人工神经网络(artificial neural networks,ANNs),是模拟生物神经网络进行信息处理的一种数学模型。
一、人工神经网络简介
更多关于神经网络的发展可以参考:人工神经网络简介_网络资源是无限的-CSDN博客_人工神经网络
人工神经元是人工神经网络操作的基本信息处理单位。人工神经元的模型如图所示,它是人工神经网络的设计基础。一个人工神经元对输入信号X=[x1,x2,…,xm]的输出为y=f(u+b),其中
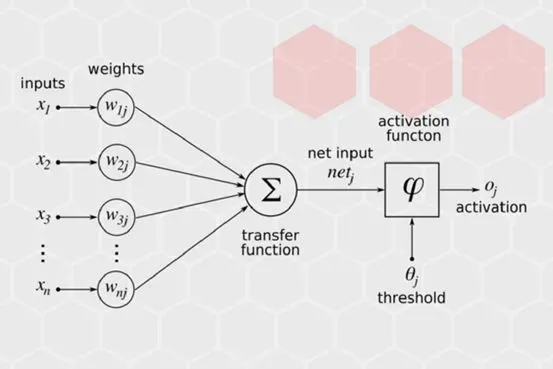
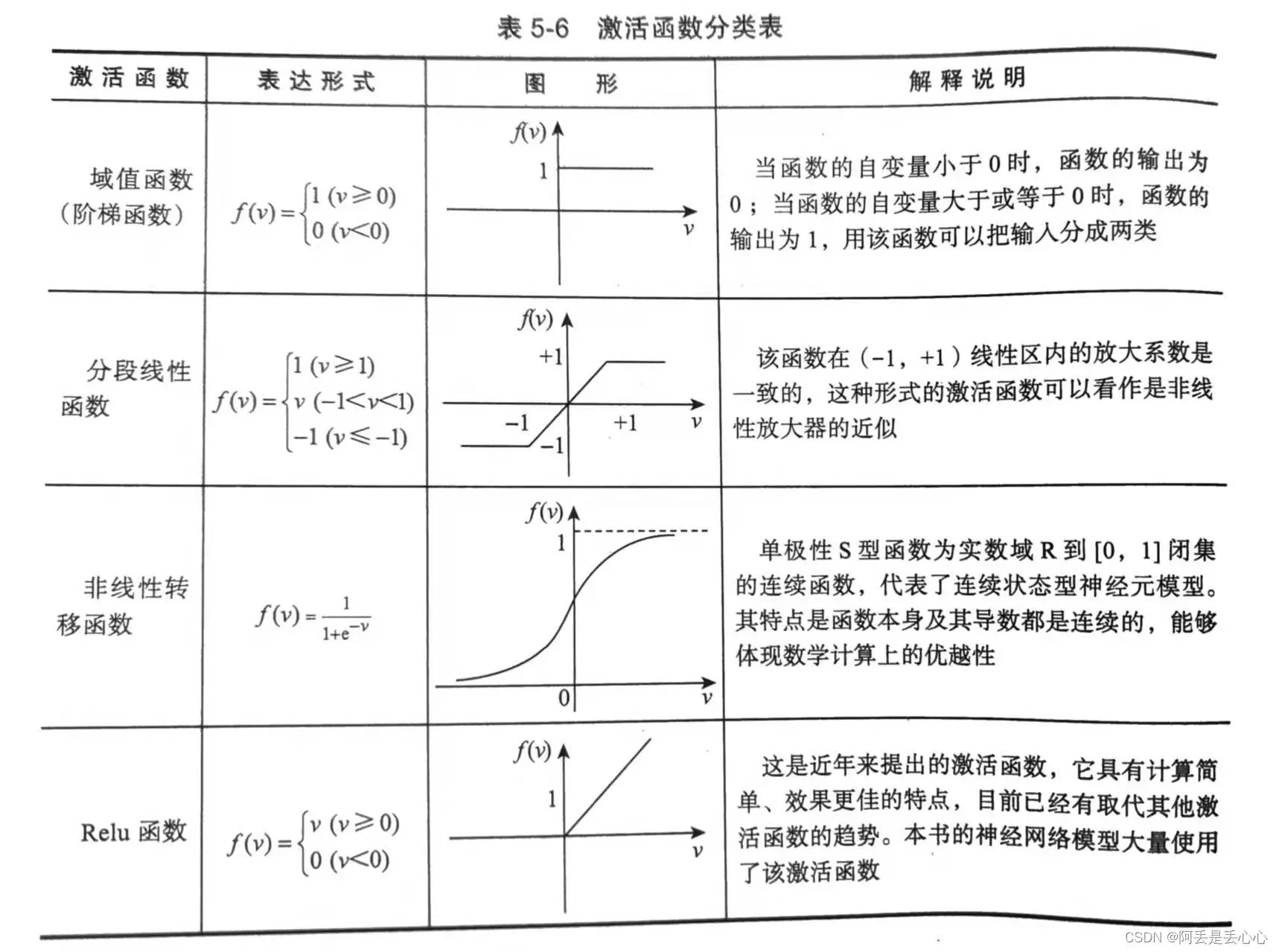
激活函数主要有以下几种形式
人工神经网络的学习也称为训练,指的是神经网络在收到外部环境的刺激下调整神经网络的参数,使神经网络以一种新的方式对外部环境做出反应的一个过程。
在神经网络的发展过程中,提出了多种不同的学习规则,没有一种特定的学习算法适用于所有的网络结构和具体问题。在分类和预测中,学习规则(误差校正学习算法)是使用最广泛的一种。误差校正学习算法根据神经网络的输出误差对神经元连接强度进行修正,属于有指导学习。我们最常见的BP神经网络用的就是δ学习算法。BP神经网络通过信号正向传播与误差逆向传播来进行各层权矩阵的修改,此过程一直进行到网络输出的误差逐渐减少到可以接受的程度或达到设定的学习次数为止。
下面两篇文章是我认为对BP神经网络解释的比较通俗易懂的:
人工神经网络_Remys的技术博客_51CTO博客_人工神经网络算法
人工神经网络(ANN)及BP算法_leiting_imecas的博客-CSDN博客_人工神经网络
使用人工神经网络模型需要确定网络连接的拓扑结构、神经元特征和学习规则等,常用来实现分类和预测的人工神经网络算法如下表:

二、人工神经网络的Python实现
Python中scklit-learn库中并没有神经网络模型,我们通常用Keras库来实现神经网络。
下面我们建立一个简单的神经网络模型,其中有三个输入节点,10个隐藏节点和1个输出节点
import pandas as pd
filename = './Python数据分析与挖掘实战(第2版)/chapter5/demo/data/sales_data.xls'
data = pd.read_excel(filename, index_col ="序号")
#数据是类别标签,将它转换为数据
data[data == "好"] = 1
data[data == "是"] = 1
data[data == "高"] = 1
data[data != 1] = 0
x = data.iloc[:,:3].astype(int)
