一. 线性表——顺序表部分
总结1——多值删除问题:
下面这三个题的特点都是“在顺序表中进行多次删除”,在基础阶段,常见的操作是删除顺序表中的某个元素,是单值的删除,对于单值删除,只需要逐一挪动元素进行覆盖即可,非常简单,而多值的删除,所涉及到的代码中,最为关键的一行就是:
L.data[ i – j ] = L.data[ i ];
1. 删除线性表中所有值为x的元素
void DeleteElemX(Sqlist& L, ElemType x) {
int i = 0;
for (int j = 0; j < L.length; j++) {
if (L.data[j] == x) {
i++;
}
else {
L.data[j - i] = L.data[j];
}
}
L.length = L.length - i;
print(L);
}
//更为灵活的写法
void DeleteElemX(SqList& L, ElemType x) {
int i = 0;
for (int j = 0; j < L.Length; j++) {
if (L.data[j] == x) {
i++;
}
L.data[j] = L.data[j + i];
}
L.Length = L.Length - i;
print(L);
}2. 删除有序顺序表中所有值重复的元素
void DeleteRepeadElem(Sqlist& L) {
int i, j = 0;
for (i = 0; i < L.length; i++) {
if (L.data[i + 1] == L.data[i]) {
j++;
}
else {
L.data[i - j] = L.data[i];
}
}
L.length = L.length - j;
print(L);
}
//更为灵活的写法
void DeleteDepeated(SqList& L) {
int i,j = 0;
for (i = 0; i < L.Length; i++) {
if (L.data[i + 1] == L.data[i]) {
j++;
}
L.data[i] = L.data[i + j];
}
L.Length = L.Length - j;
print(L);
}3. 顺序表中删除给定值之间的元素
void DeleteElem(Sqlist& L, ElemType x1, ElemType x2) {
int i, j = 0;
for (i = 0; i < L.length; i++) {
if (L.data[i] >= x1 && L.data[i] <= x2) {
j++;
}
else {
L.data[i - j] = L.data[i];
}
}
L.length = L.length - j;
print(L);
}总结2——多路归并问题(与排序的结合):
1. 合并两个有序顺序表为一个有序顺序表
void MergeSqlist(Sqlist L1, Sqlist L2) {
Sqlist L3;
L3.length = L1.length + L2.length;
int i, j, k;
for (i = 0, j = 0, k = 0; i < L1.length && j < L2.length; k++) {
if (L1.data[i] < L2.data[j]) {
L3.data[k] = L1.data[i++];
}
else {
L3.data[k] = L2.data[j++];
}
}
while (i < L1.length) {
L3.data[k++] = L1.data[i++];
}
while (j < L2.length) {
L3.data[k++] = L2.data[j++];
}
print(L3);
}本题的思路基于二路归并排序的代码,即:
归并排序
void Merge(int A[],int low,int mid,int high) {
int B[MaxSize];
int i, j, k;
for (k = low; k < high; k++) {
B[k] = A[k];
}
for (i = low, j = mid + 1, k = i; i <= mid && j <= high; k++) {
if (A[i] < A[j]) {
B[k] = A[i++];
}
else if (A[i] > A[j]) {
B[k] = A[j++];
}
}
while (i <= mid) {
B[k++] = A[i++];
}
while (j <= high) {
B[k++] = A[j++];
}
}
void MergeSort(int A[], int low, int high) {
int mid = (low + high) / 2;
if (low < mid) {
MergeSort(A, low, mid);
MergeSort(A, mid, high);
Merge(A, low, mid, high);
}
}总结3:交换次序问题
例题:在一维数组中将两个线性表(a1,a2,…an)和(b1,b2,…,bm)顺序置换,即从原来的(a1,a2,…an,b1,b2,…,bm)变为(b1,b2,…,bm,a1,a2,…an)
思路:先置换a1…an,再置换b1…bm,再整体置换a1,…,bm,最后打印即可
void Transport(int A[], int n, int m,int len) {
int i, j;
int x;
for (i = 0; i <= (n - 1) / 2; i++) {
