语义分割数据集制作与转换方法
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
第一章 基于PS的语义分割标注
第二章 构建VOC语义分割数据集
前言
PASCAL VOC2012数据集简介
PASCAL VOC2012是语义分割任务极为重要的官方数据集,大量优秀的语义分割模型都会刷一下这个数据集,因此我们在使用别人的开源代码时,如果能将自己的数据集整理成官方数据集的格式,则可快速验证模型性能,减少自身工作量。
VOC2012官方数据集文件结构共包含五个文件夹
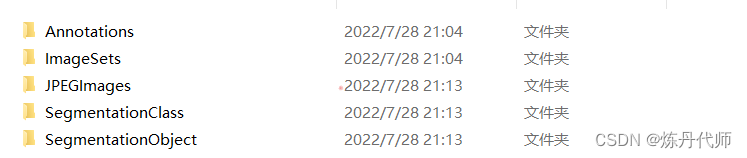
其中语义分割需要的包括:
1.ImageSets/Segmentation:存放训练验证集文件名称的txt文件;
2.JPEGImages:存放原始图像的文件夹
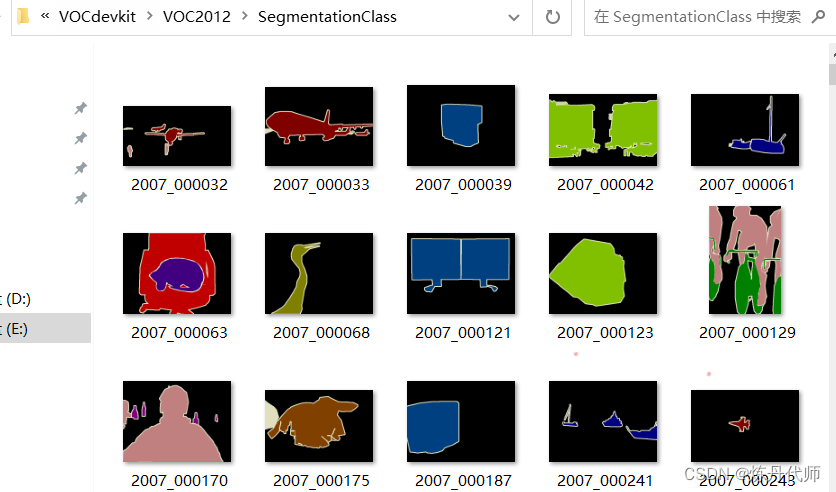
3.SegmentationClass:存放标注文件的文件夹
因此,在制作自己数据集时,只需保证这三个文件夹的内容统一,即可完成数据集制作。
一、构建文件夹
根据上述的文件夹结构,创建VOC2012文件夹,在VOC2012内创建ImageSets文件夹、JPEGImages文件夹、SegmentationClass文件夹,在ImageSets文件夹内创建Segmentation文件夹。



二、移动图片
将自己数据集的原始图片移动到JPEGImages文件夹下,将自己数据集的标注图片移动到SegmentationClass文件夹下。
PS标注工具的使用请移步至:【PS才是真科研利器,助力快速分割标注工作】
三、生成TXT文件
这里提供一段代码:可自动生成train.txt、val.txt、trainval.txt,并检查图像与标注图像长宽维度是否一致、标注图像是否为二维图像、并生成数据集均值、方差及各类别像素比例:
import mmcv
import os
import os.path as osp
import random
"""1.检查图像维度"""
import numpy as np
from PIL import Image,ImageOps
from torchvision import transforms
def get_Image_dim_len(png_dir: str,jpg_dir:str):
png = Image.open(png_dir)
png_w,png_h=png.width,png.height
#若第十行报错,说明jpg图片没有对应的png图片
png_dim_len = len(np.array(png).shape)
assert png_dim_len==2,"提示:存在三维掩码图"
jpg=Image.open(jpg_dir)
jpg = ImageOps.exif_transpose(jpg)
jpg.save(jpg_dir)
jpg_w,jpg_h=jpg.width,jpg.height
print(jpg_w,jpg_h,png_w,png_h)
assert png_w==jpg_w and png_h==jpg_h,print("提示:%s mask图与原图宽高参数不一致"%(png_dir))
"""2.读取单个图像均值和方差"""
def pixel_operation(image_path: str):
img = cv.imread(image_path, cv.IMREAD_COLOR)
means, dev = cv.meanStdDev(img)
return means,dev
"""3.分割数据集,生成label文件"""
# 原始数据集 ann上一级
data_root = 'VOC2012'
#图像地址
image_dir="JPEGImages"
# ann图像文件夹
ann_dir = "SegmentationClass"
# txt文件保存路径
split_dir = 'ImageSets/Segmentation'
mmcv.mkdir_or_exist(osp.join(data_root, split_dir))
png_filename_list = [osp.splitext(filename)[0] for filename in mmcv.scandir(
osp.join(data_root, ann_dir), suffix='.png')]
jpg_filename_list=[osp.splitext(filename)[0] for filename in mmcv.scandir(