y = data.iloc[:,3].astype(int)from keras.models import Sequential
from keras.layers.core import Dense, Activation
model = Sequential() #建立模型
model.add(Dense(input_dim = 3, units = 10))
model.add(Activation('relu')) #用relu函数作为激活函数能够大幅度提高准确度
model.add(Dense(input_dim = 10, units = 1))
model.add(Activation('sigmoid')) #由于是0-1输出,用sigmoid函数作为激活函数
model.compile(loss = 'binary_crossentropy', optimizer = 'adam')
#编译模型,由于我们做的是二元分类,所以我们指定损失函数为binary_crossentropy,以及模式为binary
#另外常见的损失函数还有mean_squared_error, categorical_crossentropy等
#对于求解方法,我们指定adam,此外还有sgd,rmsprop等
model.fit(x, y, epochs = 1000, batch_size = 10) #训练模型,学习1000次
yp = model.predict_classes(x).reshape(len(y)) #分类预测
用混淆矩阵可视化结果
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y, yp)
print(cm)
import matplotlib.pyplot as plt
plt.matshow(cm, cmap=plt.cm.Greens)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
cm_plot(y,yp).show()得到的结果如下:
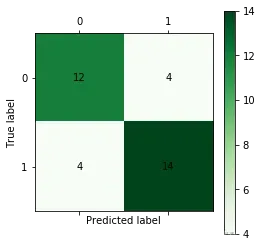
可以看到,检测样本为34个,预测正确的个数为26个,预测准确率为76.47%,预测准确率较低,这是由于神经网络训练时需要较多样本,而这里的训练数据较少导致。
版权声明:本文为博主阿丢是丢心心原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_41168304/article/details/122647648