操作系统原理实验报告
实验题目 实验四内存分配算法
实验四、内存分配算法
1.1 实验目的
一个好的计算机系统不仅要有一个足够容量的、存取速度高的、稳定可靠的主存储器,而且要能合理地分配和使用这些存储空间。当用户提出申请主存储器空间时,存储管理必须根据申请者的要求,按一定的策略分析主存空间的使用情况,找出足够的空闲区域分配给申请者。当作业撤离或主动归还主存资源时,则存储管理要收回作业占用的主存空间或归还部分主存空间。主存的分配和回收的实现是与主存储器的管理方式有关的,软件模拟内存的分配。
通过本实验帮助学生理解在动态分区管理方式下应怎样实现主存空间的分配和回收。
1.2 实验内容及要求
在动态分区管理方式下采用不同的分配算法实现主存分配和实现主存回收。
1.3 实验技术
1)一台运行Windows 操作系统的计算机
2)计算机中需安装Visual C专业版或企业版
1.4实验步骤
1)可变分区方式是按作业需要的主存空间大小来分割分区的。当要装入一个作业时,根据作业需要的主存量查看是否有足够的空闲空间,若有,则按需要量分割一个分区分配给该作业;若无,则作业不能装入。随着作业的装入、撤离、主存空间被分成许多个分区,有的分区被作业占用,而有的分区是空闲的。例如:

为了说明哪些区是空闲的,可以用来装入新作业,必须要有一张空区说明表,格式如下:

- 其中,起址——指出一个空闲区的主存起始地址。
- 长度——指出从起始地址开始的一个连续空闲区的长度。
- 状态——有两种状态,一种是“未分配”状态,指出对应的由起址指出的某个长度的区域是空闲区;另一种是“空表目”状态,表示表中对应的登记项目是空白(无效),可用来登记新的空闲区(例如,作业撤离后,它所占的区域就成了空闲区,应找一个“空表目”栏登记归还区的起址和长度且修改状态)。由于分区的个数不定,所以空闲区说明表中应有适量的状态为“空表目”的登记栏目,否则造成表格“溢出”无法登记。
- 上述的这张说明表的登记情况是按提示(1)中的例所装入的三个作业占用的主存区域后填写的
2)当有一个新作业要求装入主存时,必须查空闲区说明表,从中找出一个足够大的空闲区。有时找到的空闲区可能大于作业需要量,这时应把原来的空闲区变成两部分:一个部分分给作业占用;另一部分又成为一个较小的空闲区。为了尽量减少由于分割造成的“碎片”,在作业请求装入时,尽可能地利用主存的低地址部分的空闲区,而尽量保存高地址部分有较大的连续空闲区域,以利于大型作业的装入。为此,在空闲区说明表中,把每个空闲区按其地址顺序登记,即每个后继的空闲区其起始地址总是比前者大。为了方便查找还可使表格“紧缩”,总是让“空表目”栏集中在表格的后部。
3)采用首次适应算法或循环首次算法或最佳适应算法分配主存空间。由于本实验是模拟主存的分配,所以当把主存区分配给作业后并不实际启动装入程序装入作业,而用输出“分配情况”来代替。(即输出当时的空闲区说明表及其内存分配表)
4)当一个作业执行结束撤离时,作业所占的区域应该归还,归还的区域如果与其它空闲区相邻,则应合成一个较大的空闲区,登记在空闲区说明表中。例如,在提示(1)中列举的情况下,如果作业2撤离,归还所占主存区域时,应与上、下相邻的空闲区一起合成一个大的空闲区登记在空闲区说明表中。
5)请分别按首次适应算法、循环首次算法和最佳适应算法设计主存分配和回收的程序。然后按(1)中假设主存中已装入三个作业,且形成两个空闲区,确定空闲说明表的初值。现有一个需要主存量为6K的作业4 申请装入主存;然后作业3 撤离;再作业2 撤离。请你为它们进行主存分配和回收,把空闲区说明表的初值以及每次分配或回收后的变化显示出来或打印出来。
6)要求如下:
打印程序运行时的初值和运行结果,要求如下:
- 打印空闲区说明表的初始状态,作业4 的申请量以及为作业4 分配后的空闲区说明表状态;
- 再依次打印作业3 和作业2 的归还量以及回收作业3,作业2 所占主存后的空闲区说明表。
程序设计的如下:
定义一个的类freespace来构建内存块的结构
typedef struct freespace
{
int num; //分区号
int size; //分区大小
int address; //分区首地址
status state; //分区状态,FREE和BUSY
};Freespace中包含分区的作业号、分区大小、分区首地址和分区状态。
分区的节点定义,主要利用了双链表结构,数据包含头指针、尾指针、数据
域freespace变量,还定义了全局变量first指针和last指针以及一个辅助的help指针,并进行初始化。
typedef struct node{ freespace data; node *head; node *next;}*Linklist;若两个空闲区合并的时候,因为last->next=null,会导致最后两个p->next->next为空的情况,指针help用于避免程序陷入停滞状况。
程序中菜单设计如下:
void menu(){cout << "********************内存分配系统********************" << endl;cout << "* 1.首次适应算法分配内存 *" << endl;cout << "* 2.最佳适应算法分配内存 *" << endl;cout << "* 6.下次适应算法分配内存 *" << endl;cout << "* 3.查看主存分配情况 *" << endl;cout << "* 4.回收主存 *" << endl;cout << "* 5.退出 *" << endl;cout << "****************************************************" << endl;cout << "请选择:" << endl;}
首次适应算法,找到第一个可以放入的空闲块:
node *p = first;
while (p)
{
if (p->data.state == FREE&&p->data.size == size)//有大小刚好合适的空闲块
{
p->data.state = BUSY;
p->data.num = num;
pre=p->next;
display();
return 1;
}
if (p->data.state == FREE&&p->data.size > size)//有大小比他大的空闲块
{
list->head = p->head;
list->next = p;
list->data.address = p->data.address;
p->head->next = list;
p->head = list;
p->data.address = list->data.address + list->data.size;
p->data.size -= size;
pre=p;
display();
return 1;
}
p = p->next;
}最佳适应算法(找到内存大小>=作业申请内存的最小空闲块):
while (p)//找到最佳位置
{
if ((p->data.size > size || p->data.size == size)&&p->data.state==FREE)
{
if (p->data.size - size < min_space)
{
q = p;
min_space = p->data.size - size;
}
}
p = p->next;
}下次适应算法(从上次最后插入的作业位置往下找到第一个可以放入的空闲区):
node *p = pre;
while (p)
{
if (p->data.state == FREE&&p->data.size == size)//有大小刚好合适的空闲块
{
p->data.state = BUSY;
p->data.num = num;
pre=p->next;
display();
return 1;
}
if (p->data.state == FREE&&p->data.size > size)//有大小比他大的空闲块
{
list->head = p->head;
list->next = p;
list->data.address = p->data.address;
p->head->next = list;
p->head = list;
p->data.address = list->data.address + list->data.size;
p->data.size -= size;
pre=p;
display();
return 1;
}
p = p->next;
}
内存回收(需要考虑三种情况:前后都有空闲区,只有前有空闲区,只有后有空闲区):
if(p->head->data.state == FREE&&p->next->data.state == FREE)//判断前后是不是都有空闲区if (p->head->data.state == FREE)//与前一块空闲区相邻,则合并if (p->next->data.state == FREE)//与后一块空闲区相邻,则合并1.5实验结果及分析说明
1)按照题目要求分配内存如下:

先用首次适应法分配作业如下:
|
0-5k |
作业4 |
|
5k-10k |
作业1 |
|
10k-14k |
作业3 |
|
14k-26k |
作业5 |
|
26k-32k |
作业2 |
|
32k-128k |
空闲 |
分配之后内存的分配情况如下:

再回收作业4和作业5,使得初始状态分配表如下,满足实验的前提要求:

2)首次适应算法。
①分配占用内存大小为6k的作业四,结果如下图所示:
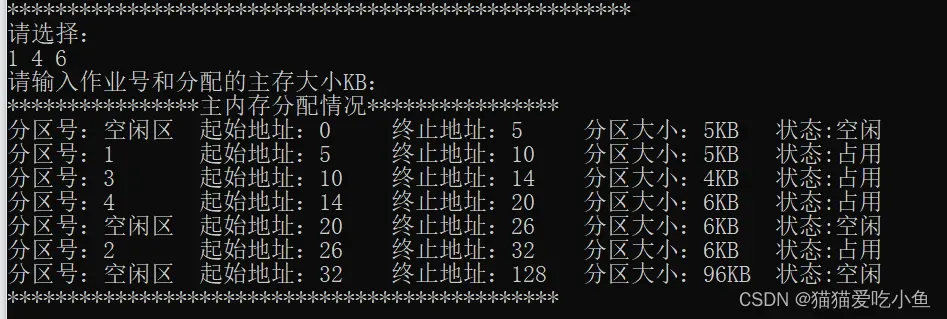
原内存中一共有三个空闲区,大小分别为5k,12k,96k,作业4占用内存为6k,所以根据首次适应法,作业四应该分配到空闲区为12k的内存中,该空闲区分配后剩余大小为6。结果与上图一致。
②回收作业3,输入4 3,结果如下图所示:
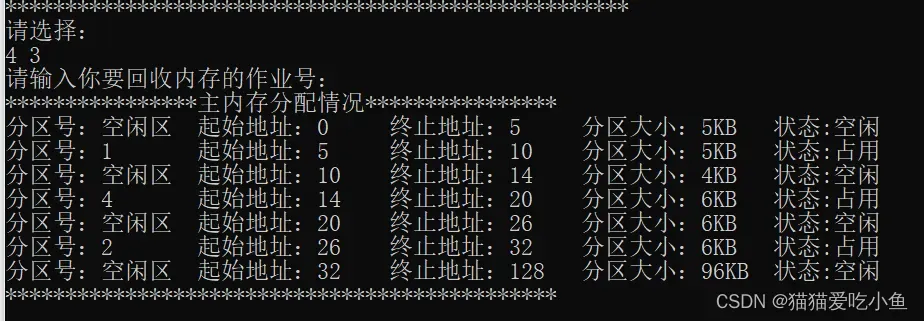
回收作业3后,内存中10k-14k的位置变为空闲区。
③回收作业2,输入4 2,结果如下图所示:

因为作业2前面和后面都为空闲区,回收作业2后,空闲区合并。起始地址为20K,终止地址为128k,空闲区大小为108k。
3)下次适配算法
为了看出下次适应算法初始内存分配情况如下:
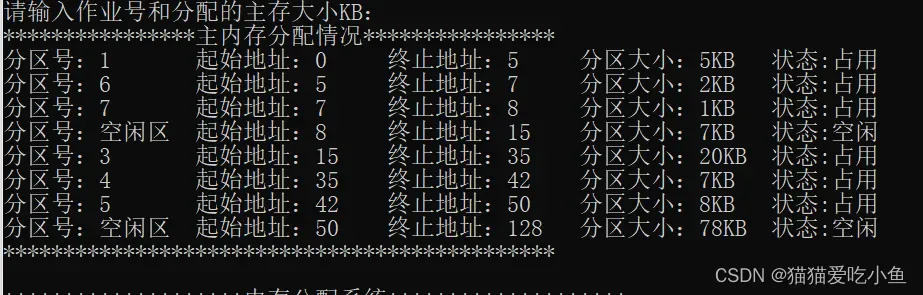
用首次适应法 为作业8 分配8k内存空间后,50k-58k被占用,作业8即为最后一次分配的位置:

用下次适应法为作业9分配2k内存空间,输入 6 9 2;
因为作业8即为最后一次分配的位置:所以从这里开始向下找空间进行分配,作业9分配在作业8后的位置,起始位置为58k,终止位置为60k.

