
🏆 作者简介,愚公搬代码
🏆《头衔》:华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,51CTO博客专家等。
🏆《近期荣誉》:2022年CSDN博客之星TOP2,2022年华为云十佳博主等。
🏆《博客内容》:.NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。
🏆🎉欢迎 👍点赞✍评论⭐收藏
文章目录
- 🚀前言
- 🚀一、ElasticSearch的分词器
- 🔎1.分词器-介绍
- 🔎2.ik分词器安装
- 🦋2.1 环境准备
- 🦋2.2 安装IK分词器
- ☀️2.2.1 Liunx安装
- ☀️2.2.2 Docker安装
- 🦋2.3 使用IK分词器
- 🔎3.使用IK分词器-查询文档
- 🚀感谢:给读者的一封信
🚀前言
分词器是一种程序,用于将文本字符串分割成具有独立含义的单元。在自然语言处理中,分词器通常用于将连续的一段文本划分为句子、词语或字符。分词器的主要作用是将非结构化的文本数据转换为结构化的数据,以便进行各种形式的文本分析和处理,如文本搜索、信息检索、自然语言理解等。分词器可以基于规则、统计模型或深度学习等技术实现。
🚀一、ElasticSearch的分词器
🔎1.分词器-介绍
IKAnalyzer是一种开源的中文分词器,是Java语言编写的,并且是Lucene搜索引擎的中文分词器插件。IKAnalyzer使用了词典分词和规则分词相结合的方式进行中文分词,可以识别中文词语、英文单词、数字、日期、时间、量词等复杂的语言模式,适用于各种中文文本的分析和处理。IKAnalyzer还支持自定义词典,用户可以根据自己的需要添加、删除、修改词典,以达到更精准的分词效果。IKAnalyzer是一种稳定、高效、易用的中文分词器,广泛应用于自然语言处理、信息检索、文本挖掘等领域。
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/archive/v7.4.0.zip
注意:插件和ES版本需要匹配,不要用太新的版本
🔎2.ik分词器安装
🦋2.1 环境准备
Elasticsearch 要使用 ik,就要先构建 ik 的 jar包,这里要用到 maven 包管理工具,而 maven 需要java 环境,而 Elasticsearch 内置了jdk, 所以可以将JAVA_HOME设置为Elasticsearch 内置的jdk
1)设置JAVA_HOME
vim /etc/profile
# 在profile文件末尾添加
#java environment
export JAVA_HOME=/opt/elasticsearch-7.4.0/jdk
export PATH=$PATH:${JAVA_HOME}/bin
# 保存退出后,重新加载profile
source /etc/profile
2)下载maven安装包
wget http://mirror.cc.columbia.edu/pub/software/apache/maven/maven-3/3.1.1/binaries/apache-maven-3.1.1-bin.tar.gz
3)解压maven安装包
tar xzf apache-maven-3.1.1-bin.tar.gz
4)设置软连接
ln -s apache-maven-3.1.1 maven
5)设置path
打开文件
vim /etc/profile.d/maven.sh
将下面的内容复制到文件,保存
export MAVEN_HOME=/opt/maven
export PATH=${MAVEN_HOME}/bin:${PATH}
设置好Maven的路径之后,需要运行下面的命令使其生效
source /etc/profile.d/maven.sh
6)验证maven是否安装成功
mvn -v
🦋2.2 安装IK分词器
☀️2.2.1 Liunx安装
1)下载IK
wget https://github.com/medcl/elasticsearch-analysis-ik/archive/v7.4.0.zip
2)解压IK
由于这里是zip包不是gz包,所以我们需要使用unzip命令进行解压,如果本机环境没有安装unzip,请执行:
yum install zip
yum install unzip
解压IK
unzip v7.4.0.zip
3)编译jar包
# 切换到 elasticsearch-analysis-ik-7.4.0目录
cd elasticsearch-analysis-ik-7.4.0/
#打包
mvn package
4) jar包移动
package执行完毕后会在当前目录下生成target/releases目录,将其中的elasticsearch-analysis-ik-7.4.0.zip。拷贝到elasticsearch目录下的新建的目录plugins/analysis-ik,并解压
#切换目录
cd /opt/elasticsearch-7.4.0/plugins/
#新建目录
mkdir analysis-ik
cd analysis-ik
#执行拷贝
cp -R /opt/elasticsearch-analysis-ik-7.4.0/target/releases/elasticsearch-analysis-ik-7.4.0.zip /opt/elasticsearch-7.4.0/plugins/analysis-ik
#执行解压
unzip /opt/elasticsearch-7.4.0/plugins/analysis-ik/elasticsearch-analysis-ik-7.4.0.zip
5)拷贝辞典
将elasticsearch-analysis-ik-7.4.0目录下的config目录中的所有文件 拷贝到elasticsearch的config目录
cp -R /opt/elasticsearch-analysis-ik-7.4.0/config/* /opt/elasticsearch-7.4.0/config
记得一定要重启Elasticsearch!!!
