1 绕着Z轴旋转的CUDA动态场景追踪算法
#include <stdio.h>
#include <GL/glut.h>
#include<math.h>
#include<vector>
#define DIM 1024
#define rnd( x ) (x * rand() / RAND_MAX)
#define INF 2e10f
struct Sphere {
float r, b, g;
float radius;
float x, y, z;
__device__ float hit(float ox, float oy, float* n) {
float dx = ox - x;
float dy = oy - y;
if (dx * dx + dy * dy < radius * radius) {
float dz = sqrtf(radius * radius - dx * dx - dy * dy);
*n = dz / sqrtf(radius * radius);
return dz + z;
}
return -INF;
}
};
#define SPHERES 20
__global__ void kernel(Sphere* s, unsigned char* ptr) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float ox = (x - DIM / 2);
float oy = (y - DIM / 2);
float r = 0, g = 0, b = 0;
float maxz = -INF;
for (int i = 0; i < SPHERES; i++) {
float n;
float t = s[i].hit(ox, oy, &n);
if (t > maxz) {
float fscale = n;
r = s[i].r * fscale;
g = s[i].g * fscale;
b = s[i].b * fscale;
maxz = t;
}
}
ptr[offset * 4 + 0] = (int)(r * 255);
ptr[offset * 4 + 1] = (int)(g * 255);
ptr[offset * 4 + 2] = (int)(b * 255);
ptr[offset * 4 + 3] = 255;
}
// globals needed by the update routine
struct DataBlock {
unsigned char* dev_bitmap;
Sphere* s;
};
static int j = 0;
Sphere* temp_s = (Sphere*)malloc(sizeof(Sphere) * SPHERES);
std::vector<Sphere> listspere;
void intisphere()
{
for (int i = 0; i < SPHERES; i++) {
Sphere temp;
temp.r = rnd(1.0f);
temp.g = rnd(1.0f);
temp.b = rnd(1.0f);
temp.x = (rnd(1000.0f) - 500);
temp.y = (rnd(1000.0f) - 500);
temp.z = rnd(1000.0f) - 500;
temp.radius = rnd(100.0f) + 20;
listspere.push_back(temp);
}
}
double averagetime=0;
struct CPUBitmap {
unsigned char* pixels;
int x, y;
void* dataBlock;
void (*bitmapExit)(void*);
CPUBitmap(int width, int height, void* d = NULL) {
pixels = new unsigned char[width * height * 4];
x = width;
y = height;
dataBlock = d;
//intisphere();
//intisphere();
}
~CPUBitmap() {
delete[] pixels;
}
unsigned char* get_ptr(void) const { return pixels; }
long image_size(void) const { return x * y * 4; }
void display_and_exit(void(*e)(void*) = NULL) {
CPUBitmap** bitmap = get_bitmap_ptr();
