一、前言
在YouTube上看到up主——Nicholas Renotte的相关教程,觉得非常有用。使用他的方法,我训练了能够检测四种手势的模型,在这里和大家分享一下。
附上该up主的视频链接Sign Language Detection using ACTION RECOGNITION with Python | LSTM Deep Learning Model
视频的代码链接https://github.com/nicknochnack/ActionDetectionforSignLanguage
我的系列文章一:Mediapipe入门——搭建姿态检测模型并实时输出人体关节点3d坐标
我的系列文章二:Mediapipe姿态估计——用坐标计算手指关节弯曲角度并实时标注
我使用的环境
Pycharm2021
mediapipe0.8.9
tensorflow2.3.0
openCV4.5.4
个人认为版本影响不大,可以跟我不一致,但tensorflow最好2.0以上
二、使用mediapipe搭建姿态估计模型并打开摄像头采集坐标数据集
源代码中,up主进行了很好地封装,代码稍长,接下来我只挑重要的部分说一下,完整的代码请看文末(代码中的中文注释是我添加的,英文的是原作者的)。
首先是处理视频流的函数。
def mediapipe_detection(image, model):
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # BGR 转 RGB
image.flags.writeable = False # Image is no longer writeable
results = model.process(image) # 对视频流处理,返回坐标
image.flags.writeable = True # Image is now writeable
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) # RGB 转 BGR
return image, results
然后是在人体上渲染节点的函数。
def draw_styled_landmarks(image, results):
mp_drawing.draw_landmarks(image, results.pose_landmarks, mp_holistic.POSE_CONNECTIONS,
