深度学习模型的训练
前言
在我们训练模型时,会经常使用一些小技巧,包括:模型的保存与加载、断点的保存与加载、模型的冻结与预热、模型的预训练与加载、单GPU训练与多GPU训练。这些在我们训练网络的过程中会经常遇到。
1.模型的保存与加载
方法一:同时保存模型和参数
# 保存(vgg16是模型,vgg16_methond1.pth是保存的名称)
torch.save(vgg16,"vgg16_methond1.pth")
# 加载
model = torch.load("vgg16_methond1.pth")
方法二:仅保存参数(数据量小,推荐!)
# 保存
torch.save(vgg16.state_dict(),"vgg16_methond2.pth")
# 加载
model2= vgg16(classes=2019) # 初始化网络结构
vgg16_dict = torch.load("vgg16_methond2.pth")# 加载参数
model2.load_state_dict(vgg16_dict ) # 将参数加载到网络中去
注意:加载模型权重时,我们需要先实例化模型类,因为该类定义了网络的结构。
2.断点的保存与加载
如果模型的训练时间非常长,而这中间发生了一点小意外,使得模型终止训练,而下次训练时为了节省时间,让模型从断点处继续训练,这就需要在模型训练的过程中保存一些信息,使得模型发生意外后再次训练能从断点处继续训练。所以在模型训练过程中记录信息(checkpoint)是非常重要的一点。模型训练的五个过程:数据、损失函数、模型、优化器、迭代训练。这五个步骤中数据和损失函数是没法改变的,而在迭代训练的过程中模型的一些可学习参数和优化器中的一些缓存是会变的,所以需要保留这些信息,另外还需要保留迭代的次数和学习率。
# 在模型训练时,每隔5个epoch保存模型信息
if (epoch+1) % 5== 0:
checkpoint = {
"net": model.state_dict(),
'optimizer': optimizer.state_dict(),
"epoch": epoch,
'lr_schedule': lr_schedule.state_dict()}
path_checkpoint = "./checkpoint.pkl"
torch.save(checkpoint, path_checkpoint)
# 加载断点
path_checkpoint = "./checkpoint_4_epoch.pkl"
checkpoint = torch.load(path_checkpoint) # 加载断点
net.load_state_dict(checkpoint['model']) # 加载模型可学习参数
optimizer.load_state_dict(checkpoint['optimizer']) # 加载优化器参数
start_epoch = checkpoint['epoch'] # 设置开始的epoch
lr_schedule.load_state_dict(checkpoint['lr_schedule'])#加载lr_scheduler
scheduler.last_epoch = start_epoch
在运行推理之前,必须调用model.eval()以将 dropout 和批量标准化层设置为评估模式。不这样做会产生不一致的推理结果。如果是像希望恢复训练,就调用model.train()以确保这些层处于训练模式。
3.预训练模型的使用
pytorch自带有一些高级的复杂模型,有两种使用的方式;
方法一:用torchvision.models函数调用,例如torchvision.models.densenet169(pretrained=True)就调用了densenet169的预训练模型。先来看看这个模块涵盖了哪些模型:见https://pytorch.org/vision/stable/models.html获取详细信息。像resnet50
from torchvision.io import read_image
from torchvision.models.quantization import resnet50, ResNet50_QuantizedWeights
resnet50(weights=ResNet50_Weights.DEFAULT)
