AIGC,全称是人工智能生成内容(Artificial Intelligence Generated Content)是继UGC(用户生成内容),PGC(平台生成内容)后,利用人工智能技术,自动生成内容的生产方式;
目前主要利用&集成自然语言处理、计算机视觉、语音生成等算法训练生成式大模型,且已经从纯文本生成、纯图像生成拓展到了跨模态的内容理解与生成,促进了更接近普通人定义的“智慧”的加速涌现。
目前商业项目的美术现在的流程一般是MJ起手做概念扩展,定型后用lora练自己的风格或角色,然后SD+controlnet量产。
目前市场上的主要产品:

TIPS:
- 开源平台比如StableDiffusion的话可以先用GPT生成更细致准确的prompt语句,然后跟AI绘画串联使用,大部分商用平台已经集成了用户语言->模型提示语的这一步,对prompt要求不那么敏感;Midjourney精准词汇总结 – 设计经验 – 素材集市
- 对于普通用户基本足够,专业需求比如生成logo、海报、广告等依然需要设计师精修,且大部分平台同时支持以图生图(图像编辑);
- 已有较多设计师/原画师采用AI绘图进行辅助,应用在了logo设计、儿童读物的插图、新闻通讯的艺术图、游戏的概念艺术和角色图等方面,注意自己的套餐是否支持商业用途使用。
一些常用概念:

Midjourney
- 定位:Midjourney是一款AI绘画工具,搭载在Discord社区上,目前在discord上有着较为活跃的用户群体,交互体验较好,新用户免费试用次数25次(刷新小图、重做、优化都会消耗),付费基础版本10刀/月,年用户8刀/月。
- 注册:需要先下载并注册discord(聊天软件,起家是游戏聊天应用与社区,类似美版YY语音,21年被微软收购,需要挂Seal全局),搜索MidjourneyBot,加载/创建服务器,授权验证,在机器人聊天框中输入【/imagine + 你的prompt语句】进行生成。
DALL-E2
- 定位:OpenAI推出的文本生成图像系统https://openai.com/product/dall-e-2
- 方法:一种层级式的基于CLIP特征的根据文本生成图像模型,在图像生成时,先生成64*64再生成256*256,最终生成更精美的1024*1024的高清大图。DALLE·2模型根据CLIP的文本特征和图像特征最终生成图像,可以看做CLIP的反向过程,因此DALLE·2被作者称为unCLIP。
Stable Diffusion
原论文,直译过来就是“扩散模型 ,公式推导如下:
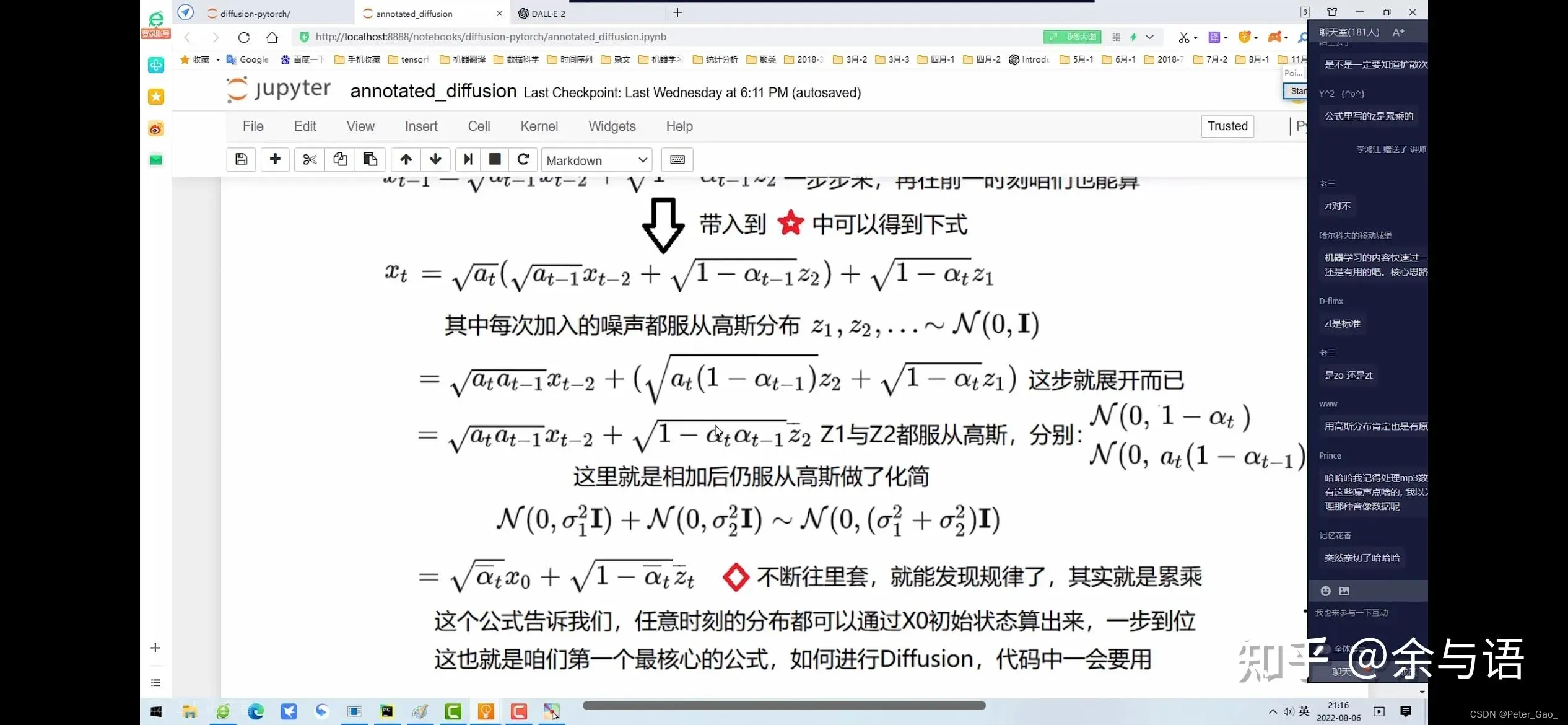
Stable Diffusion是一种潜在扩散模型(Latent Diffusion Model),能够从文本描述中生成详细的图像。它还可以用于图像修复、图像绘制、文本到图像和图像到图像等任务。简单地说,我们只要给出想要的图片的文字描述在提Stable Diffusion就能生成符合你要求的逼真的图像
