图像生成模型简介
图片生成领域来说,有四大主流生成模型:生成对抗模型(GAN)、变分自动编码器(VAE)、流模型(Flow based Model)、扩散模型(Diffusion Model)。
从2022年开始,主要爆火的图片生成模型是Diffusion Model(扩散模型)为主。
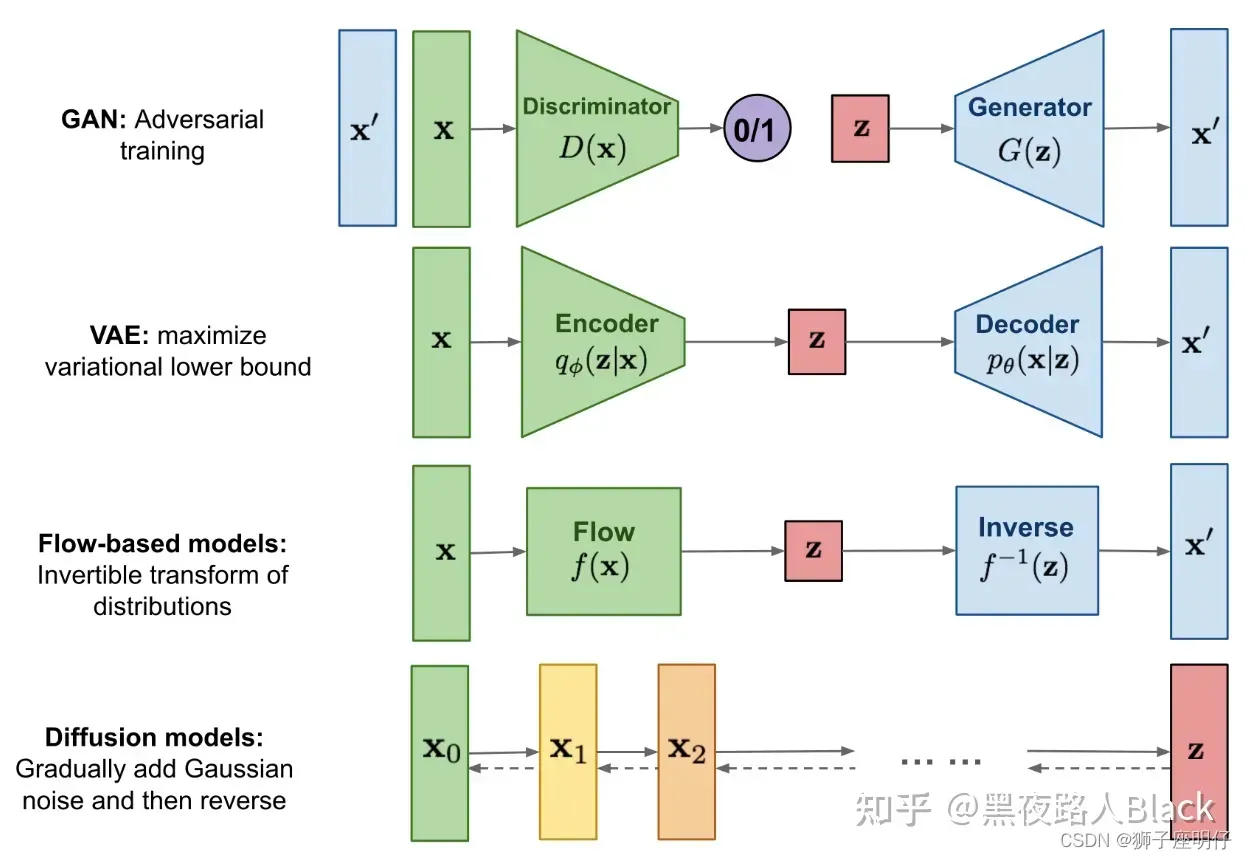
Diffusion Model:扩散模型,当前DALL-E, Midjourney, Stable Diffusion图片生成的核心都是Diffusion Model,它就是通过不停去除噪音期望获得好结果的生成模型。