*bitmap = this;
bitmapExit = e;
// a bug in the Windows GLUT implementation prevents us from
// passing zero arguments to glutInit()
int c = 1;
char* dummy = "";
glutInit(&c, &dummy);
glutInitDisplayMode(GLUT_SINGLE | GLUT_RGBA);
glutInitWindowSize(x, y);
glutCreateWindow("bitmap");
glutIdleFunc(Draw);
glutDisplayFunc(Draw);
glutMainLoop();
}
// static method used for glut callbacks
static CPUBitmap** get_bitmap_ptr(void) {
static CPUBitmap* gBitmap;
return &gBitmap;
}
// static method used for glut callbacks
// static method used for glut callbacks
static void Draw(void) {
//CPUBitmap* bitmap = *(get_bitmap_ptr());
//Sleep(100);
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
unsigned char* dev_bitmap;
j++;
double changetheta = j /(2 * 3.1415 / 360);
// allocate memory on the GPU for the output bitmap
cudaMalloc((void**)&dev_bitmap,
(*(get_bitmap_ptr()))->image_size());
Sphere* s;
cudaMalloc((void**)&s,
sizeof(Sphere) * SPHERES);
double t = glutGet(GLUT_ELAPSED_TIME) * 0.0002; // 获取时间,单位为秒
// allocate temp memory, initialize it, copy to constant
// memory on the GPU, then free our temp memory
Sphere* temp_s = (Sphere*)malloc(sizeof(Sphere) * SPHERES);
std::vector<Sphere>::iterator itbegin = listspere.begin();
std::vector<Sphere>::iterator itend = listspere.end();
int i = 0;
while (itbegin != itend)
{
temp_s[i].r = (*itbegin).r;
temp_s[i].g = (*itbegin).g;
temp_s[i].b = (*itbegin).b;
temp_s[i].x = (*itbegin).x;
temp_s[i].y = (*itbegin).y ;
temp_s[i].z = (*itbegin).z;
temp_s[i].radius = (*itbegin).radius;
double originaltheta = atan(temp_s[i].y / temp_s[i].x);
double nowtheta = originaltheta - changetheta;
double radius = sqrt(temp_s[i].x * temp_s[i].x + temp_s[i].y * temp_s[i].y);
temp_s[i].x = radius *(cos(nowtheta));
temp_s[i].y= radius *(sin(nowtheta));
/* temp_s[i].x = temp_s[i].x*cos(changetheta);
temp_s[i].y = temp_s[i].y*sin(changetheta);*/
itbegin++;
i++;
}
cudaMemcpy(s, temp_s,
sizeof(Sphere) * SPHERES,
cudaMemcpyHostToDevice);
free(temp_s);
// generate a bitmap from our sphere data
dim3 grids(DIM / 16, DIM / 16);
