AIGC实战——条件生成对抗网络
- 0. 前言
- 1. CGAN架构
- 2. 模型训练
- 3. CGAN 分析
- 小结
- 系列链接
0. 前言
我们已经学习了如何构建生成对抗网络 (Generative Adversarial Net, GAN) 以从给定的训练集中生成逼真图像。但是,我们无法控制想要生成的图像类型,例如控制模型生成男性或女性的面部图像;我们可以从潜空间中随机采样一个点,但是不能预知给定潜变量能够生成什么样的图像。在本节中,我们将构建一个能够控制输出的 GAN,即条件生成对抗网络 (Conditional Generative Adversarial Net, GAN)。该模型最早由 Mirza 和 Osindero 在 2014 年提出,是对 GAN 架构的简单改进。
1. CGAN架构
在节中,我们将使用面部数据集中的头发颜色属性来设置 CGAN 的条件。也就是说,我们将能够明确指定是否要生成带有金发的图像。头发颜色标签作为 CelebA 数据集的一部分已在数据集中提供,CGAN 的架构如下图所示。
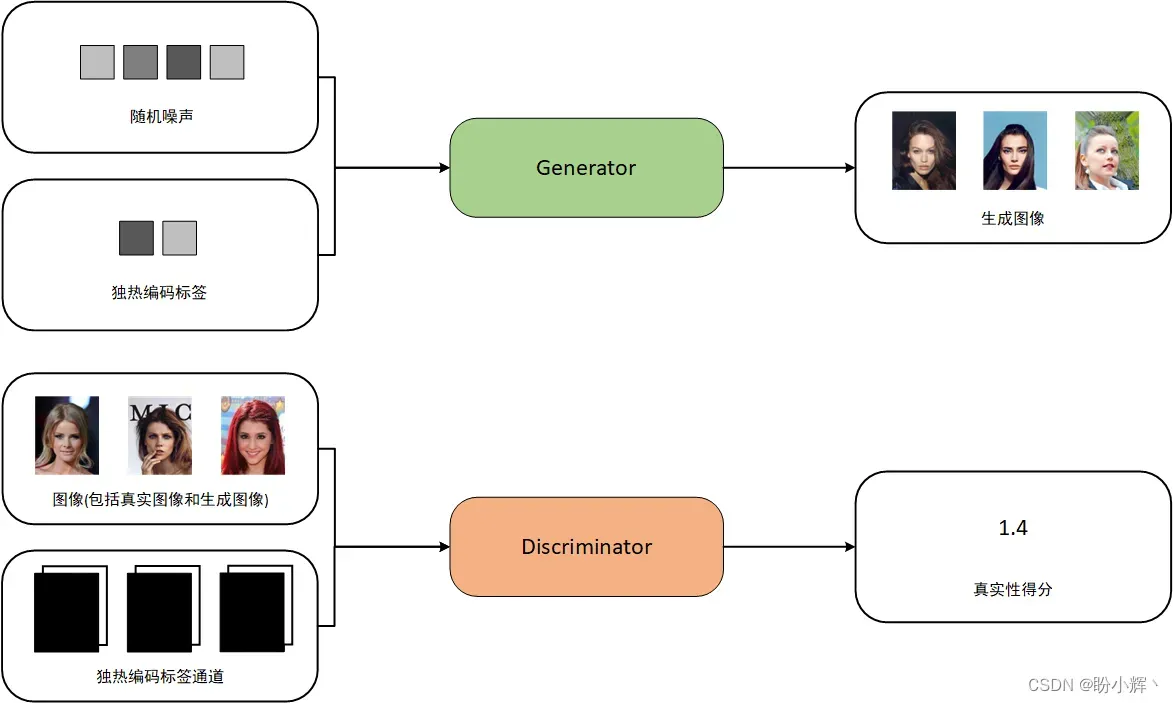
标准 GAN 和 CGAN 之间的关键区别在于:在 CGAN 中,我们需要向生成器和判别器传递与标签相关的额外信息。在生成器中,标签信息转化为独热编码 (one-hot) 向量后附加在潜空间样本之后。在判别器中,通过重复独热编码向量填充得到与输入图像相同形状的通道,将标签信息添加为 RGB 图像的额外通道。
CGAN 之所以能够生成指定类型的图像,是因为其判别器可以获得关于图像内容的额外信息,因此生成器必须确保其输出与提供的标签一致,以继续欺骗判别器。如果生成器生成了与图像标签不一致的图像,即使图像非常逼真,判别器会将它们判定为伪造图像,因为图像和标签并不匹配。
在本节所构建的 CGAN 中,因为有两个类别(金发和非金发),独热编码标签的长度是 2。但是,我们也可以根据需要拥有使用多个标签。例如,在 Fashion-MNIST 数据集上训练 CGAN 时,为了输出 10 种不同类型的 Fashion-MNIST 图像,可以通过将长度为 10 的独热编码标签向量并入生成器的输入,并将 10 个额外的独热编码标签通道并入判别器的输入。
综上,我们需要对标准 GAN 架构所进行的修改是,将标签信息与生成器和判别器的现有输入连接起来:
# 图像通道和标签通道分别传递给判别器,并进行连接
critic_input = layers.Input(shape=(IMAGE_SIZE, IMAGE_SIZE, CHANNELS))
label_input = layers.Input(shape=(IMAGE_SIZE, IMAGE_SIZE, CLASSES))
x = layers.Concatenate(axis=-1)([critic_input, label_input])
x = layers.Conv2D(64, kernel_size=4, strides=2, padding="same")(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Conv2D(128, kernel_size=4, strides=2, padding="same")(x)
x = layers.LeakyReLU()(x)
x = layers.Dropout(0.3)(x)
x = layers.Conv2D(128, kernel_size=4, strides=2, padding="same")(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Dropout(0.3)(x)
x = layers.Conv2D(128, kernel_size=4, strides=2, padding="same")(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Dropout(0.3)(x)
x = layers.Conv2D(1, kernel_size=4, strides=1, padding="valid")(x)
critic_output = layers.Flatten()(x)
critic = models.Model([critic_input, label_input], critic_output)
print(critic.summary())
