AIGC专栏8——EasyPhoto 视频领域初拓展-让AIGC肖像动起来
- 学习前言
- 源码下载地址
- 技术原理储备
- Video Inference 功能说明 & 效果展示
- 1、Text2Video功能说明
- a、实现原理简介
- b、文到视频UI介绍
- c、结果展示
- 2、Image2Video功能说明
- a、实现原理简介
- i、单图模式
- ii、首尾图模式
- b、图到视频UI
- c、结果展示
- 3、Video2Video功能说明
- a、原理与功能
- b、视频到视频UI
- c、结果展示
- 分支安装
- 1、已安装EasyPhoto
- 2、未安装EasyPhoto
学习前言
图像的AI写真是AI人像的初步应用,如何让图像动起来,形成一段视频,是AI写真领域的重要应用方向拓展。
文生视频,图生视频与视频转视频,是AI写真视频的3个方向。

源码下载地址
WebUI插件版本:https://github.com/aigc-apps/sd-webui-EasyPhoto
Diffusers版本:https://github.com/aigc-apps/EasyPhoto
麻烦各位朋友点个Star,这对我来讲还是很重要的!
技术原理储备
近年来,Stable Diffusion的开源使得更多非专业作画的用户也能通过简单的文字提示生成非常高质量的图片内容(动漫、真人、场景)。但静态图像的表达能力总是有限的,如果能直接文生动画、动图,那么Stable Diffusion的应用领域将大大增长。
随着Lora与Dreambooth的普及,人们定制化模型的能力越来越强,如果可以有一个类似于Controlnet的即用插件,那么模型便有了定制生成动画的能力。
而AnimateDiff则是这样一种可以即插即用的插件,作者提出了一种将任何定制化文生图模型拓展用于动画生成的框架,可以在保持原有定制化模型画面质量的基础上,生成相应的动画片段。
为了避免破坏原始文生图微调模型的生成能力,AnimateDiff在文生图模型中插入了一个动作建模模块,并从视频数据中学习动作先验。因为只是一个模块的插入(类似于Controlnet),加入了先验知识,其实并不改变原有的Stable Diffusion结构,所以AnimateDiff的拓展性非常强!