早期的扩散模型在AI绘画中效果不好,而且单张图生成需要10-15分钟,后来英国 Stability AI 公司对模型进行了改进并开源,把图片生成稳定性和质量都大幅提高,图片生成速度提高了100倍,意味着以前需要10-15分钟(600-900秒)现在只需要6-10秒就可以生成一张图。
在Stable Diffusion(稳定扩散模型)出现之前,是有一个稳定扩散模型(Latent Diffusion),是Latent Difusion论文中的text2image模型。
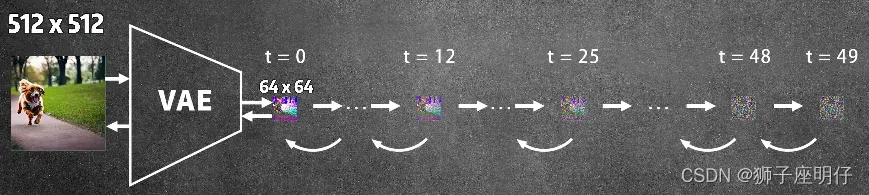
Latent Diffusion Model: 潜在扩散模型,是扩散模型的一种变体,最大的区别是,它把图片压缩,降维,压缩后的空间叫Latent Space(潜在空间或隐空间),这样可以大幅减少计算量,有了这个技术我们才可以在普通GPU上生成图片。另外,Diffusion model不仅可以生成图像,还可以生成音频、视频。
Stability Al改进了Latent diffusion,新模型叫做 Stable Diffusion。改进点包括:
(1) 训练数据:Latent diffusion是采用laion-400M数据训练的,而Stable diffusion是在laion-2B.en数据集上训练的,明显后者用了更多的训练数据,而且后者也采用了数据筛选来提升数据质量,比如去掉有水印的图像以及选择美学评分较高的图像
(2) text-encoder:Latent diffusion采用一个随机初始化的transformer来编码text,而Stable difusion采用一个预训练好的CLIP text encoder来编码text,预训练的text model往往要优于从零开始训练的模型
(3) 训练尺寸:Latent diffusion只是在256×256分辨率上训练,而Stable diffusion先在256×256分辨率上预训练,然后再在512×512分辨率上Finetune
总结:Stable diffusion使用了更好的text encoder在更大的数据集上训练,并且能生成更高分辨率图像,所以目前图片生成效果 Stable Diffusion更好。
Stable Diffusion推理过程

更细化的推理过程:

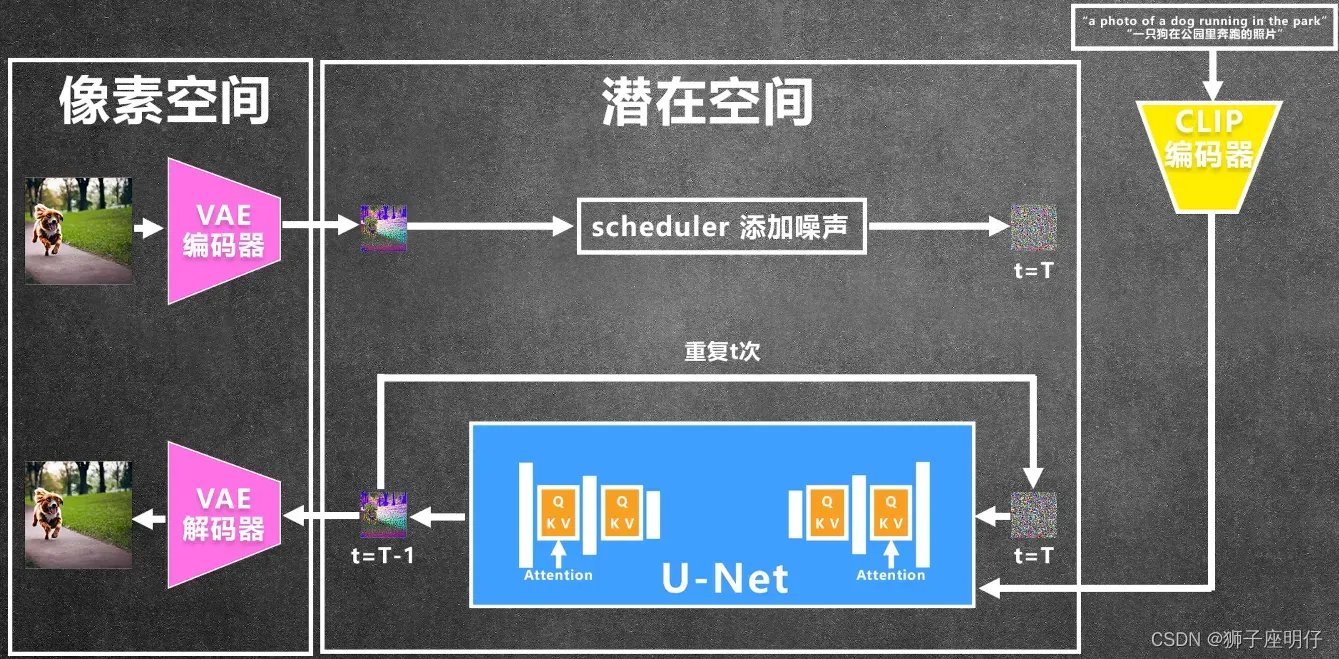
过程:prompt text(cat girl) -> CLIP -> text embedding -> diffusion(U-Net + Scheduler)-> VAE -> generate image
Stable Diffusion底层工作机制
Step 1. 输入提示词,解析提示词:文本图片编码器CLIP
Step 2. 基于提示词表征生成图像表征:基于U-Net的Diffusion过程(U-Net + Scheduler)
Step 3. 图片输入输出的处理转换:VAE(图像解码器负责latent space到pixel space的图像生成)
下面分别解析每一步骤的原理。
CLIP
CLIP(Contrastive Language-Image Pre-training): 图文对比学习的预训练模型

