
Hi,今天为大家介绍最新的本地中文语言模型进展。
[2023/08/25] Chinese-LLaMA-2发布了新的更新:
长上下文模型Chinese-LLaMA-2-7B-16K和Chinese-LLaMA-2-13B-16K,支持16K上下文,并可通过NTK方法进一步扩展至24K+。
这意味着在使用这些模型时,你可以获得更长的上下文信息,从而提高模型的语义理解和生成能力。
这些模型的发布对于本地部署的私有化应用场景来说是一个重要的进展。现在,你可以在个人电脑上快速进行大模型量化和部署体验,无需依赖云服务。这为开发者和研究人员提供了更大的灵活性和自主性。
另外,这些模型还支持🤗transformers、llama.cpp、text-generation-webui、LangChain、privateGPT、vLLM等LLaMA生态,你可以根据自己的需求选择合适的工具和框架进行开发和部署。
同时,还引入了FlashAttention-2技术,这是一种高效的注意力机制,可以加速模型的推理速度并节省显存占用。
如果你对模型的详细信息和使用方法感兴趣,可以在GitHub仓库中找到相关文档和代码。提供了预训练脚本、指令精调脚本以及量化和部署的教程,帮助你更好地理解和使用这些模型。
这些最新的本地中文语言模型为开发者和研究人员提供了更多选择和灵活性,让他们能够更好地应对不同的应用场景和需求。
本地模型部署后,现在也可以在MixCopilot接入使用啦:
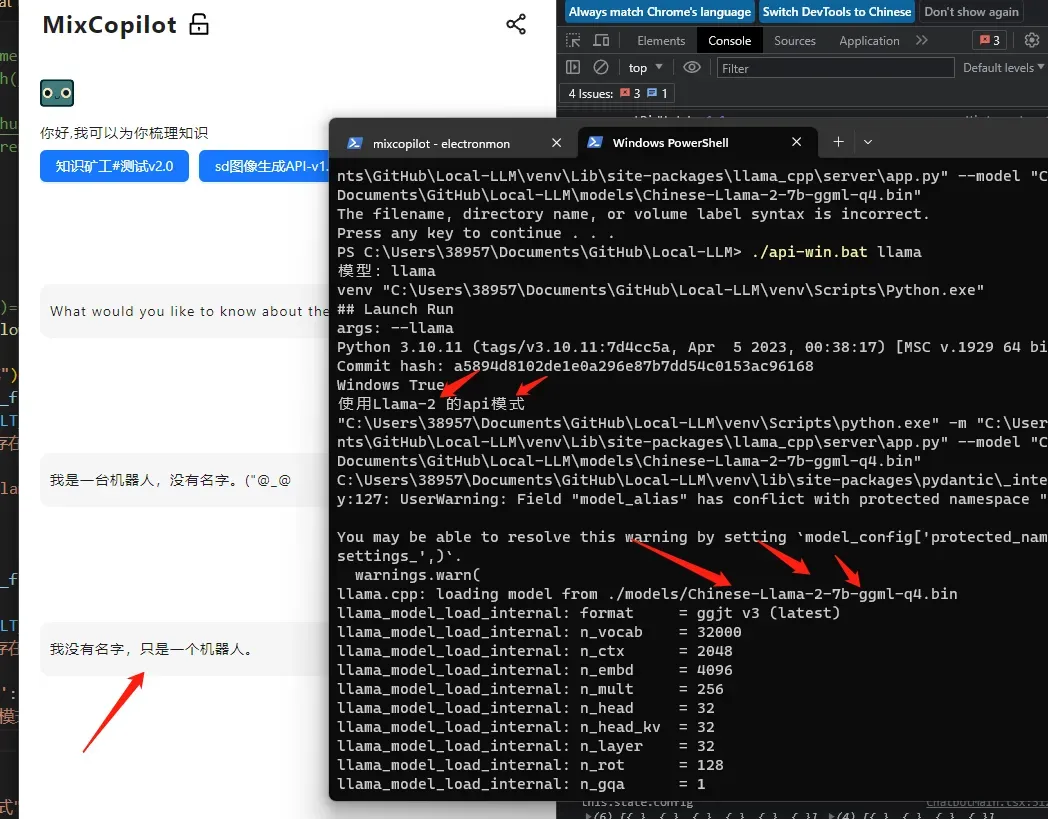
期待看到更多基于这些模型的创新应用和研究成果的出现。欢迎添加我们的大语言模型社群:

感谢大家收听今天的节目,我们下期再见!
文章出处登录后可见!
已经登录?立即刷新