一、环境部署(云部署)
AOTUDL 云部署
1.算力市场选用RTX3090/RTX A5000
2.点击算法镜像noval ai 3.0和Lora scripts
配置python环境及其他
3.启动stable diffusion和Lora scripts
4.装配模型:可在如Civitai上下载标注有CKPT的模型,有模型才能作画。下载的模型放入下载后文件路径下的models/Stable-diffusion目录。
5.Stable Diffusion 可配置大量插件扩展,在 webui 的“扩展”选项卡下,可以安装插件:

6.点击“加载自”后,目录会刷新,选择需要的插件点击右侧的 install 即可安装。
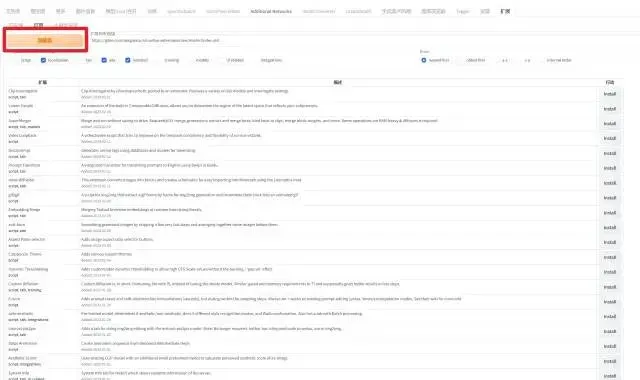
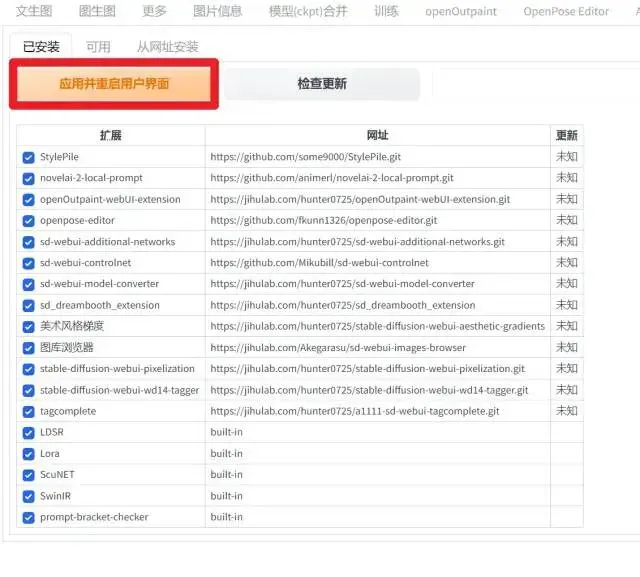
安装完毕后,需要重新启动用户界面:
文生图最简流程
选择需要使用的模型(底模),这是对生成结果影响最大的因素,主要体现在画面风格上。
1.在第一个框中填入提示词(Prompt),对想要生成的东西进行文字描述

2.在第二个框中填入负面提示词(Negative prompt),你不想要生成的东西进行文字描述

3.选择采样方法、采样次数、图片尺寸等参数。
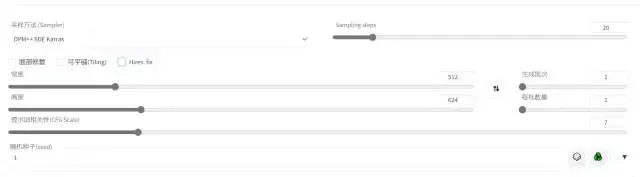
4.高清修复:

5.面部修复:修复画面中人物的面部,但是非写实风格的人物开启面部修复可能导致面部崩坏。
图片预处理
1.图片选择高清图片,数量20-30,剪裁为512*768
2.在训练里进行预处理,勾选上deepbooru生成说明文tags
3.创建训练集
脚本训练
使用Lora scripts修改参数保存,运行bash train.sh
生成Lora模型
1.将模型保存至models/Stable-diffusion/lora
2.使用lora-block-weight插件对lora不同层进行调整的方法,并提供了测试例子
生成作品
文章出处登录后可见!
已经登录?立即刷新