内容来源:@xiaohuggg
Distil-Whisper:比Whisper快6倍,体积小50%的语音识别模型
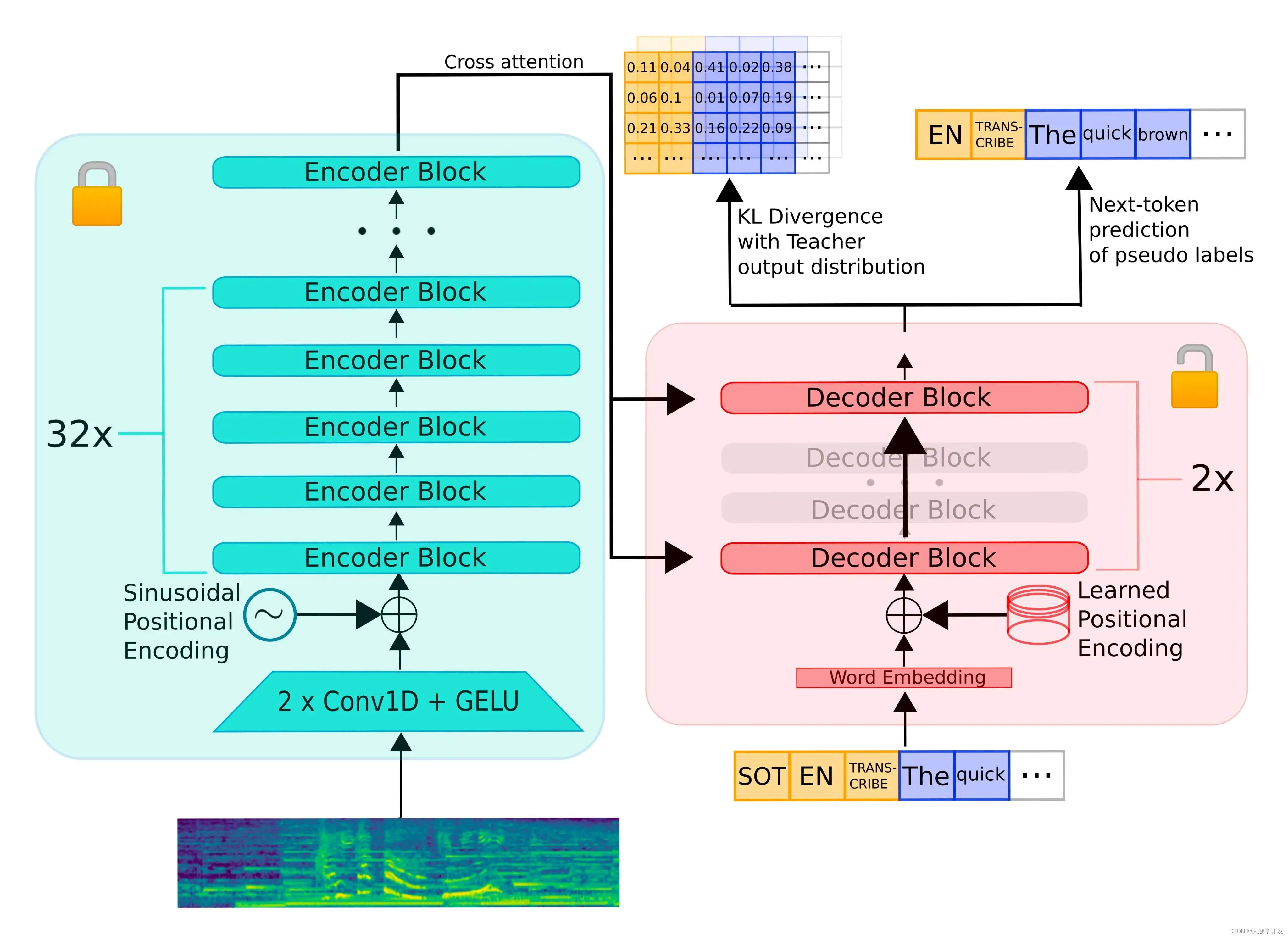
该模型是由Hugging Face团队开发,它在Whisper核心功能的基础上进行了优化和简化,体积缩小了50%。速度提高了6倍。并且在分布外评估集上的字错误率 (WER) 不超过 1%。
它还可以作为 Whisper 的助手模型用于推测性解码,速度提高了2倍。
主要优点:
速度 – Distil-Whisper 的推理速度是 Whisper 的 6 倍。
尺寸 – 模型大小减少了 49%,更适合资源有限的设备。
准确性 – 词错误率(WER)与 Whisper 相比只有 1% 的差距。
抗噪声 – 在嘈杂环境下仍能保持较高的识别准确性。
减少幻听 – 减少了重复词组的出现,并降低了插入错误率。
推测性解码 – 作为 Whisper 的辅助模型,推理速度提高了 2 倍。
主要方法:
Whisper模型是一个基于大规模弱监督数据训练的语音识别模型,具有1.5亿参数,并在680,000小时的语音识别数据上进行预训练,展现出在多个数据集和领域的强大泛化能力。然而,随着预训练语音识别模型大小的增加,将这些大型模型部署到低延迟或资源受限的环境中变得越来越困难。
为了解决这个问题,研究者们采用了伪标签方法来构建一个大规模的开源数据集(在 9 个不同的开源数据集上接受了 22,000 个小时的训练,涵盖 10 个域、超过 18,000 个说话者),并使用这个数据集来进行知识蒸馏,从而创建了Distil-Whisper模型。
研究者们使用了一个基于词错误率(WER)的启发式方法来筛选高质量的伪标签,以用于训练Distil-Whisper模型。
实验结果:
Distil-Whisper模型在保持原有 Whisper 模型核心功能的基础上,显著提高了处理速度。速度提高了5.8倍,参数减少了51%,并且在零样本迁移设置中对分布外测试数据的WER性能仅下降了1%。
这一速度的提升不仅意味着在相同的时间内可以处理更多的语音数据,而且对于那些需要快速响应的应用场景,如实时语音翻译、实时会议记录等,具有重要的实际意义。
在长音频评估中,Distil-Whisper的表现甚至超过了原始的Whisper模型,这主要是因为它在处理长形音频时产生幻听错误的倾向较低。
此外,Distil-Whisper与Whisper模型共享相同的编码器权重,这意味着它可以作为Whisper的辅助模型,用于推测性解码,从而实现了2倍的推理速度提升,同时确保预测结果与原始模型相同。这使得Distil-Whisper可以作为现有使用Whisper的语音识别管道的即插即用替代品。
由于模型更小,对计算资源的需求也相对较低,这使得它更适合在资源受限的设备上运行,例如在移动设备或边缘计算设备上。这种轻量级的设计也使得 Distil-Whisper 在网络带宽有限或计算能力受限的环境中更为实用。
模型下载:
https:https://huggingface.co/collections/distil-whisper/distil-whisper-models-65411987e6727569748d2eb6
论文:
https://arxiv.org/abs/2311.00430
GitHub:https://github.com/huggingface/distil-whisper
Colab:httphttps://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/Distil_Whisper_Benchmark.ipynbain/Distil_Whisper_Benchmark.ipynb
文章出处登录后可见!