目录
1 生成模型分类 1
2 Autoregressive model 2
3 变分推断 3
3.1 ELBO 3
3.2 变分分布族Q 5
4 VAE 6
5 GAN 6
6 flow模型 7
7 EM算法 8
8 DDPM 8
1 生成模型分类
生成模型(Generatitve Models)在传统机器学习中具有悠久的历史,它经常与另外一个主要方法(判别模型,Discriminative Models)区分开。
主要有如下几种生成模型:autoregressive models 、VAE、GAN、flow、DDPM。
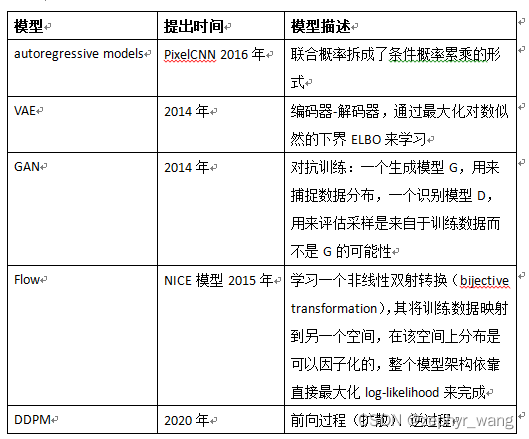
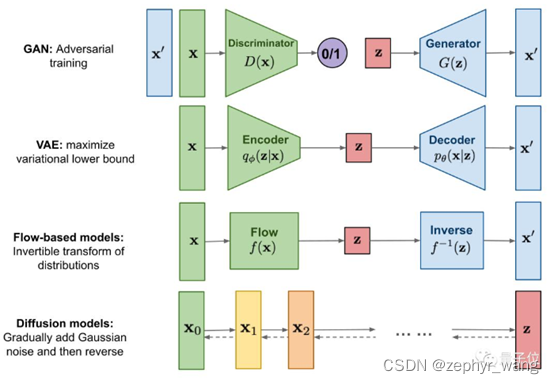
上图摘自:https://m.thepaper.cn/baijiahao_19541556
2 Autoregressive model
自回归模型(英语:Autoregressive model,简称AR模型),是统计上一种处理时间序列的方法,用同一变数例如x的之前各期,亦即x1至xt-1来预测本期xt的表现,并假设它们为一线性关系。因为这是从回归分析中的线性回归发展而来,只是不用x预测y,而是用x预测 x(自己);所以叫做自回归。
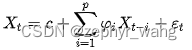
神经网络中的AR模型,将联合概率拆成了条件概率累乘的形式,采用如下形式:
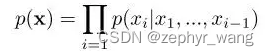
如PixelCNN模型,自回归模型的一个主要缺点是它生成速度慢,因为需要逐像素生成,而无法并行化。
3 变分推断
马尔科夫蒙特卡洛(MCMC)采样是近似推断(Approximate Inference)的一种重要方法,其改进包括Metropolis-Hastings算法,Gibbs采样。
在MCMC不满足性能要求的时候,我们使用变分推断(Variational Inference,VI)。变分推断通过优化逼近后验,而MCMC通过采样逼近后验。
对观测数据x=(x1,…,xn)和隐变量z=(z1,…,zm),推断问题(inference)希望计算出隐变量的后验概率p(z|x),利用贝叶斯公式重写后验概率如下公式。在确定隐变量z的先验概率p(z)时,公式中的联合概率p(z,x)能够计算,而p(x)需要积分p(x)=∫p(z,x)dz计算,但是通常,这个积分没有解析解,利用采样的方法计算效率也非常低。
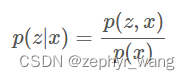
EM算法、VAE、GAN、AAE、ALI(BiGAN)都可以作为变分推断的某个特例。
3.1 ELBO
变分推断选择一类分布族Q(称为变分分布族),将推断问题转换为优化q*∈Q使得与后验p(z|x)的差别最小。
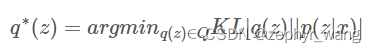
变分推断使用KL[q||p]衡量变分分布(即分布q)和真实后验p之间的差别,KL散度是非对称的,这种形式的KL着重于惩罚真实后验p很小时变分概率q很大的情况。
我们无法最小化目标函数KL[q||p],因为KL中包含有logp(x),如下推导:
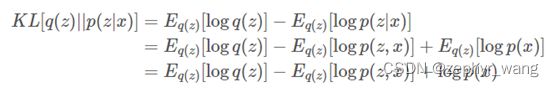
但是,通过上面公式的变化可以得到一个新的目标函数ELBO:
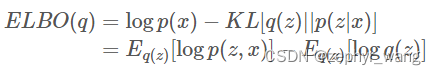
这个目标函数可以从两个方面来解释:
由于logp(x)相对于q(z)是一个常量,而我们想要最小化KL,而ELBO等于负的KL加上一个常量,所以我们最大化ELBO就等价于最小化KL。
最大化logp(x)就是对观测数据的极大似然估计(即log evidence),由于KL是非负的,所以这个目标函数ELBO是极大似然估计log p(x)的下界(即evidence lower bound, ELBO)。
继续推导:
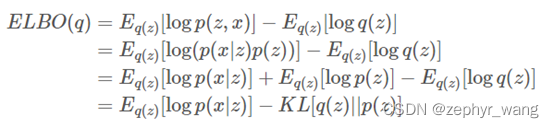
从结果来看,ELBO目标函数第一项是似然的期望,第二项是与先验之间的差别。所以最大化ELBO就是在**(1)隐变量对观测数据的解释最佳和(2)变分分布q更靠近先验之间平衡。**
3.2 变分分布族Q
对变分推断中选择的变分分布族Q进行介绍。
由于分布族Q越复杂,变分推断的优化就越复杂。一般变分推断中会假定一个性质,就是选择的分布族是平均场变分分布族(mean-field variational family)。