osp.join(data_root, image_dir), suffix='.jpg')]
assert len(jpg_filename_list)==len(png_filename_list),"提示:原图与掩码图数量不统一"
print("数量检查无误")
for i in range(10):
random.shuffle(jpg_filename_list)
red_num=0
black_num=0
with open(osp.join(data_root, split_dir, 'trainval.txt'), 'w+') as f:
length = int(len(jpg_filename_list))
for line in jpg_filename_list[:length]:
pngpath=osp.join(data_root,ann_dir,line+'.png')
jpgpath=osp.join(data_root,image_dir,line+'.jpg')
get_Image_dim_len(pngpath,jpgpath)
img=cv.imread(pngpath,cv.IMREAD_GRAYSCALE)
red_num+=len(img)*len(img[0])-len(img[img==0])
black_num+=len(img[img==0])
f.writelines(line + '\n')
value=red_num/black_num
train_mean,train_dev=[[0.0,0.0,0.0]],[[0.0,0.0,0.0]]
with open(osp.join(data_root, split_dir, 'train.txt'), 'w+') as f:
train_length = int(len(jpg_filename_list) * 7/ 10)
for line in jpg_filename_list[:train_length]:
jpgpath=osp.join(data_root,image_dir,line+'.jpg')
mean,dev=pixel_operation(jpgpath)
train_mean+=mean
train_dev+=dev
f.writelines(line + '\n')
with open(osp.join(data_root, split_dir, 'val.txt'), 'w+') as f:
for line in jpg_filename_list[train_length:]:
jpgpath=osp.join(data_root,image_dir,line+'.jpg')
mean,dev=pixel_operation(jpgpath)
train_mean+=mean
train_dev+=dev
f.writelines(line + '\n')
train_mean,train_dev=train_mean/length, train_dev /length
doc=open('均值方差像素比.txt','a+')
doc.write("均值:"+'\n')
for item in train_mean:
doc.write(str(item[0])+'\n')
doc.write("训练集方差:"+'\n')
for item in train_dev:
doc.write(str(item[0])+'\n')
doc.write("像素比:"+'\n')
doc.write(str(value))
train_mean,train_dev=[[0.0,0.0,0.0]],[[0.0,0.0,0.0]]
运行完上述代码后,在VOC2012文件夹下便可看到均值方差像素比.txt文件:
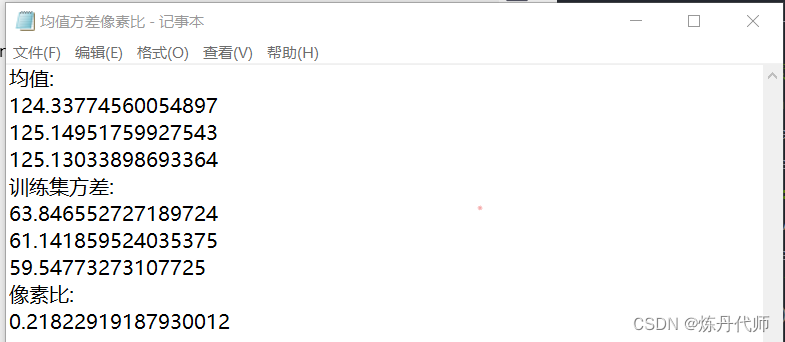
同时,三个标签引索txt文件也随之生成:

总结
提示:这里对文章进行总结:
本文介绍了如何构建自己的VOC数据集。以供大家交流讨论!
往期回顾:
(1)CBAM论文解读+CBAM-ResNeXt的Pytorch实现
(2)SENet论文解读及代码实例
(3)ShuffleNet-V1论文理解及代码复现
(4) ShuffleNet-V2论文理解及代码复现
(5)GhostNet论文理解及代码复现
(6)PS才是真科研利器,助力快速分割标注工作
下期预告:
VOC数据集的使用–如何根据自己的数据集实现mmsegmentation算法库任意语义分割算法
文章出处登录后可见!