其实就是在Stable Diffusion的每层后面,新加上一层用于batch批次之间的理解动作信息。

因此,我们选择AnimateDiff作为EasyPhoto视频领域拓展的应用技术,让AIGC肖像成功动起来。
Video Inference 功能说明 & 效果展示
在EasyPhoto完成基于人像Lora训练后,如何使用EasyPhoto完成以下的几种功能:
- Text2Video :使用指定user_id + 描述文本,进行具有指定人脸的视频生成
- Image2Video :使用指定user_id + 模板图片 + 描述, 进行人脸图片的动态视频生成。
- Video2Video :使用指定user_id 完成视频人像编辑。
1、Text2Video功能说明
a、实现原理简介
- 在Text2Video功能中,我们首先自选的SD模型 + AnimateDiff设置的mm_sd_v15_v2.ckpt(Animate运动先验模型;默认选取,无需自己选择),以及用户设定的prompt,生成一段顺滑的带有人脸的视频。
- 在生成的视频上逐帧进行EasyPhoto的前处理,然后对视频使用(EasyPhoto选择的SD模型 + AnimateDiff + User-Lora)进行视频片段上的人脸重绘,用于生成指定ID足够相似的顺滑的人脸。
- 在重绘后的结果上,逐帧进行EasyPhoto的后处理,提升人脸的美观度和全局的和谐程度。
b、文到视频UI介绍
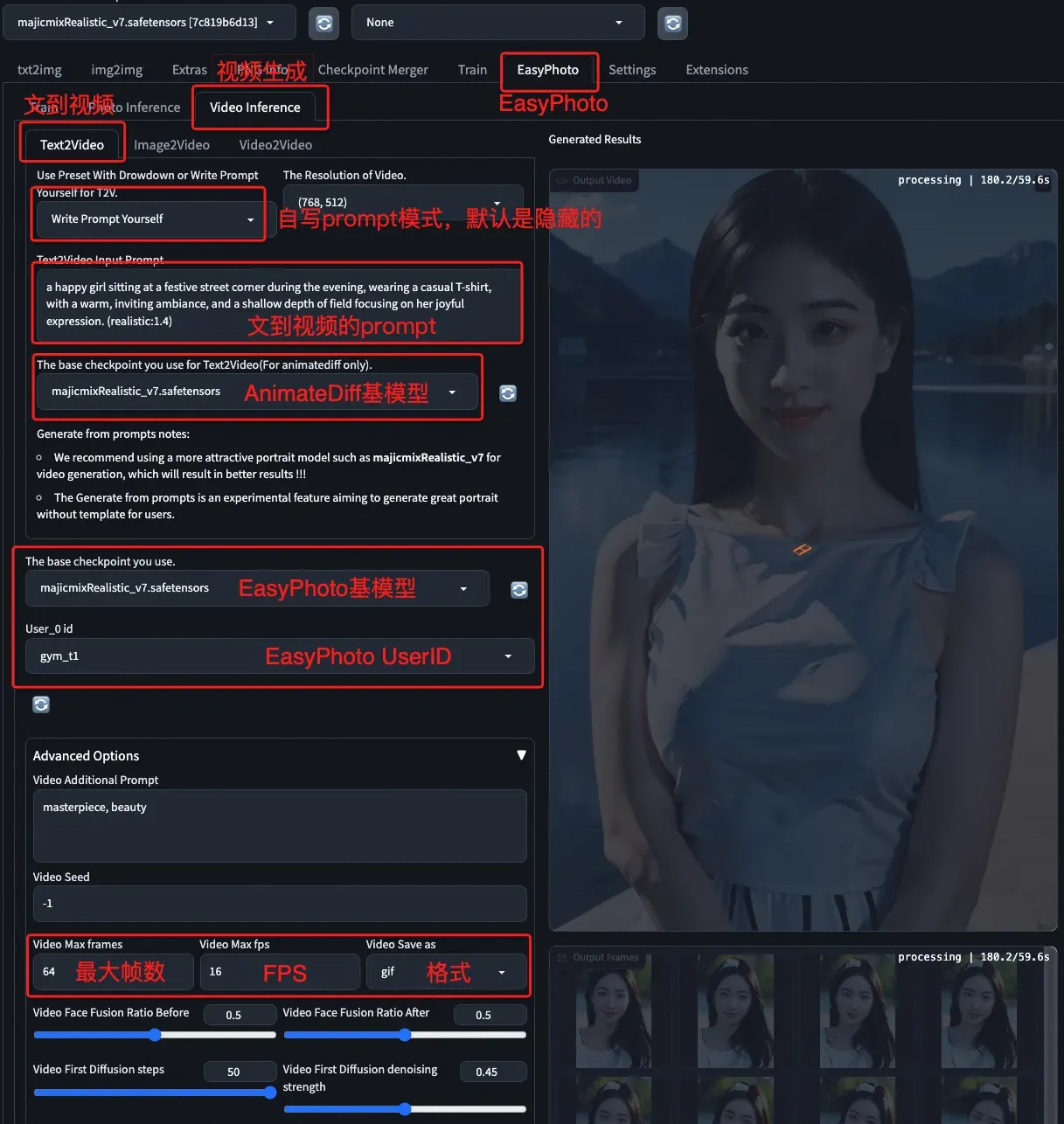
c、结果展示
下面的文到视频采用的参数是:
- Stable Diffusion Model:majicmixRealistic_v7;
- seed=12345;
- max_frame=32;
- fps=8。
图中模特为 师兄亲信。
| GIF | prompt |
|---|---|