dim3 threads(16, 16);
kernel << <grids, threads >> > (s, dev_bitmap);
// copy our bitmap back from the GPU for display
cudaMemcpy((*(get_bitmap_ptr()))->get_ptr(), dev_bitmap,
(*(get_bitmap_ptr()))->image_size(),
cudaMemcpyDeviceToHost);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime,
start, stop);
averagetime = averagetime + elapsedTime;
if (j == 1)
{
printf("Time to generate: %3.1f ms\n", averagetime);
}
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaFree(dev_bitmap);
cudaFree(s);
glClearColor(0.0, 0.0, 0.0, 1.0);
glClear(GL_COLOR_BUFFER_BIT);
glDrawPixels((*(get_bitmap_ptr()))->x, (*(get_bitmap_ptr()))->y, GL_RGBA, GL_UNSIGNED_BYTE, (*(get_bitmap_ptr()))->pixels);
glFlush();
glutSwapBuffers();
}
};
int main(void) {
intisphere();
DataBlock data;
CPUBitmap bitmap(DIM, DIM, &data);
// display
bitmap.display_and_exit();
}
角度1:

角度2:

角度3:

可以发现整个物体呈顺时针旋转,启动程序后不停运转;
其时间为: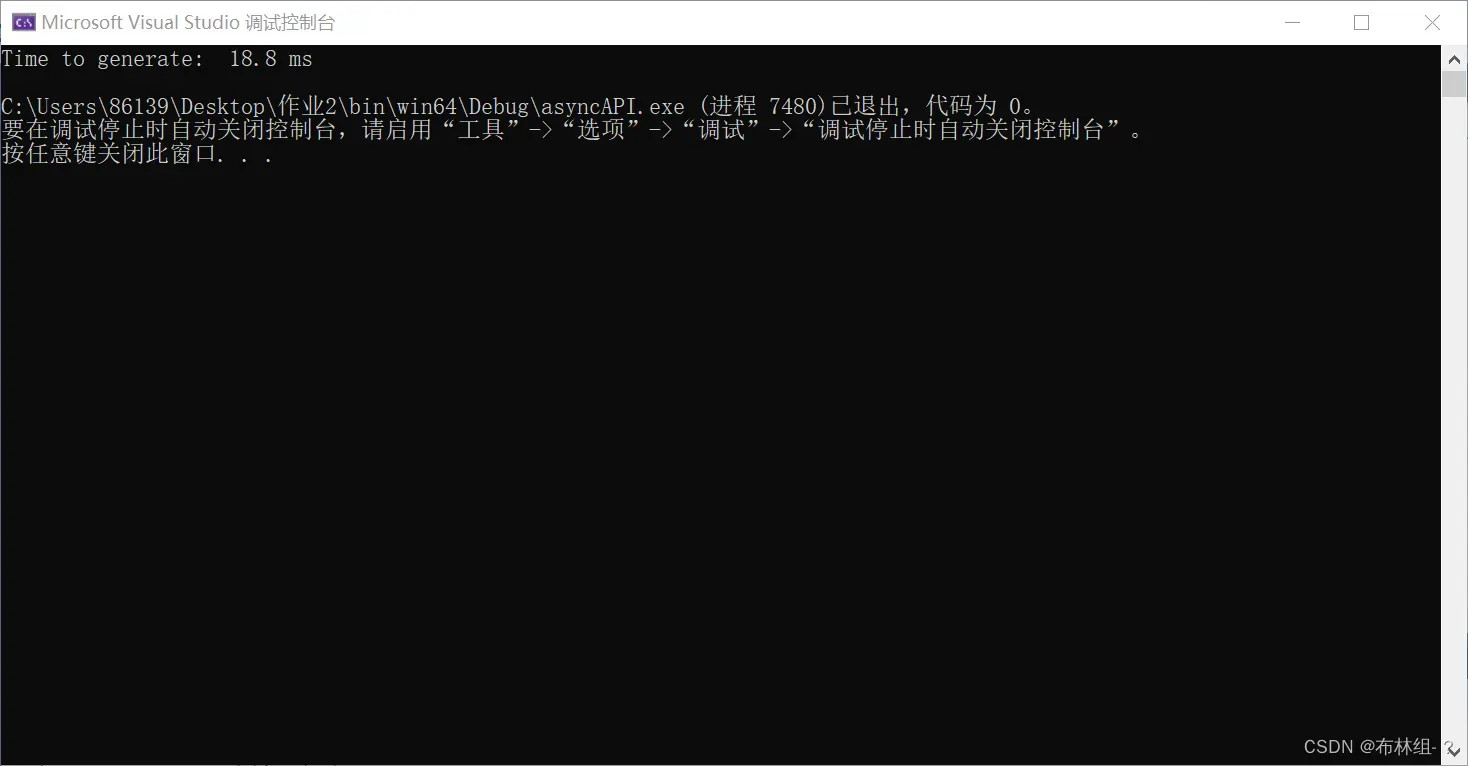
2 使用常量内存进行优化(也是可运动的)
// includes CUDA Runtime
//#include <cuda_runtime.h>
//
includes, project
//#include <helper_cuda.h>
//#include <helper_functions.h> // helper utility functions
#include <stdio.h>
#include <GL/glut.h>
#include<math.h>
#include<vector>
//#include <helper_cuda.h>
#define DIM 1024
#define rnd( x ) (x * rand() / RAND_MAX)
#define INF 2e10f
struct Sphere {
float r, b, g;
float radius;
float x, y, z;
__device__ float hit(float ox, float oy, float* n) {
float dx = ox - x;
float dy = oy - y;
if (dx * dx + dy * dy < radius * radius) {
float dz = sqrtf(radius * radius - dx * dx - dy * dy);
*n = dz / sqrtf(radius * radius);
return dz + z;
}
return -INF;
}
};
#define SPHERES 20
__constant__ Sphere s[SPHERES];
__global__ void kernel(unsigned char* ptr) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float ox = (x - DIM / 2);
float oy = (y - DIM / 2);
float r = 0, g = 0, b = 0;
float maxz = -INF;
for (int i = 0; i < SPHERES; i++) {
float n;
float t = s[i].hit(ox, oy, &n);
if (t > maxz) {
float fscale = n;
r = s[i].r * fscale;
g = s[i].g * fscale;
b = s[i].b * fscale;
maxz = t;
