总而言之:
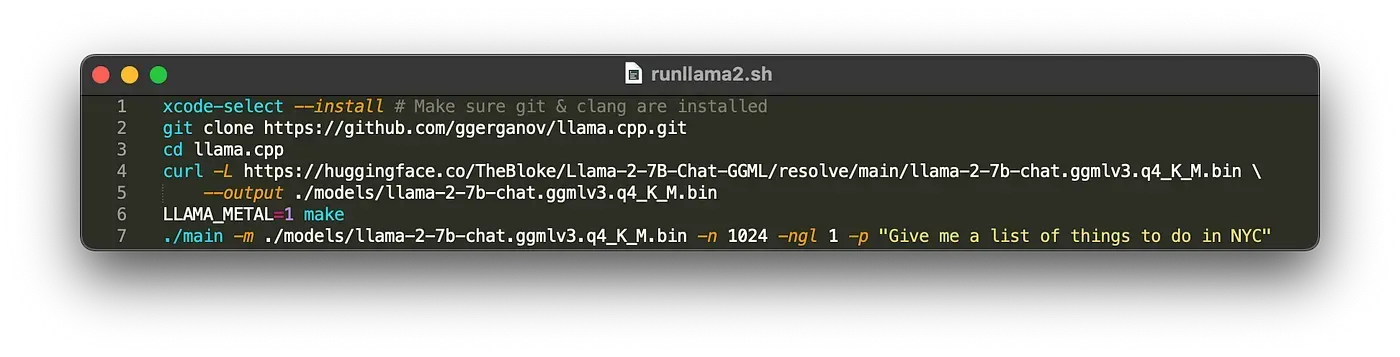
xcode-select --install # Make sure git & clang are installed
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
curl -L https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/resolve/main/llama-2-7b-chat.ggmlv3.q4_K_M.bin --output ./models/llama-2-7b-chat.ggmlv3.q4_K_M.bin
LLAMA_METAL=1 make
./main -m ./models/llama-2-7b-chat.ggmlv3.q4_K_M.bin -n 1024 -ngl 1 -p "Give me a list of things to do in NYC"
注意:7B 型号重量约为 4GB,请确保您的机器上有足够的空间。
这是在做什么?
这是使用 Georgi Gerganov 令人惊叹的llama.cpp项目来运行 Llama 2。它通过TheBloke的 Huggingface 存储库为 Llama 7B Chat 下载一组 4 位优化的权重,将其放入 llama.cpp 中的模型目录中,然后使用 Apple 的 Metal 优化构建 llama.cpp。
这允许您以最少的工作在本地运行 Llama 2。7B 权重应该适用于具有 8GB RAM 的机器(如果您有 16GB 则更好)。13B 或 70B 等较大型号将需要更多的 RAM。
请注意,Llama 2
文章出处登录后可见!
已经登录?立即刷新