基于本人大创项目所学习三维建模过程的笔记。
1.概念:三维重建是指对三维物体建立适合计算机表示和处理的数学模型,是在计算机环境下对其进行处理、操作和分析其性质的基础,也是在计算机中建立表达客观世界的虚拟现实的关键技术。
2.三维重建的分类:
根据采集设备是否主动发射测量信号,分为两类:基于主动视觉理论和基于被动视觉的三维重建方法。
主动视觉三维重建方法:主要包括结构光法和激光扫描法。
被动视觉三维重建方法:被动视觉只使用摄像机采集三维场景得到其投影的二维图像,根据图像的纹理分布等信息恢复深度信息,进而实现三维重建。
3.常见的三维重建表达方式
常规的3D shape representation有以下四种:深度图(depth)、点云(point cloud)、体素(voxel)、网格(mesh)。
 深度图
深度图
深度图其每个像素值代表的是物体到相机xy平面的距离,单位为 mm。
 体素
体素
体素是三维空间中的一个有大小的点,一个小方块,相当于是三维空间种的像素。
 点云
点云
点云是某个坐标系下的点的数据集。点包含了丰富的信息,包括三维坐标X,Y,Z、颜色、分类值、强度值、时间等等。在我看来点云可以将现实世界原子化,通过高精度的点云数据可以还原现实世界。万物皆点云,获取方式可通过三维激光扫描等。
 用三角网格重建
用三角网格重建
三角网格就是全部由三角形组成的多边形网格。多边形和三角网格在图形学和建模中广泛使用,用来模拟复杂物体的表面,如建筑、车辆、人体,当然还有茶壶等。任意多边形网格都能转换成三角网格。
三角网格需要存储三类信息:
顶点:每个三角形都有三个顶点,各顶点都有可能和其他三角形共享。 .
边:连接两个顶点的边,每个三角形有三条边。
面:每个三角形对应一个面,我们可以用顶点或边列表表示面。
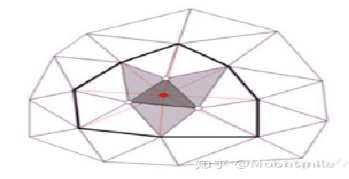 三角网格
三角网格
4.主要内容:在计算机视觉中, 三维重建是指根据单视图或者多视图的图像重建三维信息的过程. 由于单视频的信息不完全,因此三维重建需要利用经验知识. 而多视图的三维重建(类似人的双目定位)相对比较容易, 其方法是先对摄像机进行标定, 即计算出摄像机的图象坐标系与世界坐标系的关系.然后利用多个二维图象中的信息重建出三维信息。
5.主要步骤:
(1) 图像获取:在进行图像处理之前,先要用摄像机获取三维物体的二维图像。光照条件、相机的几何特性等对后续的图像处理造成很大的影响。
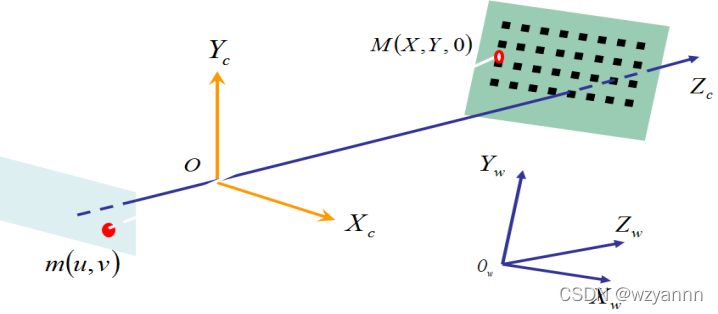
(2)摄像机标定:利用摄像机所拍摄到的图像来还原空间中的物体。在这里,不妨假设摄像机所拍摄到的图像与三维空间中的物体之间存在以下一种简单的线性关系:[像]=M[物],这里,矩阵M可以看成是摄像机成像的几何模型。 M中的参数就是摄像机参数。通常,这些参数是要通过实验与计算来得到的。这个求解参数的过程就称为摄像机标定。
(3)特征提取:特征主要包括特征点、特征线和区域。大多数情况下都是以特征点为匹配基元,特征点以何种形式提取与用何种匹配策略紧密联系。因此在进行特征点的提取时需要先确定用哪种匹配方法。特征点提取算法可以总结为:基于方向导数的方法,基于图像亮度对比关系的方法,基于数学形态学的方法三种。
(4)立体匹配:立体匹配是指根据所提取的特征来建立图像对之间的一种对应关系,也就是将同一物理空间点在两幅不同图像中的成像点进行一一对应起来。在进行匹配时要注意场景中一些因素的干扰,比如光照条件、噪声干扰、景物几何形状畸变、表面物理特性以及摄像机机特性等诸多变化因素。