mp_drawing.DrawingSpec(color=(80,22,10), thickness=2, circle_radius=4),
mp_drawing.DrawingSpec(color=(80,44,121), thickness=2, circle_radius=2)
)
......
#剩下还有,不一一放上来了,完整请看文末
这两个功能比较简单,如果想了解如何用mediapipe搭建姿态检测模型,请看我的系列文章一。
然后是比较重要的提取坐标的函数,将process返回的坐标提取出来,并转换为numpy矩阵。为了训练手势模型,我使用了姿势坐标33个、左右手坐标各21个。原作者还使用了脸部坐标一起训练,个人没这个需求,将相关代码注释了。
def extract_keypoints(results):
#姿势坐标33个,np.zeros(33*4)是因为除x,y,z外,还有置信度visibility,以下类似
pose = np.array([[res.x, res.y, res.z, res.visibility] for res in results.pose_landmarks.landmark]).flatten() if results.pose_landmarks else np.zeros(33*4)
#mediapipe面网多达468个节点,这里我不用,注释掉
#face = np.array([[res.x, res.y, res.z] for res in results.face_landmarks.landmark]).flatten() if results.face_landmarks else np.zeros(468*3)
#左手坐标21个
lh = np.array([[res.x, res.y, res.z] for res in results.left_hand_landmarks.landmark]).flatten() if results.left_hand_landmarks else np.zeros(21*3)
#右手坐标21个
rh = np.array([[res.x, res.y, res.z] for res in results.right_hand_landmarks.landmark]).flatten() if results.right_hand_landmarks else np.zeros(21*3)
return np.concatenate([pose, lh, rh])
