通俗易懂Resnet50网络结构分析
1 Why(该网络要解决什么样的问题)
- 理论上网络越来越深,获取的信息越多,而且特征也会越丰富? ———–> 一个从业者的正常思维
但是实验表明,随着网络的加深,优化效果反而更差??思考为什么会出现这个现象呢?以下实验结果表明确实出现了该现象,论文中称为网络退化现象,注意这和网络过拟合是两种情况。
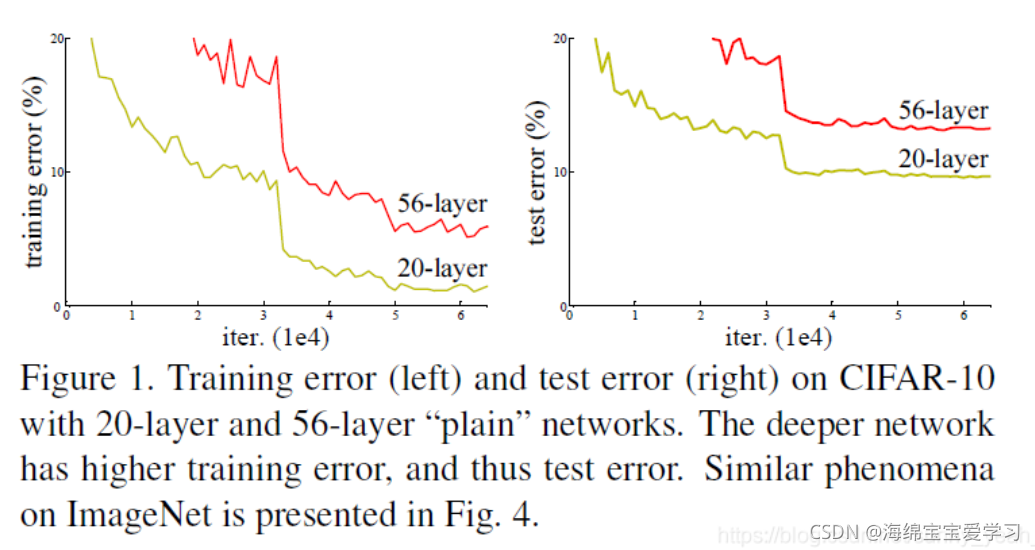
论文给出解释:这是由于网络的加深会造成梯度爆炸和梯度消失的问题。😵梯度消失和梯度爆炸?有没有详解?ok 下面链接告诉你。接下来解释如何解决这个问题呢?继续往下看
1.1 什么叫梯度消失和梯度爆炸
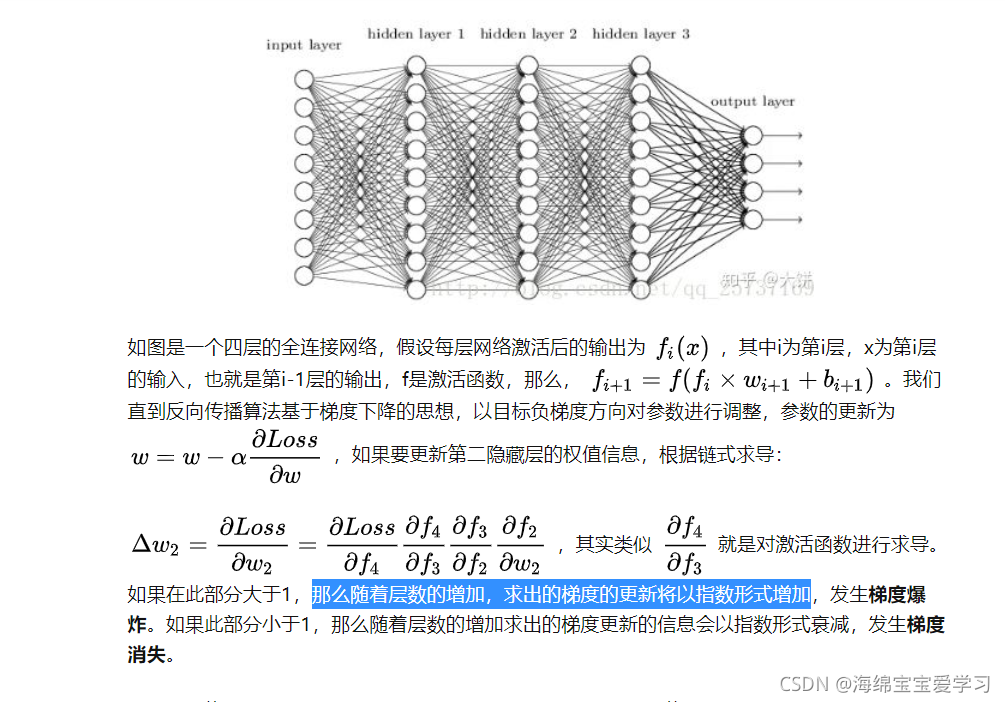
2 How(如何解决该问题)
论文提供了Residual Network(ResNet)网络结构,来使得网络的学习能力能够随着网络深度的增加而增加。

懵逼了…为什么加一个 跳层链接就可以避免退化影响呢???