回收则不再演示。
4)最佳适应算法
为了看出最佳适应和首次适应算法的区别,初始内存分配情况如下:
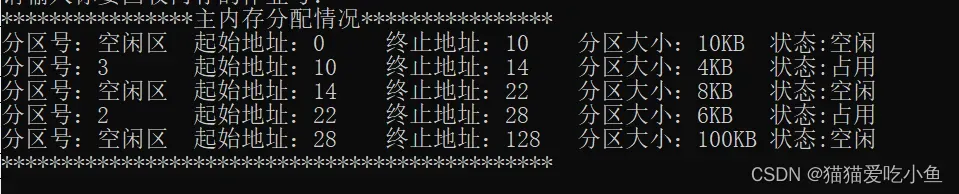
表格如下:
0-10k |
空闲 | 10k |
|
10k-14k |
作业3 |
4k |
|
14k-22k |
空闲 | 8k |
|
22k-28k |
作业2 |
6k |
|
28k-128k |
空闲 |
100k |
①分配占用内存大小为6k的作业四,结果如下图所示:
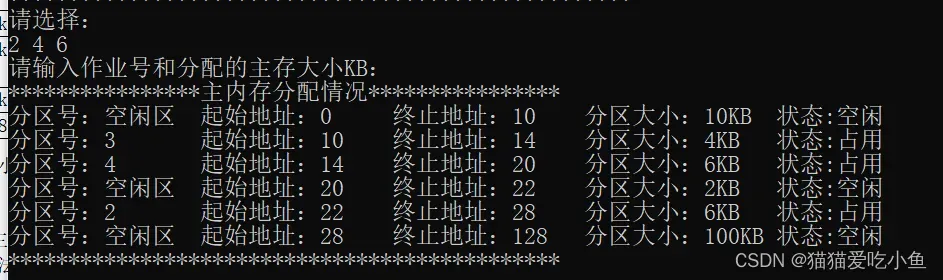
原内存中一共有三个空闲区,大小分别为10k,8k,100k,作业4占用内存为6k,所以根据最佳适应法,作业四应该分配到空闲区为8k的内存中。该空闲区分配后剩余大小为2k。结果与上图一致。
②回收作业3,输入4 3,结果如下图所示:
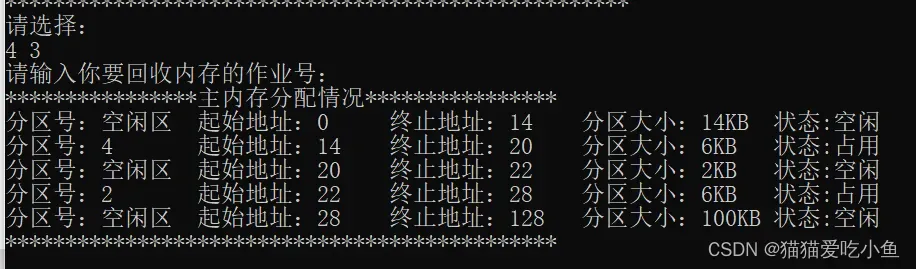
回收作业3后,作业3空出的空闲区和前一个空闲区合并,内存中0k-14k的位置变为空闲区。
③回收作业2,输入4 2,结果如下图所示:
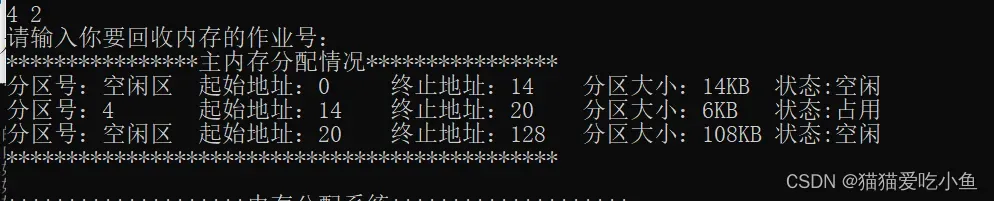
因为作业2前面和后面都为空闲区,回收作业2后,空闲区合并。起始地址为20K,终止地址为128k,空闲区大小为108k。
1.6实验体会(实验中遇到的问题及解决方法)
实验反思和思想收获
- 该程序是利用了链表结构来模拟内存块,链表中会有些涉及空指针的问题(最后一个节点的后一个节点),最好是应该利用循环链表的结构来模拟内存分布,这样分配可以更加简单,但是需要修改循环条件。这里是加了一个节点来避免空指针的问题。
- 首次适应和下次适应的思想基本一致,主要是起始搜索的节点不一样,首次适应的起始节点使first,下次适应的起始节点是pre。每次作业申请后,都需记录该位置,以便下次进行下次适应算法分配。
- 内存回收时,需要注意空闲区链表的尾节点问题。
版权声明:本文为博主作者:猫猫爱吃小鱼原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/cangzhexingxing/article/details/124905484