Stable Diffusion WebUI
- 定位:一个基于 Stable Diffusion 的基础应用,利用 gradio 模块搭建出交互程序,后端依旧是Stable Diffusion以及一系列相关的工具包,提供了txt2img、img2img、inpaint 等多种功能,还包含了许多模型融合改进、图片质量修复等附加升级。贵在开源,可以在上面训练我们自己的模型,或者在社区里下载别人的模型。
- 使用:目前提到SD更多是指这套开源框架,大家一般在模型分享站下载模型,原生的模型效果并不好。SD搭建后可以安装插件,加载controlnet、lora等拓展功能。
- Git clone 项目地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui
- 模型下载:https://huggingface.co/runwayml/stable-diffusion-v1-5 【这是基础的SD1-5版本,可以用来ft】
- 详细教程:https://zhuanlan.zhihu.com/p/63
LoRA(定向生成)
LoRA的算法原理简单理解就是外挂一个由少量图片定制训练的小模型,去影响原本的生成大模型;一般用来做角色或画风,比如给若干张类似的图(特朗普), 然后生成的时候都是他。
LoRA本身是Low-Rank Adaption of large language model的缩写,这个方法是一种大语言模型fine-tune的方法。主要思路是在固定大网络的参数,并训练某些层。
外挂一个LoRA小模型(可以在HuggingFace上下载),并设置权重参数,用<>加在prompt语句中即可触发,例如<lora:koreanDollLikeness_v10:0.66>,这样用少量prompt描述语句就可以得到更定向的结果,减少微调。
ControlNet插件
现在的 AI 绘画技术主要采用了一种名为扩散模型的方法,这种方法能够使生成的图片呈现出独特且富有趣味性的效果。然而,这种方法也存在一个显著的问题,那就是生成的图片可控性非常差。在某些情况下,生成的图片可能会非常精美,而在其他时候,效果却可能不尽如人意。这使得设计师在使用此类工具时,很难确保能够满足客户的具体需求。
然而,随着一种名为 ControlNet 的新技术的出现,这一局面得到了改善。ControlNet 能够帮助设计师更好地控制 AI 绘画过程,从而使这个工具更加符合他们的实际工作需求。AI 绘画不再仅仅是一个供人们娱乐的小玩具,而是逐渐发展成为一种能够真正帮助设计师提高工作效率的实用工具。虽然目前 ControlNet 的可控性仍然有待提高,但与之前的技术相比,它已经实现了质的飞跃。