# 潜向量和标签类别分别传递给生成器,并在调整形状之前进行连接
generator_input = layers.Input(shape=(Z_DIM,))
label_input = layers.Input(shape=(CLASSES,))
x = layers.Concatenate(axis=-1)([generator_input, label_input])
x = layers.Reshape((1, 1, Z_DIM + CLASSES))(x)
x = layers.Conv2DTranspose(
128, kernel_size=4, strides=1, padding="valid", use_bias=False
)(x)
x = layers.BatchNormalization(momentum=0.9)(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Conv2DTranspose(
128, kernel_size=4, strides=2, padding="same", use_bias=False
)(x)
x = layers.BatchNormalization(momentum=0.9)(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Conv2DTranspose(
128, kernel_size=4, strides=2, padding="same", use_bias=False
)(x)
x = layers.BatchNormalization(momentum=0.9)(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Conv2DTranspose(
64, kernel_size=4, strides=2, padding="same", use_bias=False
)(x)
x = layers.BatchNormalization(momentum=0.9)(x)
x = layers.LeakyReLU(0.2)(x)
generator_output = layers.Conv2DTranspose(
CHANNELS, kernel_size=4, strides=2, padding="same", activation="tanh"
)(x)
generator = models.Model([generator_input, label_input], generator_output)
print(generator.summary())
2. 模型训练
调整 CGAN 的 train_step 方法,以令生成器和判别器适应新的输入格式:
def train_step(self, data):
# 从数据集中提取图像和标签
real_images, one_hot_labels = data
# 将独热编码向量扩展为具有与输入图像相同空间尺寸 (64×64) 的独热编码图像
image_one_hot_labels = one_hot_labels[:, None, None, :]
image_one_hot_labels = tf.repeat(image_one_hot_labels, repeats=IMAGE_SIZE, axis=1)
image_one_hot_labels = tf.repeat(image_one_hot_labels, repeats=IMAGE_SIZE, axis=2)
batch_size = tf.shape(real_images)[0]
for i in range(self.critic_steps):
random_latent_vectors = tf.random.normal( shape=(batch_size, self.latent_dim))
with tf.GradientTape() as tape:
# 生成器接受包含两个输入的列表——随机潜向量和独热编码的标签向量
fake_images = self.generator([random_latent_vectors, one_hot_labels], training=True)
# 判别器接受包含两个输入的列表——真实/生成图像和独热编码的标签通道
fake_predictions = self.critic([fake_images, image_one_hot_labels], training=True)
