原文链接:https://arxiv.org/pdf/2007.08199.pdf
github链接:GitHub – songhwanjun/Awesome-Noisy-Labels: A Survey
(本文仅做阅读笔记之用,如需了解细节可自行查看原文,翻译不周之处,敬请指正)
1. Introduction
据统计真实世界的数据集中存在的标注噪声范围在8%到38.5%。
深度神经网络(DNN)因为具有很强的拟合能力,所以很容易对噪声标签过拟合。
正则化技术(如数据增强,权重衰减,dropout,批次正则化(BN)等)虽然能缓解过拟合问题,但是光靠正则化并不能完全克服过拟合。如fig.1就形象地说明了这个问题:
- 无论训练数据是否有噪声(Noisy or Clean),或者是否使用了正则化技术(w/o Reg.),网络都能完全拟合训练集(train-acc 都达到了100%)
- 但是在测试集中存在严重的gap,用了正则化能有效缓解过拟合,但是和无噪声的数据集相比还有很大差距
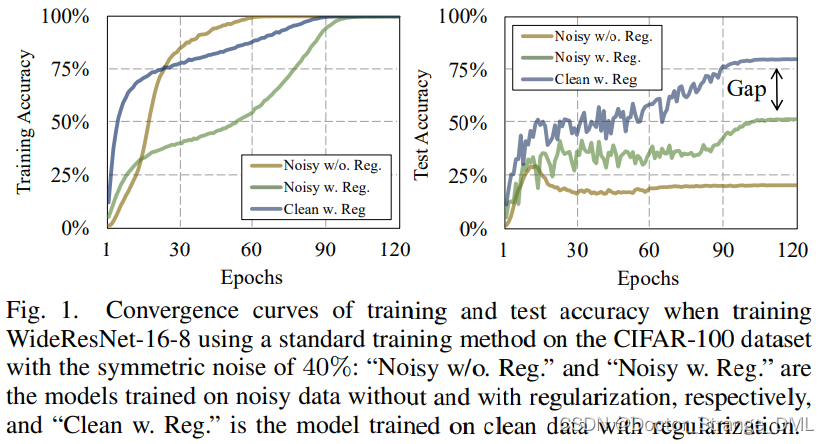
此外,标签中的噪声比其他噪声(如输入的噪声)危害更大。
鲁棒训练(Robust training)还包括其他两个研究方向:对抗学习(Adversarial learning)和数据插补(data imputation),但是以上两个方向都是针对特征上的噪声,因此不在此综述(标签噪声)的讨论范围。
2. Preliminaries
A. 带噪声的全监督学习范式
符号定义,经验风险最小化,梯度下降……
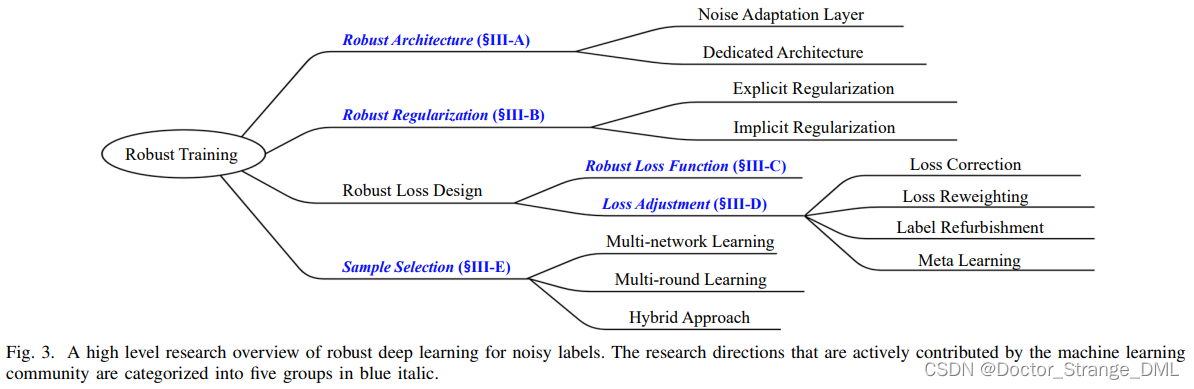
B. 标签噪声的分类
(1)实例不相关的标签噪声
传统的标签噪声建模方法假设标签噪声是和数据特征无关的,使用一个过渡矩阵T来将真实标签变为噪声标签。根据此过渡矩阵的特点(标签转变的概率分布),标签噪声可以分为对称噪声(symmetric noise)和非对称噪声(asymmetric noise),非对称噪声还包括一种极端情况,此时一种标签只可能转变为另外一种噪声,称为对噪声(pair noise)。
(2)实例相关的标签噪声
在实际场景中,噪声更有可能与标签和数据本身的特征都有关系。(即某些困难样本或者模糊样本更有可能有标注错误)
C. 非深度学习的方法
- 数据清洗(data clean)
- 代理损失(surrogate loss)
