目前扎克布格带来了最新的Llama 2开源NLP大模型,目前有三个版本分别是70亿参数量,130亿参数量和700亿参数量,庞大的数据集和参数量保证了模型的强大,官网宣称性能与gpt4相比不落下风,又因为开源使得我们可以实现本地化gpt4的梦想并且免费!我们可以通过微调让其掌握我们更想让其清楚的知识。但是由于其参数量的庞大,可能很多的小伙伴的硬件无法顺利便捷的运行Llama 2,在这里我分享一个方法可以实现一键部署,并且对配置没有任何要求!这里我们采用的是Google Colab,具体步骤如下:
首先,点击Google Colab打开链接,点击左上角文件按钮,位置如下图所示:
之后点击,新建笔记本,位置如下图所示:
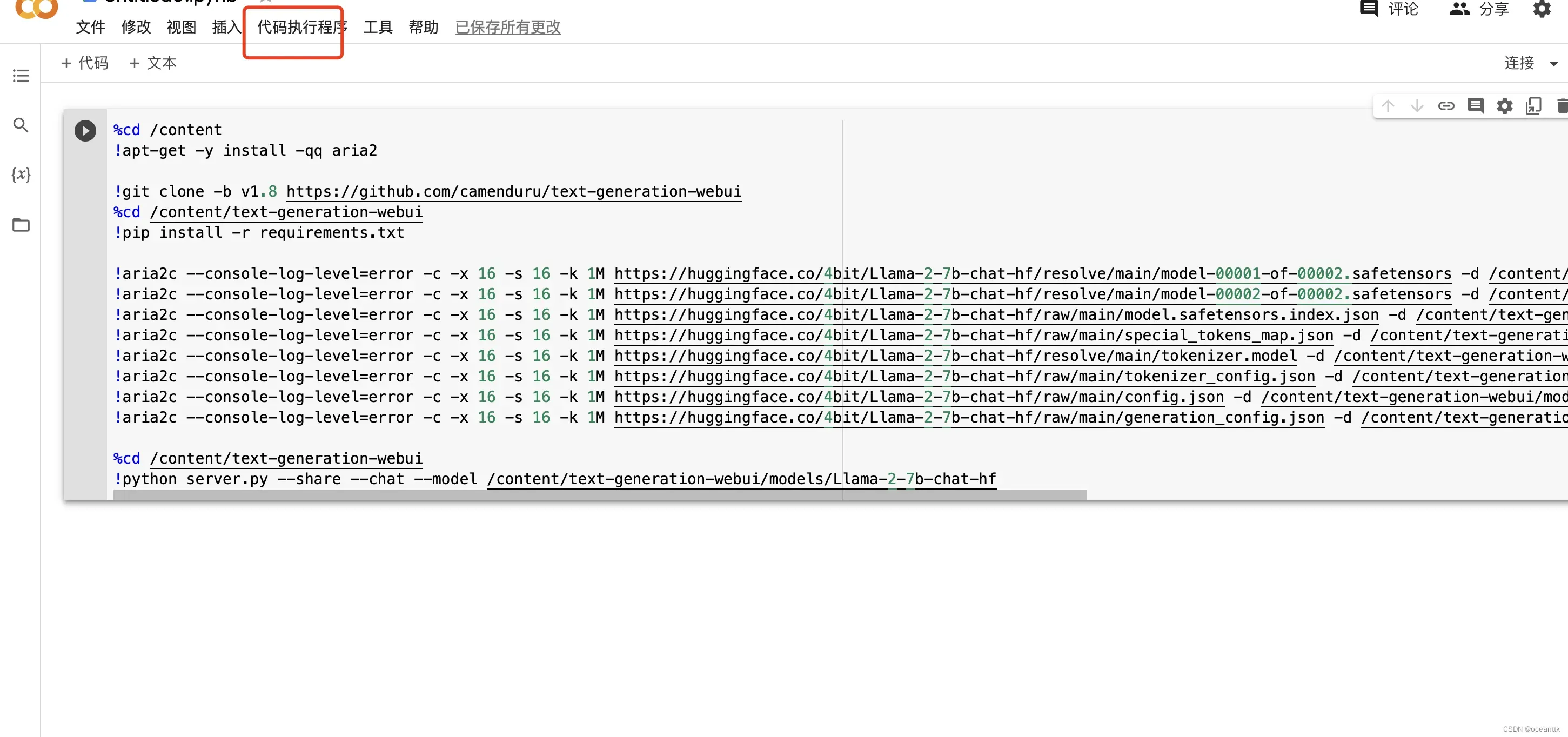
可能会经过一段时间的等待,打开后将下面的代码直接复制到笔记本中
%cd /content
!apt-get -y install -qq aria2
!git clone -b v1.8 https://github.com/camenduru/text-generation-webui
%cd /content/text-generation-webui
!pip install -r requirements.txt
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-chat-hf/resolve/main/model-00001-of-00002.safetensors -d /content/text-generation-webui/models/Llama-2-7b-chat-hf -o model-00001-of-00002.safetensors