使用平均场变分分布族的缺点是,当隐变量之间互相有关联的时候(性质被破坏)逼近的效果就会下降。比如下图的二维高斯后验,x1和x2两个隐变量的后验概率是紫色的椭圆形部分,而我们使用mean-field approximation的时候,会学习到一个均值相同但协方差不同的二维高斯分布。
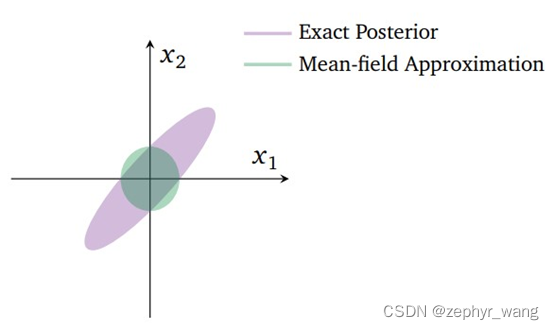
参考文章http://cairohy.github.io/2018/02/28/vi/VI-1/
4 VAE
VAE(Variational Auto-Encoder)变分自编码器。
引入了Stochastic Gradient VB(SGVB)方法,对variational lower bound进行估计,对连续隐变量的有效近似推断。进而提出了使用SGVB估计器的Auto-Encoding VB(AEVB)。
SGVB的一个公式如下,主要是引入了重参数g,可以看到类似上面的ELBO:
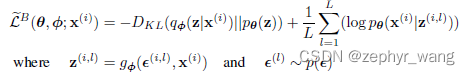
参见:https://blog.csdn.net/zephyr_wang/article/details/126259953
5 GAN
GAN(Ganerative Adversarial Networks)生成对抗性网络
GAN产生了许多流行的架构,如DCGAN,StyleGAN,BigGAN,StackGAN,Pix2pix,Age-cGAN,CycleGAN等.
对抗自编码器(Adversarial Autoencoders,AAE)和对抗推断学习(Adversarially Learned Inference,ALI)这两个模型是GAN的变种之一。
模型如下:
p(z):带有噪声的输入;
G(z,θ):一个可微分的函数,带参数θ的多层感知机;
D(x):代表x是来自于data还是来自于生成函数的概率。
整体训练函数如下,最大化D,同时针对G来最小化log(1-D(G(z))):
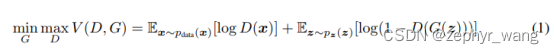
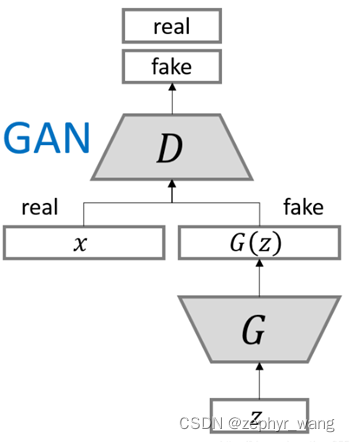
参见:https://blog.csdn.net/zephyr_wang/article/details/105037867
6 flow模型
NICE模型是学习一个非线性双射转换(bijective transformation),其将训练数据映射到另一个空间,在该空间上分布是可以因子化的,整个模型架构依靠直接最大化log-likelihood来完成。
利用change of variable方法。对于转换h=f(x),我们假定f是可逆的,h的维度和x的一样。
训练目标函数如下:
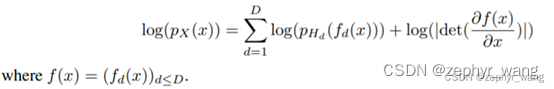
参见:https://blog.csdn.net/zephyr_wang/article/details/126575352
7 EM算法
最大期望算法(Expectation-Maximization algorithm, EM),或Dempster-Laird-Rubin算法,是一类通过迭代进行极大似然估计(Maximum Likelihood Estimation, MLE)的优化算法。

8 DDPM
《Denoising Diffusion Probabilistic Models》,即DDPM,去噪扩散概率模型。
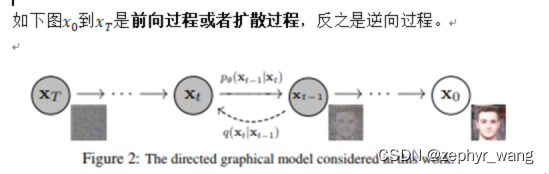
在训练阶段,则是通过对真实数据分布下,最大化模型预测分布的对数似然,即下面算法1。

参见:https://blog.csdn.net/zephyr_wang/article/details/126455200
文章出处登录后可见!