


Lag-Llama: Towards Foundation Models for Time Series Forecasting
摘要
本文提出Lag-Llama,在大量时间序列数据上训练的通用单变量概率时间序列预测模型。模型在分布外泛化能力上取得较好效果。模型使用平滑破坏幂律(smoothly broken power-laws)。
介绍
目前任务主要集中于在相同域的数据上训练模型。当前已有的大规模通用模型在大规模不同数据上进行训练,展现出了极强的泛化能力。
本文训练了一个Transformer模型,使用大量时序数据进行训练并在未见过的数据集上进行测试。文章在Monash时序仓库上训练了Lag-Llama。
本文贡献:
- 提出了Lag-Llama,一个单变量概率时序预测模型。
- 在时序语料数据集上训练了LagLlama,并且Lag-Llama在未见过的数据集上进行零样本测试时,展现出了优于Baseline的效果。确定了一个“稳定”的制度。
- 将零样本测试性能的经验缩放定律拟合为模型大小的函数,允许潜在推断和预测模型外的泛化。
相关工作
本文与Time-LLM等的不同点在于,Lag-Llama使用了滞后特征。
本文与TimeGPT-1的不同点在于,TimeGPT-1使用了在不确定量化时使用了共形预测,而本文直接进行概率预测。
扩展模型和数据集大小被证明可以带来显著的迁移学习能力和新任务上出色的小样本学习能力。
在量化训练基础模型所需资源时,神经缩放定律可以通过模型大小、训练集大小、计算资源等来尝试预测神经网络性能。而本文采用了平滑破坏幂律来推断网络的非线性缩放行为。
概率时序预测
假定有训练数据集

在单变量概率时序预测问题中,希望能够在给定可观测过去和协变量的一维序列情况下,建模
