这是一篇什么文章?
本文希望以一个用户请求为线索,将整个用户侧到服务器至存储层整个链路给串起来,从全链路到角度尽可能通俗的谈一谈各个部分的一些优化思路和自己的思考,笔者水平有限,有些思路也还没有经过大流量的检验,对于一些大佬来说可能本文不能让你眼前一亮,在此就可以return了。
为什么会写这么一篇文章?
先说一说我的情况吧,目前大四在读,通信工程专业,学校算不上很好吧,普通一本罢了,上了大学以来,对计算机就挺感兴趣的,对于本专业的一些课程,像模拟电路,通信原理等提不起太大的兴趣,于是在业余时间,自己学习计算机相关的东西,大一大二时以学习python为主,学习了爬虫,自动化,机器学习,深度学习等等,当时是想着毕业后搞人工智能方面的工作,自己也玩过一些demo,像猫狗识别啊,NLP等等,不过其实都是很浅显的部分。后来了解到人工智能这玩意好像挺看重学历的,而自己的学历本身不出众,所以放弃了,大二结束的暑假转而学习后端开发的技术栈,当时学习的语言是Java,为什么选它呢?当时是觉得Java的就业人员虽然多,但是就业机会也是最多的,并且网上的资料也是最全的。当时也没有想过进什么大厂之类的,就凭借着自己的一腔热情在学。
时间到了大三下学期开学,当时春招也开始了嘛,试着投了几家,有幸拿到了两家大厂一个实习机会,实习了几个月又开始秋招,也是受打击的一次,最开始蛮顺利的,三家大厂都是技术面➕HR面都面完了,然后等这三家的结果,结果一家都没等到,不知道是学历的原因还是哪一面没答太好(个人猜测是横向对比排掉了),也情绪低落了两天吧,不过总是要站起来的,这也是我觉得秋招比考研更好的一点,考研一年只有一次,但秋招大厂有很多,同一家大厂也不只 一次机会,就接着面嘛。最后还是拿到了几家大厂的意向,目前在鹅厂提前实习。来了公司之后也学习了很多,很多的内部资源,真的有很多大佬,所以写一篇文章也是对我这么久以来的一些知识做一个总结吧。
本篇文章图不多,因为懒。
从用户侧说起
当时年少不太懂啊,学java不久那段时间遇到这个问题我可能会说,这有啥好说的,不就是一个dns解析,拿到ip,然后就到服务器了嘛。
其实这玩意还真有些可以优化的点,为什么这么说呢,首先最极致的性能就是没有网络开销,也就是浏览器缓存,直接在客户端就做了,但是这么做不可靠啊,万一数据有变更不就是旧数据了嘛。是这样,所以所谓的浏览器缓存并不是什么都不做,http请求的请求头信息其实有很多,服务器可以设置资源的过期时间,或者说服务器在响应一个资源时添加了ETag字段,那么当下一次浏览器会先发一个请求判断资源有没有过期。当然这其实不是很常用,这儿就浅说一下。
然后是DNS这一层,浏览器得把域名解析成ip嘛,可是这里可能存在本地DNS缓存了失效的ip,域名劫持等问题哦,也可能存在本地运营商DNS偷懒把解析请求发给其他运营商, 导致全局调度器搞错浏览器的运营商造成跨网访问的问题。
关于跨网访问这儿可以说一下,简单来说服务器是也是有运营商出口的,所谓的三网服务器就是有电信,移动,联通的出口,只要你的网络是这三个运营商的都不需要跨网,但是三网服务器贵啊,一般的服务器可能只有电信或者联通的,而跨网就是说你访问服务器会到 国家级互联网骨干直联点 进行一个转化,简单来说就是绕路了。