CLIP不是完全的理解语义,只是想个方法把文字和图像对应起来:
文本编码为text embedding只是CLIP的中间产物。
CLIP的训练集:

训练集:400 million image-text pairs(4亿)
训练过程
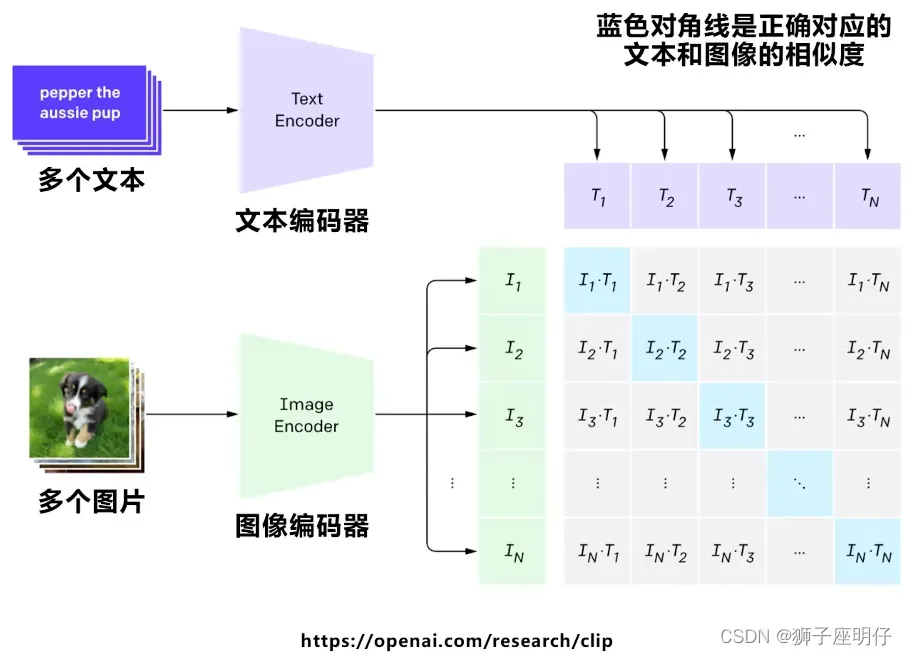
同一个batch里面对比学习,对角线为正样本,其他的均为负样本,CLIP的训练目标就是最大 N 个正样本的相似度,同时最小化 N^2 – N 个负样本的相似度。
这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系:同义的图文对得分高,不同的得分低。
简单说:就是把文字和图片放到一个矩阵空间里,用来解决文本到图片的映射和相似性交集,方便通过文本找到对应图像的分布。
trick:batch越大训练效果越好。

需要多大CLIP模型?
论文:《Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding》
paper:https://arxiv.org/abs/2205.11487