(5)三维重建:有了比较精确的匹配结果,结合摄像机标定的内外参数,就可以恢复出三维场景信息。由于三维重建精度受匹配精度,摄像机的内外参数误差等因素的影响,因此首先需要做好前面几个步骤的工作,使得各个环节的精度高,误差小,这样才能设计出一个比较精确的立体视觉系统。
6.具体操作(对应上述步骤)
首先在上述几种常见表达方式中,我们选择点云,所以以下具体操作步骤是以点云为基本表达方式来展开细说。
(1)图像获取:工业相机与民用相机相比,采集的图像更加清晰、数据传输更加迅速以及稳定、可以适应更多的非常规条件。因此本设计选择海康威视公司型号为MV-CA013-20GC的CMOS工业相机。
表2.2 MV-CA013-20GC的主要参数
| 参数类型 | 参数规格 |
|---|---|
| 分辨率 | 1280×1024 |
| 最大帧率 | 90 fps |
| 数据接口 | GigE |
| 外形尺寸 | 29 mm × 29 mm × 42 mm |
| IP防护等级 | IP30 |
| 传感器类型 | CMOS |
| 工作温度 | 0℃~ 50℃ |
| 湿度 | 20% ~ 80%RH 无冷凝 |
使用三台相机,以待测物为中心,每台间隔 120°放置,即可以采集到环待测物的3张图片。便于对待测物的下一步研究,但是图片需要同时采集,因此本设计对于同步的要求极高。
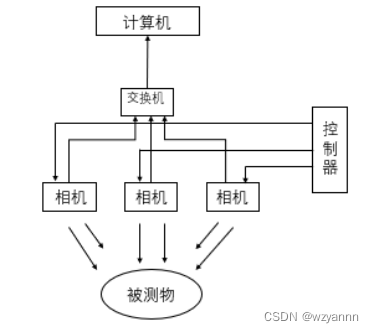 图3.1 整体系统构建图
图3.1 整体系统构建图
(2)摄像机标定:相机标定即根据标定板,拍摄相应的图像,建立图像中像素位置与场景点位置之间的函数关系,根据相机成像模型,由匹配点在图像中的坐标与场景中的坐标的对应关系,求解相机的内部参数和外部参数。
 黑白格标定板
黑白格标定板
首先我们先打印一张黑白格标定板固定于平面上,由于我们使用多个相机,因此需要对各个相机都进行标定。以各个相机从不同的角度拍摄若干张标定板的图像,将标定图像导入到程序中,检测标定图像中的特征点,然后求解理想无畸变情况下的相机的内部参数和外部参数,并用极大似然估计来提升精度。 这之后需要应用最小二乘法来求出实际的径向畸变系数,接着再次用极大似然估计法,综合内部参数,外部参数及畸变参数,来优化估计精度,最后得出相机的内部参数、外部参数及畸变参数。

(3)特征提取:对比ORB、SURF、SIFT三种算法
计算速度: ORB>>SURF>>SIFT(各差一个量级)
旋转鲁棒性: SURF>ORB~SIFT(表示差不多)
模糊鲁棒性: SURF>ORB~SIFT
尺度变换鲁棒性: SURF>SIFT>ORB(ORB并不具备尺度变换性)
较SIFT计算量小,耗时短,具有旋转不变性、尺度不变性,鲁棒性较好。我们选择SURF算法。
Python SURF算法实现:
下面展示一些 内联代码片。
// An highlighted block
def surf(filename): img = cv2.imread(filename) # 读取文件
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转化为灰度图
