1、Java中拷贝的概念
在Java语言中,拷贝一个对象时,有浅拷贝与深拷贝两种
浅拷贝:只拷贝源对象的地址,所以新对象与老对象共用一个地址,当该地址变化时,两个对象也会随之改变。
深拷贝:拷贝对象的所有值,即使源对象发生任何改变,拷贝的值也不会变化。
在User类的基础上,介绍两种浅拷贝案列
User类:
@Data
public class User {
private String name;
private Integer age;
}
案列①:普通对象的浅拷贝
package com.shuizhu.study;
//浅拷贝案例1
public class Study01 {
public static void main(String[] args) {
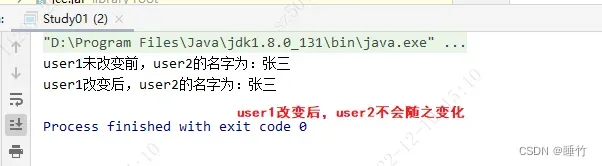
User user1 = new User();
user1.setName("张三");
user1.setAge(18);
User user2 = user1;
System.out.println("user1未改变前,user2的名字为:" + user2.getName());
user1.setName("李四");
System.out.println("user1未改变前,user2的名字为:" + user2.getName());
}
}
结果:改变user1后,user2的值也随之变化

案列②:List浅拷贝(这也是我们平时项目中,经常遇到的情况)
package com.shuizhu.study;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
//Java浅拷贝案列2
public class Study02 {
public static void main(String[] args) {
List<User> list1 = new ArrayList<>();
User user1 = new User();
user1.setName("张三");
user1.setAge(18);
User user2 = new User();
user2.setName("李四");
user2.setAge(19);
list1.add(user1);
list1.add(user2);
//TODO 以下是开发中,经常发生的浅拷贝
//方式1:通过new ArrayList方式,把list01拷贝给list02
List<User> list2 = new ArrayList<>(list1);
System.out.println("list1未改变前,list2的结果为:" + list2);
//方式2:通过addAll方法,把list01拷贝给list02
List<User> list3 = new ArrayList<>();
list3.addAll(list1);
System.out.println("list1未改变前,list3的结果为:" + list3);
//方式3:通过stream流的方式,把list01拷贝给list02
List<User> list4 = list1.stream().collect(Collectors.toList());
System.out.println("list1未改变前,list4的结果为:" + list4);
//改变list1集合中的user1对象
System.out.println("--------------------------------------------");
user1.setName("老六");
user1.setAge(78);
System.out.println("list1改变后,list2的结果为:" + list2);
System.out.println("list1改变后,list3的结果为:" + list3);
System.out.println("list1改变后,list4的结果为:" + list4);
}
}
结果:对List的3种拷贝,其实都是浅拷贝,当源集合中对象发生改变时,新的List也会随之变化

2、常见的深拷贝方式
- 构造函数方式(new的方式)
- 重写clone方法
- Apache Commons Lang序列化
- Gson序列化
- Jackson序列化
2.1、构造函数方式
这种方式就是创建一个新的对象,然后通过源对象的get方法与新对象set方法,把源对象的值复制新对象,这里就不再演示了。
缺点:在拷贝的对象数量较少时,可以使用,但是对象数量过多时,会大大增加系统开销,开发中应避免使用。
2.2、重写clone方法
步骤:
1>需要拷贝对象的类,去实现Cloneable接口
2>重写clone方法
3>使用”对象.clone()“的方式进行拷贝
根据上面的案列,进行对应的改造:
首先是User实体类 ,如下:
@Data
public class User implements Cloneable{
private String name;
private Integer age;
@Override
protected User clone() throws CloneNotSupportedException {
return (User) super.clone();
}
}改造案列①:
package com.shuizhu.study;
//Java深拷贝案列
public class Study03 {
public static void main(String[] args) throws CloneNotSupportedException {
User user1 = new User();
user1.setName("张三");
user1.setAge(18);
User user2 = user1.clone();
System.out.println("user1未改变前,user2的名字为:" + user2.getName());
user1.setName("李四");
System.out.println("user1未改变前,user2的名字为:" + user2.getName());
}
}
结果:当user1改变后,user2的值不会改变

改造案列②:List类型深拷贝
package com.shuizhu.study;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
//Java深拷贝案列
public class Study04 {
public static void main(String[] args) {
List<User> list1 = new ArrayList<>();
User user1 = new User();
user1.setName("张三");
user1.setAge(18);
User user2 = new User();
user2.setName("李四");
user2.setAge(19);
list1.add(user1);
list1.add(user2);
/
//通过clone方式,把list01拷贝给list02
List<User> list2 = new ArrayList<>();
//TODO 当数据量多时,建议使用对象的方式,把List当做属性,然后拷贝哦到一个新的对象中,从而不需要循环,可以见Apache Commons Lang序列化深拷贝方式
list1.forEach(user->{
try {
list2.add(user.clone());
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
});
System.out.println("list1未改变前,list2的结果为:" + list2);
//改变list1集合中的user1对象
System.out.println("--------------------------------------------");
user1.setName("老六");
user1.setAge(78);
System.out.println("list1改变后,list2的结果为:" + list2);
}
}
结果:list1中的每个对象通过clone()添加list2中,当list1中的对象改变时,list2不会改变

