特征匹配
在声音训练得到的模型中,我们如何检测某一段音频中是否存在我们想要的波段?
假设我们训练得到“机”这个字的音频为【1,2,5,8,1】
而待检测的声音“煤 泥 只 因 抬”波形为【1,2,12,4,8,9,2,1,2,4,8,1,0,8,1,2,1,↑】
通过观察可以看到需要找的波段和待检测的声音中黄色的波段相似度最高。
滑动窗口
窗口滑动的过程就是窗口数据在某段数据上按照某个步长遍历对照的过程
滑动窗口算法有三个要素:窗口长度,滑动长度,滑动步长。
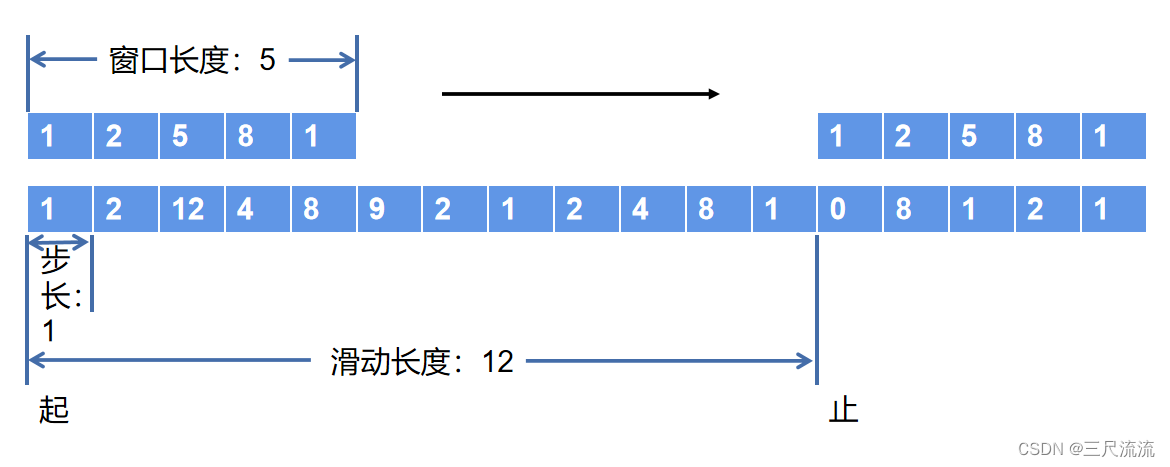
图中窗口为5的列表按照“1”的速度向对照列表末端滑动。每滑动一位坐标就与下方列表对应的坐标段进行一次对照。
特征相似度
特征相似度指示的是两个特征是否接近,在高维的特征列表中,一般应用俩高维特征点之间的距离来表示两个特征之间的差异大小。
欧氏距离
欧氏距离算法(Euclidean distance)也称欧几里得距离,是最常见的距离度量描述两个相同维度向量数据区别(距离)的算法。
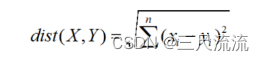
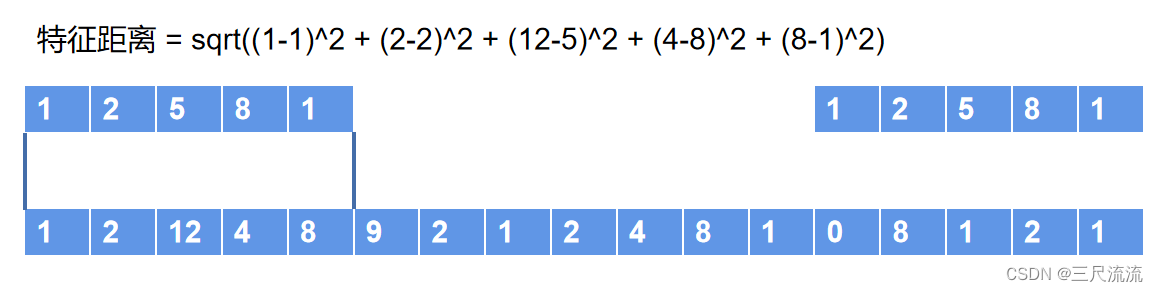
使用此特征时,每滑动一位需要计算一次欧式距离,图中一共计算13次距离。计算所得的欧氏距离均为大于等于0的数,当距离越小时两段高纬度向量列表的特征也相似度越高。
逻辑流
1.输入“机”与“煤 泥 只 因 抬”的音频列表。
2.计算窗口的滑动范围。
3.依次按照步长滑动窗口,计算每一步的特征相似度。
4.筛选得到相似度最高的音频段。
完整代码
import numpy as np
voice_j = np.asarray([1,2,5,8,1])
voice_mnzyt = np.asarray([1,2,12,4,8,9,2,1,2,4,8,1,0,8,1,2,1])
# 特征差异列表
edu_list = []
# 滑动步长
for i in range(len(voice_mnzyt)-len(voice_j)+1):
voice_compare = voice_mnzyt[i:i+len(voice_j):1]
# print(voice_compare,voice_compare)
edu_list.append(np.sqrt(sum((voice_compare - voice_j) ** 2)))
print("特征差异列表",edu_list)
print("相似索引",edu_list.index(min(edu_list)))由结果可以看到,在待检测音频中坐标为“7”,长度为“5”的一段音频与我们所要找的的音频特征相似度差异仅为“1”
结论:“机”与“只因”发音高度相似且发声所用时基本相同,我们所要查找的字符位“机”的音频于检测音频坐标“7”的位置。
文章出处登录后可见!
已经登录?立即刷新