swap(A[i], A[n - i - 1]);
}
for (j = n, x = 1; j <= (2 * n + m - 1) / 2; j++,x++) {
swap(A[j], A[m + n - x]);
}
for (int k = 0; k <= (m + n - 1) / 2; k++) {
swap(A[k], A[m + n - k - 1]);
}
for (int l = 0; l < len; l++) {
printf("%3d", A[l]);
}
}总结4:与“查找”相结合的问题
例如:设计算法在最短时间内查找到顺序表中值为x的元素,如果没有则插入,如果有则删除
int FindANDDelete1(Sqlist& S, ElemType x) {
int local = 0;//初始化并记录元素节点的位置
int low, high, mid;
low = 0; high = S.length - 1;
while (low <= high) {
mid = (low + high) / 2;
if (S.data[mid] < x) {
low = mid + 1;
}
if (S.data[mid] > x) {
high = mid - 1;
}
if(S.data[mid] == x) {
local = mid;
break;
}
}
if (low > high) {
printf("查找失败!,下面进行插入");
S.data[high + 1] = x;
S.length++;
print(S);
return 1;
}
for (int i = local; i < S.length; i++) {
S.data[i] = S.data[i + 1];
}
S.length--;
printf("找到节点%d,下面进行删除", x);
print(S);
}这里要强调以下折半(二分)查找的一个易错点:那就是在while(low<=high)这个循环中,忘了写return语句而导致无限循环,因为课本上仅仅是返回查找成功的位置,因而直接return mid,但是本题要返回查找到的位置并进行后序操作,因此这里用了一个break来跳出循环
再者,就是要注意折半查找失败的情况,是low>high,此时,low或者high+1的位置就是要插入的位置
二. 线性表——链表部分
链表部分同样分为增删改查四种题型,其中“增”我们可以利用头插法和尾插法进行实现,较为简单,“查”我们可以借助工作指针通过循环遍历来实现,也很容易,因此,本篇主要讲“改”和“删”
1. “改”
所谓“改”,在数据结构考研考察中,鲜有仅仅是对某个节点的数据域进行修改的题目,因为这种题目过于简单,那么,考研一般考察的是对于某个节点进行修改,例如链表的就地逆置算法就是一个典型的“改”的操作
在“改”的时候,需要着重注意一点:
1. 用于循环的指针变量在完成对一个节点的修改后,要立刻指向下一个节点,那么,这就需要一个前指针q,初始化时q = p->next从而使得p在修改完成一个节点后能够借助q找到下一个待处理节点,这时通常的手法是:p = q ; q = q->next ; 但是,最容易出错的也正是这里,很多情况下,我们容易忽略q在前进的过程中可能会出现的空指针异常问题,因此,我们需要对q进行if条件限定,即
p = q ; if(q->next!=NULL){ q = q->next ; }
下面,以几道例题为例:
① 链表的就地逆置操作:
void LocalReverse(Linklist& L) {
Linklist p = L->next;
Linklist q = p->next;
L->next = NULL;
while (p != NULL) {
p->next = L->next;
L->next = p;
p = q;
if (q) {
q = q->next;
}
}
print(L);
}② 链表的拆分操作
void DivideList(Linklist& L) {
Linklist L1 = (LinkNode*)malloc(sizeof(LinkNode));
L1->next = NULL;
Linklist p = L->next;
LinkNode* q = p->next;//如果q在循环工作指针p的前面,注意if(q){q = q->next;}
L->next = NULL;
Linklist r = L, r1 = L1;
int count = 1;
while (p != NULL) {
if (count % 2 == 1) {
p->next = r->next;
r->next = p;
r = p;
p = q;
if (q) { q = q->next; }
count++;
}
else if (count % 2 == 0) {
p->next = r1->next;
r1->next = p;
r1 = p;
p = q;
if (q) { q = q->next; }
count++;
}
}
print(L);
printf("\n");
print(L1);
}我们有时候可能会有疑问,为什么while中的判断条件不可以写while(q!=NULL)呢?如果这样子写,那不是不用再判断q是否为空了吗?
答案是,如果写成while(q),我们就无法在循环语句中对链表的最后一个元素进行处理,需要进行特殊考虑,因为真正处理元素的是指针p,即q的前驱指针,如果判断条件写成q,那么p指向最后一个待处理节点时,循环已经结束了,故无法处理链表的最后一个节点,这里切记!!
