VAE Stable Diffusion(稳定扩散)是一种用于生成模型的算法,结合了变分自编码器(Variational Autoencoder,VAE)和扩散生成网络(Diffusion Generative Network)的思想。它通过对变分自编码器进行改进,提高了生成样本的质量和多样性。
VAE Stable Diffusion的核心思想是使用扩散生成网络来替代传统的解码器。扩散生成网络是一个逐步生成样本的过程,每一步都通过对噪声进行扩散来生成样本。这种逐步生成的过程可以提高生成样本的质量,并且可以控制生成样本的多样性。
这话太学术性了。说人话就是在Stable Diffusion中使用VAE能够得到颜色更鲜艳、细节更锋利的图像,同时也有助于改善脸和手等部位的图像质量。
VAE在生成图像过程中的作用可以通过下面的图简单了解下:
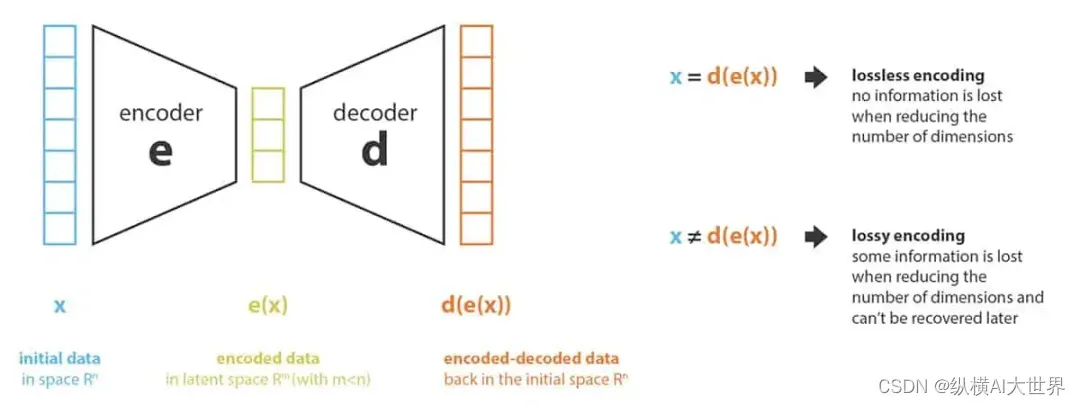
原始图像,比如高维度 512*512的,会经过encoder编码生成低维度的大小 比如 64*64,编码后的图像跟原始图像位于不同的空间中,前者在一个叫latent 空间中,后者是像素 pixel空间。在latent空间中生成后的图像再经解码还原到像素空间,即人类看见的图像,这个过程中,图像会有信息损失,而VAE就充当了上述编解码器的角色,好的VAE模型能够较好的保证图像质量。

PastelMix model:

Deliberate model

常见 VAE 模型类型
一般情况下,我们只需要重点关注 Stability AI 推出的 EMA (Exponential Moving Average)和 MSE (Mean Square Error )两个类型的 VAE 模型即可。
•stabilityai/sd-vae-ft-ema[1]
•stabilityai/sd-vae-ft-mse[2]
就使用经验而言,EMA 会更锐利、MSE 会更平滑。
除此之外,还有两个比较知名的 VAE 模型,主要用在动漫风格的图片生成中:
•WarriorMama777/OrangeMixs[3]
•hakurei/waifu-diffusion-v1-4[4]
除了上面的几种 VAE 模型之外,有一些模型会自带自己的 VAE 模型,比如最近发布的 SDXL 模型,在项目中,我们能够看到模型自己的 VAE 模型。
•stabilityai/stable-diffusion-xl-refiner-1.0/vae[5]
•stabilityai/stable-diffusion-xl-base-1.0/vae[6]
在 Stable Diffusion 的世界,修复人脸主要依赖的是下面两个项目的能力:
•TencentARC/GFPGAN[7]
•sczhou/CodeFormer[8]
前文提到的 Stability AI 推出的常用的 VAE 模型,是基于 LAION-Aesthetics[9]和 LAION-Humans,对 CompVis/latent-diffusion[10] 项目进行了模型微调而来的模型。而这两个数据集特别针对人对于图片的喜爱程度进行了整理,其中后者包含大量的人脸。
所以,在经过高质量的图片、大量人脸数据的训练后,VAE 模型对于改善图片色调,以及轻微修正图片中的人脸,也具备了一些能力。
Stable Diffusion 最好的VAE
- kl-f8-anime (Anything V3) – for anime art (created by Hakurei by finetuning the SD 1.4 VAE on several anime-styled images).【11】
- kl-f8-anime2 – for anime art, improved colors (use of red hue is dimmed down).【12】
- vae-ft-mse-840000-ema-pruned – for realistic models or styles (created by StabilityAI).【13】
- OrangeMixs – for anime art.【14】
- Color101 – for improving colors and color depth.【15】
在Stable Diffusion中,不管是V1,V2,还是其他基础模型,如果本身对图像质量没有苛刻要求,其实是不需要额外部署VAE模型的,因为现在很多模型中都已经集成了VAE,比如 Anything VAE 已经集成到 Anything 模型了,再额外增加模型也没有效果。但是通过使用额外的VAE能够胜过默认提供的内置模型。当确实需要下载部署额外VAE时候,将下载的模型放置在目录(以AUTOMATIC1111’s WebUI为例):
*\stable-diffusion-webui\models\VAE
如果有多个VAE,你可以在UI Settings中选择你更喜欢的VAE:
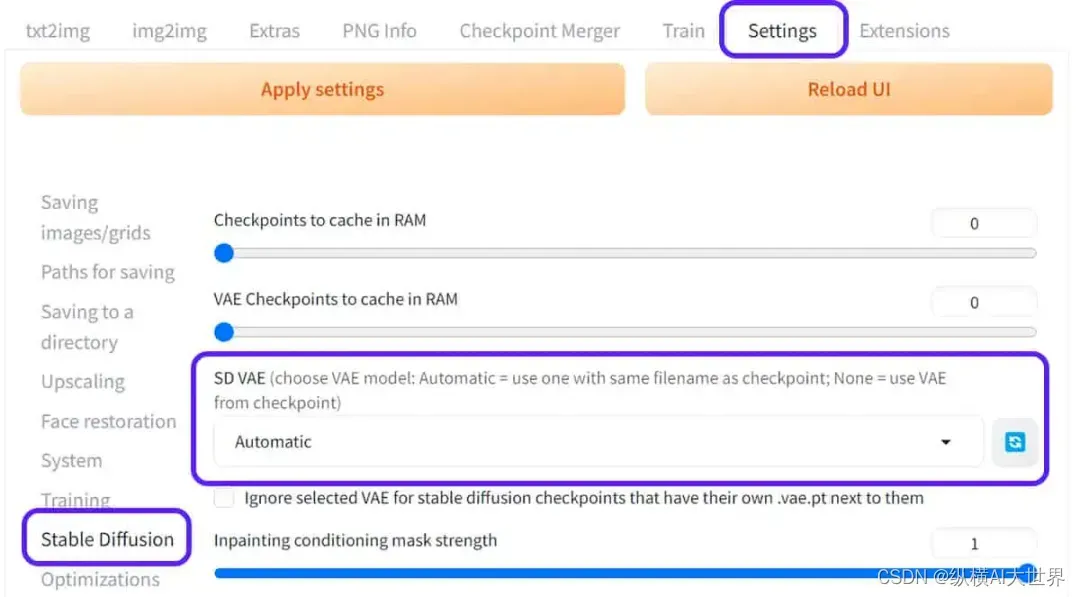
Selecting VAE manually from AUTOMATIC1111 WebUI’s Settings. Settings -> Stable Diffusion -> SD VAE -> Choose your preferred VAE
资源链接:
[1] stabilityai/sd-vae-ft-ema: stabilityai/sd-vae-ft-ema · Hugging Face
[2] stabilityai/sd-vae-ft-mse: stabilityai/sd-vae-ft-mse · Hugging Face
[3] hakurei/waifu-diffusion-v1-4: hakurei/waifu-diffusion-v1-4 · Hugging Face
[4] stabilityai/stable-diffusion-xl-refiner-1.0/vae: stabilityai/stable-diffusion-xl-refiner-1.0 at main
[5] stabilityai/stable-diffusion-xl-base-1.0/vae: stabilityai/stable-diffusion-xl-base-1.0 at main
[6] stabilityai/sdxl-vae: stabilityai/sdxl-vae · Hugging Face
[7] TencentARC/GFPGAN: GitHub – TencentARC/GFPGAN: GFPGAN aims at developing Practical Algorithms for Real-world Face Restoration.
[8] sczhou/CodeFormer: GitHub – sczhou/CodeFormer: [NeurIPS 2022] Towards Robust Blind Face Restoration with Codebook Lookup Transformer
[9] LAION-Aesthetics: LAION-Aesthetics | LAION
[10] CompVis/latent-diffusion: GitHub – CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
[11] vae/kl-f8-anime2.ckpt · hakurei/waifu-diffusion-v1-4 at main
[12] vae/kl-f8-anime2.ckpt · hakurei/waifu-diffusion-v1-4 at main
[13] vae-ft-mse-840000-ema-pruned.safetensors · stabilityai/sd-vae-ft-mse-original at main
[14] VAEs/orangemix.vae.pt · WarriorMama777/OrangeMixs at main
文章出处登录后可见!