- 概率方法(probabilistic method)
- 基于特定模型的方法(model-based method)
D. 带标签噪声的回归问题
回归问题的目标是建模特征和连续目标变量之间的关系(分类是离散的目标空间)
回归问题考虑考虑两种类型的标签噪声:
- 加性噪声(additive noise):
- 实例相关噪声(instance-dependent noise):
尽管目标空间不同,但是分类和回归都是学习从特征空间到标签的映射关系,因此用于分类问题的方法很容易扩展到回归问题。本文重点关注分类问题。
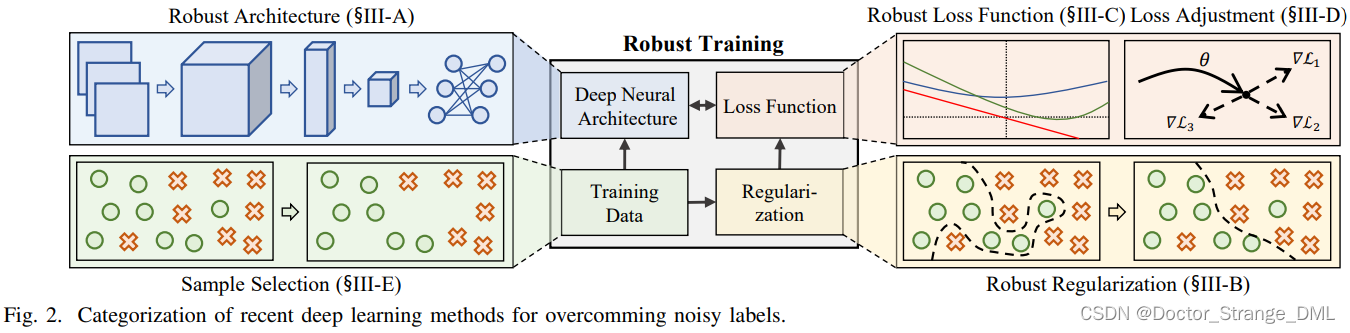
3. 基于深度学习的方法
共分为五类,如fig.2和fig.3所示,分别为:
- 鲁棒结构设计:
- 鲁棒正则化方法:减少对假样本的过拟合
- 鲁棒损失函数设计
- 损失调整:包括损失校正、损失重加权、标签翻新(label refurbishment)和元学习
- 样本选择:【有点类似数据清洗的想法?】
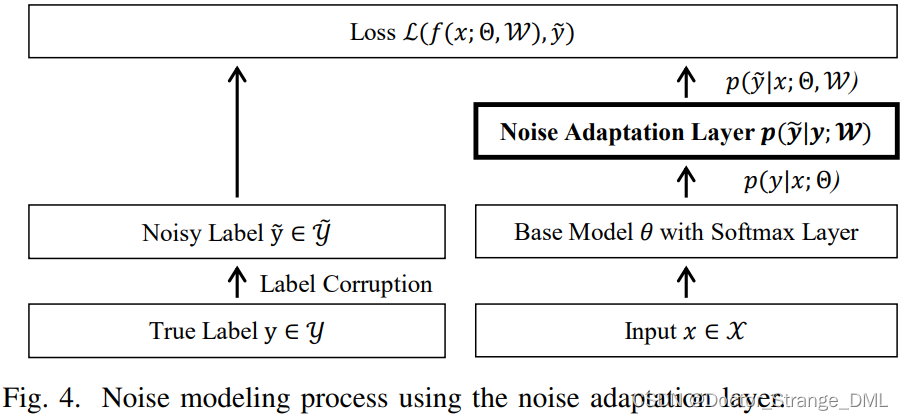
A. Robust Architecture
(1)噪声自适应层(noise adaptation layer)
专门用噪声过渡矩阵来建模噪声转换,测试的去掉这一层。只针对实例无关的噪声。
(2)精细结构(dedicated architecture)
设计精细的网络结构,目标是增加噪声过渡矩阵的估计的可靠性。(标签噪声主要来自于人类和任务的交互作用)此类方法能处理多种类型的噪声,但是不容易扩展到其他通用网络结构。
B. Robust Regularization
正则化是一个常用的缓解过拟合的方法,但是只能处理中等程度的噪声,当噪声非常严重时,网络还是会取得很差泛化性能,因此很多更先进的正则化技术被提出,这类方法的主要有点是可以很灵活的应用到其他问题。
(1)显式正则
直接修改loss,如权重衰减、dropout等。这类方法通常要引入超参或者需要加深网络结构来补偿模型搜索空间的减小,但是如果好好调参会有明显的性能提升。