#如果要使用脸部坐标训练,列表更换为[pose, face, lh, rh]
33个姿势节点如下所示。
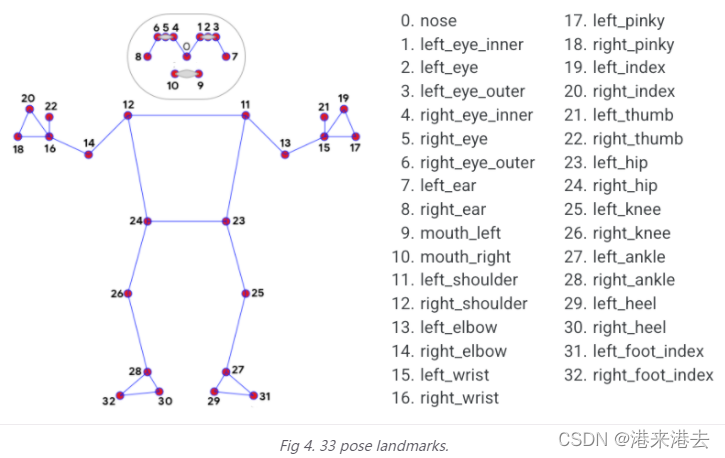
21个手部节点如下所示。

现在使用os库在同一目录下新建文件夹存放等下要采集的数据集。
DATA_PATH = os.path.join('MP_Data')
接下来比较重要了。我将训练的四个手势是“666”,“大拇指”、“比心”、“剪刀手”。每个动作将采集30次,每次采集30帧(这些可以改)
actions = np.array(['666', 'thumbs_up', 'finger_heart','scissor_hand'])#你要训练的手势名称,即动作标签label
# Thirty videos worth of data
no_sequences = 30#采集30次
# Videos are going to be 30 frames in length
sequence_length = 30#30帧
#关于这个for循环,会在MP_data文件下建立四个文件夹(对应四个动作),每个文件夹又包含30个子文件夹,
#每个子文件夹包含30个.npy文件,都是每次采集坐标信息时保存的
for action in actions:
for sequence in range(no_sequences):
try:
os.makedirs(os.path.join(DATA_PATH, action, str(sequence)))
except:
pass
然后运行这部分程序开始采集数据集(完整代码请看文末)。采集前都会有提示,原作者做得很好。
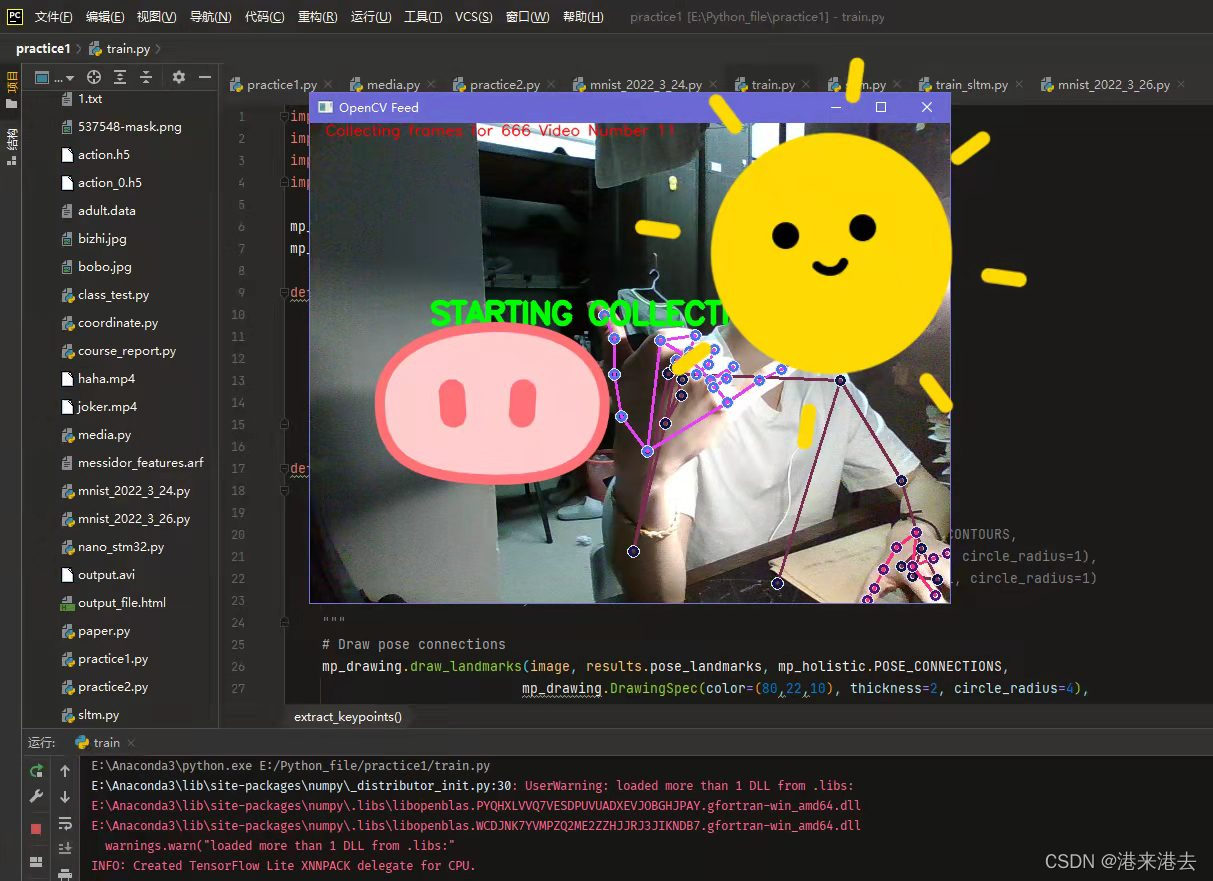
就这样慢慢采集,大概几分钟,采集完会自动结束程序。
三、使用Tensorflow搭建LSTM网络进行训练,然后保存模型
有了数据集,开始搭建网络训练。关于长短期记忆网络LSTM,请看官网的介绍
#同样,这里只是部分代码,详细请看文末
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
model = Sequential()
#关于input_shape,原作者的网络是(30,1662),1662=33*4 + 468*2 + 21*3 + 21*3,而我不需要面网坐标,故只有258
