系列文章目录
本文专门开一节写图生图相关的内容,在看之前,可以同步关注:
stable diffusion实践操作
文章目录
前言
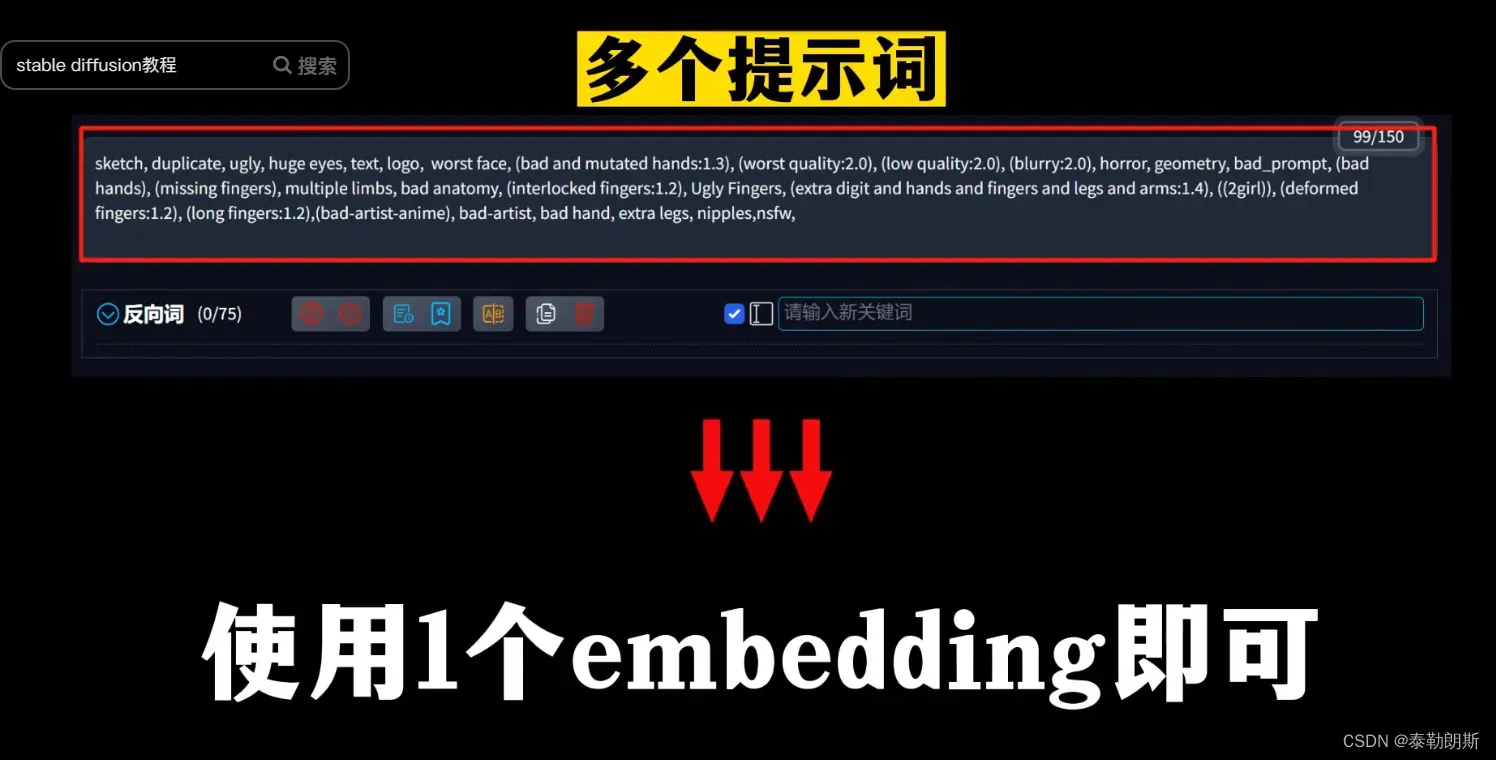
textualinversion 中文名为文本反转,可以理解为提示词的集合,提示词打包,可以省略大量的提示词。后缀safetensors,大小几十kb
本文根据B站A_Eye视频而来,需要看原视频的,可以进入:
Stable diffusion喂饭级基础教程 第九期 什么是embedding
1、embeddding的功能
可以理解为提示词的集合,可以省略大量的提示词。
下面是一篇关于embeddding的权威论文,感兴趣的小伙伴可以自己去看

我总结一下,举个例子,希望左图生成右图,那么对于左面的模型来说,右边的图是个新的概念,然而在一个大模型中,引入新的概念是很困难的,如果为了这个新的图片而重新训练模型,成本就太高了。

所以论文作者提出了一个新的想法,就是在文本编码器的嵌入空间中,找到新的伪装词,通过这个伪装词,去捕获高级语义和精细的视觉细节
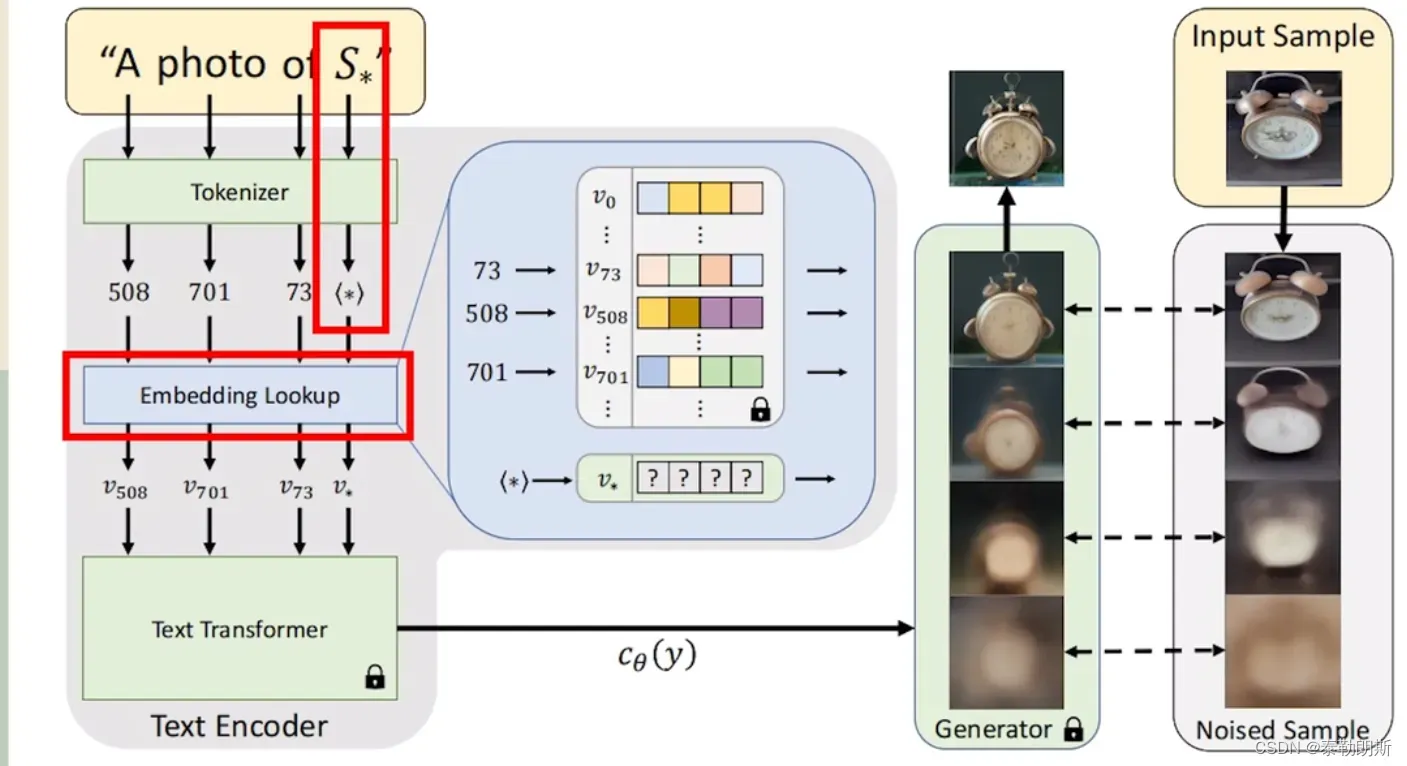
换句话说,就是采用少量有图的文本,训练出一个新的反转文本,这个反转文本可以在生成图片的时候,可以嵌入到大模型的词汇库中,让左边模型学习到了右边图片的概念,从而生成带有右边特征的图片。
这样就可以使用语言文本,将新的特征注入到模型当中,训练成本低,使用方便,并且体积很小,唯一缺点是很难进行精确学习,但是对于普通人来说已经足够了。

