什么是注意力机制
注意力机制(Attention Mechanism)源于对人类视觉的研究。 在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他可见的信息。 上述机制通常被称为注意力机制。 人类视网膜不同的部位具有不同程度的信息处理能力,即敏锐度(Acuity),只有视网膜中央凹部位具有最强的敏锐度。(以上为官方解释:个人的理解是注意力机制就是通过一通操作,将数据中关键的特征标识出来,让网络学到数据中需要关注的区域,也就形成了注意力。从而起到突出重要特征的作用。)
常用的简单的注意力机制
常用的注意力机制多为SE Attention和CBAM Attention。为什么常用的是它们呢?其实回看所有注意力机制的代码,都不难发现,它们基本都可以当成一个简单的网络。例如SE注意力机制,它主要就是由两个全连接层组成,这就是一个简单的MLP模型,只是它的输出变了样。所以,在我们把注意力机制加入主干网络里时,所选注意力机制的复杂程度也是我们要考虑的一个方面,因为增加注意力机制,也变相的增加了我们网络的深度,大小。下面我们将介绍两个比较简单的注意力机制。
SE Attention
SE Attentionq其实称为SENet,它全称是Squeeze-and-Excitation Networks。它是2017ImageNet冠军模型。SENet它注意的是我们的通道重要性。SENet的结构如下面两张图。它的结构resnet相识,同样采用短路连接的方式来避免梯度消失,从而可以加深网络和更好地训练模型。不同的是SENet增加了一个由两个FC层,一个池化和两个激活函数组成的block来学习到不同通道特征的重要程度。这种注意力机制可以让模型更加关注信息量最大的通道特征,而抑制那些不重要的通道特征。还有一点是SE模块是通用的,这意味着其可以嵌入到现有的网络架构中,而且非常简洁有效。想更深入了解的可以阅读SENet的论文。论文地址
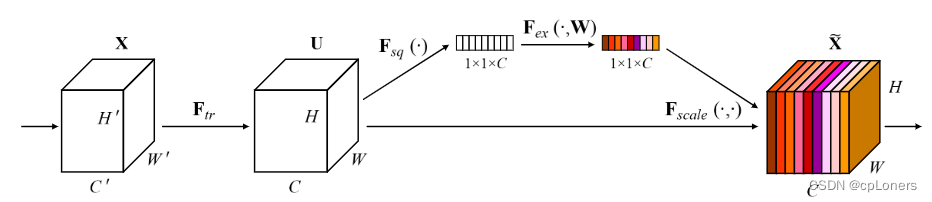
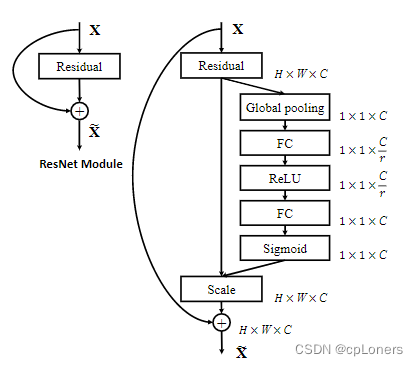
SE Attention的pytorch代码:
import torch.nn as nn
import torch
class SEAttention(nn.Module):
def __init__(self, channel, reduction=16): # channel为输入通道数,reduction压缩大小
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(),
nn.Linear(channel // reduction, channel),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
CBAM Attention
CBAM(Convolutional Block Attention Module) 表示卷积模块的注意力机制模块。是一种结合了空间(spatial)和通道(channel)的注意力机制模块。一般情况下,相比于SEnet只关注通道(channel)的注意力机制可以取得更好的效果。其中CBAM的结构如下面两张图,由Channel Attention和 Spatial Attention这两个模块组成,其中Channel Attention模块和SENet是十分相似的,只是在池化上做了最大和平均池化,把FC层换成了卷积。至于Spatial Attention模块,这个更为简单,本质上就是一个卷积层。想要更深入的理解可以去阅读原论文。论文地址
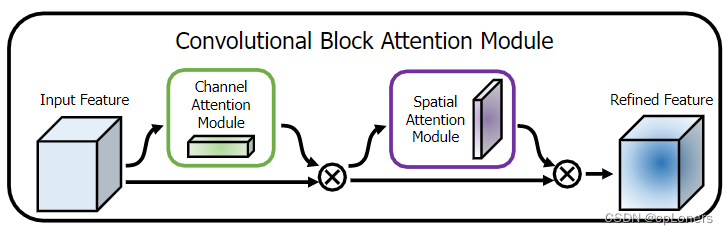

CBAM Attention 代码(Pytorch版):
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ChannelAttention(nn.Module):
def __init__(self,channel,reduction=16):
super().__init__()
self.maxpool=nn.AdaptiveMaxPool2d(1)
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.se=nn.Sequential(
nn.Conv2d(channel,channel//reduction,1,bias=False),
nn.ReLU(),
nn.Conv2d(channel//reduction,channel,1,bias=False)
)
self.sigmoid=nn.Sigmoid()
def forward(self, x) :
max_result=self.maxpool(x)
avg_result=self.avgpool(x)
max_out=self.se(max_result)
avg_out=self.se(avg_result)
output=self.sigmoid(max_out+avg_out)
return output
class SpatialAttention(nn.Module):
def __init__(self,kernel_size=7):
super().__init__()
self.conv=nn.Conv2d(2,1,kernel_size=kernel_size,padding=kernel_size//2)
self.sigmoid=nn.Sigmoid()
def forward(self, x) :
max_result,_=torch.max(x,dim=1,keepdim=True)
avg_result=torch.mean(x,dim=1,keepdim=True)
result=torch.cat([max_result,avg_result],1)
output=self.conv(result)
output=self.sigmoid(output)
return output
class CBAMBlock(nn.Module):
def __init__(self, channel=512,reduction=16,kernel_size=49):
super().__init__()
self.ca=ChannelAttention(channel=channel,reduction=reduction)
self.sa=SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
b, c, _, _ = x.size()
residual=x
out=x*self.ca(x)
out=out*self.sa(out)
return out+residual
其他注意力机制
除了上面介绍的两种视觉的注意力机制,其实还有很多各种花样且“有效”的注意力机制。如:SK Attention(Selective Kernel Networks) ,Shuffle Attention (Sa-net: Shuffle attention for deep convolutional neural networks) , Pyramid Split Attention(论文地址)等等。想要了解和使用更多的视觉注意力代码可以到这个github里找,这里面复现了许多注意力机制的代码,而且不限与视觉的,有兴趣的同学可以去了解下。 github地址
注意力机制该加到网络的哪里
当我们的网络需要加注意力机制时,它该加在哪里呢?虽然注意机制是一个独立的块,一般来说加在哪里都是可以的,但是,注意机制加入我们的网络中时,他是会影响我们网络的特征提取的,即它注意的特征不一定都是我们重要的特征。所以注意力机制加入我们网络的位置就比较重要了。其实注意力提出的作者就告诉了我们注意力机制加在哪里比较合适。所以,当我我们使用一个注意力机制不知道加在哪里时可以去看看提出注意力机制作者的源代码。下面的代码就是CBAM注意力机制的源代码,可以看出,注意力机制加在了残差网络(以resnet18为例)的残差块后面。当然,如果我们使用的网络不是注意力机制作者使用的网络,那这是注意力机制该加在哪里呢?这里个人建议加在最后一个卷积层后面或者第一个全连接层前面。当然并不是每个注意力机制或者每个网络都适用,因为不同的注意力机制注意的地方可能都不一样,所以加到主干网络的地方可能也不一样。