model.add(LSTM(64, return_sequences=True, activation='relu', input_shape=(30,258)))
model.add(LSTM(128, return_sequences=True, activation='relu'))
model.add(LSTM(64, return_sequences=False, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(actions.shape[0], activation='softmax'))
model.compile(optimizer='Adam', loss='categorical_crossentropy', metrics=['categorical_accuracy'])
model.fit(X_train, y_train, epochs=2000, callbacks=[tb_callback])
model.summary()
model.save('action.h5')#要保存的模型名称,保存在当前目录
tensorflow的使用还是比较简单的,如果看不懂,请看TensorFlow中文官网。训练结果如图。
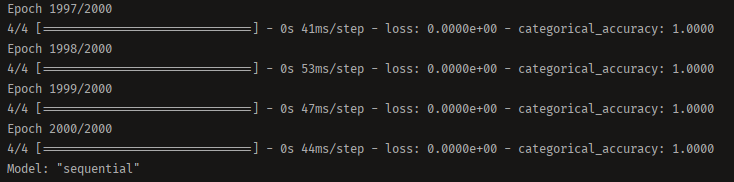
虽有2000个epochs,但即使是CPU下训练速度也很快。最后在同一目录下得到了我们的权重文件action.h5,接下来就可以实际使用训练好的模型了。
四、使用训练好的模型进行实际检测
看效果图吧,当识别到对应手势,相应标签的框框颜色条会变长,这代表分类到这一手势的概率。同时运行端也会输出此刻检测到手势类别。这部分代码与上文的代码大体类似,请看文末吧。总的来说,手势基本上都能识别正确,响应速度也很快。
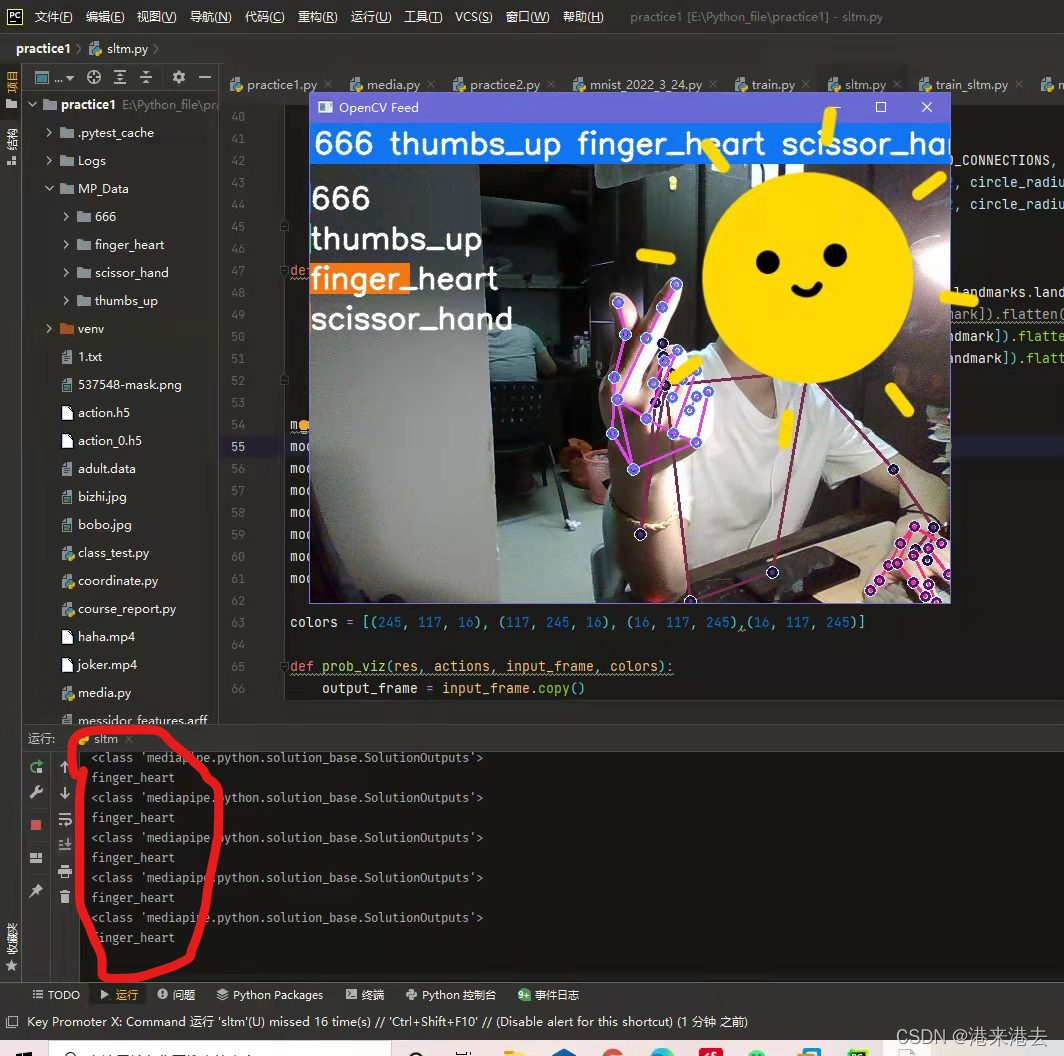
最后我将该模型部署到了树莓派上,虽然运行起来有点慢,但还是很成功的。部署的话,就是注意相关库都要安装,然后代码和权重文件拖过去运行就好了,没什么难点。
五、总结
借助该up主的代码,可以简便的训练自己的手势识别模型,准确率也高。不过要注意的是,当使用训练好的模型进行实际检测时,所做动作务必和采集数据集时的动作保持一致。这是因为,代码中使用的mediapipe坐标会随你离摄像头的距离变化而变化。所以同样的手势动作,只要你离摄像头的距离或角度变了,识别准确率就会大大下降,这是我多次实践得出的结论。使用自己的模型时,所做动作务必和采集数据集时的动作保持一致!