# Strings are also supported
resnet50(weights="IMAGENET1K_V2")
# No weights - random initialization
resnet50(weights=None)
方法二:下载训练好了的参数:
在网站中下载好参数,然后直接加载进网络。
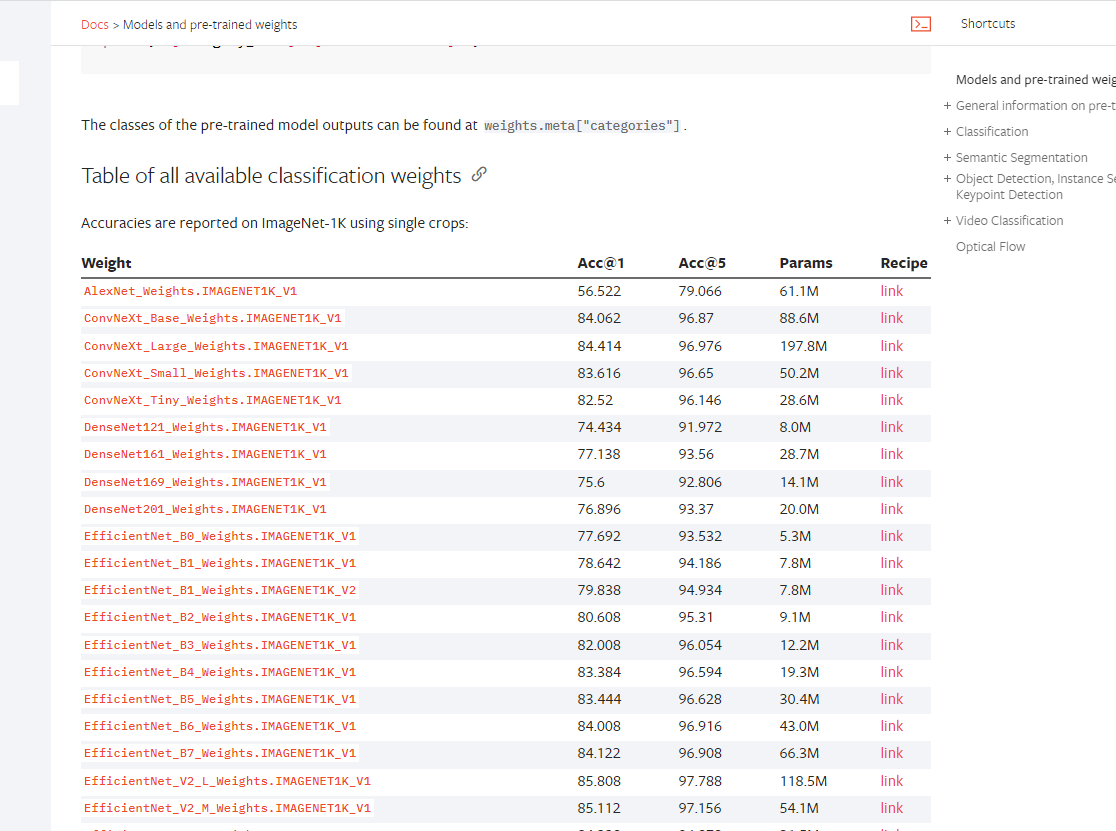
网站还是上面的那个网站,往下翻就能找到。而且不仅仅是分类的模型,语义分割、量化、对象检测、实例分割和人物关键点检测等等。在这里都能找到
4.模型的冻结
在迁移学习或训练新的复杂模型时,加载部分模型是常见的情况。利用训练好的参数,有助于热启动训练过程,并希望帮助你的模型比从头开始训练能够更快地收敛。
方法一:设置requires_grad为False
这种方法的效果是:被冻结的层可以前向传播,也可以反向传播,只是自己这一层的参数不更新,其他未冻结层的参数正常更新。要注意优化器要加上filter: (别的文章都说需要加,但是我用代码测试发现不加好像也可以)
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, perception.parameters()), lr=learning_rate)
还要注意的是: 构造optimizer对象的位置要放在冻结图层操作之后。
设置requires_grad为False有两种方法:
①: x.requires_grad_(False)
②:x.requires_grad = False
两种效果相同。
直接看例子:
import torch
import numpy as np
from torch import nn
from torch.optim import lr_scheduler
# 检查GPU是否可用
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
# 首先建立一个卷积的神经网络
class Bulk(nn.Module):
def __init__(self,in_channels,out_channels):
super(Bulk, self).__init__()
self.bulk_6 = nn.Sequential(
nn.Conv2d(in_channels,in_channels*2, kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(in_channels*2),
nn.Conv2d(in_channels*2, out_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
logits = self.bulk_6(x)
return logits
class module(nn.Module):
def __init__(self,in_C, hid1, hid2, out_C):
super(module, self).__init__()
self.bulk1 = Bulk(in_C,hid1)
self.bulk2 = Bulk(hid1, hid2)
self.bulk3 = Bulk(hid2, out_C)
def forward(self, x):
x1 = self.bulk1(x)
x2 = self.bulk2(x1)
y = self.bulk3(x2)
return y
def save_breakpoint(model, lr_schedule):
if (epoch + 1) % 5 == 0:
checkpoint = {
"net": model.state_dict(),
'optimizer': optimizer.state_dict(),
"epoch": epoch,
'lr_schedule': lr_schedule.state_dict()}
path_checkpoint = "./checkpoint.pkl"
torch.save(checkpoint, path_checkpoint)
# 模型实例化
module_1 = module(1, 2, 2, 1)
# 创建输入输出数据
X = np.random.normal(1, 0.5, (32, 32))