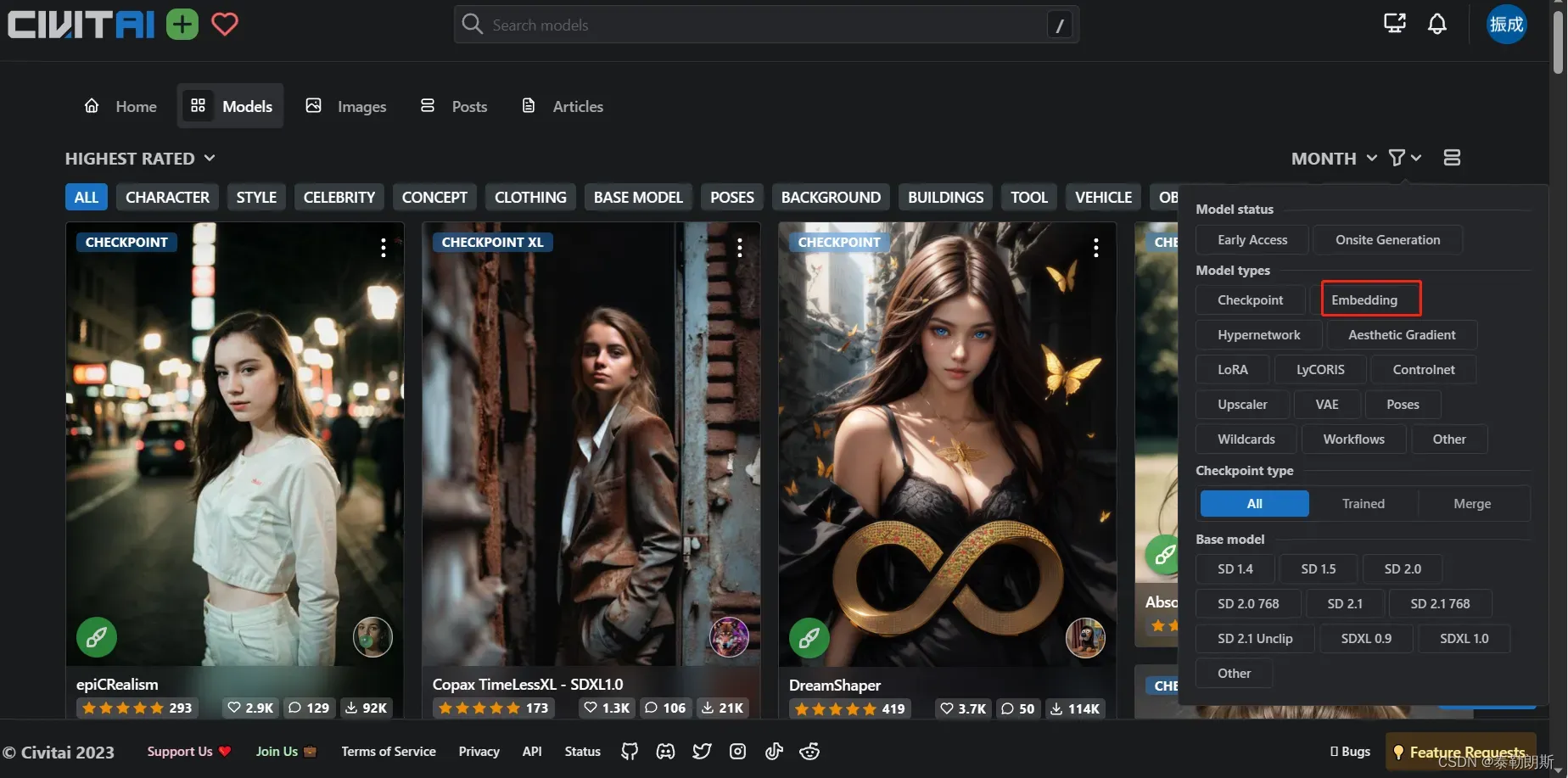
2、如何去下载(https://civitai.com/models)
2.1 筛选 TEXTUAL INVERSION
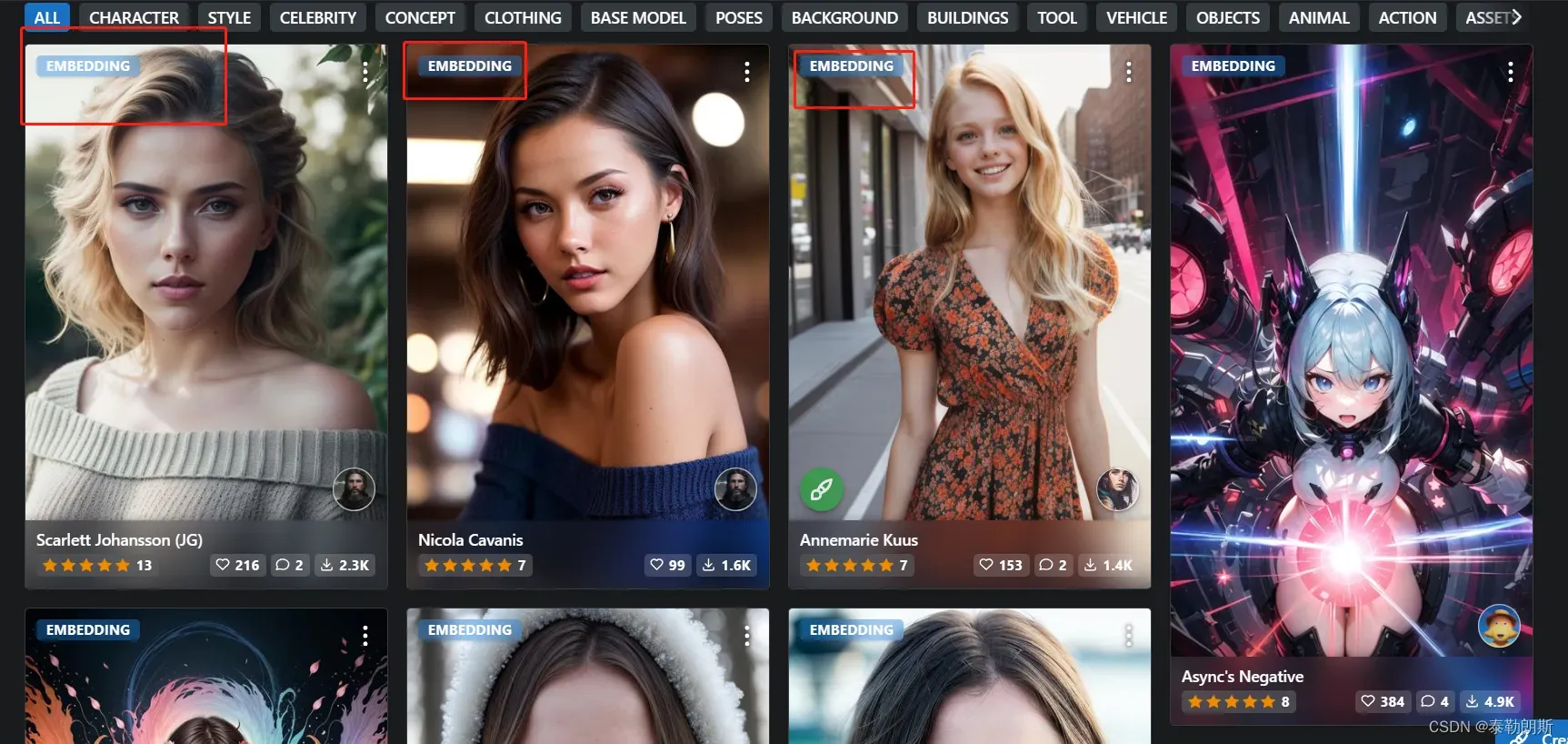
2.2 筛选出来
2.3 下载保存
在C站可以下载:https://civitai.com
下载后存放地址:sd-webui-aki-v4.2\embeddings