六、所有代码
如果你想复现我的模型,你不需要改动任何代码;如果想扩大数据集,请修改no_sequences 和sequence_length;如果想训练别的动作或增加动作数目,请修改actions列表和colors列表(增加或减少动作数目就要修改);想训练面网坐标,增加表情识别,请取消相应注释。如果有其他不懂的,可以在评论区问我。
首先是采集数据集的代码
import cv2
import numpy as np
import os
import mediapipe as mp
mp_holistic = mp.solutions.holistic # Holistic model
mp_drawing = mp.solutions.drawing_utils # Drawing utilities
def mediapipe_detection(image, model):
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # COLOR CONVERSION BGR 2 RGB
image.flags.writeable = False # Image is no longer writeable
results = model.process(image) # Make prediction
image.flags.writeable = True # Image is now writeable
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) # COLOR COVERSION RGB 2 BGR
return image, results
def draw_styled_landmarks(image, results):
"""
要训练脸部坐标就取消注释
# Draw face connections
mp_drawing.draw_landmarks(image, results.face_landmarks, mp_holistic.FACEMESH_CONTOURS,
mp_drawing.DrawingSpec(color=(80,110,10), thickness=1, circle_radius=1),
mp_drawing.DrawingSpec(color=(80,256,121), thickness=1, circle_radius=1)
)
"""
# Draw pose connections
mp_drawing.draw_landmarks(image, results.pose_landmarks, mp_holistic.POSE_CONNECTIONS,
mp_drawing.DrawingSpec(color=(80,22,10), thickness=2, circle_radius=4),
mp_drawing.DrawingSpec(color=(80,44,121), thickness=2, circle_radius=2)
)
# Draw left hand connections
mp_drawing.draw_landmarks(image, results.left_hand_landmarks, mp_holistic.HAND_CONNECTIONS,
mp_drawing.DrawingSpec(color=(121,22,76), thickness=2, circle_radius=4),
mp_drawing.DrawingSpec(color=(121,44,250), thickness=2, circle_radius=2)
)
# Draw right hand connections
mp_drawing.draw_landmarks(image, results.right_hand_landmarks, mp_holistic.HAND_CONNECTIONS,
mp_drawing.DrawingSpec(color=(245,117,66), thickness=2, circle_radius=4),
mp_drawing.DrawingSpec(color=(245,66,230), thickness=2, circle_radius=2)
)
def extract_keypoints(results):
pose = np.array([[res.x, res.y, res.z, res.visibility] for res in results.pose_landmarks.landmark]).flatten() if results.pose_landmarks else np.zeros(33*4)
#face = np.array([[res.x, res.y, res.z] for res in results.face_landmarks.landmark]).flatten() if results.face_landmarks else np.zeros(468*3)
lh = np.array([[res.x, res.y, res.z] for res in results.left_hand_landmarks.landmark]).flatten() if results.left_hand_landmarks else np.zeros(21*3)
rh = np.array([[res.x, res.y, res.z] for res in results.right_hand_landmarks.landmark]).flatten() if results.right_hand_landmarks else np.zeros(21*3)
return np.concatenate([pose, lh, rh])
# Path for exported data, numpy arrays
DATA_PATH = os.path.join('MP_Data')
# Actions that we try to detect
actions = np.array(['666', 'thumbs_up', 'finger_heart','scissor_hand'])
# Thirty videos worth of data
no_sequences = 30
# Videos are going to be 30 frames in length
sequence_length = 30
for action in actions:
for sequence in range(no_sequences):
try:
os.makedirs(os.path.join(DATA_PATH, action, str(sequence)))
except:
pass
cap = cv2.VideoCapture(0)
# Set mediapipe model
with mp_holistic.Holistic(min_detection_confidence=0.5, min_tracking_confidence=0.5) as holistic:
# NEW LOOP
# Loop through actions
for action in actions:
# Loop through sequences aka videos
for sequence in range(no_sequences):
# Loop through video length aka sequence length
for frame_num in range(sequence_length):
# Read feed
ret, frame = cap.read()
# Make detections
image, results = mediapipe_detection(frame, holistic)