③ 两递增单链表的归并(归并后递减排列)
void 单链表归并算法(Linklist& L1, Linklist& L2) {
Linklist p1 = L1->next;
Linklist p2 = L2->next;
Linklist pro1 = p1->next;
Linklist pro2 = p2->next;
L1->next = NULL;
while (p1 != NULL && p2 != NULL) {
if (p1->data < p2->data) {
p1->next = L1->next;
L1->next = p1;
p1 = pro1;
if (pro1) {
pro1 = pro1->next;
}
}
else if (p1->data > p2->data) {
p2->next = L1->next;
L1->next = p2;
p2 = pro2;
if (pro2) {
pro2 = pro2->next;
}
}
}
while (p1 != NULL) {
p1->next = L1->next;
L1->next = p1;
p1 = pro1;
if (pro1) {
pro1 = pro1->next;
}
}
while (p2 != NULL) {
p2->next = L1->next;
L1->next = p2;
p2 = pro2;
if (pro2) {
pro2 = pro2->next;
}
}
print(L1);
}2. “删”
对于“删除”,在用于循环遍历的工作变量找到要删除的节点后,我们通常的做法都是令一个指针指向其前驱(因为是单链表,我们可以通过遍历的方式找到其前驱),之后再进行删除,我们也可以直接令p->next作为循环指针而不是令p作为循环指针,这样可以使代码简明一些:
① 删除介于两个值之间的数
bool DeleteElemBet(Linklist& L, ElemType x1, ElemType x2) {
if (x1 > x2) {
return false;
}
Linklist p = L;
while (p->next != NULL) {
if (p->next->data >= x1 && p->next->data <= x2) {
Linklist q = p->next;
p->next = q->next;
free(q);
}
else {
p = p->next;
}
}
print(L);
return true;
}② 删除升序有序表重的重复元素
void 去除重复元素(Linklist& L) {
Linklist p = L->next;
while (p->next != NULL) {
if (p->next->data == p->data) {
Linklist r = p->next;
p->next = r->next;
free(r);
}
else {
p = p->next;
}
}
print(L);
}代码技巧补充:嵌套循环的值重置问题
这里需要注意,对于嵌套循环的题目,一定要注意在每一层嵌套的开始位置对新一轮的工作变量进行重新重置,否则会出现一系列的错误,例如在下面这个题目中,每一次遍历的开始就要重新初始化最小值指针min以及循环遍历工作指针p;但是,还有一种情况,那就是在内层嵌套结束处对工作变量或者指针进行重置,那么如何区别什么时候用第一种,什么情况用第二种呢?