}
}
ptr[offset * 4 + 0] = (int)(r * 255);
ptr[offset * 4 + 1] = (int)(g * 255);
ptr[offset * 4 + 2] = (int)(b * 255);
ptr[offset * 4 + 3] = 255;
}
// globals needed by the update routine
struct DataBlock {
unsigned char* dev_bitmap;
Sphere* s;
};
static int j = 0;
Sphere* temp_s = (Sphere*)malloc(sizeof(Sphere) * SPHERES);
std::vector<Sphere> listspere;
void intisphere()
{
for (int i = 0; i < SPHERES; i++) {
Sphere temp;
temp.r = rnd(1.0f);
temp.g = rnd(1.0f);
temp.b = rnd(1.0f);
temp.x = (rnd(1000.0f) - 500);
temp.y = (rnd(1000.0f) - 500);
temp.z = rnd(1000.0f) - 500;
temp.radius = rnd(100.0f) + 20;
listspere.push_back(temp);
}
}
float averagetime=0;
struct CPUBitmap {
unsigned char* pixels;
int x, y;
void* dataBlock;
void (*bitmapExit)(void*);
CPUBitmap(int width, int height, void* d = NULL) {
pixels = new unsigned char[width * height * 4];
x = width;
y = height;
dataBlock = d;
//intisphere();
//intisphere();
}
~CPUBitmap() {
delete[] pixels;
}
unsigned char* get_ptr(void) const { return pixels; }
long image_size(void) const { return x * y * 4; }
void display_and_exit(void(*e)(void*) = NULL) {
CPUBitmap** bitmap = get_bitmap_ptr();
*bitmap = this;
bitmapExit = e;
// a bug in the Windows GLUT implementation prevents us from
// passing zero arguments to glutInit()
int c = 1;
char* dummy = "";
glutInit(&c, &dummy);
glutInitDisplayMode(GLUT_SINGLE | GLUT_RGBA);
glutInitWindowSize(x, y);
glutCreateWindow("bitmap");
glutIdleFunc(Draw);
glutDisplayFunc(Draw);
glutMainLoop();
}
// static method used for glut callbacks
static CPUBitmap** get_bitmap_ptr(void) {
static CPUBitmap* gBitmap;
return &gBitmap;
}
// static method used for glut callbacks
// static method used for glut callbacks
static void Draw(void) {
//CPUBitmap* bitmap = *(get_bitmap_ptr());
// capture the start time
unsigned char* dev_bitmap;
j++;
/* if (i > 360)
{
i = 360;
}*/
double changetheta = j / (2 * 3.1415 / 360);
// allocate memory on the GPU for the output bitmap
cudaMalloc((void**)&dev_bitmap,
(*(get_bitmap_ptr()))->image_size());
/* Sphere* s;