☀️2.2.2 Docker安装
1、在线安装ik插件(较慢)
# 进入容器内部
docker exec -it elasticsearch /bin/bash
# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
#退出
exit
#重启容器
docker restart elasticsearch
2、离线安装ik插件(推荐)
1)查看数据目录
docker volume inspect es-plugins
显示结果:
[
{
"CreatedAt": "2022-05-06T10:06:34+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]
说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data 这个目录中。
2)解压缩分词器安装包
资源文件下载地址:https://download.csdn.net/download/aa2528877987/88596281?spm=1001.2014.3001.5503
解压缩,重命名为ik
3)上传到es容器的插件数据中
就是/var/lib/docker/volumes/es-plugins/_data :
4)重启容器
# 4、重启容器
docker restart es
# 查看es日志
docker logs -f es
3、扩展词汇
IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:
2)在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典-->
<entry key="ext_dict">ext.dic</entry>
</properties>
3)新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
小鱼
大雨
4)重启elasticsearch
docker restart es
# 查看 日志
docker logs -f es
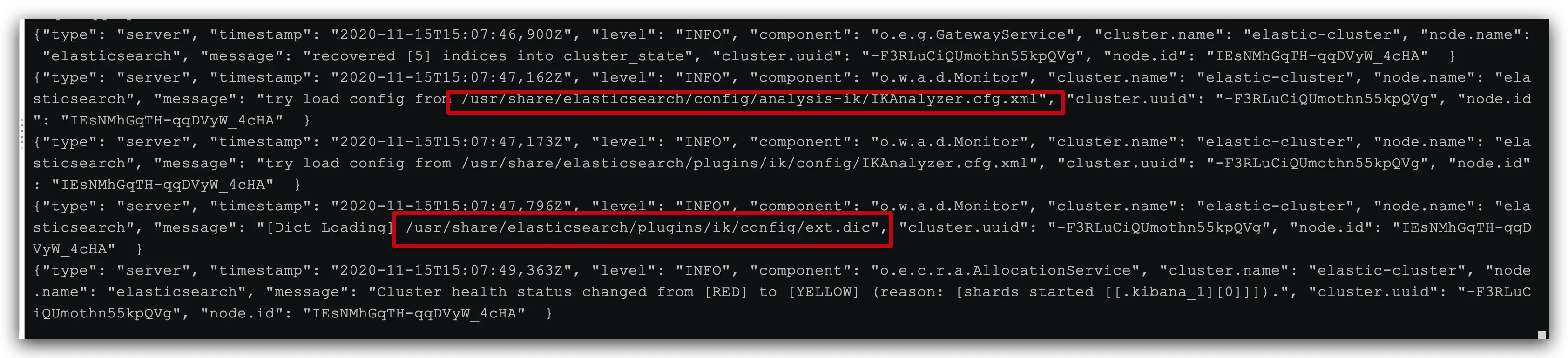
日志中已经成功加载ext.dic配置文件
5)测试效果:
GET /_analyze
{
"analyzer": "ik_max_word",
"text": " 小鱼大雨!"
}
注意当前文件的编码必须是 UTF-8 格式,严禁使用Windows记事本编辑,可以直接linux系统vi编辑
4、停用词汇
1)IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置-->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置-->
<entry key="ext_stopwords">stopword.dic</entry>
</properties>
3)在 stopword.dic 添加停用词
愚公
4)重启elasticsearch
# 重启服务
docker restart es
docker restart kibana
# 查看 日志
docker logs -f es
日志中已经成功加载stopword.dic配置文件
5)测试效果:
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "小鱼大雨!"