答案是:如果要将工作变量或者指针归于起始位置或者起始位置附近(例如工作指针循环遍历完一一遍后要回到遍历前的原位置或者原位置的后一个位置),那么,在内层循环开始之前进行初始化,如果是要将工作变量或指针指向下一个位置,那么就在内层循环结束之时进行改动;并且如果有多个遍历指针的情况下,走的慢的“时针”可以在内层循环结束时进行修改,也可以在开始时进行修改,如果是前者,那么while中的语句通常是:while(p)如果是后者,那么就是while(p->next)
这点其实很好理解。如果是前者,那么是先指针移动,再进行while条件判断,如果是后者,那么是先进行条件判断,再移动指针,因此while中的设置本质目的是为了避免空指针异常的问题,下面看一个例子:在链表中,删除绝对值相等的节点仅保留第一次出现的,下面是针对上面两种情况的两个实例:
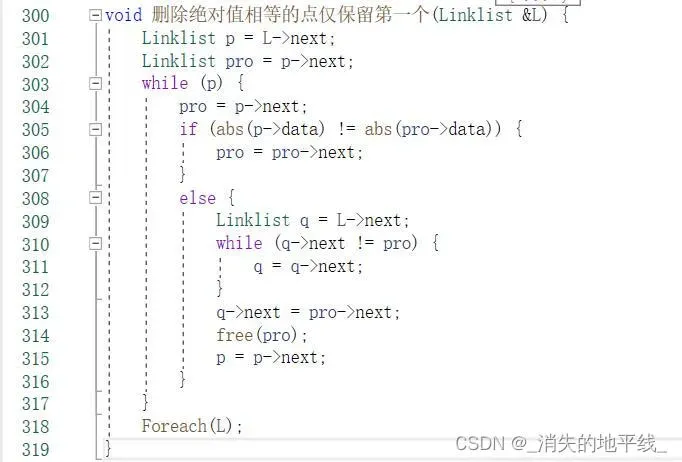
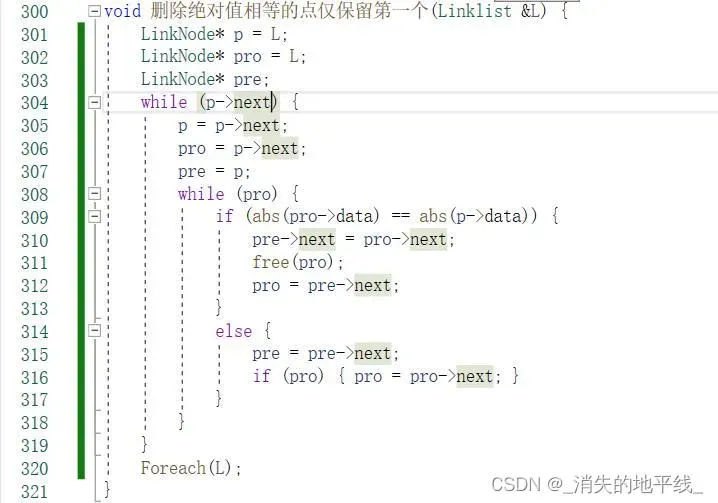
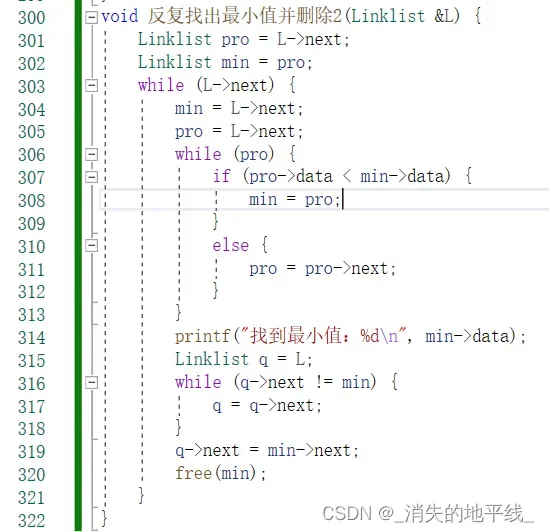
③ 依次删除最小值并打印
void PushIncreasement(Linklist &L) {
Linklist min = L->next;
Linklist p = L;
while (L->next != NULL) {
min = L->next;//这里容易遗漏,没有在每次循环开始时初始化min指针,导致第一次循环结束后min成为野指针而错误
p = L->next;
while (p != NULL) {
if (p->data < min->data) {
min = p;
}
else {
p = p->next;
}
}
Linklist q = L;
while (q) {
if (q->next == min) {
q->next = min->next;
printf("删除最小值%3d成功!", min->data);
free(min);
}
else {
q = q->next;
}
}
}
}
④ 链表的简单选择排序(还是考察嵌套循环时要在循环开始进行初始化设置这个考点)
//链表的简单选择排序
bool SampleSortForList(Linklist& L) {
Linklist p = L->next;
Linklist min = p;
Linklist q = L->next;
while (q->next) {
p = q;
min = q;
while (p) {
if (p->data < min->data) {
min = p;
}
else {
p = p->next;
}
}
swap(min->data, q->data);
q = q->next;
}
print(L);
return true;
}对比一下一般的简单选择排序:
bool SampleSort(int A[], int len) {
int i, j;
for (i = 0; i < len; i++) {
int min = i;
for (j = i; j < len; j++) {
if (A[min] > A[j]) {
min = j;
}
}
if (min != i) {
swap(A[min], A[i]);
}
}
printArr(A, len);
return true;
}⑤ 提取两链表公共元素并形成新链表
void CreateFromPublic(Linklist L1, Linklist L2) {
Linklist p1;
Linklist p2 = L2->next;
Linklist L = (LinkNode*)calloc(1, sizeof(LinkNode));
while (p2 != NULL) {
p1 = L1->next;//注意嵌套循环,每一层的开始一定要进行工作变量(或指针)初始化!!
