背景
上一篇中,我们使用了 PAI-Blade 优化了 diffusers 中 Stable Diffusion 模型。本篇,我们继续介绍使用 PAI-Blade 优化 LoRA 和 Controlnet 的推理流程。相关优化已经同样在 registry.cn-beijing.aliyuncs.com/blade_demo/blade_diffusion镜像中可以直接使用。同时,我们将介绍 Stable-Diffusion-webui 中集成 PAI-Blade 优化的方法。
LoRA优化
PAI-Blade优化LoRA的方式,与前文方法基本相同。包括:加载模型、优化模型、替换原始模型。以下仅介绍与前文不同的部分。
首先,加载Stable DIffusion模型后,需要加载LoRA权重。
pipe.unet.load_attn_procs(“lora/”)
使用LoRA时,用户可能需要切换不同的LoRA权重,尝试不同的风格。因此,PAI-Blade需要在优化配置中,传入freeze_module=False,使得优化过程中,不对权重进行编译优化,从而不影响模型加载权重的功能。通过这种方式,PAI-Blade优化后的模型,依然可以使用pipe.unet.load_attn_procs()方式加载LoRA的权重,而不需要重新编译优化。
由于模型权重未进行优化流程,一些对常量的优化无法进行,因此会损失部分优化空间。为了解决性能受损的问题,PAI-Blade中,使用了部分patch,对原始模型进行python层级的替换,使得模型更适合PAI-Blade优化。通过在优化前,使用 torch_blade.monkey_patch优化 Stable Diffusion 模型中的 unet和vae部分,能更好的发挥PAI-Blade能力。
from torch_blade.monkey_patch import patch_utils
patch_utils.patch_conv2d(pipe.vae.decoder)
patch_utils.patch_conv2d(pipe.unet)
opt_cfg = torch_blade.Config()
...
opt_cfg.freeze_module = False
with opt_cfg, torch.no_grad():
...如果没有LoRA权重切换的需求,可以忽略上述步骤,获得更快的推理速度。
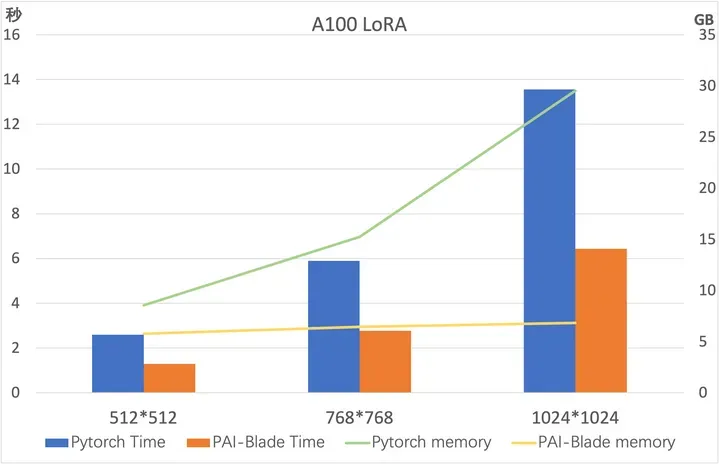
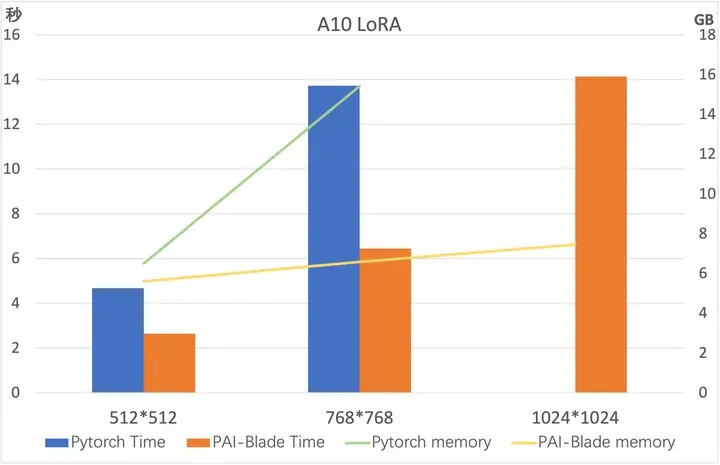
Benchmark
我们在A100/A10上测试了上述对LoRA优化的结果,测试模型为 runwayml/stable-diffusion-v1-5,测试采样步数为50。
ControlNet适配
根据
文章出处登录后可见!