}
注意当前文件的编码必须是 UTF-8 格式,严禁使用Windows记事本编辑
🦋2.3 使用IK分词器
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
1、ik_max_word
会将文本做最细粒度的拆分,比如会将"乒乓球明年总冠军"拆分为乒乓球、乒乓、球、明年、总冠军、冠军”。
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "乒乓球明年总冠军"
}
ik_max_word分词器执行如下:
{
"tokens" : [
{
"token" : "乒乓球",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "乒乓",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "球",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "明年",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "总冠军",
"start_offset" : 5,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "冠军",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 5
}
]
}
2、ik_smart
会做最粗粒度的拆分,比如会将"乒乓球明年总冠军"拆分为乒乓球、明年、总冠军。
GET /_analyze
{
"analyzer": "ik_smart",
"text": "乒乓球明年总冠军"
}
ik_smart分词器执行如下:
{
"tokens" : [
{
"token" : "乒乓球",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "明年",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "总冠军",
"start_offset" : 5,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 2
}
]
}
注意:
执行如下命令时如果出现 打包失败(501码)将maven镜像换成阿里云的
mvn package
配置文件地址:/opt/apache-maven-3.1.1/conf/setting.xml
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
🔎3.使用IK分词器-查询文档
- 词条查询:term
- 词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时才匹配搜索
- 全文查询:match
- 全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集
1、创建索引,添加映射,并指定分词器为ik分词器
PUT person2
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"address": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
2、添加文档
POST /person2/_doc/1
{
"name":"张三",
"age":18,
"address":"北京海淀区"
}
POST /person2/_doc/2
{
"name":"李四",
"age":18,
"address":"北京朝阳区"
}
POST /person2/_doc/3
{
"name":"王五",
"age":18,
"address":"北京昌平区"
}
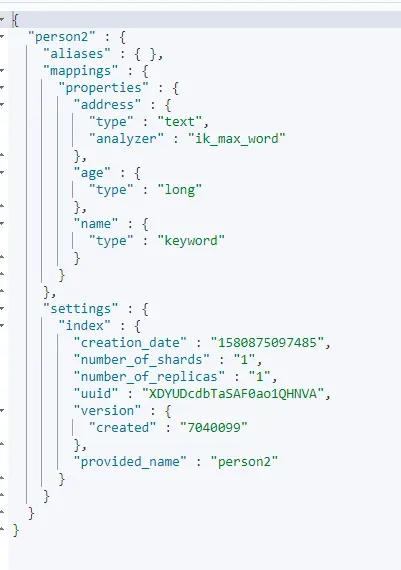
3、查询映射
GET person2
4、查看分词效果
GET _analyze
{
"analyzer": "ik_max_word",
"text": "北京海淀"
}
5、词条查询:term
查询person2中匹配到”北京”两字的词条
GET /person2/_search
{
"query": {
"term": {
"address": {
"value": "北京"
}
}
}
}
6、全文查询:match
全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集
GET /person2/_search
{
"query": {
"match": {
"address":"北京昌平"
}
}
}
🚀感谢:给读者的一封信
亲爱的读者,
我在这篇文章中投入了大量的心血和时间,希望为您提供有价值的内容。这篇文章包含了深入的研究和个人经验,我相信这些信息对您非常有帮助。
如果您觉得这篇文章对您有所帮助,我诚恳地请求您考虑赞赏1元钱的支持。这个金额不会对您的财务状况造成负担,但它会对我继续创作高质量的内容产生积极的影响。
我之所以写这篇文章,是因为我热爱分享有用的知识和见解。您的支持将帮助我继续这个使命,也鼓励我花更多的时间和精力创作更多有价值的内容。
如果您愿意支持我的创作,请扫描下面二维码,您的支持将不胜感激。同时,如果您有任何反馈或建议,也欢迎与我分享。

再次感谢您的阅读和支持!
最诚挚的问候, “愚公搬代码”
文章出处登录后可见!