我们来看一个图片:

好了,我觉得解释的很清楚了!结束…
不对,我们做科研还是要严谨的态度,进行数学理论的介绍
2.1 直观解释
深度残差网络,如果深层网络的后面那些层都是恒等映射,那么模型就退化为一个浅层网络。那现在要解决的就是学习恒等映射函数了。但是直接让一些层去拟合一个潜在的恒等映射函数H(x) = x, 比较困难,这可能就是深层网络难以训练的原因。但是,如果网络设计为H(x) = F(x) + x, 如下图,我们就可以转换为学习一个残差函数F(x) = H(x) -x 。只要F(x) = 0, 就构成一个恒等映射H(x) = x,而且拟合残差肯定更加容易。
理论上,对于随着网络加深,准确率下降的问题,resnet提供了两种选择方式,也就是identity mapping和residual mapping。如果网络已经达到最优,继续加深网络,residual mapping 将被 push为0,只剩下identity mapping,这样理论上网络一直处于最优状态了,网络的性能也就不会随着深度增加而降低了。
通俗的解释就是:
F是求前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是F’(5) = 5.1, 引入残差后是H(5) = 5.1, H(5)=F(5) + 5, F(5) = 0.1。这里的F’和F 都表示网络参数映射,映入残差后的映射对输出的变化更加敏感。 比如s输出从5.1变到5.2,映射F’的输出增加了1/51=2%,而对于残差结构输出从5.1到5.2,映射F’的输出增加了0.1到0.2,增加了100%。明显后者输出变化对权值的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化。