# print(results)
# Draw landmarks
draw_styled_landmarks(image, results)
# NEW Apply wait logic
if frame_num == 0:
cv2.putText(image, 'STARTING COLLECTION', (120, 200),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 4, cv2.LINE_AA)
cv2.putText(image, 'Collecting frames for {} Video Number {}'.format(action, sequence), (15, 12),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1, cv2.LINE_AA)
# Show to screen
cv2.imshow('OpenCV Feed', image)
cv2.waitKey(2000)
else:
cv2.putText(image, 'Collecting frames for {} Video Number {}'.format(action, sequence), (15, 12),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1, cv2.LINE_AA)
# Show to screen
cv2.imshow('OpenCV Feed', image)
# NEW Export keypoints
keypoints = extract_keypoints(results)
npy_path = os.path.join(DATA_PATH, action, str(sequence), str(frame_num))
np.save(npy_path, keypoints)
# Break gracefully
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
使用TensorFlow搭建LSTM网络进行训练
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from tensorflow.keras.callbacks import TensorBoard
import numpy as np
import os
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import to_categorical
log_dir = os.path.join('Logs')
tb_callback = TensorBoard(log_dir=log_dir)
no_sequences = 30
# Videos are going to be 30 frames in length
sequence_length = 30
DATA_PATH = os.path.join('MP_Data')
actions = np.array(['666', 'thumbs_up', 'finger_heart','scissor_hand'])
label_map = {label:num for num, label in enumerate(actions)}
sequences, labels = [], []
for action in actions:
for sequence in range(no_sequences):
window = []
for frame_num in range(sequence_length):
res = np.load(os.path.join(DATA_PATH, action, str(sequence), "{}.npy".format(frame_num)))
window.append(res)
sequences.append(window)
labels.append(label_map[action])
X = np.array(sequences)
y = to_categorical(labels).astype(int)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.05)
model = Sequential()
model.add(LSTM(64, return_sequences=True, activation='relu', input_shape=(30,258)))
model.add(LSTM(128, return_sequences=True, activation='relu'))
model.add(LSTM(64, return_sequences=False, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(actions.shape[0], activation='softmax'))
model.compile(optimizer='Adam', loss='categorical_crossentropy', metrics=['categorical_accuracy'])
model.fit(X_train, y_train, epochs=2000, callbacks=[tb_callback])
model.summary()
model.save('action.h5')
使用训练好的模型进行实际检测
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
import cv2
import numpy as np
import mediapipe as mp
mp_holistic = mp.solutions.holistic # Holistic model
mp_drawing = mp.solutions.drawing_utils # Drawing utilities
sequence = []
sentence = []
threshold = 0.8
actions = np.array(['666', 'thumbs_up', 'finger_heart','scissor_hand'])
def mediapipe_detection(image, model):
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # COLOR CONVERSION BGR 2 RGB
image.flags.writeable = False # Image is no longer writeable
results = model.process(image) # Make prediction
image.flags.writeable = True # Image is now writeable
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) # COLOR COVERSION RGB 2 BGR
return image, results
def draw_styled_landmarks(image, results):
# Draw face connections
"""
mp_drawing.draw_landmarks(image, results.face_landmarks, mp_holistic.FACEMESH_CONTOURS,
mp_drawing.DrawingSpec(color=(80,110,10), thickness=1, circle_radius=1),
mp_drawing.DrawingSpec(color=(80,256,121), thickness=1, circle_radius=1)
)
"""