 | upper-body, look at viewer, 1girl, wear white dress, besides lake, smiles, Autumn Atmosphere, black eyes, black hair, (cowbody shot, realistic), daytime, f32 |
 | upper-body, look at viewer, 1girl, wear white dress, In the room, luxurious lighting, laser light effects, black eyes, black hair, (cowbody shot, realistic), daytime, f32 |
 | upper-body, look at viewer, 1girl, wear white dress, black eyes, black hair, Sitting by the edge of the grass, warm sunlight, half-body, illuminated,(cowbody shot, realistic), daytime, f32 |
2、Image2Video功能说明
a、实现原理简介
i、单图模式
- 用户会输入一张图作为封面图,该封面图会通过VAE映射到隐空间,与img2img的步骤类似,我们会对隐空间的特征进行一部分加噪。
- 为了让图像 更能动起来 并且 动的更流畅,然后我们会按照一定系数加上一个随机噪声,构成初始化的潜变量。
- 最后结合文本prompt监督,生成Image2Video的视频。
在这里我们使用了两次加噪:
- 如img2img的加噪,这个是为了让图像可以走正常的生图流程,只有在加了噪声后,模型 才有能力发生变化 与 结合prompt 进行生成;
- 按照一定系数加上一个随机噪声,这个 随机噪声 是 符合正态分布 的;这次 加噪声 是为了生成的视频更流畅。
ii、首尾图模式
- 用户会输入两张图作为封面图和尾图,该封面图和尾图会通过VAE映射到隐空间;
- 我们修改了隐向量的初始化,利用首图和尾图的隐向量 插值 构成的 [init_latent, … ,end_latent]作为初始化。从而能生成连贯的从初始图到输出图的变化视频,