2.4 如何使用
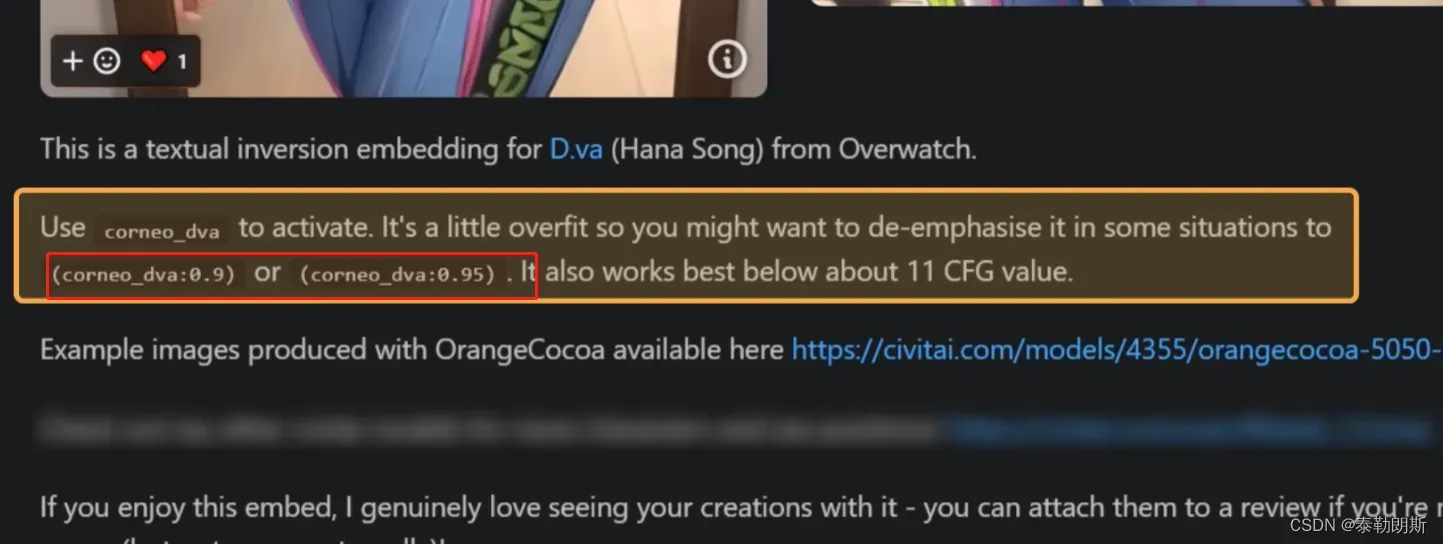
没有触发词,直接使用名称就可以了。注意得到是不要把负向embedding放到正向提示词中去了。

2.5 增加权重
版权声明:本文为博主作者:泰勒朗斯原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_43360707/article/details/132630440