bilevel learning: 使用一个干净的验证集,应用双层优化的方式来约束过拟合。传统的方法正则化限制也作为一个优化问题。通过调整权重,最小化在验证集上的错误;annotator confusion: 假设存在多个标注者,regularizer使得估计的标签转移概率收敛到真实的标注者混淆矩阵;pre-training: fine-tuning比train from scratch泛化性好很多;loss-based gradient clipping(梯度裁剪的噪声鲁棒版); early-learning(参数分类分别拟合干净和噪声标签,只惩罚其中一类参数); random noise to open-set examples。
(2)隐式正则
隐式引入随机性,如数据增强,小批次随机梯度下降等。隐式正则在不降低模型表示能力的前提下提升了泛化性能,没有引入模型超参,但是扩展的特征和标签空间降低了收敛速度。
adversarial training: 对抗训练,鼓励网络正确分类原始输入和扰动的输入;label smoothing:标签平滑,防止过度自信,平滑分类边界,平滑标签是原始标签和其他可能标签的加权组合;mixup: 数据线性插值,标签也线性插值。
C. Robust Loss Function
理论证明一个适当的损失函数可以在噪声数据上取得贝叶斯最优分类器。这类修改损失函数的方法有很好的理论支撑,但是性能只在简单情况下(学习简单、类别少)比较好,此外因为修改了损失函数,训练时间会更长。
categorical cross entropy(CCE)分类交叉熵损失是最常用的分类损失,但是当存在标签噪声时,robust MAE损失会有更好地泛化性能,但是MAE在数据复杂是性能会下降;generalized cross entropy(GCE) 结合了CCE和MAE的优点;symmetric cross entropy(SCE)在CCE上结合了一个noise tolerance term;curriculum loss(CL)是0-1 loss的代理损失,它提供了一个更紧的上界并且很容易扩展到多类任务;active passive loss(APL)是两种噪声鲁棒损失的组合,其中一个最大化属于某一类的概率,另一个最小化属于其他类的概率。
D. Loss Adjustment
不同于C中的鲁棒损失函数,这类方法目标是让传统的优化过程更加噪声鲁棒,因此通过在训练过程中调整更新规则来最小化噪声标签的负面影响。但是可能会有矫枉过正的问题,尤其是类别或者错误标注的样本数量很多的时候。
(1)Loss Correction
和噪声自适应层类似,损失校正通过给模型输出结果乘上一个估计的标签转移矩阵来修改loss,不同之处在于,噪声转移矩阵的学习是和模型的学习解耦的。此类方法高度依赖噪声转移矩阵的估计,因此通常需要先验知识(如锚点或者干净的验证集)。