Y = X*3+np.random.normal(0, 0.1, (32,32))
x = torch.tensor(X, dtype=torch.float32).unsqueeze(0).unsqueeze(0)
y = torch.tensor(Y, dtype=torch.float32).unsqueeze(0).unsqueeze(0)
loss_fn = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, module_1.parameters()), lr=1e-2)
epochs=2
for epoch in range(epochs):
# 模型冻结
if epoch == 0:
for k, v in module_1.named_parameters():
if any(x in k.split('.') for x in ['0']):
print('unfreezing %s' % k)
v.requires_grad_(True)
else:
for k, v in module_1.named_parameters():
if any(x in k.split('.') for x in ['0']):
print('freezing %s' % k)
v.requires_grad_(False)
# 查看参数
for k, v in module_1.bulk1.bulk_6.named_parameters():
if any(x in k.split('.') for x in ['0']):
print(k,v)
y_pred = module_1(x) # 预测
loss = loss_fn(y_pred, y) # 损失函数
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播计算梯度
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, module_1.parameters()), lr=1e-2)
scheduler = lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.995)
optimizer.step() # 更新参数
scheduler.step() # 一次epoch进行一次scheduler.step(),进行学习率更新
save_breakpoint(module_1, scheduler) # 保存断点
# print('lr={0}, Loss={1}'.format(optimizer.state_dict()['param_groups'][0]['lr'], loss.item()))
for k, v in module_1.bulk1.bulk_6.named_parameters(): # 查看参数
if any(x in k.split('.') for x in ['0']):
print(k,v)
torch.save(module_1.state_dict(),"freezing.pth")
- 梯度正常更新时, 所有层都参与训练,下面是bulk6.0层训练前后的变化:
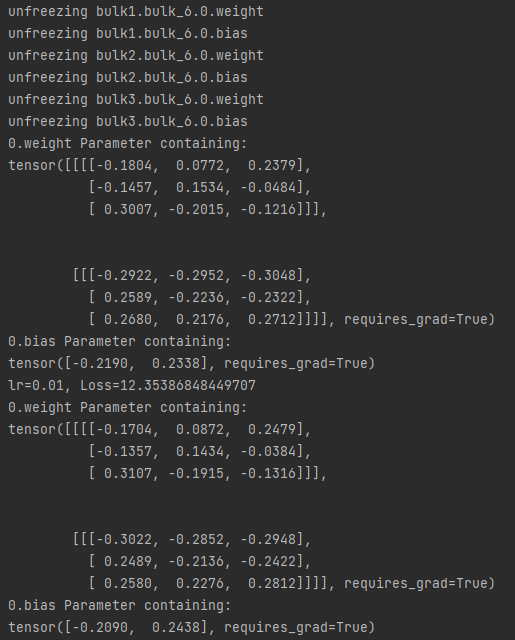
- 梯度停止更新时, bulk6.0层不参与训练,下面是bulk6.0层训练前后的变化:
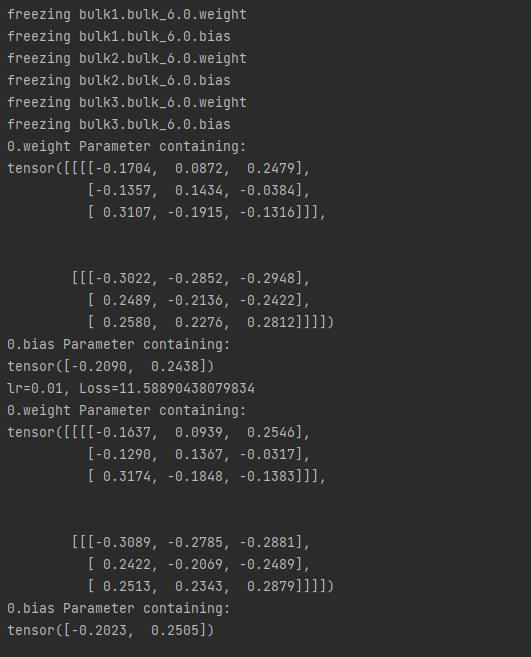
方法二:使用 with torch.no_grad()
该方法的性质:
这种方式只需要在网络定义中的forward方法中,将需要冻结的层放在 with torch.no_grad()下。
放入with torch.no_grad()中的网络层,可以前向传播,但反向传播被阻断,自己这层(如self.layer2)和前面的所有与之相关的层(如self.layer1)的参数都会被冻结,不会被更新。但如果前面的层除了和self.layer2相关外,还与其他层有联系,则与其他层联系的部分正常更新。
还是直接看例子:
# 首先建立一个卷积的神经网络
class Bulk(nn.Module):
def __init__(self,in_channels,out_channels):
super(Bulk, self).__init__()