cudaMalloc((void**)&s,
sizeof(Sphere) * SPHERES);*/
double t = glutGet(GLUT_ELAPSED_TIME) * 0.0002; // 获取时间,单位为秒
// allocate temp memory, initialize it, copy to constant
// memory on the GPU, then free our temp memory
Sphere* temp_s = (Sphere*)malloc(sizeof(Sphere) * SPHERES);
std::vector<Sphere>::iterator itbegin = listspere.begin();
std::vector<Sphere>::iterator itend = listspere.end();
int i = 0;
while (itbegin != itend)
{
temp_s[i].r = (*itbegin).r;
temp_s[i].g = (*itbegin).g;
temp_s[i].b = (*itbegin).b;
temp_s[i].x = (*itbegin).x;
temp_s[i].y = (*itbegin).y;
temp_s[i].z = (*itbegin).z;
temp_s[i].radius = (*itbegin).radius;
double originaltheta = atan(temp_s[i].y / temp_s[i].x);
double nowtheta = originaltheta - changetheta;
double radius = sqrt(temp_s[i].x * temp_s[i].x + temp_s[i].y * temp_s[i].y);
temp_s[i].x = radius * (cos(nowtheta));
temp_s[i].y = radius * (sin(nowtheta));
/* temp_s[i].x = temp_s[i].x*cos(changetheta);
temp_s[i].y = temp_s[i].y*sin(changetheta);*/
itbegin++;
i++;
}
cudaMemcpyToSymbol(s, temp_s, sizeof(Sphere) * SPHERES);
free(temp_s);
// generate a bitmap from our sphere data
dim3 grids(DIM / 16, DIM / 16);
dim3 threads(16, 16);
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
kernel << <grids, threads >> > (dev_bitmap);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime,
start, stop);
averagetime = averagetime + elapsedTime;
if (j == 1)
{
printf("Time to generate: %3.1f ms\n", averagetime );
}
// copy our bitmap back from the GPU for display
cudaMemcpy((*(get_bitmap_ptr()))->get_ptr(), dev_bitmap,
(*(get_bitmap_ptr()))->image_size(),
cudaMemcpyDeviceToHost);
// get stop time, and display the timing results
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaFree(dev_bitmap);
glClearColor(0.0, 0.0, 0.0, 1.0);
glClear(GL_COLOR_BUFFER_BIT);
glDrawPixels((*(get_bitmap_ptr()))->x, (*(get_bitmap_ptr()))->y, GL_RGBA, GL_UNSIGNED_BYTE, (*(get_bitmap_ptr()))->pixels);
glFlush();
glutSwapBuffers();
}
};
int main(void) {
intisphere();
DataBlock data;
CPUBitmap bitmap(DIM, DIM, &data);
// display