sift = cv2.xfeatures2d_SURF.create() keyPoint, descriptor = sift.detectAndCompute(img, None) # 特征提取得到关键点以及对应的描述符(特征向量)
return img, keyPoint, descriptor
(4)特征匹配
特征匹配主要是计算两幅图像中特征描述子的匹配关系。需要计算两个描述符之间的距离,这样他们的差异就被转换成一个单一的数字,我们可以用它作为一个简单的相似度量,如下图:
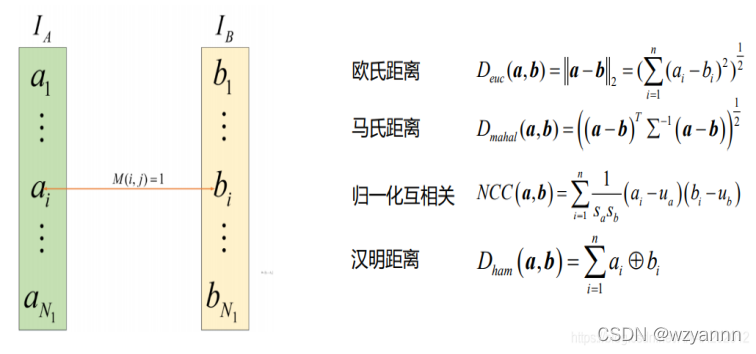
匹配策略
a.蛮力匹配(Brute Force Matching)
对于第一张图像中给定的关键点,它将获取第二张图像中的每个关键点并计算距离。距离最小的关键点将被视为一对、
b.快速最近邻(FLANN)
2014年,David Lowe和Marius Muja发布了"快速最近邻(fast library for approximate nearest neighbors(FLANN)“)。FLANN训练了一种索引结构,用于遍历使用机器学习概念创建的潜在匹配候选对象。该库构建了非常有效的数据结构(KD树)来搜索匹配对,并避免了穷举法的穷举搜索。因此,速度更快,结果也非常好,但是仍然需要调试匹配参数。
BFMatching和FLANN都接受描述符距离阈值T,该距离阈值T用于将匹配项的数量限制为“好”,并在匹配不对应的情况下丢弃匹配项。相应的“好”对称为"正阳性(TP)”,而错对称为"假阳性(FP)",为T选择合适的值的任务是允许尽可能多的TP匹配,而应尽可能避免FP匹配。尽管在大多数情况下都无法避免FP,但我们可以尽可能的降低FP次数。
有效降低FP的两种策略
a.BFMatching-crossCheck
只要不超过所选阈值T,即使第二图像中不存在关键点,蛮力匹配也将始终返回与关键点的匹配。这不可避免地导致许多错误的匹配。抵消这种情况的一种策略称为交叉检查匹配,它通过两个方向上应用匹配过程并仅保留那些在一个方向上的与在另一个方向上的最佳匹配相同的匹配来工作。交叉检查方法的步骤为:
①对于源图像中的每个描述符,请在参考图像中找到一个或多个最佳匹配。
②切换源图像和参考图像的顺序。
③重复步骤1中源图像和参考图像之间的匹配过程。
④选择其描述符在两个方向上最匹配的那些关键点。
尽管交叉检查匹配会增加处理时间,但通常会消除大量的错误匹配,因此,当精度优于速度时,应始终执行交叉匹配。交叉匹配一般仅仅用于BFMatching。
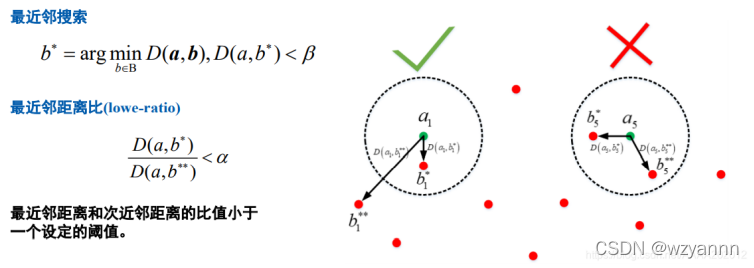
b.Nearest neighbor distance ratio (NN)/K-nearest-neighbor(KNN)
减少FP数量的另一种非常有效的方法是为每个关键点计算最近邻距离比(nearest neighbor distance ratio)。
KNN与NN的区别在与NN每个特征点只保留一个最好的匹配,而KNN每个特征点保留k个最佳匹配,k一般为2。
主要思想是不要将阈值直接应用于SSD,相反,对于源图像中的每个关键点,两个最佳匹配位于参考图像中,并计算描述符距离之间的比率。然后,将阈值应用于比率,以筛选出模糊匹配。如下图所示:
(5)三维重建:
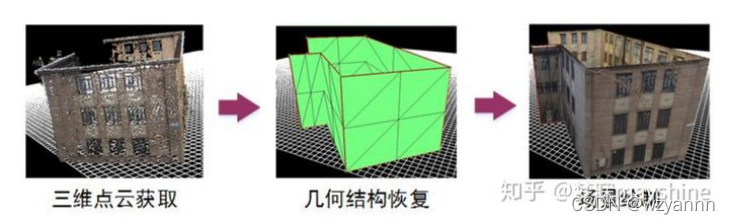
利用surf算法获得深度图,采用python opencv库完成三维重建点云的重建。
文章出处登录后可见!