while (p1 != NULL && (p1->data != p2->data)) {
p1 = p1->next;
}
if (p1 == NULL) {
p2 = p2->next;
}
else {
LinkNode* s = (Linklist)calloc(1, sizeof(LinkNode));
s->data = p2->data;
s->next = L->next;
L->next = s;//头插法产生新的单链表L
p2 = p2->next;
}
}
print(L);
}⑥ 判断两个链表的数据元素是否为包含关系(重难点题目)
这个题目较为困难,它结合了上面说到的两种方法,既要在嵌套循环开始前进行重置,又要在循环结束时进行指针后移
bool isContain(Linklist L1, Linklist L2) {
int len1 = 0;
int len2 = 0;
Linklist p1 = L1->next;
Linklist p2 = L2->next;
while (p1) { p1 = p1->next; len1++; }
while (p2) { p2 = p2->next; len2++; }
if (len1 < len2) {
printf("序列2不是序列1的子序列");
return false;
}
p1 = L1;
p2 = L2->next;
while (p2) {
p1 = L1->next;
bool iseql = false;
while (p1) {
if (p1->data != p2->data) {
p1 = p1->next;
}
else {
iseql = true;
break;
}
}
if (iseql == false) {//说明一次循环中,序列2中存在序列1中没有的元素
printf("序列2不是序列1的子序列");
return false;
}
p2 = p2->next;
}
printf("序列2是序列1的子序列");
return true;
}三. 非线性结构—-树与二叉树部分
基于层次遍历的算法
1. 找最大值与最小值
void countMaxAndMin(Bitree T) {
Queue Q;
initQueue(Q);
Bitree p = NULL;
EnQueue(Q, T);
int max = T->data, min = T->data;
while (!isEmptyQueue(Q)) {
p = DeQueue(Q, p);
if (p->data > max) {
max = p->data;
}if (p->data < min) {
min = p->data;
}
if (p->lchild) {
EnQueue(Q, p->lchild);
}
if (p->rchild) {
EnQueue(Q, p->rchild);
}
}
printf("最大值是:%d\n,最小值是:%d", max, min);
}
2. 求二叉树的高度
在非递归算法中,需要注意的是工作变量r始终指向当前层的最后一个节点,要判断当前层的节点是否全部入队,关键在于front指针,如果front指针走到了下一层节点入队前rear的前一个位置(即r的位置),那么说明此时,第i层入队的节点已经全部出队,第i层的所有孩子,即第i+1层的节点全部入队,此时,层数就要加1
int 计算二叉树的高度(Bitree T) {
if (T == NULL) { return 0; }
Queue Q;
initQueue(Q);
Bitree p = T;
EnQueue(Q, p);
int r = 1;
int level = 0;//注意level是从0开始的
while (!isEmptyQueue(Q)) {
p = DeQueue(Q, p);
if (p->lchild) { EnQueue(Q, T->lchild); }
if (p->rchild) { EnQueue(Q, T->rchild); }
if (r == Q.front) {
r = Q.rear;
level++;
}
}
printf("总层数:%d\n", level);
}
int 求二叉树深度递归算法(Bitree T) {
if (T == NULL) {
return 0;
}
else {
int llen = 求二叉树深度递归算法(T->lchild);
int rlen = 求二叉树深度递归算法(T->rchild);
if (llen > rlen) {
return llen + 1;
}
else {
return rlen + 1;
}
}
}
3. 求二叉树的宽度
同样是利用了rear和front指针,当某一层节点全部入队后,此时rear和front指针的差距就是当前层节点的个数,若要统计最大宽度,那么只需要不断迭代更新,如果当前层节点个数大于上一次记录的该层最大节点个数,就更新
void countwidth(Bitree T) {
Queue Q;
initQueue(Q); //Q.front = Q.rear = 0
Bitree p = NULL;
int r = 0; //r始终指向当前层最后一个节点
int width = 1; //width初始化设为第一次节点的个数
EnQueue(Q, T);
while (!isEmptyQueue(Q)) {
p = DeQueue(Q, p);
if (p->lchild) {
EnQueue(Q, p->lchild);
}
if (p->rchild) {
EnQueue(Q, p->rchild);
}
if (r == Q.front - 1) {
if (width < Q.rear - Q.front) { //Q.rear-Q.front表示当前层节点的个数
width = Q.rear - Q.front;
}
r = Q.rear - 1;
}
}
printf("树的宽度是:%d\n", width);
}
4.求二叉树中第k层中的节点数量
int GetCountK(Bitree T,ElemType k) {
if (k == 0) { return 0; }