本文从完整的时间序列中选择大小为
因此可以通过自回归模型建立一个概率的链式规则:
Lag-Llama
本文设定下的主要挑战:
- 本文模型仅限于单变量建模,因为对于时间序列分组而获得的多变量维度对每个数据集是不同的。
- 本文需要从每个数据集中进行采样,以便从所有数据集中学习表示,而不会从任何一个数据集中不成比例的采样。
由于使用Transformer架构,需要向量化输入,但时间序列频率不同。因此需要对单变量数据以能够表示数据频率的方法进行向量化。本文提出了一种通用方法用于向量化给定特定频率的的时间序列。
滞后特征
模型中所需的滞后协变量是通过目标值的的滞后特征,包括季度、月、周、天、小时和二级频率构建的。给定排序的滞后系数集合
一种向量化单变量序列的方法是使用潜在的重叠部分或具有一定大小和步长的片段,但是这种方法会导致向量中因果混合。
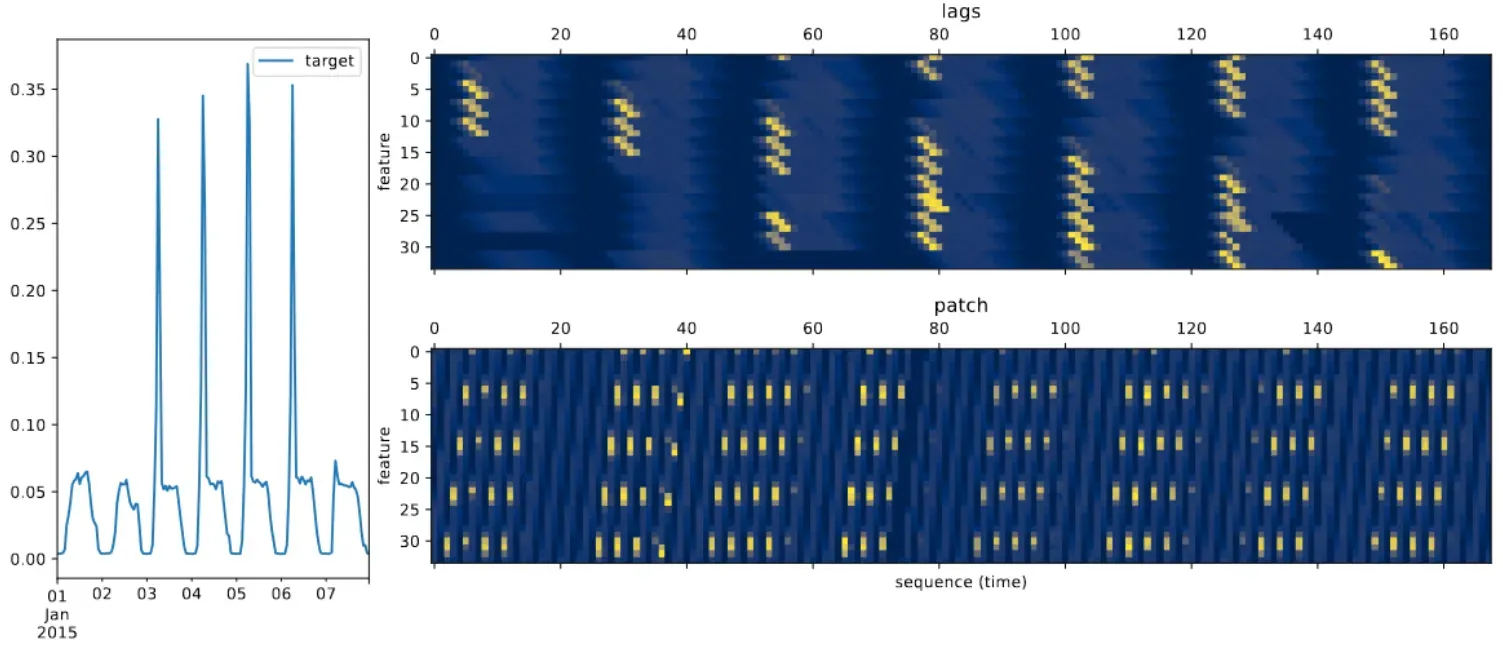

滞后系数直接对应于数据各种可能的季节性,并且能够保留日期时间指数因果结构。通过依赖滞后特征,可以在训练期间使用掩码解码器,在推理时使用自回归采样。但一个缺点是在推理时需要一个
Lag-Llama结构
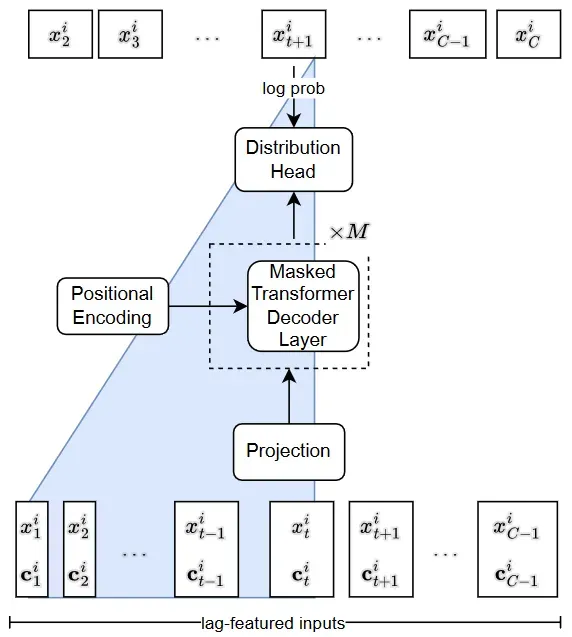

Lag-Llama基于Llama结构,并且通过RMS归一化整合了预归一化并且在每个Attention层的Q和K增加了旋转位置编码。以上是
一个长度为
在推断时,给定长度为
分布头的选择
分布头用于映射模型特征到参数的概率分布上。用不同表示能力的分布头来输出参数的概率分布。
值缩放
该模型中最大的挑战是如何处理不同数量级的数据。
通过计算平均值
数据增强