说明:FID↓ CLIP Score ↑
增加语言模型的encoder大小比增加图像扩散模型的大小更能提高图像-文本对齐。
FID(Fréchet Inception Distance)
paper:https://arxiv.org/abs/1706.08500
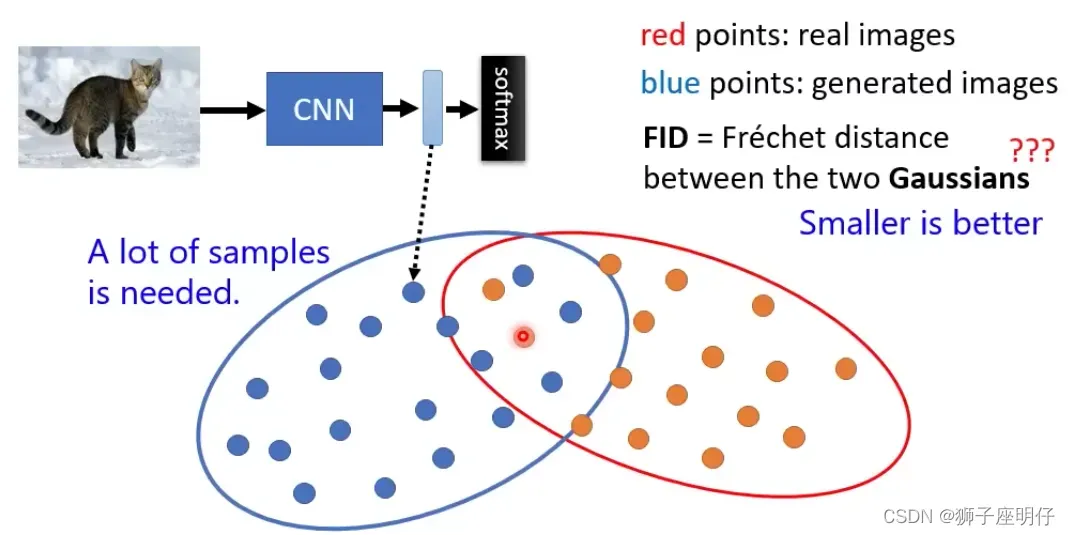
FID是度量真实图像和生成图像的特征分布(假设是高斯分布)的距离,要求需要很多特征分布(FID-10K是10K张图),FID得分越小越好,代表生成的图越像真图。
Diffusion Model
基于Diffusion Model的思路实现DDPM(Denoising Diffusion Probabilistic Models,去噪扩散概率模型)。
DDPM就是通过对数据不断加噪成为真实噪声,和从真实噪声不断去噪还原成原始数据的过程中,学习到去噪的过程,进而就能对真实噪声进行随机采样,还原(生成)成各式各样的数据了。

前向过程(forward process,也叫扩散过程diffusion process)是指的对数据逐渐增加高斯噪音直至数据变成随机噪音的过程。
反向过程(reverse process 逆向过程)是一个去噪的过程,如果我们知道反向过程的每一步的真实分布,那么从一个随机噪音开始,逐渐去噪就能生成一个真实的样本,所以反向过程也就是生成数据的过程。
为啥要加噪声,为啥一步一步加噪声?
1)直接移除像素会导致信息丧失,添加噪声可以让模型学习到图片特征;
2)随机噪声还可以增加模型生成时的多样性;
3)一步一步的来可以控制这一过程,同时提供了去噪过程中的稳定性
每一步要加多少噪声?
这个根据schedule来,一般先少后多比较好,图片特征损失的比较慢

去噪的过程,可以类比为雕刻,米开朗基罗说:塑像本来就在石头里,我只是把不需要的部分去掉。
如何训练?
直接把随机噪声分step的添加到图片,这个过程就叫diffusion process(也叫Forward process,扩散/加噪),每个step就有ground truth的图片,训练模型还原图片。
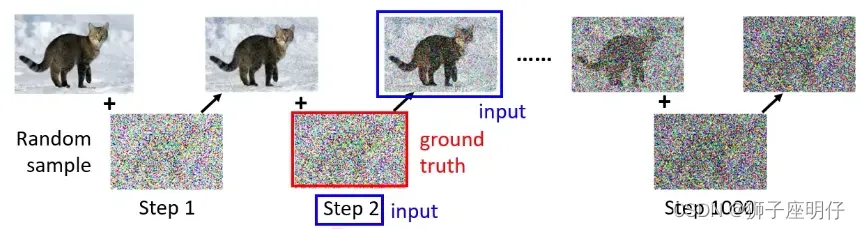
还原图片的过程:
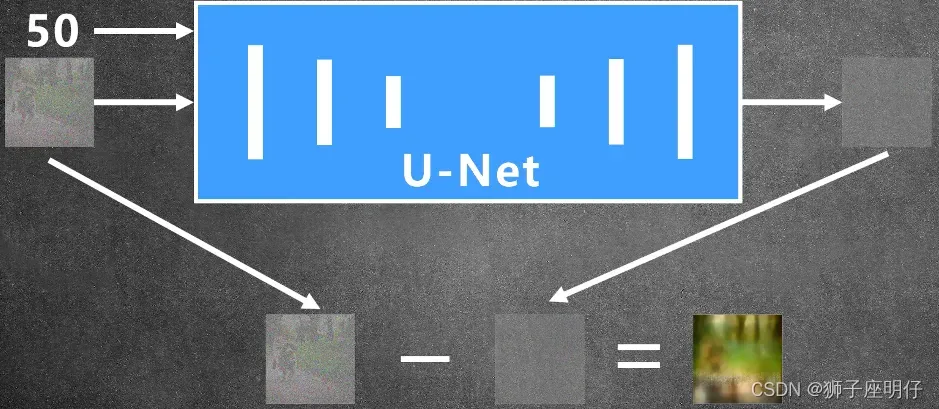
1)输入原图(覆盖了step=50的noise)和step=50,用U-Net预测图片的noise,这里每个step都共用相同的U-Net
2)噪声很多时,U-Net无法预测精准的图片细节,只能预测很模型的图片大概轮廓