if (k == 1) { return 1; }
Queue Q;
initQueue(Q);
BitNode* p = T;
int r = 0, level = 0;
int count = 0;//count代表对应层数的节点数量
EnQueue(Q, p);
while (!isEmptyQueue(Q)) {
p = DeQueue(Q, p);
if (p->lchild) {
EnQueue(Q, p->lchild);
}if (p->rchild) {
EnQueue(Q, p->rchild);
}
if (Q.front - 1 == r) {
level++;
r = Q.rear - 1;
if (level+1 == k) {
count = Q.rear - Q.front;
}
}
}
printf("\n");
return count;
}
5. 求值为x的节点所在层次
int GetLevelOfk(Bitree T,ElemType x){
Queue Q;
initQueue(Q);
Bitree p = T;
EnQueue(Q, T);
int level = 0, r = 0;
while (!isEmptyQueue(Q)) {
p = DeQueue(Q, p);
if (p->lchild) { EnQueue(Q, p->lchild); }
if (p->rchild) { EnQueue(Q, p->rchild); }
if (Q.front - 1 == r) {
level++;
r = Q.rear - 1;
}
if (p->data == x) {
printf("值为%c的节点所在层次为:%d", x, level);
return level;
}
}
6. 交换二叉树的左右子树
如果当前访问节点不为空,且左右子树存在其一,那么就进行交换(这里很好理解,首先如果是空节点,肯定不用交换,其次,如果该节点没有子树,那么也肯定不用交换)
BitNode* swap(Bitree T) {
Queue Q;
initQueue(Q);
Bitree p = T;
EnQueue(Q, T);
while (!isEmptyQueue(Q)) {
p = DeQueue(Q, p);
if (p != NULL && (p->lchild || p->rchild)) {//如果当前访问节点不为空,且左右子树存在其一,那么就进行交换(这里很好理解,首先如果是空节点,肯定不用交换,其次,如果该节点没有子树,那么也肯定不用交换)
BitNode* temp;
temp = p->lchild;
p->lchild = p->rchild;
p->rchild = temp;
if (p->lchild) {
EnQueue(Q, p->lchild);
}if (p->rchild) {
EnQueue(Q, p->rchild);
}
}
}
printf("交换后的次序如下:");
LevelTraversal(T);
return T;
}
7. 统计节点类型(即单分支,双分支,终端节点的个数)
void CountCateglory(Bitree T) {
Queue Q;
initQueue(Q);
Bitree p = T;
EnQueue(Q, p);
int single = 0, doubles = 0, leaf = 0;
while (!isEmptyQueue(Q)) {
p = DeQueue(Q, p);
if ((p->lchild != NULL) && (p->rchild == NULL)) {
EnQueue(Q,p->lchild);
single++;
}
else if ((p->rchild != NULL) && (p->lchild == NULL)) {
EnQueue(Q, p->rchild);
single++;
}
else if (p->lchild && p->rchild) {
EnQueue(Q, p->rchild);
EnQueue(Q, p->lchild);
doubles++;
}
else {
leaf++;
}
}
printf("该二叉树的叶子节点有%d个,单分支节点有%d个,双分支节点有%d个", leaf, single, doubles);
}
8. 统计是否为完全二叉树
bool Is_Complete(Bitree T) {
Queue Q;
initQueue(Q);
BitNode* p = T;
EnQueue(Q, p);
while (!isEmptyQueue(Q)) {
p = DeQueue(Q, p);
if (p != NULL) {
EnQueue(Q, p->lchild);
EnQueue(Q, p->rchild);
}
else {
while (!isEmptyQueue(Q)) {
BitNode* q = DeQueue(Q, q);
if (q != NULL) {
printf("!Com");
return false;
}
}
printf("是完全二叉树");
return true;
}
}
}
基于后序遍历的算法
1. 寻找双节点共同祖先
提到寻找祖先,就不难想到用非递归的后续遍历模型来求解,因为后续遍历在遍历到一个节点时,此时工作栈中存放的节点均为当前被遍历的节点的祖先
因此,我们只需要设立两个工作栈,分别存储p和q的所有祖先,然后,当遍历到p,q时,将这两个工作栈中的元素依次进行对比,其中最近出现的公共元素即为两者距离最近的共同祖先,具体的代码逻辑如下:
void SearchAllAncestorOfPQ(Bitree T,ElemType x1,ElemType x2) {
Stack S;
stackInit(S);
Stack S1, S2;
stackInit(S1); stackInit(S2);
Bitree p = T, r = NULL;
Bitree pre = NULL;
while (p || !isEmpty(S)) {
if (p) {
stackpush(S, p);
p = p->lchild;
}
else {
p = getTop(S);