为了防止过拟合,使用了时间序列增强技术Freq-Mix和Freq-Mask,概率为0.5,增强率为0.1。为避免样本过多/过少,采用分层抽样并采用总时间步进行加权。
实验
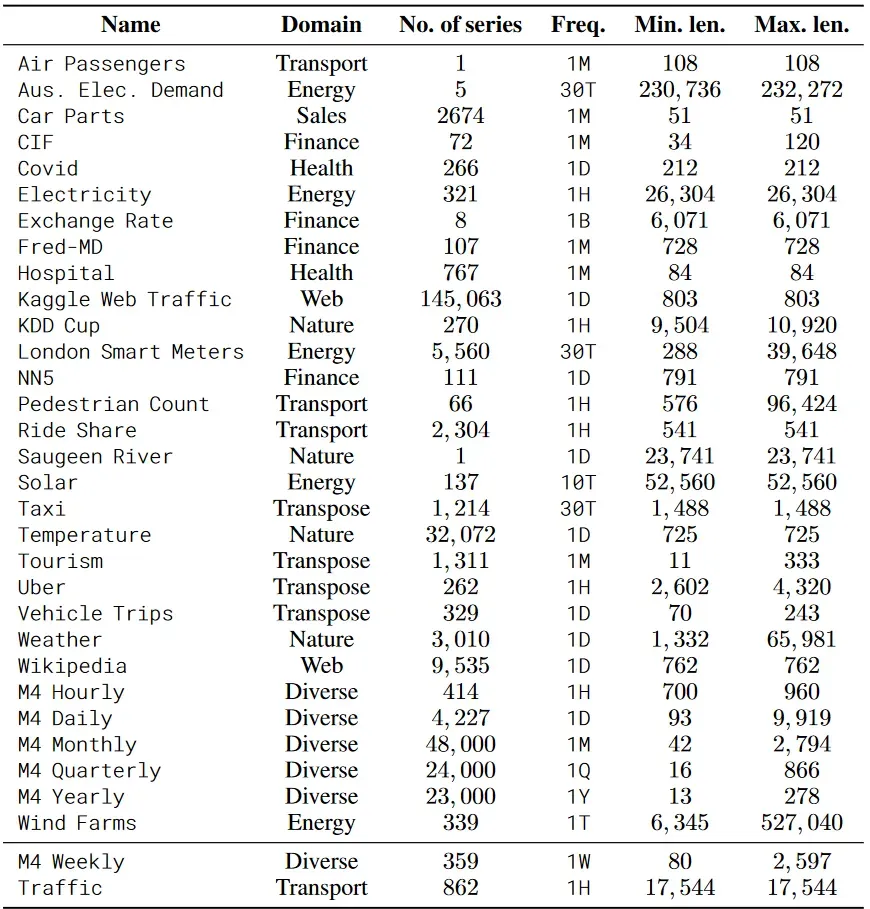
数据集
使用Monash Time Series Repository及来自不同领域的数据进行训练,使用M4 Weekly和Traffic数据集进行测试。其中测试数据集在训练时是不可见的并用来测试OOD性能。

模型训练
Batch_size 100,学习率 1e-3,50轮早停,每个epoch由100个窗口组成。早停由留出数据集的平均loss决定。
评估
使用CRPS(连续分级概率分数)按照分布进行评估:
实验结果
零样本性能
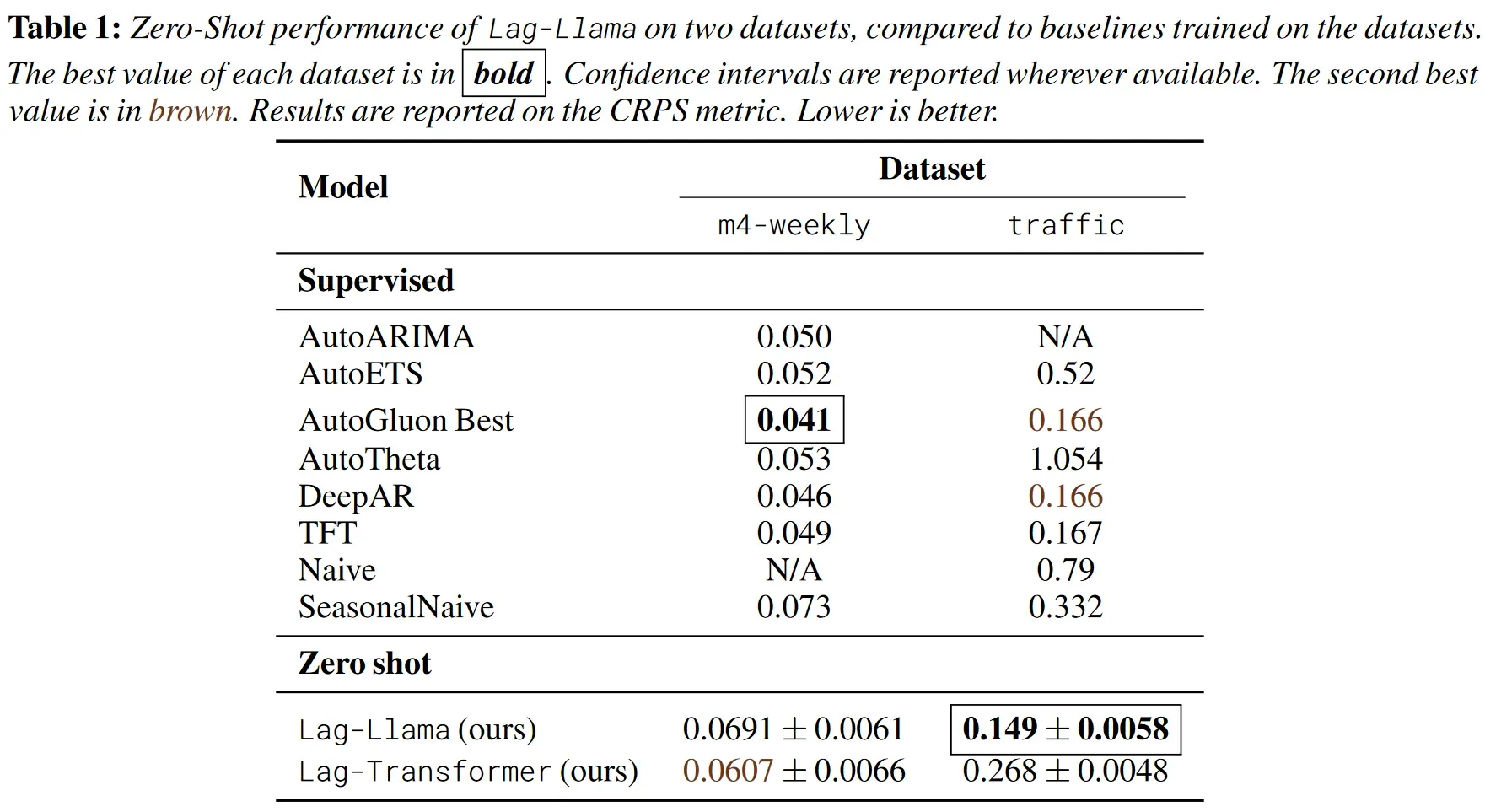