bitmap.display_and_exit();
}
时间变为18.5ms
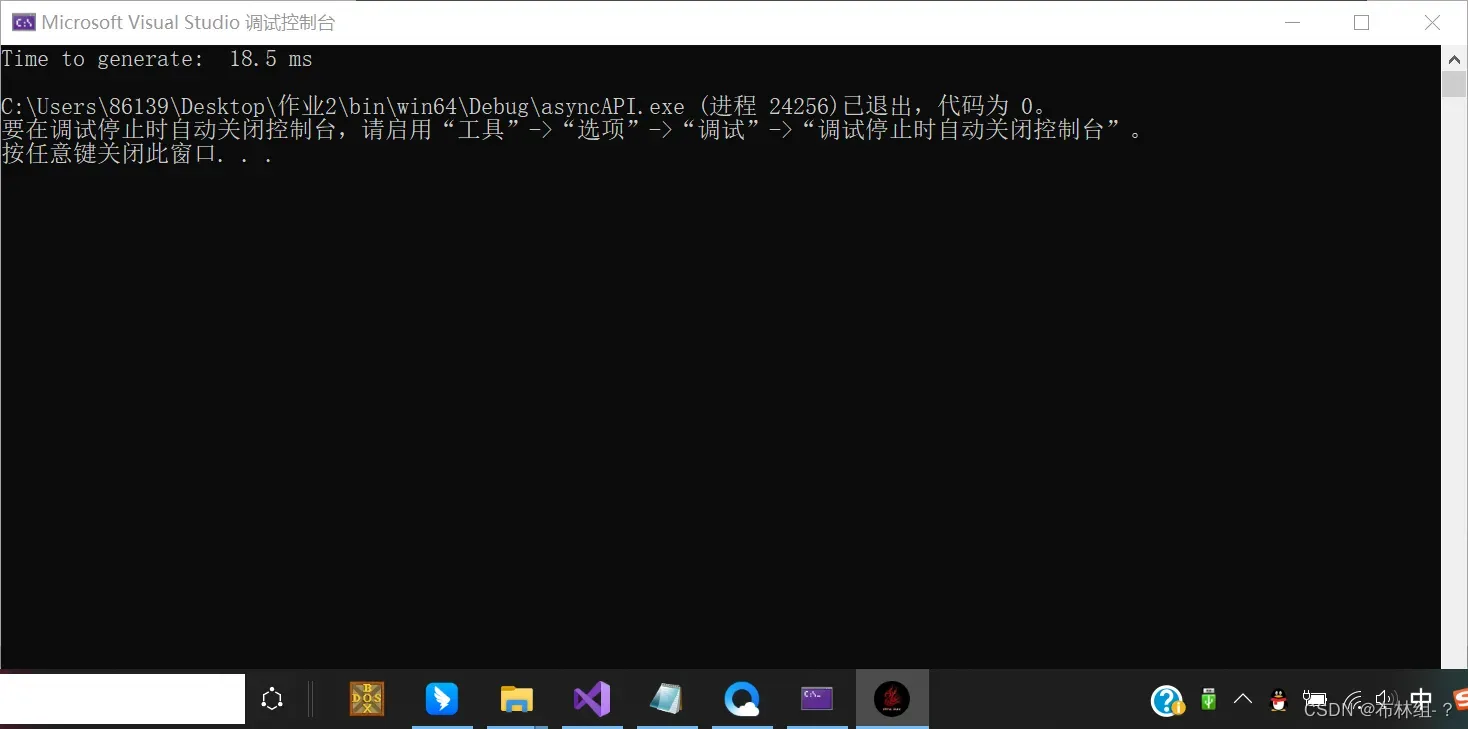
3 考虑核函数的优化方式(二维变三维,thread线程数达到最大1024)
// generate a bitmap from our sphere data
dim3 grids(DIM/64, DIM /64,4);
dim3 threads(32, 32,1);
kernel << <grids, threads >> > (s, dev_bitmap);
//变为三维
//在kernel函数中进行三维转二维映射
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
int k = blockIdx.z * blockDim.z + threadIdx.z;
int offset = i + j * blockDim.x * gridDim.x + k * blockDim.x * gridDim.x * blockDim.y * gridDim.y;
int x = offset%(DIM);
int y =offset/(DIM);完整代码如下:
#include <stdio.h>
#include <GL/glut.h>
#include<math.h>
#include<vector>
// includes CUDA Runtime
#include <cuda_runtime.h>
// includes, project
#include <helper_cuda.h>
#include <helper_functions.h> // helper utility functions
#define DIM 1024
#define rnd( x ) (x * rand() / RAND_MAX)
#define INF 2e10f
struct Sphere {
float r, b, g;
float radius;
float x, y, z;
__device__ float hit(float ox, float oy, float* n) {
float dx = ox - x;
float dy = oy - y;
if (dx * dx + dy * dy < radius * radius) {
float dz = sqrtf(radius * radius - dx * dx - dy * dy);
*n = dz / sqrtf(radius * radius);
return dz + z;
}
return -INF;
}
};
#define SPHERES 20
__global__ void kernel(Sphere* s, unsigned char* ptr) {
// map from threadIdx/BlockIdx to pixel position
/* int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;*/
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
int k = blockIdx.z * blockDim.z + threadIdx.z;
int offset = i + j * blockDim.x * gridDim.x + k * blockDim.x * gridDim.x * blockDim.y * gridDim.y;
int x = offset%(DIM);
int y =offset/(DIM);
//printf("x %d, y %d\n",i, j);
float ox = (x - DIM / 2);
float oy = (y - DIM / 2);
float r = 0, g = 0, b = 0;
float maxz = -INF;
for (int i = 0; i < SPHERES; i++) {
float n;
float t = s[i].hit(ox, oy, &n);
if (t > maxz) {
float fscale = n;
r = s[i].r * fscale;
g = s[i].g * fscale;
b = s[i].b * fscale;
maxz = t;
}
}
ptr[offset * 4 + 0] = (int)(r * 255);
ptr[offset * 4 + 1] = (int)(g * 255);
ptr[offset * 4 + 2] = (int)(b * 255);
ptr[offset * 4 + 3] = 255;