这里挂一张 国家级互联网骨干直联点 图
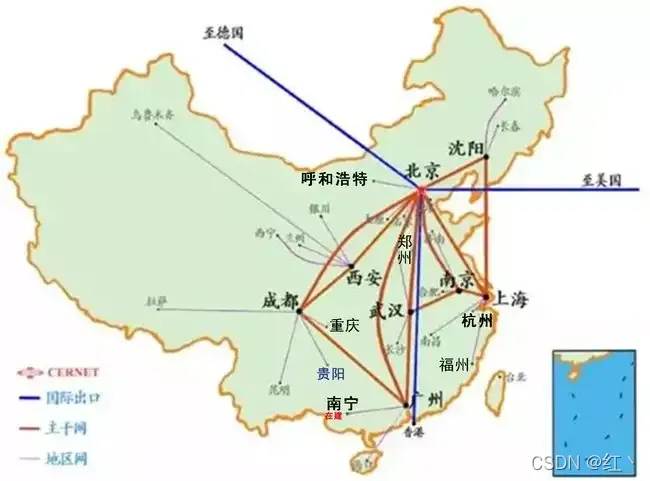
那么这怎么解决呢,其实在浏览器上还真不好解决,不过到客户端上就好解决了,用httpdns就能很好解决了,httpdns简单来说就是将DNS解析发http请求找公司自己建的dns服务器,不走本地运营商的DNS了。这时候就能拿到用户真实的信息,实现最优的一个调度。
不过用户到服务器的这一段是最不可控的,只要请求到了服务器,那么这个请求就是可控的了,而且内网的速度可是比公网快很多的。那么我们就得想办法减少这个不可控的范围。那么如何减少这个距离呢,用CDN就好了。
CDN又叫内容分发网络,简单来说就是在全国各大城市建一个CDN服务器,那么用户请求只需要请求离他最近的CDN服务器不就好了,CDN有什么用呢?
- 可以做静态资源的加速,也就是说把一些静态的资源放到CDN上,请求到CDN这一层就返回了,而且还可以做动态的一个加速,比如我们为了安全使用https协议请求,那么到CDN这一层是不是就可以把tls卸载了?走http或者rpc请求到服务器上。如果想要加速得更多的话有钱的公司甚至会搭专线,这可比走公网快多了。
- CDN也可以让我们的服务器更加安全,为什么?因为除了CDN谁也不知道我们服务器的真实IP了呀。
- 请求聚合也算是CDN的一个优势吧,比如大量访问同一份资源请求miss了,那么CDN是不是只用发一个请求到服务器去拿数据就好了?有条件的公司甚至会设置多级CDN,如果资源miss了一层层回源,尽可能减少到服务器的请求。
- 连接聚合,CDN也能够自己管理大量的连接,服务器则只需要管理自己和CDN的连接就好了。
- 边缘计算了,我们可以把一些计算的逻辑放到CDN上。
总的思想就是在离用户近一些的地方做更多的事情,CDN近几年的发展也是非常迅速,像现在还有PCDN,SCDN等。
ps: CDN 无论是浏览器还是客户端的请求都可以加速,客户端可以走httpdns调度到离用户最近的CDN,浏览器走传统的DNS也可以通过CNAME调度到CDN。
谈服务器之前先说一说网络协议吧
现在大多数网站应该还是http1.1吧,http我们知道是基于tcp的,先说一说tcp的优化思路吧。
- tcp首先需要三次握手才能建立连接吧,第一次握手的服务器会把这个连接放在半连接队列里面,等到三次握手完了之后就会把这个连接放到全连接队列里面,然后等到accpte来取连接就好了。但是当遇到syn攻击时可能导致半连接队列被打满,后续的连接服务器就会拒绝了。这时候就可以聊一聊tcp 的 syncookie了,简单来说就是服务器不会保持这个连接到半连接队列,而是计算一个cookie给客户端,第三次握手的时候客户端带上这个cookie,服务端验证这个cookie的有效性,如果合法再分配专门的数据区进行处理未来的TCP连接。并且只要在cookie的有效期内,下一次连接无需三次握手就可以直接连接了,这是不是就省时间了?