backward correction:先正常计算loss,反向传播的时候再用噪声转移矩阵校正;forward correction:先根据噪声转移矩阵对模型输出结果校正,再计算损失;gold loss correction:利用一个干净的验证集或者锚点作为辅助信息;T-Revision:估计噪声转移矩阵不需要锚点;Dual T:将转移矩阵分解为两个容易估计的矩阵的乘积;[115]将实例置信度嵌入来估计实例相关噪声;[116]使用贝叶斯最优转移矩阵。
(2)Loss Reweighting
计算loss时给假样本更小的权重,给真样本更高的权重。这类方法手动设计权重函数和超参,因此很难实际应用(因为权重范式严重依赖于噪声类型和训练数据)
importance reweighting:近似估计两种数据的联合分布,以此来决定对loss的权重;[109] active bias:重点关注预测不一致的不确定样本,并将预测方差作为loss权重;DualGraph:使用图神经网络,并根据标签之间的结构化信息来对样本加权,从而削弱异常样本的作用。
(3)Label Refurbishment
将网络的输出标签和噪声标签组合作为翻新后的标签:(是噪声标签的置信度)
不同于损失校正和重加权,这类方法将所有噪声标签都显式地替换为近似的干净标签。但是在噪声标签比例很高的情况下,很容易过拟合到被错误翻新的样本上。
[69] bootstrapping:第一个提出标签翻新的想法来更新训练集的标签,使用交叉验证来获取标签的置信度;[110] dynamic bootstrapping:动态调整置信度,通过拟合混合模型到所有样本的loss分布?self-adaptive training:使用指数滑动平均的翻新标签
D2L:使用维数驱动的学习策略来防止过拟合;local intrinsic dimensionality:避免表征子空间的维度扩增;SELFIE:认为有一致性预测的样本为可翻新样本,只有可翻新样本才可用于校正;AdaCorr:选择性地翻新样本,但是提供了一个理论上的误差界;SEAL:对每个样本,将整个训练过程中的输出求均值后作为标签,然后重新训练一次
(4)Meta Learning