3)这样不断重复预测,直到得到原图
实际DDPM的加噪过程是不需要逐步处理,可以一次把指定step的高斯噪声加到位,然后逐步预测噪声。
论文:《Denoising Diffusion Probabilistic Models》
paper: https://arxiv.org/abs/2006.11239

论文:《Understanding Diffusion Models: A Unified Perspective》
paper:https://arxiv.org/abs/2208.11970
噪声采样方案
扩散模型很大的过程在于噪音的采样,模型采样需要从纯噪声图片出发,一步一步不断地去噪,最终得到清晰的图片。在这个过程中,模型必须串行地计算至少 50 到 100 步才可以获得较高质量的图片,这导致生成一张图片需要的时间是其它深度生成模型的 50 到 100 倍,极大地限制了模型的部署和落地。
这些采样过程,映射到Stable Diffusion里主要就是一个个 Scheduler,在 Stable Diffusion 中 Scheduler(调度)的主要作用是按照当前生成噪音是第几步(Step)然后输出生成图片噪声的系数,它简单计算公式是:( 图像噪声 = 随机生成噪声 * scheduler输出的系数 )。
在采样频次和速度的驱动要求下,扩散模型很重要的是加噪和去噪的采样方案,包括 DDPM、DDIM、PLMS 、DPM-Solver 等等。
DDPM(Denoising Diffusion Probabilistic Model)默认采用的是线性的加噪采样方案 (linear schedule)。
DDIM(Denoising Diffusion Implicit Models,去噪扩散隐式模型),DDIM和DDPM有相同的训练目标,但是它不再限制扩散过程必须是一个马尔卡夫链,这使得DDIM可以采用更小的采样步数来加速生成过程,DDIM的另外是一个特点是从一个随机噪音生成样本的过程是一个确定的过程。
DPM-Solver(Diffusion Process Model Solver,扩散处理模型求解器)是清华大学朱军教授带领的TSAIL团队所提出的,一种针对于扩散模型特殊设计的高效求解器:该算法无需任何额外训练,同时适用于离散时间与连续时间的扩散模型,可以在 20 到 25 步内收敛,并且只用 10 到 15 步也能获得非常高质量的采样。在 Stable Diffusion 上,采样速度翻倍。
图片生成过程加入Text embedding
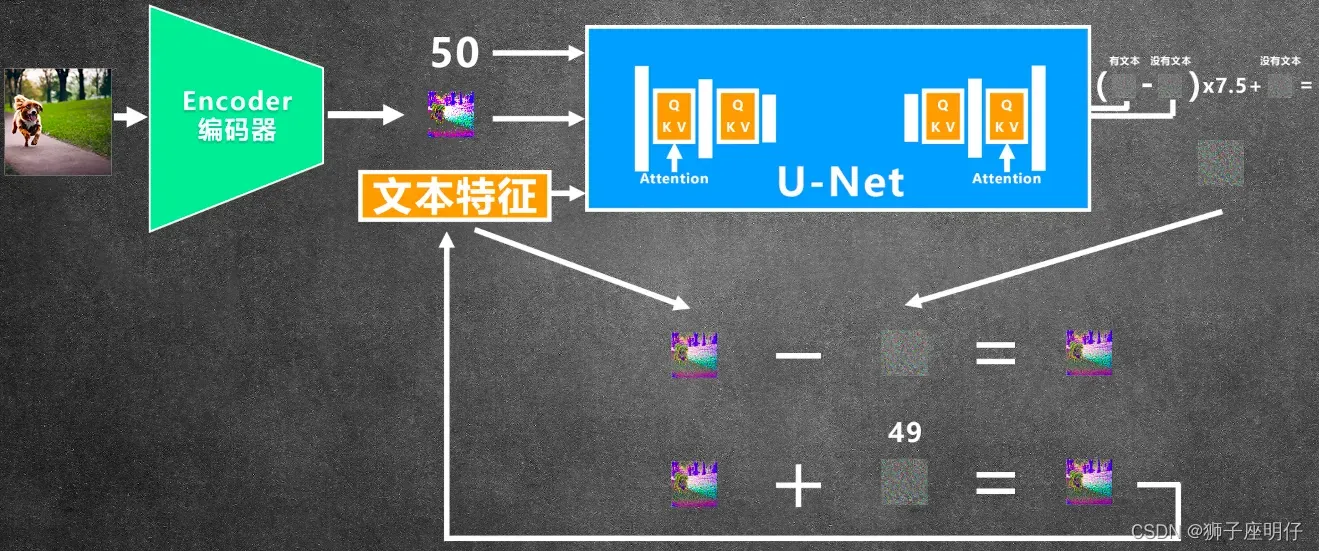
1)U-Net为了融入文本特征,网络结构里面补充了attention机制(QKV)
![]()
2)为了强化文本引导作用,这里用到了classifier free guidance的方法,这里的7.5参数就是guidance scale
不同guidance scale的图片效果:

扩散模型的核心就在于训练噪音预测模型,由于噪音和原始数据是同维度的,所以我们可以选择采用AutoEncoder架构来作为噪音预测模型。DDPM所采用的模型是一个基于residual block和attention block的U-Net模型。
Unet是2015年《U-Net: Convolutional Networks for Biomedical Image Segmentation》提出的模型。
UNet就是一个语义分割模型,其执行过程:
首先利用卷积进行下采样,然后提取出一层又一层的特征,利用这一层又一层的特征,其再进行上采样,最后得出一个每个像素点对应其种类的图像。
U-Net网络结构:
Unet的优势:
1. 网络层越深得到的特征图,有着更大的视野域;
2. 浅层卷积关注纹理特征,深层网络关注本质特征,所以深层浅层特征都有意义;
3. 通过反卷积得到的更大的尺寸的特征图的边缘,是缺少信息的,毕竟每一次下采样提炼特征的同时,也必然会损失一些边缘特征,而失去的特征并不能从上采样中找回,因此通过特征拼接,来实现边缘特征找回;
4. Unet简单、高效、易懂、容易构建,可以从小数据集构建,在diffusion model中简单好用。
VAE
VAE的作用:性能友好,可以在潜在空间插值和操作,控制图像生成

这里的编码器encoder和解码器decoder不是把图像缩小、放大,而是把图像做了编码,举个例子,音乐编码为乐谱,再通过乐谱演奏出乐曲,这里可以类比把声音编码为乐谱了。