b、图到视频UI
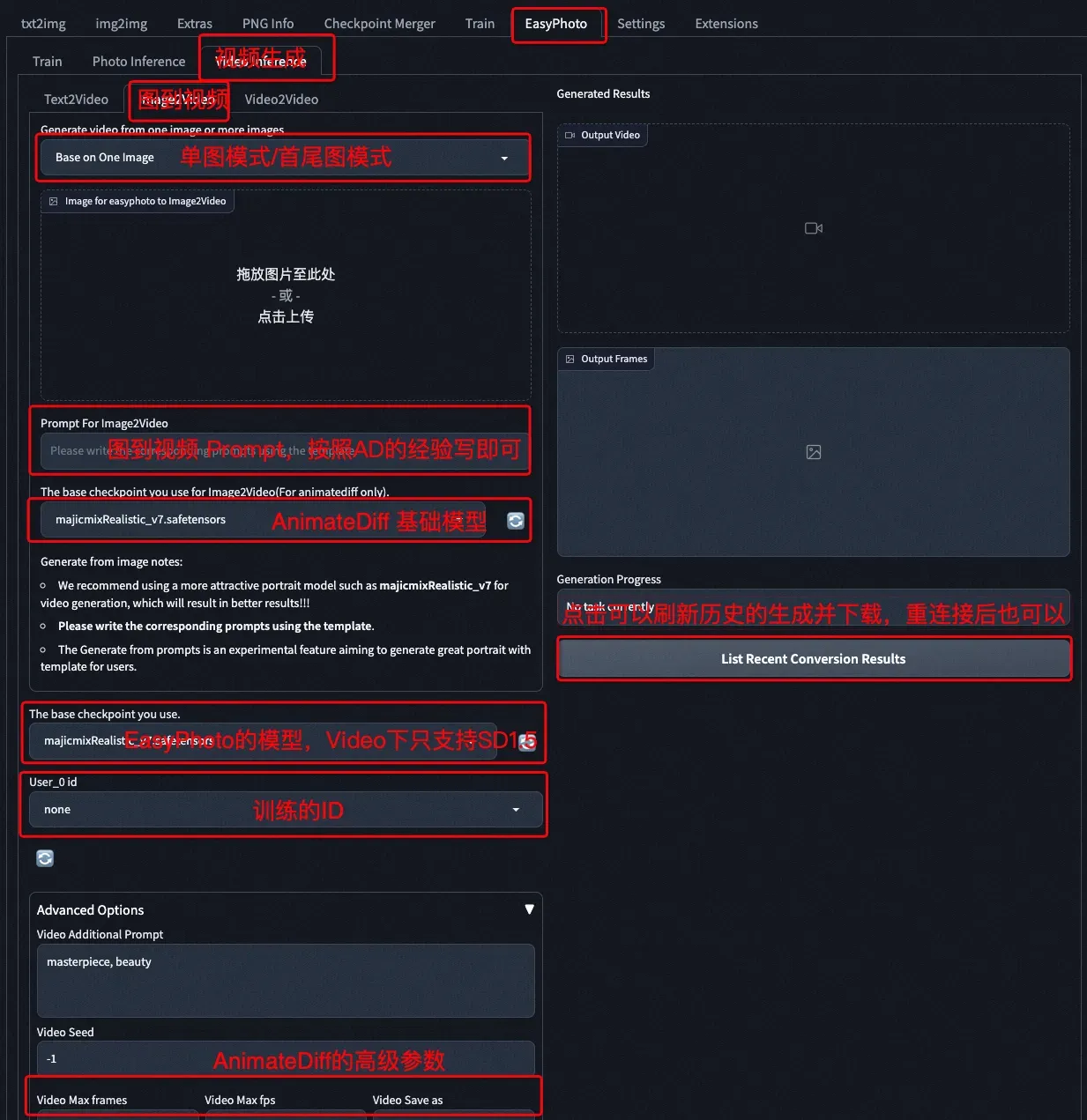
c、结果展示
图中模特为 师兄亲信。
| first | end | GIF | prompt |
|---|---|---|---|
 |  |  | 1girl,elegent,smiles,shininglight |
 |  |  | 1girl,elegent,smiles,from elegent to spotlight, dark to shining |
3、Video2Video功能说明
a、原理与功能
- 在视频上逐帧进行EasyPhoto的前处理,然后对视频使用(EasyPhoto选择的SD模型 + AnimateDiff + User-Lora)进行视频片段上的人脸重绘,用于生成指定ID足够相似的顺滑的人脸。
- 在重绘后的结果上,逐帧进行EasyPhoto的后处理,提升人脸的美观度和全局的和谐程度。
b、视频到视频UI
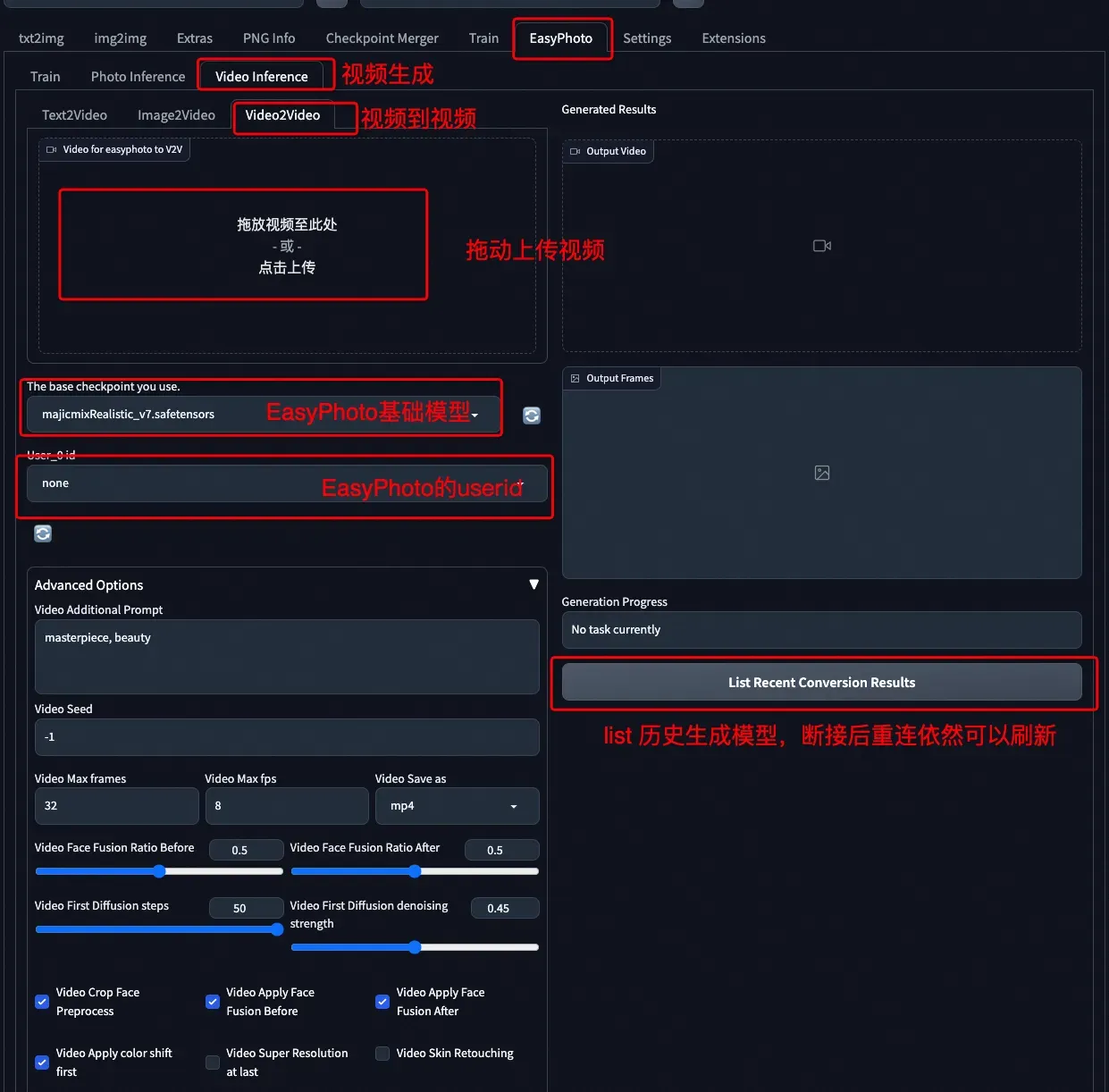
c、结果展示
图中模特为 师兄亲信。
| GIF | src | link |
|---|---|---|
 |  | 原视频链接 |
 |  | 原视频链接 |
分支安装
当前尚未与main合并,需要从分支上进行安装。
1、已安装EasyPhoto
如您已经下载并体验了EasyPhoto插件的人脸版本(main),您可进入EasyPhoto 安装目录进行分支的切换来使用(或者备份原来文件夹,然后走未安装的方案重装):
进入EasyPhoto插件所在目录
git branch -a
git fetch origin
git checkout -b feature/keyframe_video remotes/origin/feature/keyframe_video
2、未安装EasyPhoto
从WebUI 的网址下载安装。

或者手动下载 EasyPhoto feature/keyframe_video 代码文件包放置到相关文件夹。

文章出处登录后可见!