self.bulk_6 = nn.Sequential(
nn.Conv2d(in_channels,in_channels*2, kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(in_channels*2),
nn.Conv2d(in_channels*2, out_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
logits = self.bulk_6(x)
return logits
class module(nn.Module):
def __init__(self,in_C, hid1, hid2, out_C):
super(module, self).__init__()
self.bulk1 = Bulk(in_C,hid1)
self.bulk2 = Bulk(hid1, hid2)
self.bulk3 = Bulk(hid2, out_C)
def forward(self, x):
with torch.no_grad():
x1 = self.bulk1(x)
x2 = self.bulk2(x1)
y = self.bulk3(x2)
return y
# 模型实例化
module_1 = module(1, 2, 2, 1)
# 创建输入输出数据
X = np.random.normal(1, 0.5, (32, 32))
Y = X*3+np.random.normal(0, 0.1, (32,32))
x = torch.tensor(X, dtype=torch.float32).unsqueeze(0).unsqueeze(0)
y = torch.tensor(Y, dtype=torch.float32).unsqueeze(0).unsqueeze(0)
loss_fn = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, module_1.parameters()), lr=1e-2)
epochs=2
for epoch in range(epochs):
# 查看参数
for k, v in module_1.bulk1.bulk_6.named_parameters():
if any(x in k.split('.') for x in ['0']):
print(k,v)
y_pred = module_1(x) # 预测
loss = loss_fn(y_pred, y) # 损失函数
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播计算梯度
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, module_1.parameters()), lr=1e-2)
scheduler = lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.995)
optimizer.step() # 更新参数
scheduler.step() # 一次epoch进行一次scheduler.step(),进行学习率更新
# print('lr={0}, Loss={1}'.format(optimizer.state_dict()['param_groups'][0]['lr'], loss.item()))
for k, v in module_1.bulk1.bulk_6.named_parameters(): # 查看参数
if any(x in k.split('.') for x in ['0']):
print(k,v)
- 例子中的模型是由三个网络块构成,其中bulk1被with torch.no_grad()屏蔽,不参与参数更新。实验结果如下:bulk1中的网络层在运行了一个epoch后权重没变。
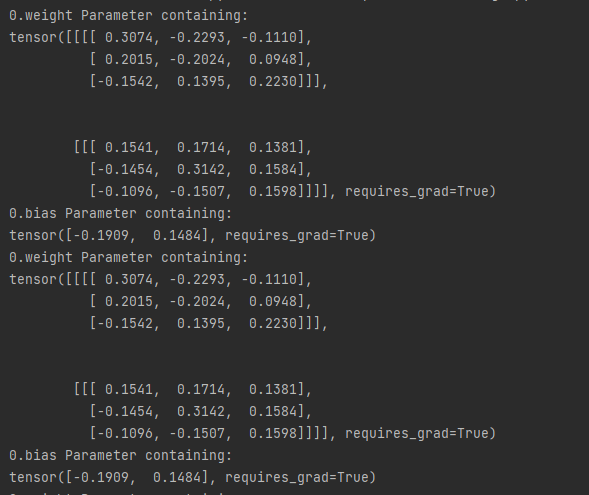
总结
- 方法一:比较灵活,但是写起来麻烦。
- 方法二:不能单独屏蔽某一个epoch,但是使用起来简单便捷,大多数的情况下其实都是够用的。
这里我再推荐一篇文章【pytorch】筛选冻结部分网络层参数同时设置有参数组的时候该怎么办?