}
// globals needed by the update routine
struct DataBlock {
unsigned char* dev_bitmap;
Sphere* s;
};
static int j = 0;
Sphere* temp_s = (Sphere*)malloc(sizeof(Sphere) * SPHERES);
std::vector<Sphere> listspere;
void intisphere()
{
for (int i = 0; i < SPHERES; i++) {
Sphere temp;
temp.r = rnd(1.0f);
temp.g = rnd(1.0f);
temp.b = rnd(1.0f);
temp.x = (rnd(1000.0f) - 500);
temp.y = (rnd(1000.0f) - 500);
temp.z = rnd(1000.0f) - 500;
temp.radius = rnd(100.0f) + 20;
listspere.push_back(temp);
}
}
double averagetime=0;
struct CPUBitmap {
unsigned char* pixels;
int x, y;
void* dataBlock;
void (*bitmapExit)(void*);
CPUBitmap(int width, int height, void* d = NULL) {
pixels = new unsigned char[width * height * 4];
x = width;
y = height;
dataBlock = d;
//intisphere();
//intisphere();
}
~CPUBitmap() {
delete[] pixels;
}
unsigned char* get_ptr(void) const { return pixels; }
long image_size(void) const { return x * y * 4; }
void display_and_exit(void(*e)(void*) = NULL) {
CPUBitmap** bitmap = get_bitmap_ptr();
*bitmap = this;
bitmapExit = e;
// a bug in the Windows GLUT implementation prevents us from
// passing zero arguments to glutInit()
int c = 1;
char* dummy = "";
glutInit(&c, &dummy);
glutInitDisplayMode(GLUT_SINGLE | GLUT_RGBA);
glutInitWindowSize(x, y);
glutCreateWindow("bitmap");
glutIdleFunc(Draw);
glutDisplayFunc(Draw);
glutMainLoop();
}
// static method used for glut callbacks
static CPUBitmap** get_bitmap_ptr(void) {
static CPUBitmap* gBitmap;
return &gBitmap;
}
// static method used for glut callbacks
// static method used for glut callbacks
static void Draw(void) {
//CPUBitmap* bitmap = *(get_bitmap_ptr());
//Sleep(100);
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
unsigned char* dev_bitmap;
j++;
double changetheta = j /(2 * 3.1415 / 360);
// allocate memory on the GPU for the output bitmap
cudaMalloc((void**)&dev_bitmap,
(*(get_bitmap_ptr()))->image_size());
Sphere* s;
cudaMalloc((void**)&s,
sizeof(Sphere) * SPHERES);
double t = glutGet(GLUT_ELAPSED_TIME) * 0.0002; // 获取时间,单位为秒
// allocate temp memory, initialize it, copy to constant