- 再说到tcp的流量控制,大家知道tcp都有一个发送窗口和接受窗口是吧,那么我们可以根据服务器的性能设置一个合适的窗口大小,尽可能提高带宽吧。
- tcp是发一个包有一个ack,要是等到ack来了再发下一个包可就耗时长了,于是就有了累计应答这么一说,客户端不必再等待ack直接发下一个包,服务端可进行累计应答,如果有丢包通过sack告知客户端是哪个包丢了就行了。
- tcp拥塞控制都知道吧,最开始窗口大小是指数增长,到了ssthresh就开始线性增长了,直至发送拥塞,可是这传统的cubic算法有一个问题,就是一旦发生丢包就要拥塞避免,虽然现在有快恢复,但是发送速率还是有一个明显的下降。其实丢包不一定就说明是拥塞了,可能有很多原因,交换机有自己的队列控制算法(codel),大家有兴趣可以自行了解,于是有大佬提出了BBR算法,即通过一段时间内的最小延时和最大带宽来计算发送效率,尽可能保证带宽跑满。
- 最后到四次挥手了,time_out状态大家都不陌生吧,服务器可能由于time_out状态太多而导致无法建立新的连接了,linux其实有一个参数tcp_tw_reuse可以复用time_out的连接,前提是得打开tcp对时间戳的支持。
这些优化可还不够,我们知道http1.1是一问一答的形式,这就会造成典型的队头阻塞问题,并且每个请求可能会带上重复且臃肿的header,于是http2诞生了,简单说它对header进行了压缩,并且将header和body分成单独的流,通过流id进行区分,解决了队头阻塞问题,可是http2是基于tcp的,所以这还是存在tcp层次的队头阻塞,于是google再次提出了http3(QUIC)协议,它是基于UDP的,并在此之上实现了滑动窗口,拥塞控制,可靠性保证等等,彻底解决了队头阻塞。可是实际应用上这儿会有一个问题,就是大量UDP的包可能导致频繁的用户态到内核态的切换,其实可以考虑搞一个环形的缓冲区,牺牲一定的延时来提高吞吐量,减少两态的切换。
接下来是不是就该到服务器侧了?
请求或许通过层层CDN最终到达了我们的入口服务器,这个入口的服务器或许是开源的LVS+Keepalive 或者 Nginx来做负载均衡,也可能是公司自研的负载均衡器,nginx大家都知道性能很高,为什么呢?,首先他使用了epoll这个就不说了,这是内核提供的高性能网络处理技巧,nginx请求的切换是基于用户态的,同时nginx基于一把全局锁避免了epoll的惊群,nginx的work数量一般与cpu核心数相同,并且每个work与cpu绑定,提高了cpu cache的命中率,像一些数据结构也适用了内存对齐的技巧,让cpu只需要去内存取一次(cpu cache line),其他的一些技巧像连接池啊,高效的内存管理啊这里就不细谈了。
总之这里就是一个大流量入口加负载均衡功能,这儿说两个优化的点,我们知道当服务器收到请求后,这个请求一般会跑一遍内核的网络协议栈,那么我们是不是可以把负载均衡的逻辑放在软中断里面?这不就避免了用户态和内核态的频繁切换了吗?或者我们能不能让这个网络包直接在用户态进行处理?没错,这就是intel的DPDK技术。DPDK已经可以让性能达到千万级别了,但这其实对CPU还是有很大的压力,那么能不能把这些操作放到网卡层面?其实是可以的,现在已经有了智能网卡了,简单来说就是网卡里面其实是有CPU的,它可以处理这些网络操作,不用占用应用层的CPU,不得不感叹现如今硬件的强大啊。
请求下一个到达的地方是微服务网关(有些公司会把流量网关和微服务网关合到一起,例如阿里的云原生网关),微服务网关的目的是为了做一些横切面的功能,如鉴权,风控等,同时把后端的所有API信息聚合到一起,方便管理。微服务网关还有一个重要的功能,就是协议转换,比如我们可以把http请求转换成性能更好的rpc请求。rpc框架有很多,开源的thrift,dubbo,grpc等等,还有很多自研的,核心就是解决了服务发现,超时重试,负载均衡等等基础功能,提供SDK给业务层使用。