5.模型的特殊加载方式和加载技巧
例1:加载预训练模型,并去除需要再次训练的层
注意:需要重新训练的层的名字要和之前的不同。
model=resnet()#自己构建的模型,以resnet为例
model_dict = model.state_dict()
pretrained_dict = torch.load('xxx.pkl')
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
例2:固定部分参数
#k是可训练参数的名字,v是包含可训练参数的一个实体
#可以先print(k),找到自己想进行调整的层,并将该层的名字加入到if语句中:
for k,v in model.named_parameters():
if k!='xxx.weight' and k!='xxx.bias' :
v.requires_grad=False#固定参数
例3:训练部分参数
#将要训练的参数放入优化器
optimizer2=torch.optim.Adam(params=[model.xxx.weight,model.xxx.bias],lr=learning_rate,betas=(0.9,0.999),weight_decay=1e-5)
例4:检查部分参数是否固定
for k,v in model.named_parameters():
if k!='xxx.weight' and k!='xxx.bias' :
print(v.requires_grad)#理想状态下,所有值都是False
需要注意的是,如果操作失误,loss函数几乎不会发生变化,一直处于最开始的状态,这很可能是因为所有参数都被固定了。
6.单GPU训练与多GPU训练
GPU处理大规模的矩阵数据的速度可以比CPU快50-100倍,所以用GPU来跑算法是很有必要的。
Pytorch 使用单GPU训练
使用 GPU 训练只需要在原来的代码中修改几处就可以了。只需要将需要在GPU上运行的模型和数据都搬过去,剩下的就和在CPU上运行的程序是一样的了,我们有两种方式实现代码在 GPU 上进行训练,
方法一 .cuda()
- 我们可以通过对网络模型,数据,损失函数这三种变量调用 .cuda() 来在GPU上进行训练
# 实例化网络模型和损失函数
model = Model()
loss_fn = nn.CrossEntropyLoss()
# 将网络模型和损失函数放在gpu上训练
if torch.cuda.is_available():# 检测是否有可用的GPU
model = model.cuda()
loss_fn = loss_fn.cuda()
# 数据放在gpu上训练
for data in dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
方法二 .to(device)
- 方法和上面差不多,就不过多赘述了,直接上代码。
# 指定训练的设备
device = torch.device("cpu") # 使用cpu训练
device = torch.device("cuda") # 使用gpu训练
device = torch.device("cuda:0") # 当电脑中有多张显卡时,使用第一张显卡
device = torch.device("cuda:1") # 当电脑中有多张显卡时,使用第二张显卡
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 使用 GPU 训练
model = model.to(device)
loss_fn = loss_fn.to(device)
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
单机多卡与多机多卡
这一部分由于设备问题无法实现,就不写了。我推荐一篇我感觉这块儿写的很不错的文章,有需要的小伙伴可以跳过去看看。
《超全Pytorch多GPU训练》:https://blog.csdn.net/Ema1997/article/details/106284407
文章出处登录后可见!