// memory on the GPU, then free our temp memory
Sphere* temp_s = (Sphere*)malloc(sizeof(Sphere) * SPHERES);
std::vector<Sphere>::iterator itbegin = listspere.begin();
std::vector<Sphere>::iterator itend = listspere.end();
int i = 0;
while (itbegin != itend)
{
temp_s[i].r = (*itbegin).r;
temp_s[i].g = (*itbegin).g;
temp_s[i].b = (*itbegin).b;
temp_s[i].x = (*itbegin).x;
temp_s[i].y = (*itbegin).y ;
temp_s[i].z = (*itbegin).z;
temp_s[i].radius = (*itbegin).radius;
double originaltheta = atan(temp_s[i].y / temp_s[i].x);
double nowtheta = originaltheta - changetheta;
double radius = sqrt(temp_s[i].x * temp_s[i].x + temp_s[i].y * temp_s[i].y);
temp_s[i].x = radius *(cos(nowtheta));
temp_s[i].y= radius *(sin(nowtheta));
/* temp_s[i].x = temp_s[i].x*cos(changetheta);
temp_s[i].y = temp_s[i].y*sin(changetheta);*/
itbegin++;
i++;
}
cudaMemcpy(s, temp_s,
sizeof(Sphere) * SPHERES,
cudaMemcpyHostToDevice);
free(temp_s);
// generate a bitmap from our sphere data
dim3 grids(DIM/64, DIM /64,4);
dim3 threads(32, 32,1);
kernel << <grids, threads >> > (s, dev_bitmap);
// copy our bitmap back from the GPU for display
cudaMemcpy((*(get_bitmap_ptr()))->get_ptr(), dev_bitmap,
(*(get_bitmap_ptr()))->image_size(),
cudaMemcpyDeviceToHost);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime,
start, stop);
averagetime = averagetime + elapsedTime;
if (j == 1)
{
printf("Time to generate: %3.1f ms\n", averagetime);
}
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaFree(dev_bitmap);
cudaFree(s);
glClearColor(0.0, 0.0, 0.0, 1.0);
glClear(GL_COLOR_BUFFER_BIT);
glDrawPixels((*(get_bitmap_ptr()))->x, (*(get_bitmap_ptr()))->y, GL_RGBA, GL_UNSIGNED_BYTE, (*(get_bitmap_ptr()))->pixels);
glFlush();
glutSwapBuffers();
}
};
int main(void) {
intisphere();
DataBlock data;
CPUBitmap bitmap(DIM, DIM, &data);
// display
bitmap.display_and_exit();
}
当核函数修改如下时,可以得到较好地结果:
dim3 grids(DIM/32, DIM /32,1);
dim3 threads(32, 32,1);
kernel << <grids, threads >> > (s, dev_bitmap);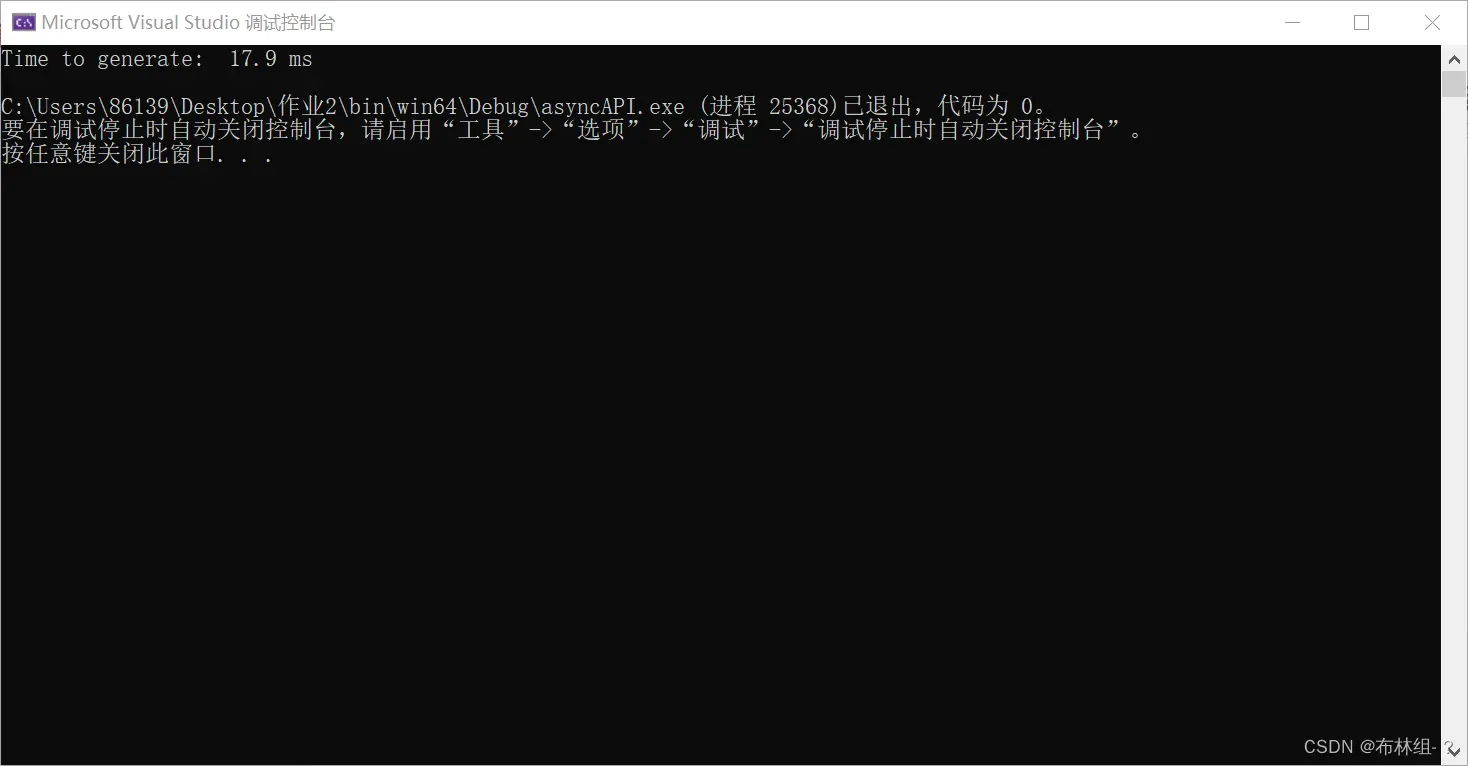
文章出处登录后可见!
已经登录?立即刷新