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from torch.nn import init
from .cbam import *
from .bam import *
def conv3x3(in_planes, out_planes, stride=1):
"3x3 convolution with padding"
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, use_cbam=False):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
if use_cbam:
self.cbam = CBAM( planes, 16 )
else:
self.cbam = None
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
if not self.cbam is None:
out = self.cbam(out)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, use_cbam=False):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
if use_cbam:
self.cbam = CBAM( planes * 4, 16 )
else:
self.cbam = None
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
if not self.cbam is None:
out = self.cbam(out)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, network_type, num_classes, att_type=None):
self.inplanes = 64
super(ResNet, self).__init__()
self.network_type = network_type
# different model config between ImageNet and CIFAR
if network_type == "ImageNet":
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.avgpool = nn.AvgPool2d(7)
else:
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
if att_type=='BAM':
self.bam1 = BAM(64*block.expansion)
self.bam2 = BAM(128*block.expansion)
self.bam3 = BAM(256*block.expansion)
else:
self.bam1, self.bam2, self.bam3 = None, None, None
self.layer1 = self._make_layer(block, 64, layers[0], att_type=att_type)
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, att_type=att_type)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, att_type=att_type)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, att_type=att_type)
self.fc = nn.Linear(512 * block.expansion, num_classes)
init.kaiming_normal(self.fc.weight)
for key in self.state_dict():
if key.split('.')[-1]=="weight":
if "conv" in key:
init.kaiming_normal(self.state_dict()[key], mode='fan_out')
if "bn" in key:
if "SpatialGate" in key:
self.state_dict()[key][...] = 0
else:
self.state_dict()[key][...] = 1
elif key.split(".")[-1]=='bias':
self.state_dict()[key][...] = 0
def _make_layer(self, block, planes, blocks, stride=1, att_type=None):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, use_cbam=att_type=='CBAM'))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, use_cbam=att_type=='CBAM'))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
if self.network_type == "ImageNet":
x = self.maxpool(x)
x = self.layer1(x)
if not self.bam1 is None:
x = self.bam1(x)
x = self.layer2(x)
if not self.bam2 is None:
x = self.bam2(x)
x = self.layer3(x)
if not self.bam3 is None:
x = self.bam3(x)
x = self.layer4(x)
if self.network_type == "ImageNet":
x = self.avgpool(x)
else:
x = F.avg_pool2d(x, 4)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def ResidualNet(network_type, depth, num_classes, att_type):
assert network_type in ["ImageNet", "CIFAR10", "CIFAR100"], "network type should be ImageNet or CIFAR10 / CIFAR100"
assert depth in [18, 34, 50, 101], 'network depth should be 18, 34, 50 or 101'
if depth == 18:
model = ResNet(BasicBlock, [2, 2, 2, 2], network_type, num_classes, att_type)
elif depth == 34:
model = ResNet(BasicBlock, [3, 4, 6, 3], network_type, num_classes, att_type)
elif depth == 50:
model = ResNet(Bottleneck, [3, 4, 6, 3], network_type, num_classes, att_type)
elif depth == 101:
model = ResNet(Bottleneck, [3, 4, 23, 3], network_type, num_classes, att_type)
return
文章出处登录后可见!