资源,在本例中就是“gym”库。该文件的内容如下图所示:
from setuptools import setup
setup(
name="babyrobot",
version="1.0.0",
install_requires=['gym']
)2. 项目目录,与设置文件的“name”参数同名。因此,在这种情况下,该目录称为“babyrobot”。这包含一个文件“__init.py__”,它定义了环境的可用版本:
from gym.envs.registration import register
register(
id='BabyRobotEnv-v0',
entry_point='babyrobot.envs:BabyRobotEnv_v0',
)
register(
id='BabyRobotEnv-v1',
entry_point='babyrobot.envs:BabyRobotEnv_v1',
)
3. 主要功能所在的“envs”目录。在我们的例子中,它包含我们上面定义的两个版本的 Baby Robot 环境(“baby_robot_env_v0.py”和“baby_robot_env_v1.py”)。这些定义了在“babyrobot/__init__.py”文件中引用的两个类。
此外,此目录包含其自己的“__init__.py”文件,该文件引用目录中包含的两个文件:
from .baby_robot_env_v0 import BabyRobotEnv_v0
from .baby_robot_env_v1 import BabyRobotEnv_v1我们现在已经定义了一个可以上传到存储库(例如 PyPi)的 Python 包,以便轻松共享您的新创建。此外,有了这个结构,我们现在可以导入我们的新环境并使用“gym.make”方法创建它,就像我们之前为 CartPole 所做的那样:[0]
import babyrobot# create an instance of our custom environment
env = gym.make(‘BabyRobotEnv-v1’)
请注意,用于指定环境的名称是用于注册它的名称,而不是类名。因此,在这种情况下,虽然类名为“BabyRobotEnv_v1”,但注册名称实际上是“BabyRobotEnv-v1”。
克隆 Github 存储库
为了更容易检查上述目录结构,可以通过克隆 Github 存储库来重新创建它。执行此操作的步骤如下:
1.获取代码并移动到新创建的目录:
git clone https://github.com/WhatIThinkAbout/BabyRobotGym.git
cd BabyRobotGym- 这个目录包含我们上面定义的文件和文件夹结构(加上我们将在第 2 部分中看到的一些额外的)。
2.创建Conda环境并安装所需的包:
为了能够运行我们的环境,我们需要安装一些其他包,最值得注意的是“Gym”本身。为了便于设置环境,Github 存储库包含几个列出所需包的“.yml”文件。
要使用这些来创建 Conda 环境并安装软件包,请执行以下操作(选择适合您的操作系统的一个):
On Unix:
conda env create -f environment_unix.ymlOn Windows:
conda env create -f environment_windows.yml3. Activate the environment:
我们已经创建了包含所有必需包的环境,所以现在只需激活它,如下所示:
conda activate BabyRobotGym(当你玩完这个环境后,运行“conda deactivate”退出)
4. Run the notebook
现在一切都应该准备就绪,可以运行我们的自定义 Gym 环境。为了测试这一点,我们可以运行存储库中包含的示例 Jupyter Notebook ‘baby_robot_gym_test.ipynb’。这将加载“BabyRobotEnv-v1”环境并使用稳定基线的环境检查器对其进行测试。
要在浏览器中启动它,只需键入:
jupyter notebook baby_robot_gym_test.ipynb或者,只需在 VS Code 中打开此文件并确保选择“BabyRobotGym”作为内核。这应该会创建“BabyRobotEnv-v1”环境,在 Stable Baselines 中对其进行测试,然后运行该环境直到完成,这恰好发生在一个步骤中,因为我们还没有编写“step”函数!
Adding Actions
尽管当前版本的自定义环境满足 Gym 界面的要求,并且具备通过环境检查器测试所需的功能,但它还没有做任何事情。我们希望 Baby Robot 能够在他的环境中四处走动,为此我们需要他能够采取一些行动。
由于 Baby Robot 将在一个简单的 Grid World 环境中运行(参见上图 2),因此他可以采取的行动将仅限于向北、向南、向东或向西移动。此外,我们希望他能够留在同一个地方,如果这是最佳行动的话。所以我们总共有 5 种可能的动作(正如我们已经在动作空间中看到的那样)。
这可以使用 Python 整数枚举来描述:
from enum import IntEnum
''' simple helper class to enumerate actions in the grid levels '''
class Actions(IntEnum):
Stay = 0
North = 1
East = 2
South = 3
West = 4
# get the enum name without the class
def __str__(self): return self.name 为了简化代码,我们可以从之前的“BabyRobotEnv_v1”类继承。这为我们提供了所有以前的功能和行为,然后我们可以扩展它们以添加与操作相关的新部分。如下所示:
class BabyRobotEnv_v2( BabyRobotEnv_v1 ):
metadata = {'render_modes': ['human']}
def __init__(self, **kwargs):
super().__init__(**kwargs)
# the start and end positions in the grid
# - by default these are the top-left and bottom-right respectively
self.start = kwargs.get('start',[0,0])
self.end = kwargs.get('end',[self.max_x,self.max_y])
# Baby Robot's initial position
# - by default this is the grid start
self.initial_pos = kwargs.get('initial_pos',self.start)
# Baby Robot's position in the grid
self.x = self.initial_pos[0]
self.y = self.initial_pos[1]
def take_action(self, action):
''' apply the supplied action '''