元学习,学习如何学习,因此可以实现数据不可知或者噪声类型不可知的学习,本方法和损失重加权或者标签翻新类似,但是所有调整都是自动的。本方法很容易适应各种类型的训练数据和标签噪声,但是无偏的干净验证集在现实世界中可能难以获得。
- 对于loss reweighting:L2LWS, CWS:由目标DNN和meta-DNN组成,meta-DNN在小规模的干净验证集上训练,从而为目标DNN提供指导;Automatic reweighting:根据梯度方向学习样本权重,最小化在干净验证集上的loss;Meta-weight-net将权重函数参数化为一个MLP,元目标是最小化干净验证集上的经验风险;data coefficients:用元优化的方式来估计样例权重和真实标签
- 对于label refurbishment:knowledge distillation:将专家模型迁移到目标模型【知识蒸馏:综述】;[130] MLC:使用在干净验证集上训练的meta-model提供的标签来训练目标网络,两个模型同时训练(via bi-level optimization)
E. Sample Selection
只用每个批次选出的干净样本来训练网络,DNN的记忆特性被用来从噪声数据集中提取干净样本,DNN倾向于先学习简单和通用的模式然后渐渐过拟合到噪声噪声上,因此经常选择有较小训练loss的样本作为干净样本。但是一旦错误选择了样本就会造成累积错误,因此很多方法选择利用多个网络互相协作或者训练多轮。
(1)Multi-network Learning
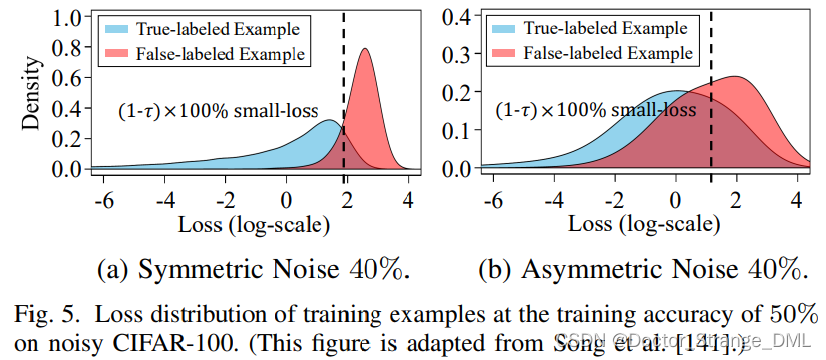
[70] Decouple:将何时更新从如何更新中解耦出来,两个网络保持一致,只在样本选择存在分歧时才更新;small-loss trick:将一定数量的拥有较小的loss的样本视为干净样本,因为相比于噪声标签,真实标签数据通常拥有更小的损失,如fig.5(a)所示(但是在某些情况下不明显,如fig.5(b)中的非对称损失);MentorNet:导师网络给学生网络提供标签大概率是正确的样本;Co-teaching:每个网络选择一定数量的小loss样本g给另一个网络;Co-teaching+:在此基础上进一步应用Decouple中的分歧策略;JoCoR:通过co-regularization来减少两个网络之间的差异,使预测值相近
(2)Multi-round Learning
不需要附加的网络,这种方法通过重复迭代不断优化选择的干净训练集。缺点是计算开销随着训练轮数线性增长。