real_predictions = self.critic([real_images, image_one_hot_labels], training=True)
c_wass_loss = tf.reduce_mean(fake_predictions) - tf.reduce_mean(real_predictions)
c_gp = self.gradient_penalty(batch_size, real_images, fake_images, image_one_hot_labels)
# 梯度惩罚函数还需要通过独热编码的标签通道传递(由于其流经判别器)
c_loss = c_wass_loss + c_gp * self.gp_weight
c_gradient = tape.gradient(c_loss, self.critic.trainable_variables)
self.c_optimizer.apply_gradients(zip(c_gradient, self.critic.trainable_variables))
random_latent_vectors = tf.random.normal(
shape=(batch_size, self.latent_dim)
)
with tf.GradientTape() as tape:
# 生成器训练过程的修改与判别器训练步骤的修改相同
fake_images = self.generator([random_latent_vectors, one_hot_labels], training=True)
fake_predictions = self.critic([fake_images, image_one_hot_labels], training=True)
g_loss = -tf.reduce_mean(fake_predictions)
gen_gradient = tape.gradient(g_loss, self.generator.trainable_variables)
self.g_optimizer.apply_gradients(zip(gen_gradient, self.generator.trainable_variables))
self.c_loss_metric.update_state(c_loss)
self.c_wass_loss_metric.update_state(c_wass_loss)
self.c_gp_metric.update_state(c_gp)
self.g_loss_metric.update_state(g_loss)
return {m.name: m.result() for m in self.metrics}
3. CGAN 分析
我们可以通过将特定的独热编码标签传递到生成器的输入中来控制 CGAN 的输出。例如,要生成一张非金发的人脸图像,我们传入向量 [1, 0];要生成一张金发的人脸图像,我们传入向量 [0, 1]。
CGAN 的输出如下图所示。可以看到,在保持随机潜向量不变的情况下,只改变条件标签向量,显然 CGAN 已经学会使用标签向量来控制图像的头发颜色属性,且图像的其余部分几乎没有改变。这证明了 GAN 能够以这种方式组织潜空间中的点,使得各个特征可以相互解耦。

如果数据集中有标签可用,即使不一定需要将生成的输出与标签相关联,将它们作为 GAN 的输入通常也可以提高生成图像的质量,我们可以把标签看作是像素输入的信息扩展。
小结
在本节中,构建了一个条件生成对抗网络 (Conditional Generative Adversarial Net, CGAN),通过将标签作为输入传递给判别器和生成器,能够生成可控类别的图像,这是由于标签为网络提供了额外的信息,以便使生成的输出与给定的标签相关联。
系列链接
AIGC实战——生成模型简介
AIGC实战——深度学习 (Deep Learning, DL)
AIGC实战——卷积神经网络(Convolutional Neural Network, CNN)
AIGC实战——自编码器(Autoencoder)
AIGC实战——变分自编码器(Variational Autoencoder, VAE)
AIGC实战——使用变分自编码器生成面部图像
AIGC实战——生成对抗网络(Generative Adversarial Network, GAN)
AIGC实战——WGAN(Wasserstein GAN)
文章出处登录后可见!