if (p->rchild && r != p->rchild) {
p = p->rchild;
}
else {
p = stackpop(S, p);
if (p->data == x1) {
S1 = S;
}if (p->data == x2) {
S2 = S;
}
r = p;
p = NULL;
}
}
}
while (!isEmpty(S1)) {
p = stackpop(S1, p);
while (!isEmpty(S2)) {
pre = stackpop(S2, pre);
if (p->data == pre->data) {
printf("公共祖先节点为:%c\n", pre->data);
}
}
}
}
想要查找节点的所有祖先,要按照后续遍历的方式进行,当找到目标节点后,将目标节点出栈,此时保存在栈中的节点,即为该节点的所有祖先,具体的原因是基于后续非递归遍历的流程,这里不再赘述,简图如下所示:
具体代码如下:
void findPreNode(Bitree T,char x) {
StackNode S;
stackInit(S);
Bitree p = T;
Bitree tab = NULL;
while (p != NULL || !isEmpty(S)) {
if (p) {
stackpush(S, p);
p = p->lchild;
}
else {
p = getTop(S);
if (p->rchild != NULL && p->rchild != tab) {
p = p->rchild;
}
else {
p = stackpop(S, p);
if (p->data == x) {
while (!isEmpty(S)) {
p = stackpop(S, p);
visits(p);
}
}
p = NULL;
}
}
}
基于递归的算法
1. 判断是否为镜像树
bool Is_Mirror(Bitree T1,Bitree T2) {
if (T1 == NULL && T2 == NULL) {
return true;
}
else if ((T1 == NULL && T2 != NULL) || (T2 == NULL && T1 != NULL)) {
return false;
}
return (T1->data == T2->data) && Is_Mirror(T1->lchild, T2->lchild) && Is_Mirror(T1->rchild, T2->rchild);
}
2. 判断是否为二叉排序树
int Is_BST(BitNode* T) {
int b1, b2;
if (T == NULL) {
return 1;//空树是二叉排序树
}
else {
b1 = Is_BST(T->lchild);
if (b1 == 0 || predt > T->data) { return 0; }
predt = T->data;
b2 = Is_BST(T->rchild);
return b2;
}
}
3. 判断是否为平衡二叉树
int Is_Balance(Bitree T,int &d) {//d表示树T的高度
if (T == NULL) {
d = 0;//空树的高度为0
return 1;//空树是平衡二叉树
}
int ld, rd;
if (!Is_Balance(T->lchild, ld)) { return 0; }
if (!Is_Balance(T->rchild, rd)) { return 0; }
d = (ld > rd ? ld : rd) + 1;
return abs(ld - rd) <= 1;
}
二叉排序树的应用
1. 二叉排序树的建立和插入
bool BST_Insert(Bitree& T, ElemType x) {
if (T == NULL) {
Bitree T = (BitNode*)calloc(1, sizeof(BitNode));
T->data = x;
return true;
}
if (T->data > x) {
BST_Insert(T->lchild, x);
}
else if (T->data < x) {
BST_Insert(T->rchild, x);
}
else {
printf("二叉排序树中不能插入相同值");
return false;
}
}
void BST_Create(Bitree& T,int A[],int len) {
T = NULL;
int i = 0;
while (i < len) {
BST_Insert(T, A[i]);
i++;
}
}
2. 二叉排序树的删除
bool BST_Delete(Bitree& T, ElemType e) {
if (T == NULL) { return false; }
if (T->data > e) {
BST_Delete(T->lchild, e);
}
if (T->data < e) {
BST_Delete(T->rchild, e);
}
else {
if (T->lchild == NULL) {
BitNode* temp = T;
T = T->rchild;
free(temp);
}else if (T->rchild == NULL) {
BitNode* temp = T;
T = T->lchild;
free(temp);
}
else {
Bitree temp = T->lchild;
while (temp->rchild) {
temp = temp->rchild;
}
T->data = temp->data;
BST_Delete(T->lchild, temp->data);
}
}
}
3. 二叉排序树的查找
bool BST_Search(Bitree T, ElemType e) {
while (T != NULL && T->data != e) {
if (T->data < e) {
T = T->rchild;
}
if (T->data > e) {
T = T->lchild;
}
}
return T;
}
文章出处登录后可见!