pytorch参数初始化
1. 关于常见的初始化方法
1) 均匀分布初始化torch.nn.init.uniform_()
torch.nn.init.uniform_(tensor, a=0.0, b=1.0)
使输入的张量服从(a,b)的均匀分布并返回。
2) 正态分布初始化torch.nn.init.normal_()
torch.nn.init.normal_(tensor, mean=0.0, std=1.0)
从给定的均值和标准差的正态分布N(mean,std)中生成值,初始化张量。
3) 常量初始化torch.nn.init.constant_()
torch.nn.init.constant_(tensor, val)
以一确定数值初始化张量。
4) Xavier均匀分布
torch.nn.init.xavier_uniform_(tensor, gain=1.0)
从均匀分布U(−a, a)中采样,初始化输入张量,其中a的值由如下公式确定,
公式中的gain值根据不同的激活函数确定
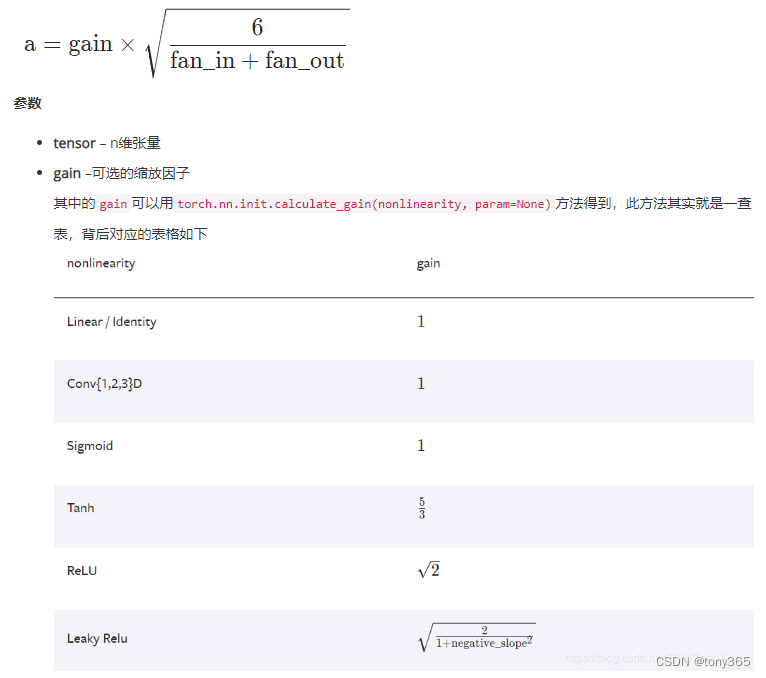
5)Xavier正态分布初始化
torch.nn.init.xavier_normal_(tensor, gain=1.0)

6) kaiming均匀分布初始化
torch.nn.init.kaiming_uniform_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')

7) kaiming正态分布初始化
torch.nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')

[1]https://www.cxyzjd.com/article/CQUSongYuxin/110928126
8) 单位初始化(在优化一些转换矩阵的时候可能会用到)
torch.nn.init.eye_(tensor)
9)正交初始化
torch.nn.init.orthogonal_(tensor, gain=1)
10) 自定义初始化
在搭建模型的时候 会 遇到需要自己自定义初始化数据的时候
class ResidualBlockNoBN(nn.Module):
"""Residual block without BN.
It has a style of:
::
---Conv-ReLU-Conv-+-
|________________|
Args:
mid_channels (int): Channel number of intermediate features.
Default: 64.
res_scale (float): Used to scale the residual before addition.
Default: 1.0.
"""
def __init__(self, mid_channels=64, res_scale=1.0):
super().__init__()
self.res_scale = res_scale
self.conv1 = nn.Conv2d(mid_channels, mid_channels, 3, 1, 1, bias=True)
self.conv2 = nn.Conv2d(mid_channels, mid_channels, 3, 1, 1, bias=True)
self.relu = nn.ReLU(inplace=True)
# if res_scale < 1.0, use the default initialization, as in EDSR.
# if res_scale = 1.0, use scaled kaiming_init, as in MSRResNet.
if res_scale == 1.0:
self.init_weights()
# 直接在__init__函数中使用
def init_weights(self):
"""Initialize weights for ResidualBlockNoBN.
Initialization methods like `kaiming_init` are for VGG-style
modules. For modules with residual paths, using smaller std is
better for stability and performance. We empirically use 0.1.
See more details in "ESRGAN: Enhanced Super-Resolution Generative
Adversarial Networks"
"""
# 初始化需要初始化的layer
for m in [self.conv1, self.conv2]:
nn.init.kaiming_uniform_(m.weight, a=0, mode='fan_in', nonlinearity='relu')
m.weight.data *= 0.1
nn.init.constant_(m.bias, 0)
def forward(self, x):
"""Forward function.
Args:
x (Tensor): Input tensor with shape (n, c, h, w).
Returns:
Tensor: Forward results.
"""
identity = x
x=self.conv1(x)
x=self.relu(x)
out = self.conv2(x)
return identity + out * self.res_scale
总之,参数初始化就是 给 参数附上需要的数值而已,
比如:
# 创建一个卷积层,它的权值是默认kaiming初始化的
w=torch.nn.Conv2d(2,2,3,padding=1)
print(w.weight)
# 先创建一个自定义权值的Tensor,这里为了方便只创建一个简单的tensor, 将所有权值设为1
ones=torch.Tensor(np.ones([2,2,3,3]))
# 当然也可以不使用numpy,直接torch.ones
ones=torch.ones((2,2,3,3))
# 把Tensor的值作为权值赋值给Conv层,这里需要先转为torch.nn.Parameter类型,否则将报错
w.weight=torch.nn.Parameter(ones)
[2]https://ptorch.com/docs/1/nn-init
[3]https://blog.csdn.net/goodxin_ie/article/details/84555805
关于初始化参数的理论介绍可以参考
[4]https://zhuanlan.zhihu.com/p/25110150
文章出处登录后可见!
已经登录?立即刷新