ITLM:选择样本和利用选择的样本进行训练交替进行;INCV:通过随机划分和交叉验证来选择真实标签样本,同时移除大loss样本;O2U-Net:重复整个训练过程直到收集到足够的每个样本的loss统计信息,然后在基于上一步得到的统计信息筛选后的干净的训练集上重新训练;iterative detection:使用local outlier factor算法检测噪声样本,在深度特征空间逐渐拉开噪声样本和真实样本的距离;MORPH:引入记忆样本,通过self-transitional learning逐渐扩增safe-set;TopoFilter:利用表征的空间拓扑模式来检测真实样本;NGC:使用隐空间特征逐渐构建最近邻图,然后通过聚合邻居信息来构建样本选择策略
(3)Hybrid Approach
样本选择的一个显著缺点是直接抛弃了所有未被选择的样本,为了充分利用噪声数据,混合策略应运而生。但是超参太多,并且不可避免的引入了额外的计算开销。
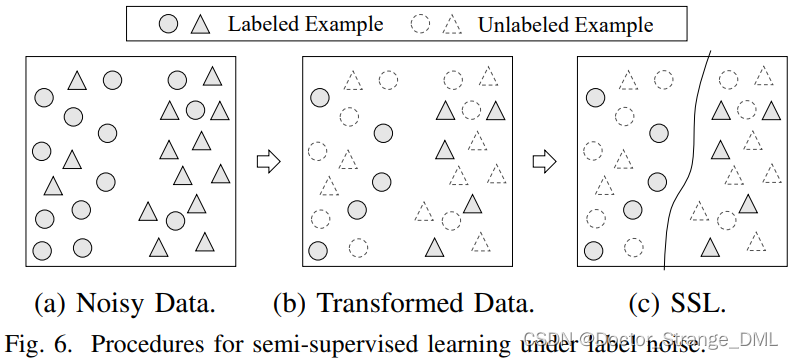
本方法中最著名的是结合半监督学习,如fig.6所示,将未被选择的样本(噪声样本)作为无标签数据;SELF:将滑动平均版的模型作为mean-teacher来获得自集成的预测,将标签和自集成预测的结果不一致的样本逐渐移除,然后利用移除的样本进行无监督学习;DivideMix:使用一维双混合高斯模型将噪声数据划分为有标签和无标签两组,然后应用MixMatch(一种半监督学习方法);RoCL:两阶段训练策略,在干净样本上监督学习,在重新标注的噪声样本上自监督学习,通过计算训练loss的指数滑动平均来选择和重标签样本;
SELFIE:翻新后的样本的loss被校正之后和small-loss的样本一起使用,因此有更多的样本用于训练网络;curriculum loss:经常和robust loss function一起使用
4. 方法对比
62个基于深度学习的方法,从以下六个角度进行对比,分别是:
- Flexibility:灵活性,是否支持任意网络结构
- No Pre-training:是否使用预训练模型
- Full Exploration:是否充分利用所有数据(or 直接放弃难样本)
- No Supervision:是否有已知干净的验证集或者噪声比例(最好是没有)
- Heavy Noise:是否对严重的噪声(主要指噪声比例高)也有鲁棒性