说到RPC就不得不提到序列化,我是比较喜欢protobuf这种序列化的,它不仅性能高而且它是强约束的,因为PB文件是严格定义了接口的格式的,我们不需要写接口文档了(这是松约束的),统一把PB文件管理到版本控制系统如git,看PB文件就相当于看接口文档,而且它一定是最新的,不会像接口文档一样有可能过时。
聊聊服务注册和发现
服务发现是一个老生常谈的话题了,现在大部门公司的应用都是微服务架构了,那么服务注册与发现一定是避不开的,所有微服务启动时一定会在注册中心进行注册,然后RPC调用的时候也会去访问注册中心进行服务发现。现在开源的组件也很多,但都是围绕CAP理论来的,像典型的AP系统Eureka,分布式协调鼻祖ZK,新生代ETCD,Consul,阿里开源的Nacos等等,也很很多公司选择自研,像Eureka这种集群是没有master的,它牺牲了一致性,保证了可用性,就是说每个节点都有全量的一个信息,这种模式的好处就是不怕高QPS,如果抗不住了水平扩容就行了,缺点就是存在存储瓶颈,一旦元数据过多那么单台机器就存不下了,并且可能数据不一致,节点变更信息需要一段时间才能同步到全部节点。那么像ZK,ETCD这种有主的缺点也就呼之欲出了,高频的写入问题,可能让master宕机,当然存储瓶颈也是存在的。
大家有没有发现一个问题,客户端是直接与存储的节点打交道的,就是注册中心既要处理服务注册与发现的请求,又要存储元数据。诶,提到这儿大家是不是就想到了,我们可以将存储和计算进行分离嘛!存算分离我个人理解应该是一个大的趋势。
没错,我们可以把计算节点单独拎出来处理这些发现和注册的请求,计算节点是无状态的了,是不是可以很方便扩缩容了?并且存储的节点由于不知道跟客户端打交道,像一些数据的迁移呀客户端基本无感。但大家有没有想一个问题,服务发现的请求是不是应该比服务注册的请求高几个数量级?没错大部分的请求应该都是服务发现的请求,那么我们可以做一个隔离,服务注册由一些节点完成,注册由一些节点完成,注册节点甚至可以直接写DB,异步同步到缓存(比如通过canal),因为并发量其实并不高,而像服务发现可以读缓存,健康检查呀则可以写缓存。有的朋友可能会问了,只写缓存不写DB吗?我们可以异步写DB嘛。比如把写请求发送到消息队列里面,然后由消费节点写DB,这样一是避免了与DB的直接依赖,二是可以聚合请求嘛,减小DB的压力。
那到来的每一个请求服务发现都查缓存吗?可不可以做个本地的缓存嘛,是不是又快了?编解码会耗cpu吧,那能不能缓存序列化好了的数据呢,这样下次请求来直接返回,无需序列化了。当然这么做可能会有一些时效性的问题,不过RPC框架也会有一些健康检查的机制,并且由于下游是多个节点,这个不通换一个不就好了,我个人觉得这是可以接受的。
写到这里突然由想到了一个解决方案,RPC框架拿到下游服务的信息,一般会进行健康检查,如果发现有连接失效了,可以给注册中心发一个请求,告诉它这个服务失效了,并把这个失效的ip带过去,注册中心首先比较本地缓存,如果一样说明本地缓存过期,然后读缓存,如果缓存过期的话,我们可以读DB,但这样与DB有依赖了,我个人觉得DB同步到缓存应该是很快的,canal是通过binlog的嘛。要不要读还是得具体情况来权衡吧,架构设计不就是不断权衡的嘛~哪有什么完美的解决方案。
聊聊RPC
现在的微服务大部分应该都是容器化部署了,并通过k8s来进行调度吧,这个架构的优点就是可按需部署,且弹性伸缩,微服务本身其实并没有什么好说的,k8s的话说起来有一点庞大了。云原生时代的三驾马车之一的service mesh对传统的rpc其实造成了一定的冲击,service mesh通过sidecar的形式部署一个数据平面(envoy)与微服务在同一个pod中,rpc调用这个数据平面就能帮我们做了,不过这其实多了两次转发(一来一回),性能有一定损耗,虽然现在做了很多优化,但也许还需要时间的考验。我们这儿只专注于rpc来聊聊,rpc最重要的功能就是服务发现了,这个其实上面也谈到了,这儿就不说了。