所有Baseline都是独立进行监督学习,然后再对应的测试集上进行测试。Lag-Llama和Lag-Transformer是在时序语料上进行训练,然后再两个测试数据集上进行测试。
窗口大小设置
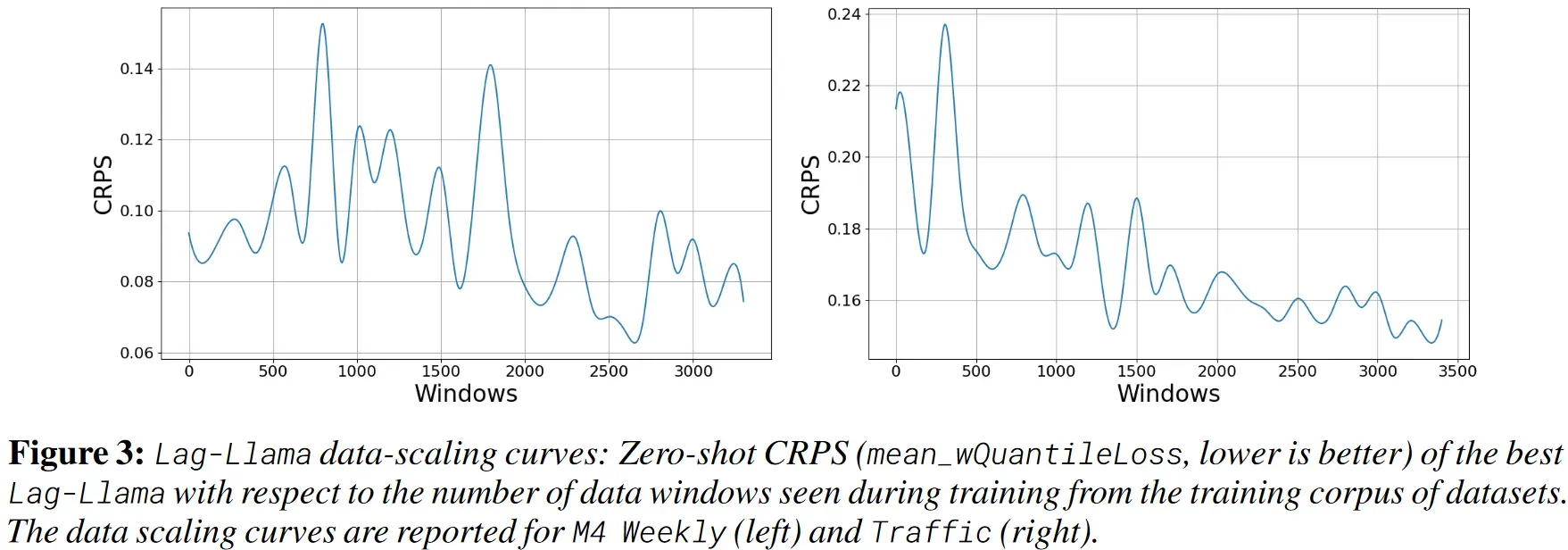

随着窗口大小增加,Lag-Llama在两个数据集上实现了更好的零样本性能。
模型参数量
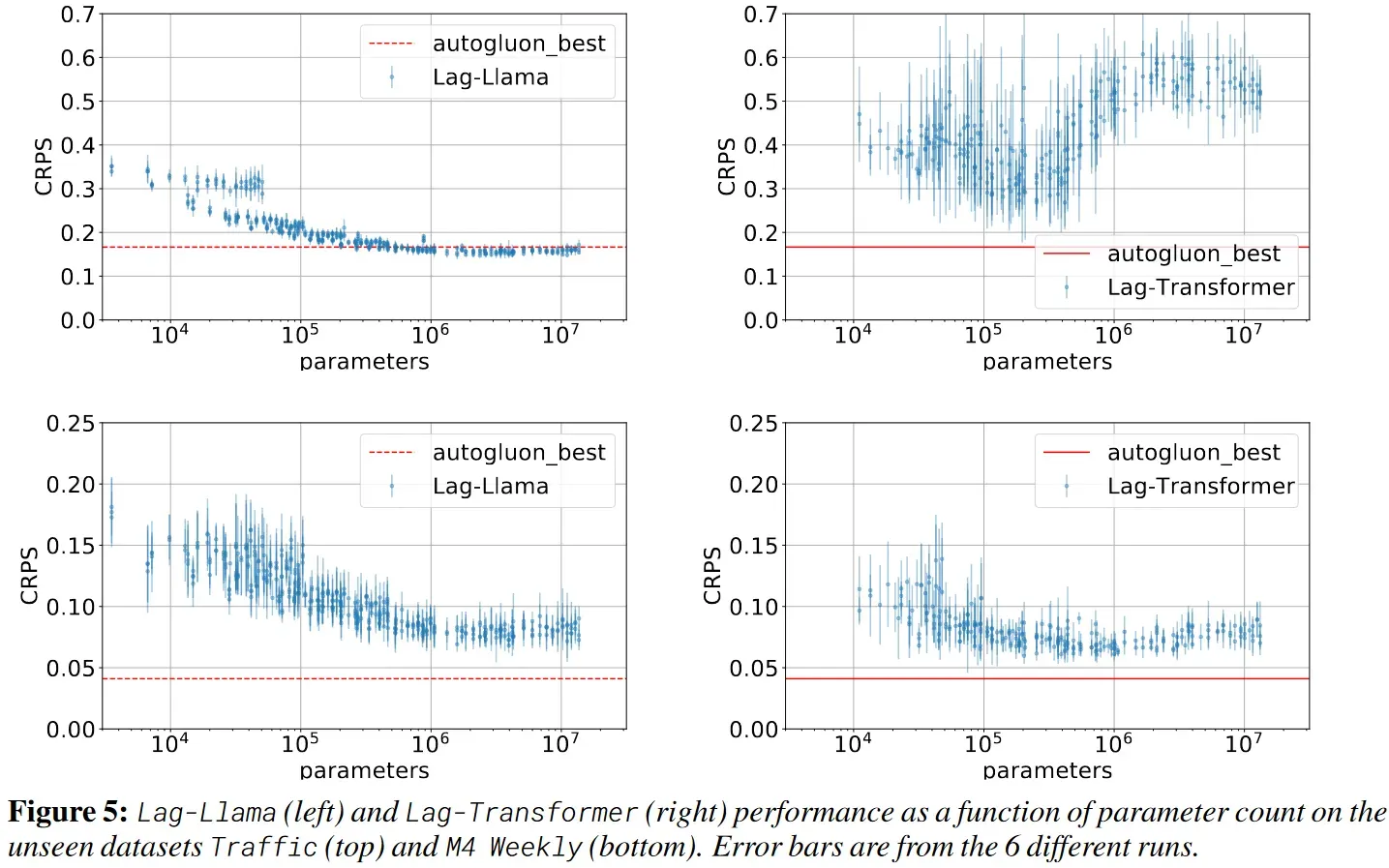

测试了在不同模型参数量下Lag-Llama的性能,可以发现在
缩放定律
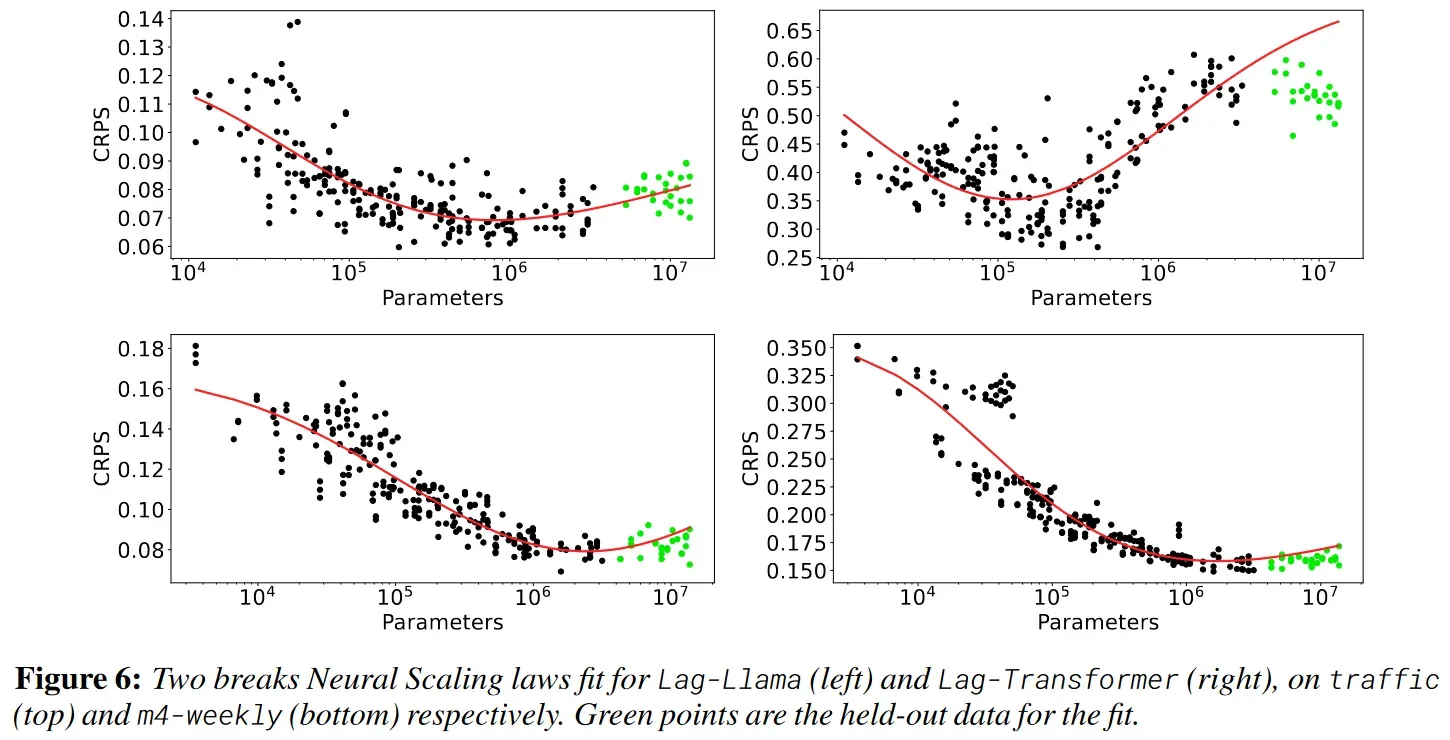

拟合缩放定律可能可以实现进一步的外推。
Broken Neural Scaling Law:
其中,
同时本文没有选择break数量,而是使用n阶最小二乘法来拟合85%的数据,然后选择使随后5%数据的RMSE最小化的n
文章出处登录后可见!