AIGC之SD可控生成论文阅读记录
提示:本博客是作者本人最近对AIGC领域相关论文调研后,临时记录所用,所有观点都是来自作者本人局限理解,以及个人思考,不代表对。如果你也正好看过相关文章,发现作者的想法和思路有问题,欢迎评论区留言指正!
既然是论文阅读分享,首先,你需要有一些AIGC基础知识,许多基础概念我不会具体深入讲它是什么!
文章目录
- AIGC之SD可控生成论文阅读记录
- 1. ControlNet
- 2. T2I-Adapter
- 3. Composer
- 4. Diffusion-AE
- 5. Diffusion-Rig
- 6. Taming-Encoder
- 7. Paint by Example
- 8. GLIGEN
- 9. Improving Diffusion Models for Scene Text Editing with Dual Encoders
- 10. Training-Free Layout Control with Cross-Attention Guidance
- 11. Universal Guidance for Diffusion Models
- 总结
1. ControlNet
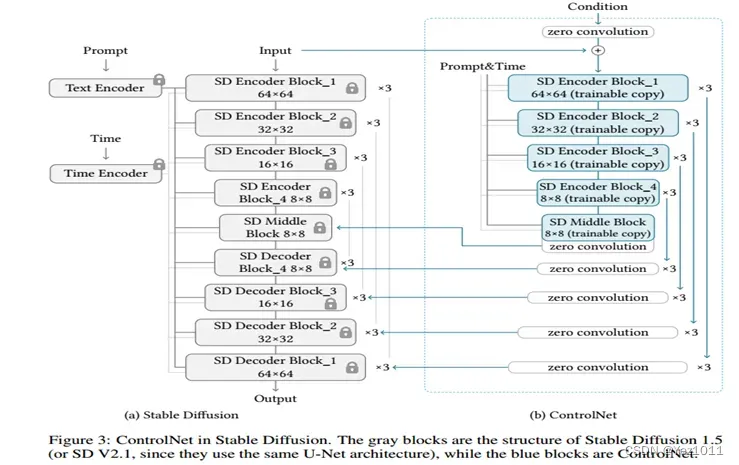
这篇文章在一个框架下统一了SD模型添加各种模态做受控生成的方法,包括但不限于Edge Map, Sketch, Depth Info, Segmentation Map, Human Pose, Normal Maps 等。9类!具体来说,对于预训练好的模型(比如作者使用SD1.5-UNet里Encoder和MidLayer的ResNet和Transformer层)里的一层结构, 作者固定了其参数,并将该层的输入额外添加了一个全联接映射后的条件c,输入到一个和该层结构一致的复制网络里,再映射一次后重新添加回原结构里的输出。按照作者的解释来看,这样做的好处有两个:一个是最大程度的保留原模型的生成能力,另一个是新添加的组件将以0值初始化所以在优化的初始阶段该模型的输出与原模型等价。
即对于一张模型生成的图片,其UNet的decoder一定已经包含了其生成的一些空间信息,语义信息等。直接抽取decoder相关的特征,添加到当前的生成能够影响当前生成的布局语义等。
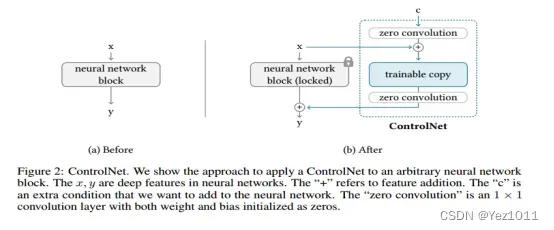
很想问具体融合方式?是否需要注意力?条件图类型不同照理说加法不同,但是作者给统一了。全部作为图像,做多尺度特征提取。
统一的条件:
-
作者所针对的每一个模态,都可以通过已有模型的基础上快速获得大量数据.(比如canny filter对edge的提取,midas对深度图的提取等)。类似于InstructPix2Pix这篇工作,针对当前任务造出一个百万级别大小的训练数据,可能是微调模型使其学到隐式关系的关键。
-
作者提出的架构和对额外模态的输入形式使得一个通用架构成为可能。在上面介绍结构时,笔者提到作者是针对UNet的前半部分里的每一层做额外信息添加和复制训练的。其中当然就包括了Resnet的卷积层。即无论什么模态的信息,作者的架构都可以把它作为图像通过UNet的encoder对其进行多尺度的信息特征的提取。大量参数(对Encoder+MidLayer的复制)加上大量训练数据加上适配的网络架构可能是其成功的关键。
-
对信息的添加及添加位置的选定。如果直观上来理解,在UNet的encoder阶段添加模态信息引导使得Decoder生成时考虑到相关添加信息当然符合直觉。但为何作者没有选定(只)在Transformer层这样的模态信息制导生成的关键位置添加模块,而是一视同仁且是在每一层的结尾做信息融合。
上面主要搬运自中森。
2. T2I-Adapter
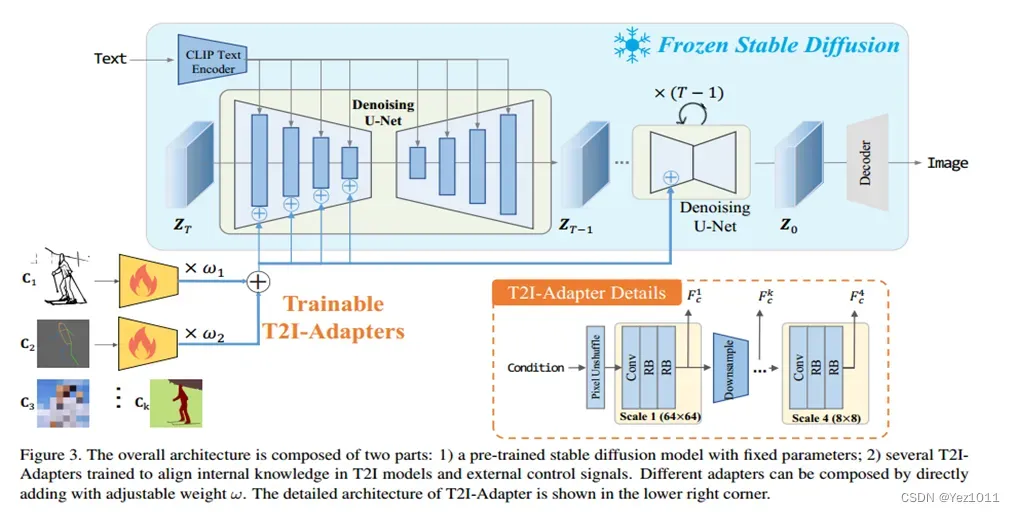
几乎跟Control-Net没区别,区别只有两点:
- T2I-Adapter可以同时组合输入多种类型的Condition,用超参数
控制的。
- T2I-Adapter是从SD的Encoder部分传入Condition的。
个人思考:
- 是否可以说明在加条件在编,解码器部分是都能成功的。
- 为啥上面这俩加条件都仅仅是堆叠,而不是做cross attention。
3. Composer

文章出处登录后可见!