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-chat-hf/resolve/main/model-00002-of-00002.safetensors -d /content/text-generation-webui/models/Llama-2-7b-chat-hf -o model-00002-of-00002.safetensors
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-chat-hf/raw/main/model.safetensors.index.json -d /content/text-generation-webui/models/Llama-2-7b-chat-hf -o model.safetensors.index.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-chat-hf/raw/main/special_tokens_map.json -d /content/text-generation-webui/models/Llama-2-7b-chat-hf -o special_tokens_map.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-chat-hf/resolve/main/tokenizer.model -d /content/text-generation-webui/models/Llama-2-7b-chat-hf -o tokenizer.model
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-chat-hf/raw/main/tokenizer_config.json -d /content/text-generation-webui/models/Llama-2-7b-chat-hf -o tokenizer_config.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-chat-hf/raw/main/config.json -d /content/text-generation-webui/models/Llama-2-7b-chat-hf -o config.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-chat-hf/raw/main/generation_config.json -d /content/text-generation-webui/models/Llama-2-7b-chat-hf -o generation_config.json
%cd /content/text-generation-webui
!python server.py --share --chat --model /content/text-generation-webui/models/Llama-2-7b-chat-hf现在距离运行只差一点了!接下来点击 代码执行程序,更改运行类型,改成T4 GPU,之后点击报错,如下图所示:
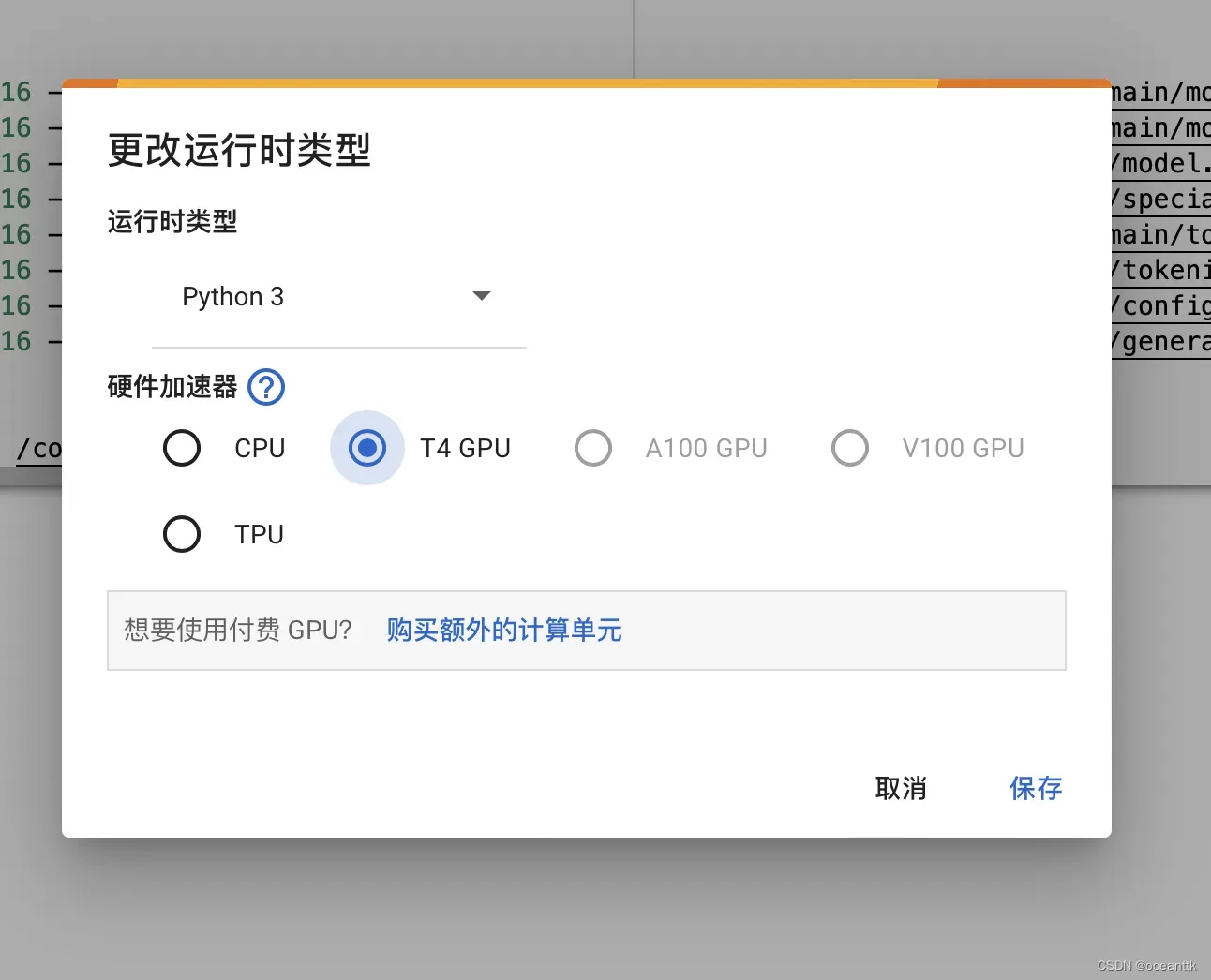
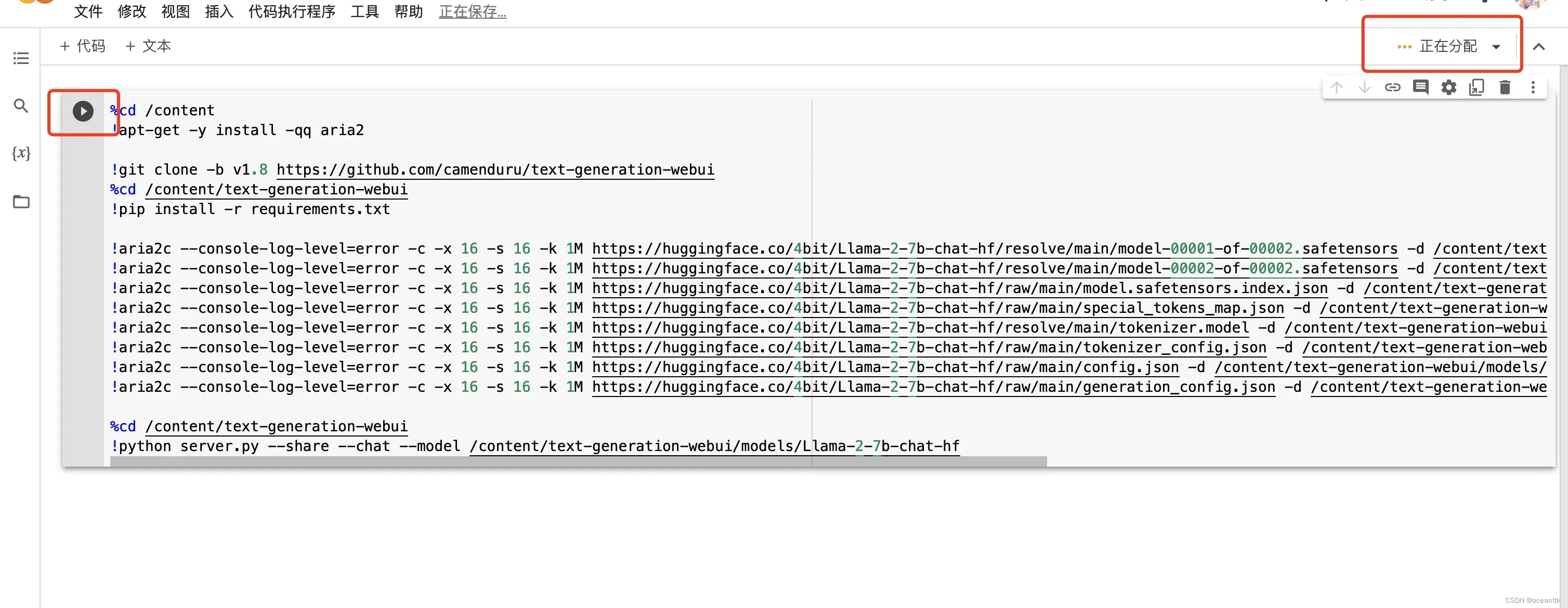
接下来连接上GPU,点击运行就可以了!