Controlnet 插件的本质是利用图像作为输入信息的方式,以弥补语言在某些情况下的局限性。相对于语言而言,图像更加直观、简洁、易于理解,能够更加准确地传达信息。因此,Controlnet 利用图像作为输入方式,可以更好地帮助 AI 理解我们的需求,从而生成我们所需要的图片。
在图片中,包含了多种信息,例如线条轮廓、表面凹凸等。Controlnet 插件的工作原理是使用特定的模型提取出特定的图像信息,然后将其输入给 AI,引导 AI 生成图片。
总的来说,我们可以将使用图片作为提示词视为补充语言的方式。这里补充一下,在文生图和图生图中用 controlnet 插件的区别,一句话说明白,需要生成新的图片用文生图,在原有图片上优化使用图生图。
其它产品:文心一格、字节豆包
百度文心一格
- 定位:百度依托飞桨、文心大模型推出的“AI 作画”产品。
- 注册:百度账号即可https://yige.baidu.com/。
- 注意:由于各种风险控制,百度的关键词屏蔽非常多,一旦设计敏感词汇就生成不成功。
- 商业化:有应用场景跳转链接,付费定制马克杯、手机壳、帆布袋等相关产品,价格不贵容易产生消费欲望。
字节豆包
- 体验链接:https://www.doubao.com/
- 定位:字节跳动推出的对标ChatGPT的产品,目前免费且无需排队;有语音功能,哄娃讲故事一把好手,用来学英语也非常方便;图片生成上相对比较小白,直接描述想要的图片画面就行,会有相关提示进一步细化描述;最近,字节的BuboGPT的多模态大模型也在huggingface上推出了Demo,预测之后也会在豆包上集成多模态大模型的功能,支持图文交互内容理解。
- 注册:网页版、安卓版和iOS版同步上线,用抖音账号、手机号和苹果账号都能登录。
SD 的学习曲线。
- 先学最基础的,大概理解参数模型提示词的用途,先把 SD 的流程跑通,这一步大概可以做出来相对看得过去的图了
- 然后再去研究模型和提示词的高级用法,比如,混用 lora 模型,提示词的分步和融合写法,这个时候,必然会涉及到一些原理性的东西,就会理解为什么 AI 画不好手了。到这一步,可以对图进行针对性的优化了,比如说一个图怎么达不到提示词想要的效果,可以针对性地优化提示词。
- 学习其他功能,图生图,Control net 插件,以及分层控制 Lora 模型等进阶功能。
- 训练自己的模型
还没有安装Stable Diffusion 软件的朋友可以网上自己找安装一下,或者看本人往期的详细安装教程,安装包:https://item.taobao.com/item.htm?ft=t&id=720790767379这个0.1元的网上很多
civitai网站(C站)的模型打包下载:https://item.taobao.com/item.htm?ft=t&id=722030250111
对于没有魔法工具的人来说,直接下载完整的模型包是比较划算的,因为C站上很多早期的作品都下架了,现在再去找,很多优秀作品都没法找到
文章出处登录后可见!