VAE的结构
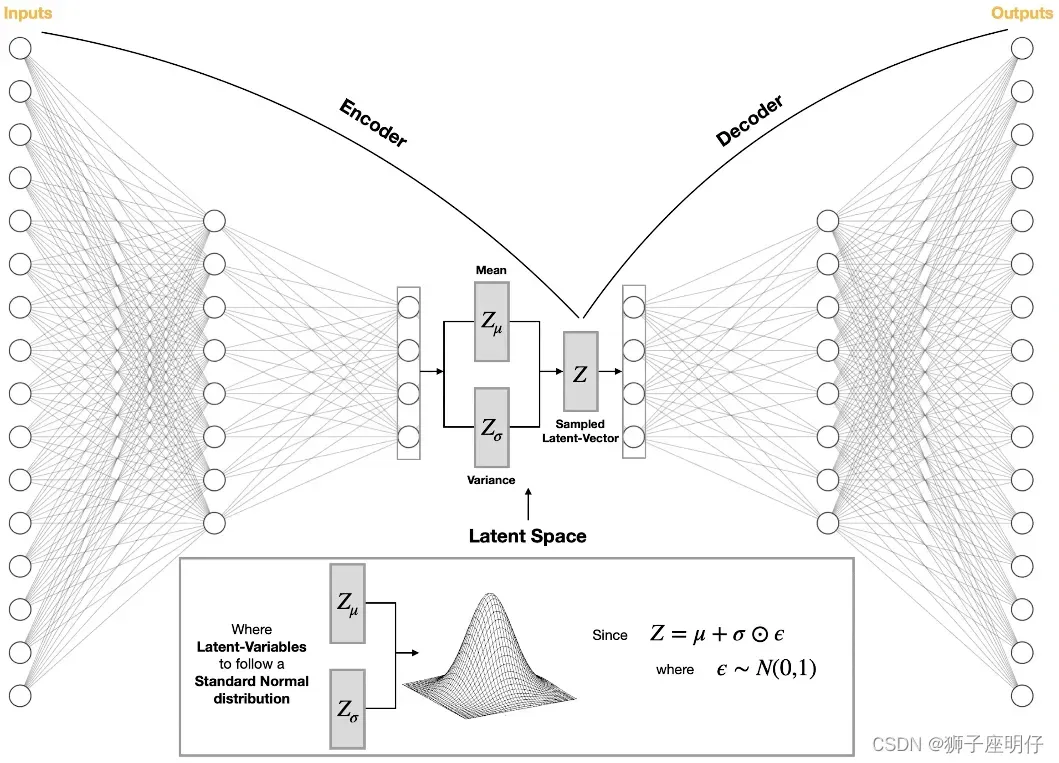
在编码器的训练过程中,VAE通过最小化重构误差来学习如何将输入数据映射到潜在空间中的概率分布。
在解码器的训练过程中,VAE通过最小化KL散度来学习如何从潜在空间中的随机向量生成原始数据。
VAE vs Diffusion Model:
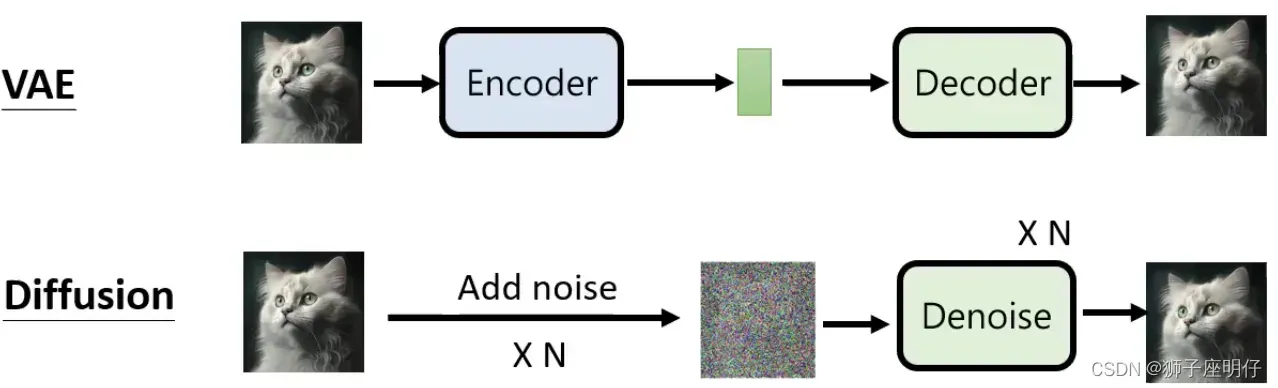
VAE 的encoder是学习一个概率分布,所以VAE也可以随机采样生成图片,但VAE图片还原效果很弱,生成的图像模糊,效果不如diffusion model
VAE的好处:减少训练和推理时间,降低GPU硬件要求
原图512x512x3->压缩到64x64x4,Stable Diffusion用的是KL-f8的VAE,下采样系数为8,缩小了48倍
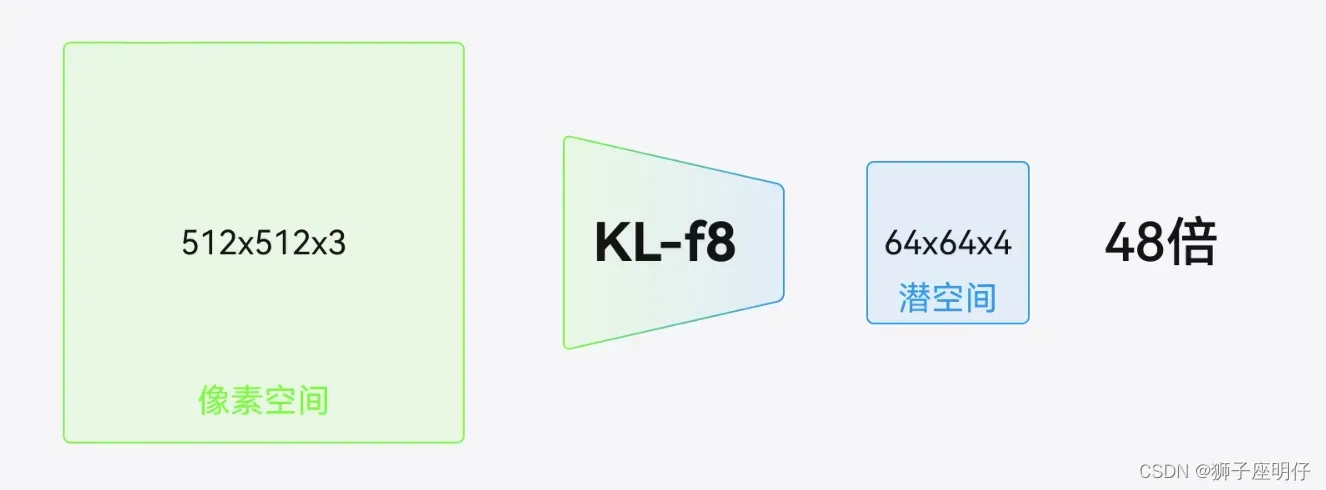
VAE的坏处:是压缩后再还原,图片细节会损失掉
Stable Diffusion的结构
Latent diffusion的论文:《High-Resolution Image Synthesis with Latent Diffusion Models》
paper:https://arxiv.org/abs/2112.10752