我们来聊聊超时控制,当然,我们希望的是一个全局的超时控制,这就需要比如从网关层算起,每到一个服务计算当前剩余超时时间和当前调用下游设置的最大超时时间中取一个最小的,然后rpc调用时把这个剩余超时时间给传递下去,这就可以做到一个全局的超时控制了。
然后是过载保护,我们可以通过滑动窗口统计一段时间内进程的负载情况,cpu,内存等使用情况,然后计算出一个负载情况,如果负载过高,对于后面的请求直接拒绝掉,避免进程挂掉。 那么对于调用方来说,我们是否可以拿到下游的负载信息,然后基于负载做一个最优的rpc负载均衡调度呢(传统的轮询,随机等由于不知道下游情况可能造成下游负载不一致)。这个该怎么拿,一是调用下游的时候返回可以携带一些信息,二就是隔一段时间问一下嘛。当然这些都是rpc框架要做的,业务应该是无感知的。
业务优化
请求从网关侧离开就会到达我们的微服务了,也就是业务侧,业务优化这里简单说几个思路
- 避免长时间的锁占有和大量的锁争夺。
- 尽量用cas替代锁,因为锁是会陷入内核态的,而cas是基于硬件的指令,不会到内核态,底层是怎么做的各位有兴趣可以看看MESI(缓存一致性)的设计。
- 批操作,提高吞吐量。
- 池化技术,使用内存池,线程池,连接池等等。
- 零拷贝技术,内存映射。
- 异步化,可以异步操作的时候尽量不要同步。
- 流水线,尽量让每个步骤都忙碌起来,提高cpu整体的利用率。
- GC 优化,减少垃圾对象
存储层
存储是一个很大的话题啊,有最常用的关系型数据库mysql,oracle等,缓存redis ,memcache等,文档型数据库mongodb,面向搜索的存储es,OLAP数据库clickhouse,海量存储Hbase,分布式数据库TiDB,分布式文件存储HDFS,到现在很火的对象存储,块存储,数据湖解决方案。实在是太多了。虽然这么多存储方案,但大家有没有想过,它们的索引的数据类型就那么几个,有B+树,B树,跳表,Hash表,倒排索引,字典树,LSM树。大家有兴趣可以了解一下这些数据结构的应用场景。
先说一说最通用的文件存储吧,我们知道一般文件系统为了加快IO的速度,一般都会是有自己的缓存的,也就是page cache,像一些零拷贝技术啊,也是直接把数据写到这里面去的,然后通过DMA控制器将数据写到磁盘,其实这儿也有一些IO调度策略,尽量一次性多写一些数据,提高吞吐量,而为了提高并行度,也可以用到RAID这样的技术,但其实这儿还是存在用户态到内核态的切换,为了解决这个问题,于是有了SPDK技术(类似于DPDK),其实就是把这些IO操作全部放到用户态来做。
再谈一下大规模分布式存储吧。
大规模的分布式存储一般有几个特点,一是数据海量,二是数据冗余(这是为了保证可靠性),三是优先写日志,因为写日志是顺序写,比较快。可是当数据量大到一定的级别就会出现元数据膨胀的问题,如果将元数据存在像ZK啊,ETCD啊这类的地方,肯定是不行的,一个节点内存撑死也才多大,像Eureka这种AP的系统也是不行的,虽然它可以抗住大量的并发(水平扩容),但是每个节点也会存在全量的数据,这可放不下啊。那么咋办。
有句话说的好,遇到解决不了的问题,加一层代理。即我们可以通过元数据分级,缩减元数据量来解决,一层存放元数据的逻辑卷映射,一层存放逻辑卷物理地址的映射,有点类似于HBASE的ROOT表和META表的思想,同时为了减少元数据的读写负载,可以给元数据也加一层缓存,其次我们可以把一些数据校验,修复,均衡的工作分离成独立的节点,各个节点只专注于自己的工作,且按需扩容,避免节点的任务繁杂,彻底解决了单master的瓶颈。
至于写日志,大部分分布式系统都是先写日志,在写磁盘,大家有没有发现这两个东西是不是有点耦合了,我们能不能把写日志的这个功能交给其他节点去做呢,即有单独的日志节点,它只负责写日志,我觉得这种方案最大的一个好处就是解耦了,由于日志节点不直接和业务相连接,对于像一些日志迁移啊基本对业务无感。
当然还有更厉害的,忘记是哪位大佬说过的一句话了,“日志即数据”,我们甚至可以把日志当作可靠的数据来看待。不过这种方案实际上用起来可能没那么简单吧,哈哈,不过也许也会是一个不错的思路呢。
文章出处登录后可见!