stable diffusion是一种文本生成图片的大模型。它可以使用不同种类的模型生成图片,每种模型都有特定的功能,从而实现对不同细节的定制化处理。
1. CheckPoint模型
首先是CheckPoint模型,它是stable diffusion的主模型,包含了大量的场景素材,所以它的体积很大,其它模型都是在它基础上做一些细节的定制。

2. lora模型
第二个模型是lora模型,它是一个微调模型。主要用于对人物进行定制,相比于主模型,lora模型更加轻巧,训练效率也更高。

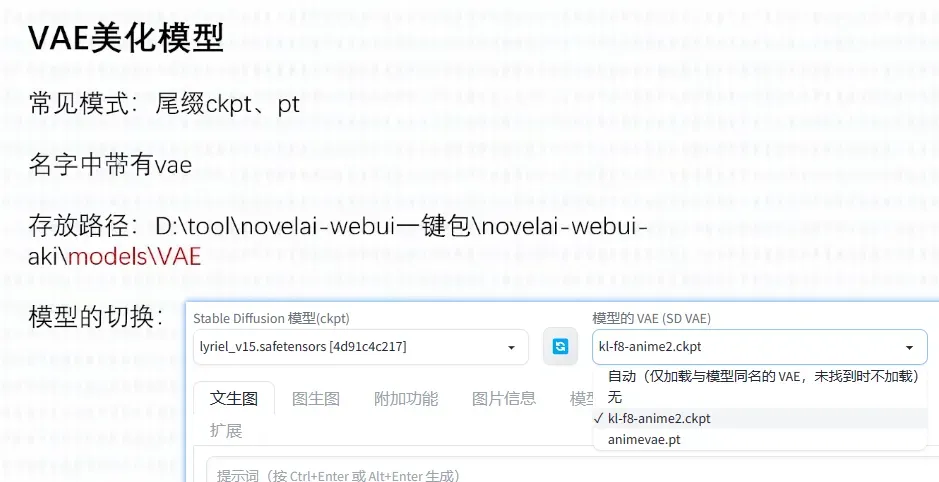
3. VAE模型
第三个模型是VAE模型,它是一个美化模型。VAE模型主要用于美化图片的色彩。很多主模型已经内置了这个功能。
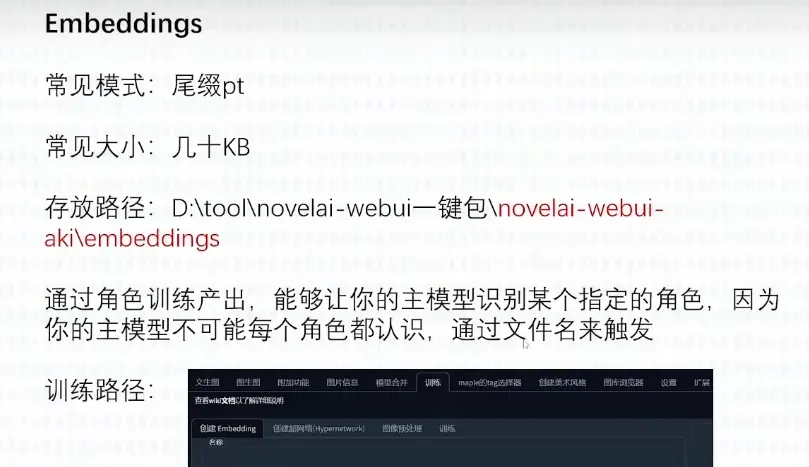
4. Embedding模型
第四个模型是Embedding模型,它是一个嵌入模型。Embedding模型的主要作用是调教文本理解能力。
5. Hypernetwork模型
最后是Hypernetwork模型,它是一个超网络模型。Hypernetwork模型的主要功能是定制生成图片的画风和风格。通过使用Hypernetwork模型,可以对生成的图片进行更加细致的风格调整和定制化处理。

版权声明:本文为博主作者:程序员阿超的博客原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/u011936655/article/details/130942540