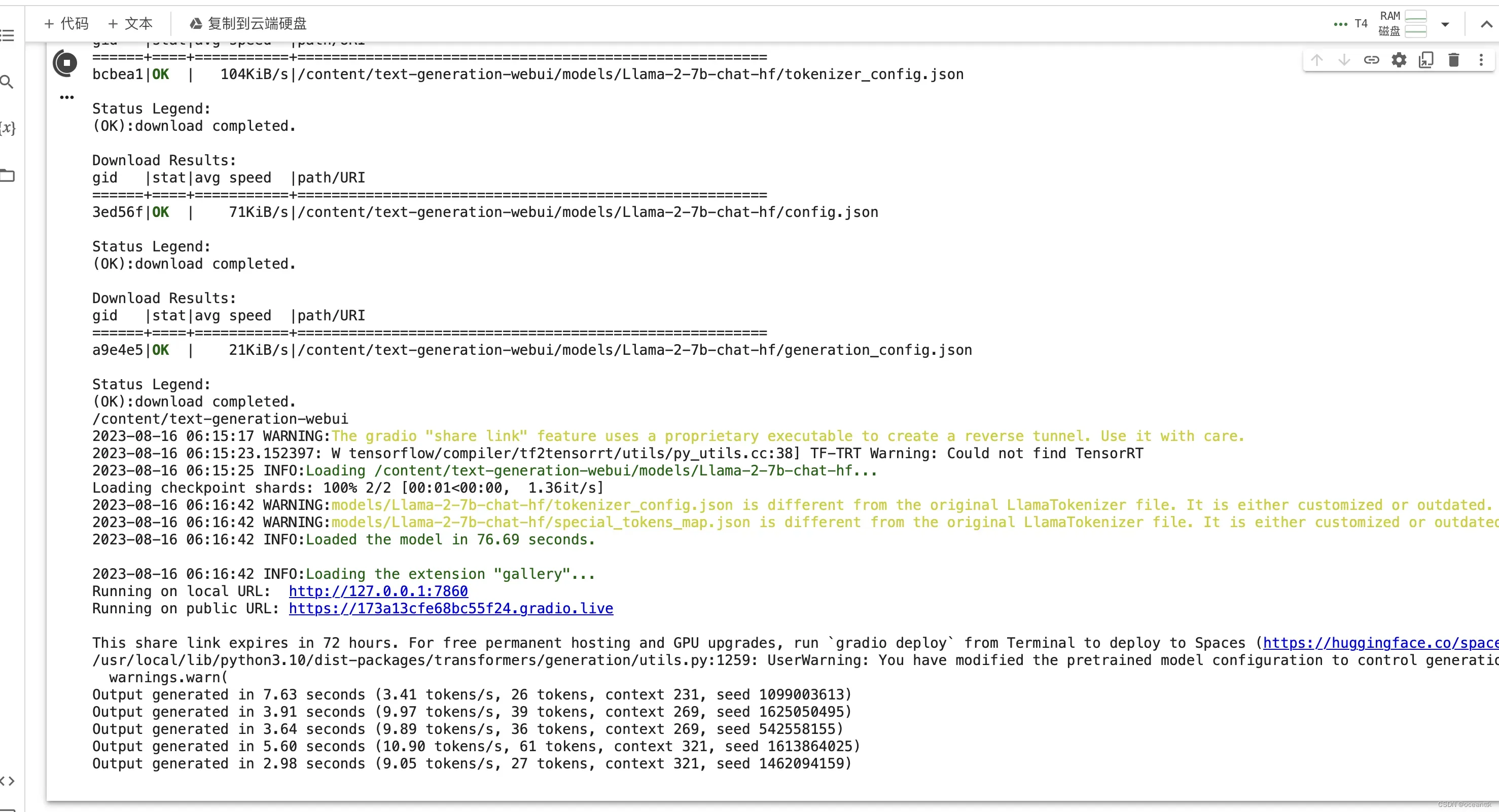
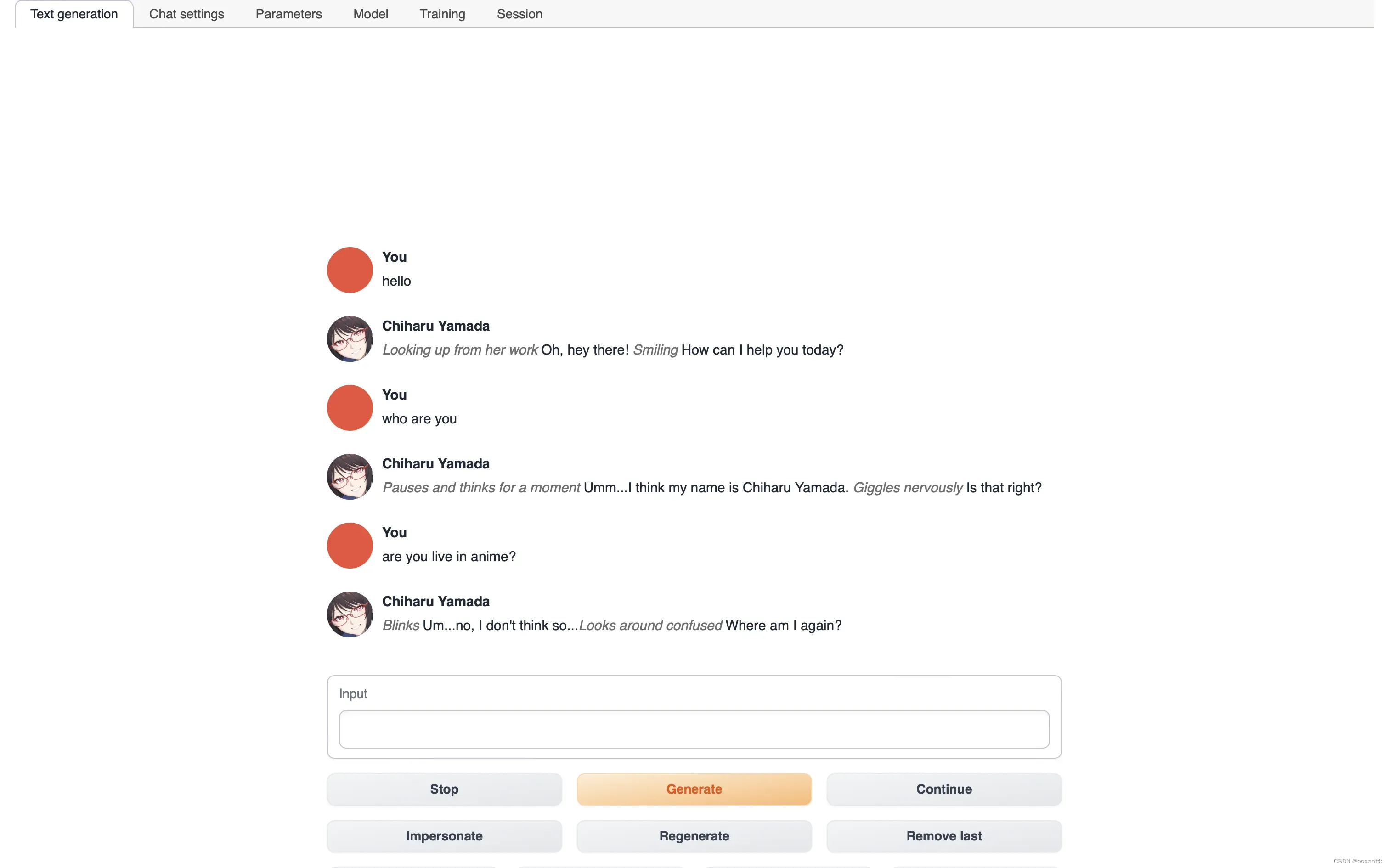
下图是运行成功的截图,可以愉快的聊天了,并且是免费的,性能不逼gpt4弱多少,但目前有个问题就是Llama 2对于中文的支持不好,中文语料只占0.15%,但是因为开源可能很快就有华人对模型微调从而适应中文了,可以关注一下。
因为是本地开源,所以是可以对模型进行微调训练的但这里我就不详细介绍了。
可能会遇到的报错:
ImportError: cannot import name 'is_npu_available' from 'accelerate.utils'
(/usr/local/lib/python3.10/dist-packages/accelerate/utils/init.py)这是我在第一次运行时发生的报错,第二次时则没有,如果发生了这个报错可以把运行类型改成TPU。
文章出处登录后可见!
已经登录?立即刷新