另外这句话解释的也挺好:


2.2 残差是什么
其中ResNet提出了两种mapping:一种是identity mapping,指的就是图1中”弯弯的曲线”,另一种residual mapping,指的就是除了”弯弯的曲线“那部分,所以最后的输出是 y=F(x)+x
identity mapping顾名思义,就是指本身,也就是公式中的x,而residual mapping指的是“差”,也就是y−x,所以残差指的就是F(x)部分。
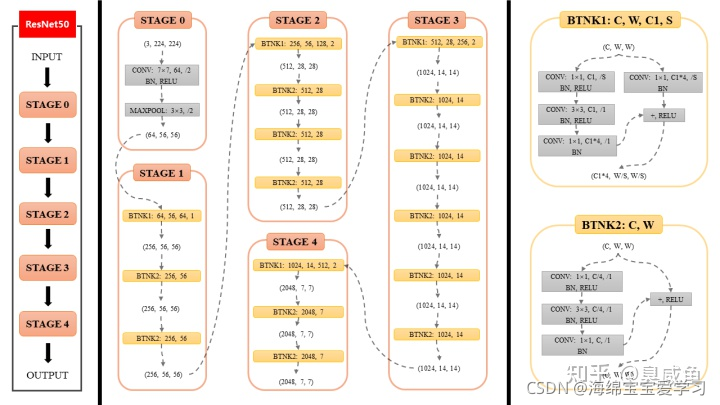
2.3 网络结构
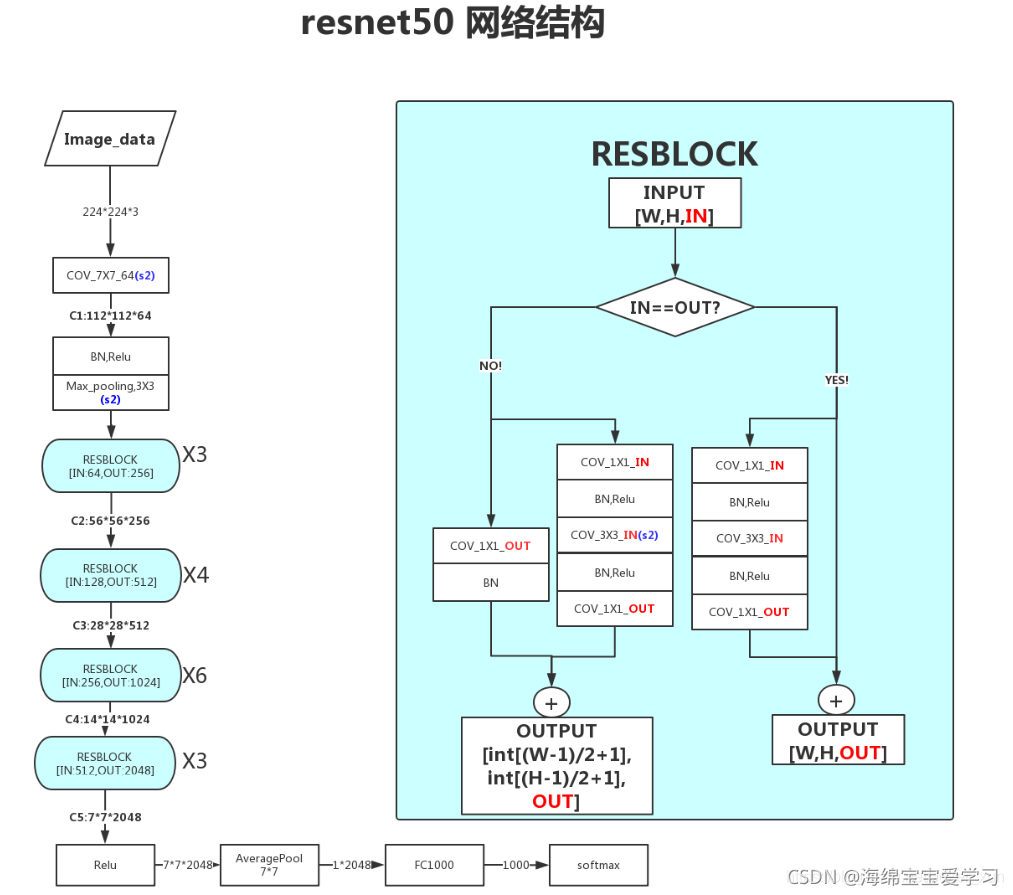
resnet50 一共有四组 block,每组分别是 3,4,6,3 个block,每个block里面有三个卷积层。另外网络最开始有一个卷积层,所以 3+4+6+3 * 3 + 1 = 49,加上取样层。
3 what 结果怎么样
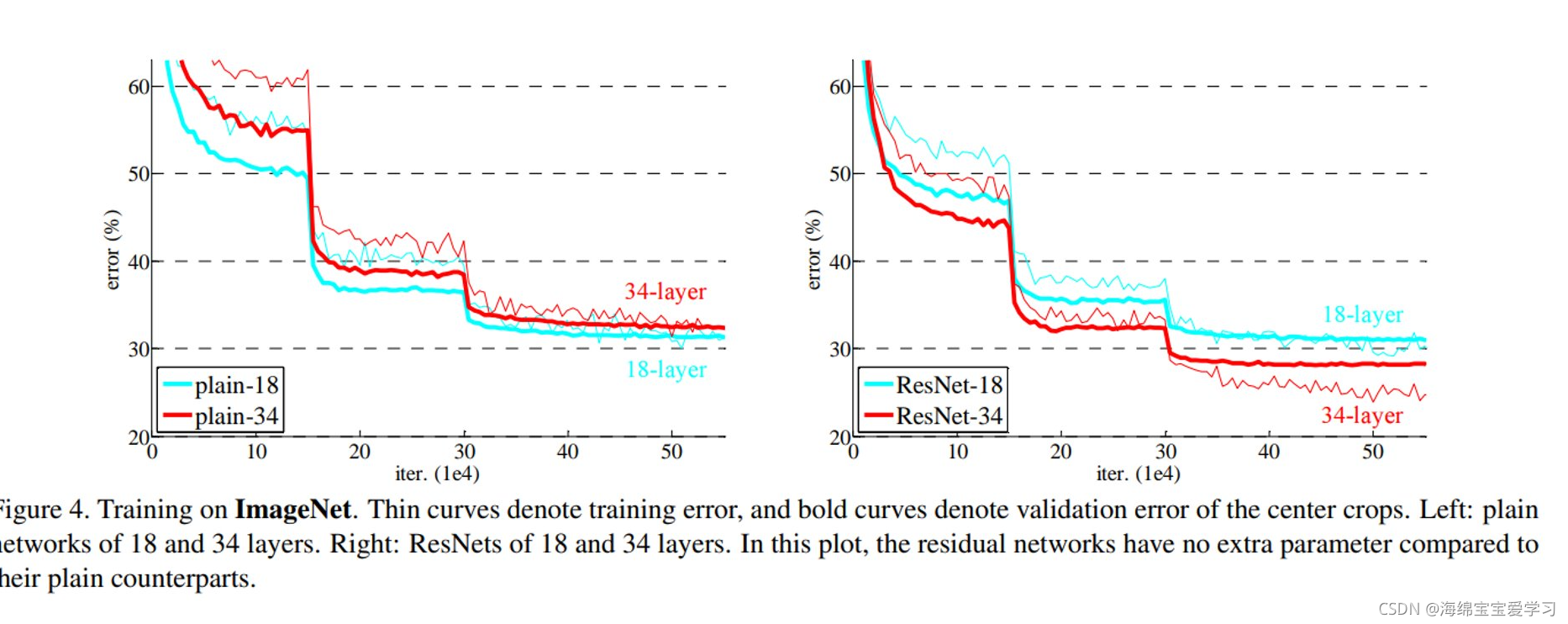
参考:
https://zhuanlan.zhihu.com/p/353235794
https://zhuanlan.zhihu.com/p/67860570
https://www.zhihu.com/question/53224378/answer/159102095
https://blog.csdn.net/Joker_xun/article/details/103024249
文章出处登录后可见!