- Complex Noise:是否对噪声类型复杂的情况(如实例相关的噪声)也有鲁棒性
结果如table.2所示,6中属性支持的越多越好,圈表示支持,叉表示不支持,三角表示不完全支持
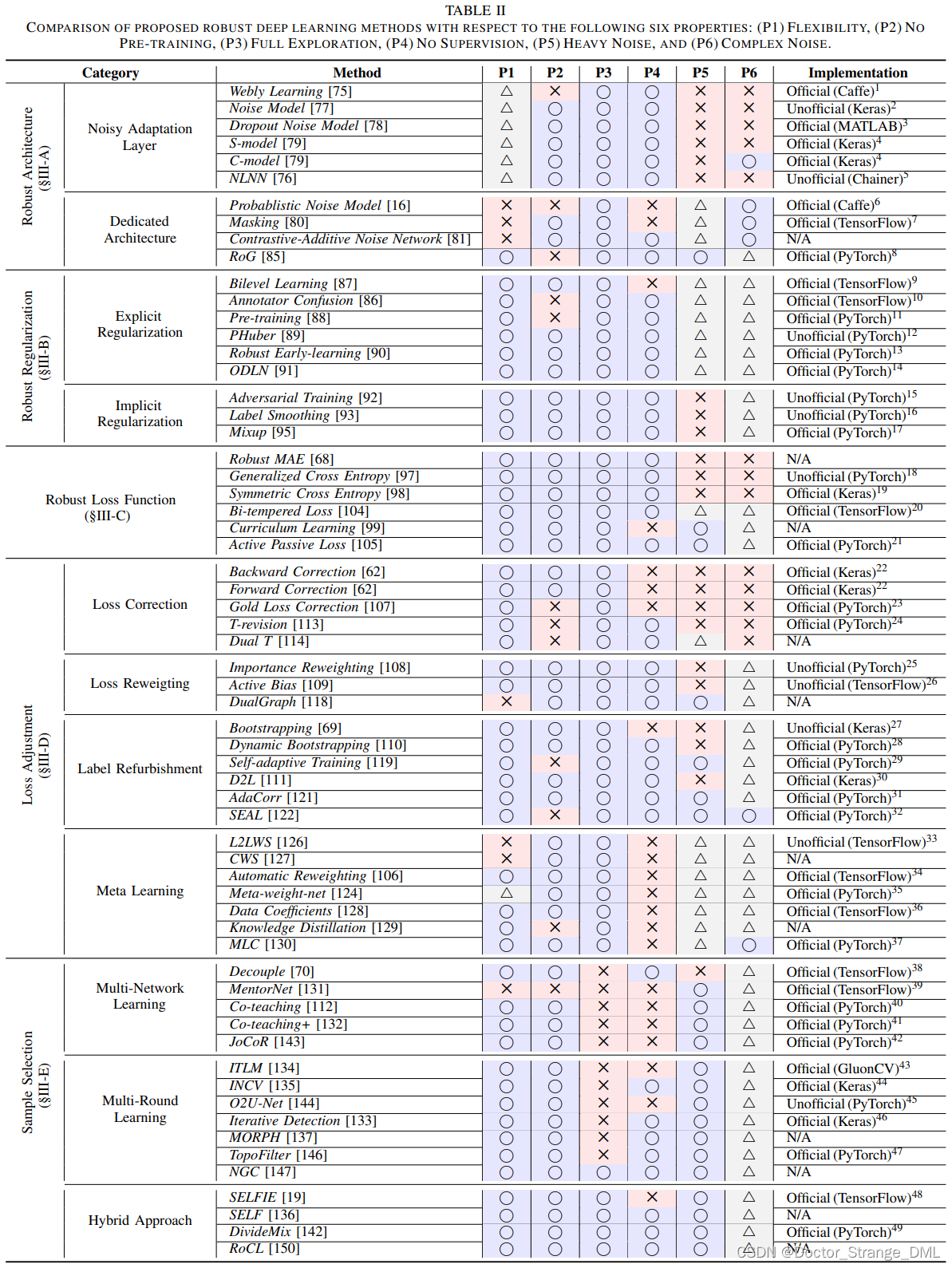
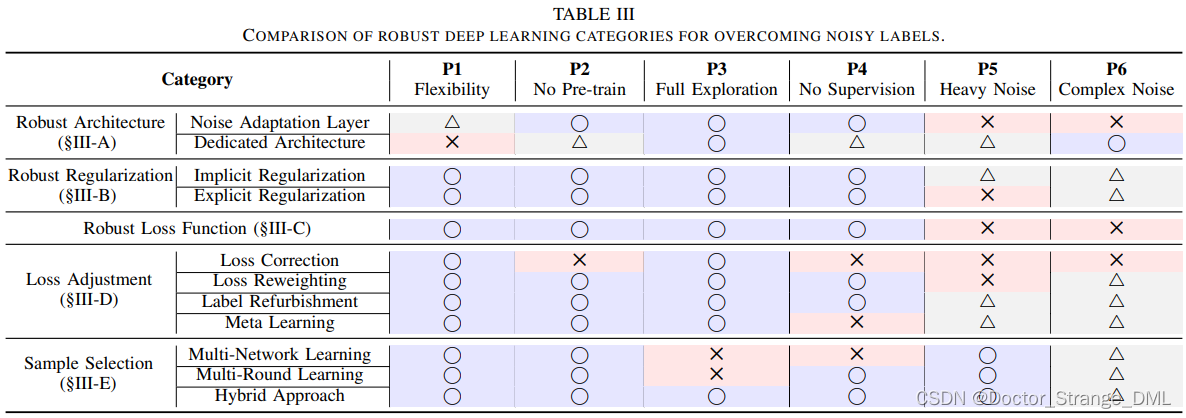
现有方法没有完全支持六种属性的,同类方法有类似的属性支持,因此进一步总结方法类别的特点如table.3所示:
5. 噪声比例估计 todo
噪声比例估计在实际应用中非常重要,尤其是对于损失调整和样本选择策略。常用的有以下三种方法:
A. Noise Transition Matrix
B. Gaussian Mixture Model
C. Cross Validation
6. 实验设计
A. 公共数据集
(1)干净的数据集
MNIST, Fashion-MNIST, CIFAR-10/100, SVHN, (Tiny)ImageNet…
(2)真实世界的带噪数据集
ANIMAL-10N, CIFAR-10N/100N, Food-101N, Clothing1M, WebVision
B. 评价指标
测试集准确率,验证集准确率,样本选择方法中的精确率和召回率,标签翻新方法中的校正错误率
7. 未来研究方向
A. 实例相关的噪声
统计实验表明,Clothing1M的标签噪声并不属于实例无关的噪声。
B. 多标签数据的标签噪声
音乐分类任务中每个样本可以属于多个种类[162], 据说多标签的数据集中的样本错误率高达26.6%,还有大量的缺失的标签。
C. 类别不均衡数据
为了简化标签噪声问题,经常假设类别是均衡的,但实际在大规模数据集中假设往往不成立。在类别不均衡场景下很多现有的方法可能并不work,尤其是当他们依赖网络的动态性时,如small-loss trick和memorization effect。
D. 鲁棒且公平的训练
公平训练关注data bias,鲁棒训练关注data noise,然而实际场景中二者同时存在,同时满足鲁棒和公平的要求就非常有挑战性。
E. 思考和输入扰动的关系
噪声输入问题和噪声标签问题的研究都是为了获得噪声鲁棒的特征表示,因此可以联动。最近的一些研究表明对抗训练可以使模型更加噪声鲁棒
F. 高效学习和轻量化
提升学习过程的效率经常被忽视,比如多分支网络结构或者多轮训练就非常低效
文章出处登录后可见!