# Draw pose connections
mp_drawing.draw_landmarks(image, results.pose_landmarks, mp_holistic.POSE_CONNECTIONS,
mp_drawing.DrawingSpec(color=(80,22,10), thickness=2, circle_radius=4),
mp_drawing.DrawingSpec(color=(80,44,121), thickness=2, circle_radius=2)
)
# Draw left hand connections
mp_drawing.draw_landmarks(image, results.left_hand_landmarks, mp_holistic.HAND_CONNECTIONS,
mp_drawing.DrawingSpec(color=(121,22,76), thickness=2, circle_radius=4),
mp_drawing.DrawingSpec(color=(121,44,250), thickness=2, circle_radius=2)
)
# Draw right hand connections
mp_drawing.draw_landmarks(image, results.right_hand_landmarks, mp_holistic.HAND_CONNECTIONS,
mp_drawing.DrawingSpec(color=(245,117,66), thickness=2, circle_radius=4),
mp_drawing.DrawingSpec(color=(245,66,230), thickness=2, circle_radius=2)
)
def extract_keypoints(results):
pose = np.array([[res.x, res.y, res.z, res.visibility] for res in results.pose_landmarks.landmark]).flatten() if results.pose_landmarks else np.zeros(33*4)
#face = np.array([[res.x, res.y, res.z] for res in results.face_landmarks.landmark]).flatten() if results.face_landmarks else np.zeros(468*3)
lh = np.array([[res.x, res.y, res.z] for res in results.left_hand_landmarks.landmark]).flatten() if results.left_hand_landmarks else np.zeros(21*3)
rh = np.array([[res.x, res.y, res.z] for res in results.right_hand_landmarks.landmark]).flatten() if results.right_hand_landmarks else np.zeros(21*3)
return np.concatenate([pose, lh, rh])
model = Sequential()
model.add(LSTM(64, return_sequences=True, activation='relu', input_shape=(30,258)))
model.add(LSTM(128, return_sequences=True, activation='relu'))
model.add(LSTM(64, return_sequences=False, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(actions.shape[0], activation='softmax'))
model.load_weights('action.h5')
colors = [(245, 117, 16), (117, 245, 16), (16, 117, 245),(16, 117, 245)]#四个动作的框框,要增加动作数目,就多加RGB元组
def prob_viz(res, actions, input_frame, colors):
output_frame = input_frame.copy()
for num, prob in enumerate(res):
cv2.rectangle(output_frame, (0, 60 + num * 40), (int(prob * 100), 90 + num * 40), colors[num], -1)
cv2.putText(output_frame, actions[num], (0, 85 + num * 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2,
cv2.LINE_AA)
return output_frame
cap = cv2.VideoCapture(0)
# Set mediapipe model
with mp_holistic.Holistic(min_detection_confidence=0.5, min_tracking_confidence=0.5) as holistic:
while cap.isOpened():
# Read feed
ret, frame = cap.read()
# Make detections
image, results = mediapipe_detection(frame, holistic)
print(results)
# Draw landmarks
draw_styled_landmarks(image, results)
# 2. Prediction logic
keypoints = extract_keypoints(results)
sequence.append(keypoints)
sequence = sequence[-30:]
if len(sequence) == 30:
res = model.predict(np.expand_dims(sequence, axis=0))[0]
print(actions[np.argmax(res)])
# 3. Viz logic
if res[np.argmax(res)] > threshold:
if len(sentence) > 0:
if actions[np.argmax(res)] != sentence[-1]:
sentence.append(actions[np.argmax(res)])
else:
sentence.append(actions[np.argmax(res)])
if len(sentence) > 5:
sentence = sentence[-5:]
# Viz probabilities
image = prob_viz(res, actions, image, colors)
cv2.rectangle(image, (0, 0), (640, 40), (245, 117, 16), -1)
cv2.putText(image, ' '.join(sentence), (3, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2, cv2.LINE_AA)
# Show to screen
cv2.imshow('OpenCV Feed', image)
# Break gracefully
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
七、我也只是搬运工,欢迎在评论区讨论、赐教
文章出处登录后可见!