拆分解释:

Latent Diffusion Models整体框架如图,首先需要训练好一个自编码模型(AutoEncoder,包括一个编码器 E 和一个解码器 D )。这样一来,我们就可以利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后我们再用解码器恢复到原始像素空间即可,论文将这个方法称之为感知压缩(Perceptual Compression)。
Stable Diffusion的Control方法
Textual Inversion

调整CLIP让它输出符合新图片的文本特征,如双耳铃铛闹钟,迪迦奥特曼,只需要保存学习到的特征。
ControlNet

训练一个新的网络去调整U-Net的resnet block,这个新网络可以输入那些用来作为控制条件的图像,如canny线稿、骨骼图等。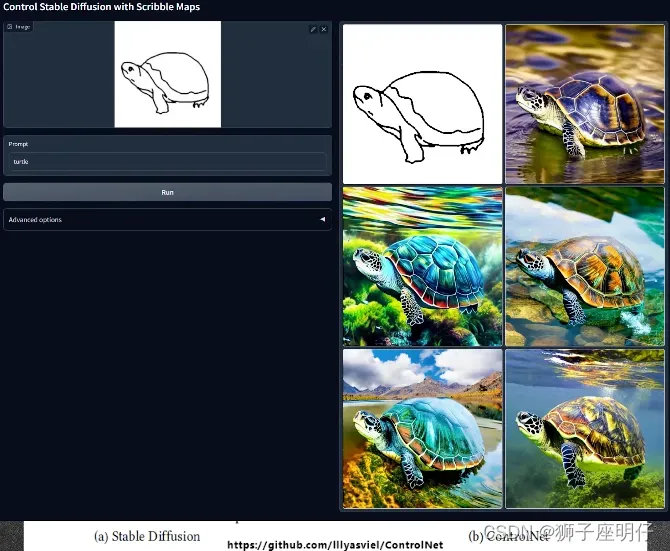
结论
Diffusion Model 与常规过去的GAN、VAE、Flow 等常见的生成模型的机制不同,它是采用从高斯噪音中逐步依照一定条件 “采样” 特殊的分布,随着“采样”轮次的增加最终得到生成图片。 换句话说,Diffusion Model 的合成过程是通过一次次迭代在噪声中提取出所需要的图像,随着迭代步数的增加,合成质量也在越来越好 。
这种机制的好处是显而易见的,合成质量和合成速度之间变得可控了。当时间宽裕时可以通过高轮次的迭代获得高质量的合成样本,同时较低轮次的快速合成也可以得到没有明显瑕疵的合成样本。而高低轮次迭代之间完全不需要重新训练模型,只用手动调整一些轮次相关的参数。
这听起来有点匪夷所思,但其背后有着极强的数学逻辑支撑。这些数学主要就是马尔科夫链和朗之万公式。
参考文献
英文
Latent Diffusion论文:https://arxiv.org/pdf/2112.10752.pdf
Diffusion Models详细公式:What are Diffusion Models? | Lil’Log
各种微调模型方法对比:https://www.youtube.com/watch?v=dVjMiJsuR5o
Scheduler对比图来自论文: https://arxiv.org/pdf/2102.09672.pdf
柯基图来自DALLE2论文:https://cdn.openai.com/papers/dall-e-2.pdf
CLIP模型的介绍:https://github.com/openai/CLIP
OpenCLIP:https://github.com/mlfoundations/open_clip
Textual Inversion: An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
LoRA论文:https://arxiv.org/pdf/2106.09685.pdf
Dreambooth 论文:https://arxiv.org/pdf/2208.12242.pdf
ControlNet 论文:https://arxiv.org/pdf/2302.05543.pdf
简单易懂的 Diffusion Model 解释:https://www.youtube.com/watch?v=1CIpzeNxIhU
很棒的Stable Diffusion解释:The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
同样很棒的SD解释:https://medium.com/@steinsfu/stable-diffusion-clearly-explained-ed008044e07e
GLIDE论文:https://arxiv.org/abs/2112.10741
CLASSIFIER-FREE DIFFUSION GUIDANCE论文:https://arxiv.org/pdf/2207.12598.pdf
中文
Stable Diffusion UNET 结构:Stable Diffusion UNET 结构 – 知乎
LoRA应用心得:你真的会用LORA吗?超详细讲解LORA分层控制 – 知乎
很棒的Stable Diffusion解释:扩散模型[译]_于建民的博客-CSDN博客
Stable Diffusion非常详细的介绍:【原创】万字长文讲解Stable Diffusion的AI绘画基本技术原理 – 知乎
文章出处登录后可见!