# move in the direction of the specified action
if action == Actions.North: self.y -= 1
elif action == Actions.South: self.y += 1
elif action == Actions.West: self.x -= 1
elif action == Actions.East: self.x += 1
# make sure the move stays on the grid
if self.x < 0: self.x = 0
if self.y < 0: self.y = 0
if self.x > self.max_x: self.x = self.max_x
if self.y > self.max_y: self.y = self.max_y
def step(self, action):
# take the action and update the position
self.take_action(action)
obs = np.array([self.x,self.y])
# set the 'done' flag if we've reached the exit
done = (self.x == self.end[0]) and (self.y == self.end[1])
# get -1 reward for each step
# - except at the terminal state which has zero reward
reward = 0 if done else -1
info = {}
return obs, reward, done, info
def render(self, mode='human', action=0, reward=0 ):
if mode == 'human':
print(f"{Actions(action): <5}: ({self.x},{self.y}) reward = {reward}")
else:
super().render(mode=mode) # just raise an exception 已添加到类中的新功能执行以下操作:
- 在“__init__”函数中,可以提供关键字参数来指定环境中的开始和结束位置以及 Baby Robot 的开始位置(默认设置为网格的开始位置)。
- “take_action”函数只是通过应用提供的动作来更新 Baby Robot 的当前位置,然后检查新位置是否有效(以阻止他离开网格)。
- “step”函数应用当前动作,然后获得新的观察和奖励,然后将其返回给调用者。默认情况下,每次移动都会返回 -1 的奖励,除非 Baby Robot 已经到达结束位置,在这种情况下,奖励设置为零并且“完成”标志设置为 true。
- ‘render’ 函数打印出当前位置和奖励。
所以,最后,我们现在可以采取行动,从一个单元格移动到另一个单元格。然后,我们可以使用上面清单 1 的修改版本(从使用 CartPole 改为使用我们最新的 BabyRobot_v2 环境)来选择随机动作并在网格中移动,直到 Baby Robot 到达已指定为网格出口的单元格(默认情况下是单元格(2,2))。
我们新环境的测试框架如下图所示:
env = BabyRobotEnv_v2()
# initialize the environment
env.reset()
done = False
while not done:
# choose a random action
action = env.action_space.sample()
# take the action and get the information from the environment
new_state, reward, done, info = env.step(action)
# show the current position and reward
env.render(action=action, reward=reward) 当我们运行它时,我们会得到一个类似于下图的输出。
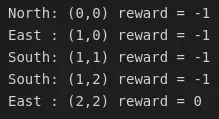
在这种情况下,通过网格的路径非常短,只需几步即可从起始方格 (0,0) 移动到出口 (2,2)。由于动作是随机选择的,因此路径通常会更长。另请注意,每一步都会收到 -1 的奖励,直到到达出口为止。所以Baby Robot到达出口的时间越长,返回值越负。
创建渲染函数
从技术上讲,我们已经创建了渲染函数,只是它不是很令人兴奋!如图 4 所示,我们得到的只是描述动作、位置和奖励的简单文本消息。我们真正想要的是环境的图形表示,显示婴儿机器人在网格世界中移动。
如上所述,Gym 库中的环境集合执行它们的渲染,以显示环境的当前状态,方法是生成基于文本的表示或创建包含图像的数组。
基于文本的表示提供了一种在基于终端的应用程序中呈现环境的快速方法。当您只需要对当前状态的简单概述时,它们是理想的选择。
另一方面,图像提供了当前状态的非常详细的图片,非常适合创建剧集的视频,在剧集完成后显示。
虽然这两种表示方式都很有用,但都不适用于在 Jupyter Notebooks 中工作时创建实时、详细的环境状态视图。当 Baby Robot 围绕网格级别移动时,我们希望看到他实际移动,而不仅仅是收到描述其位置的文本消息,或观看简单的文本绘图,“X”在点网格上移动。
此外,我们希望在剧集展开时看到这种情况的发生,而不是只能在之后观看,或者实时在闪烁的显示中看到它。简而言之,我们希望使用不同的方法来呈现文本字符或图像数组。我们可以通过使用优秀的 ipycanvas 库绘制到 HTML5 Canvas 来实现这一点,我们将在第 2 部分中全面介绍这一点。[0]
Summary
OpenAI Gym 环境是测试强化学习算法的标准方法。基础集合带有大量多样且具有挑战性的问题。但是,在许多情况下,您可能希望定义自己的自定义环境。通过实现 Gym 环境的结构和界面,很容易创建这样一个环境,它将无缝地插入任何同样使用 Gym 界面的应用程序中。
综上所述,创建自定义 Gym 环境的主要步骤如下:
- 创建一个继承自 env.Gym 基类的类。
- 实现“reset”、“step”和“render”功能(如果需要整理资源,还可以实现“close”功能)。
- 定义动作空间,以指定环境允许的动作的数量和类型。
- 定义观察空间,以描述在每个步骤中提供给代理的信息,并为环境中的移动设置边界。
- 整理目录结构并添加‘__init__.py’和‘setup.py’文件以匹配Gym规范并使环境与Gym框架兼容。
遵循这些步骤将为您提供一个基本框架,您可以从中开始添加自己的自定义功能,以根据您自己的特定问题定制环境。
在我们的例子中,我们想要创建一个 Baby Robot 可以探索的网格世界环境。此外,我们希望能够以图形方式查看此环境并观察 Baby Robot 在其周围移动时的情况。在第 2 部分中,我们将看到如何实现这一点。
References:
- The Gym library:
2. 稳定基线环境检查器:
3. 关于具有稳定基线的自定义健身房环境的优秀 YouTube 视频:
完整的 Baby Robot 强化学习指南系列可以在这里找到……[0]
文章出处登录后可见!