2.3 、Apache Commons Lang序列化
步骤:
1>导入Commons包
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3:3.5</version>
</dependency>2>实体类实现Serializable接口
@Data
public class User implements Serializable {
private String name;
private Integer age;
}
3>调用SerializationUtils工具类,实现深拷贝(注意:SerializationUtils不能直接拷贝List类型)
案列如下:
案列①:对象深拷贝
package com.shuizhu.study2;
import org.apache.commons.lang3.SerializationUtils;
//Apache Commons Lang序列化实现对象的深拷贝
public class Study01 {
public static void main(String[] args) {
User user1 = new User();
user1.setName("张三");
user1.setAge(18);
User user2 = SerializationUtils.clone(user1);
System.out.println("user1未改变前,user2的名字为:" + user2.getName());
user1.setName("李四");
System.out.println("user1改变后,user2的名字为:" + user2.getName());
}
}
结果:user1的改变不会导致user2的改变,从而实现深拷贝

案列②:List类型深拷贝
(1)改造开始,我们先创建一个专门用于拷贝List<User>类型的实体类
package com.shuizhu.study2;
import java.io.Serializable;
import java.util.List;
/**
* @author 睡竹
* @date 2022/12/10
* 用于深拷贝时,不需要去遍历List<User>集合,只需要拷贝UserCopyDTO 对象就可以
* 获取到新的List<User>集合
*/
@Data
public class UserCopyDTO implements Serializable {//必须实现Serializable接口
private List<User> users;
}
(2)拷贝List类型
package com.shuizhu.study2;
import org.apache.commons.lang3.SerializationUtils;
import java.util.ArrayList;
import java.util.List;
//Apache Commons Lang序列化实现List的深拷贝
public class Study02 {
public static void main(String[] args) {
List<User> list1 = new ArrayList<>();
User user1 = new User();
user1.setName("张三");
user1.setAge(18);
User user2 = new User();
user2.setName("李四");
user2.setAge(19);
list1.add(user1);
list1.add(user2);
//使用UserCopyDTO对象,专门用于拷贝List<User>类型数据,不需要再去遍历list1
UserCopyDTO userCopyDTO = new UserCopyDTO();
userCopyDTO.setUsers(list1);
//通过Apache Commons Lang序列化方式,把list01拷贝给list02
UserCopyDTO clone = SerializationUtils.clone(userCopyDTO);
List<User> list2 = clone.getUsers();
System.out.println("list1未改变前,list2的结果为:" + list2);
//改变list1集合中的user1对象
System.out.println("--------------------------------------------");
user1.setName("老六");
user1.setAge(78);
System.out.println("list1改变后,list2的结果为:" + list2);
}
}
结果:

2.4、Gson序列化
步骤:
1、导入Gson依赖
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.5</version>
</dependency>
2>创建Gson对象,使用该对象进行深拷贝(实体类不再需要实现Serializable接口)
案例如下:只演示对象的深拷贝,LIst类型的深拷贝与之前的流程是相似的
package com.shuizhu.study3;
import com.google.gson.Gson;
//Gson序列化实现对象的深拷贝
public class Study01 {
public static void main(String[] args) {
User user1 = new User();
user1.setName("张三");
user1.setAge(18);
Gson gson = new Gson();
User user2 = gson.fromJson(gson.toJson(user1), User.class);
System.out.println("user1未改变前,user2的名字为:" + user2.getName());
user1.setName("李四");
System.out.println("user1改变后,user2的名字为:" + user2.getName());
}
}
重点:

结果:

2.5、Jackson序列化
该方式与Gson原理、使用方式相似,但是Jackson序列化深拷贝,要求拷贝的对象必须有无参构造函数
步骤:
1>导入Jackson依赖
<dependency>
<groupId>com.fasterxml.jackson</groupId>
<artifactId>core</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson</groupId>
<artifactId>databind</artifactId>
<version>2.2.2</version>
</dependency>
2>创建ObjectMapper对象,进行深拷贝(用法与Gson一致)
package com.shuizhu.study4;
import com.fasterxml.jackson.databind.ObjectMapper;
import java.io.IOException;
//Jackson序列化实现对象的深拷贝
public class Study01 {
public static void main(String[] args) {
User user1 = new User();
user1.setName("张三");
user1.setAge(18);
ObjectMapper mapper = new ObjectMapper();
User user2 = null;
try {
user2 = mapper.readValue(mapper.writeValueAsString(user1), User.class);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("user1未改变前,user2的名字为:" + user2.getName());
user1.setName("李四");
System.out.println("user1改变后,user2的名字为:" + user2.getName());
}
}
重点:

结果:
3、总结
| 方式 | 优点 | 缺点 |
| 构造函数 | 1. 底层实现简单 2. 不需要引入第三方包 3. 系统开销小 4. 对拷贝类没有要求,不需要实现额外接口和方法 | 1. 可用性差,每次新增成员变量都需要新增新的拷贝构造函数 |
| 重载clone()方法 |
1. 底层实现较简单 2. 不需要引入第三方包 3. 系统开销小 追求性能的可以采用该方式 |
1. 可用性较差,每次新增成员变量可能需要修改clone()方法 2. 拷贝类(包括其成员变量)需要实现Cloneable接口 |
| Apache Commons Lang序列化 | 1. 可用性强,新增成员变量不需要修改拷贝方法 | 1. 底层实现较复杂 2. 需要引入Apache Commons Lang第三方JAR包 3. 拷贝类(包括其成员变量)需要实现Serializable接口 4. 序列化与反序列化存在一定的系统开销 |
| Gson序列化 | 1. 可用性强,新增成员变量不需要修改拷贝方法 2. 对拷贝类没有要求,不需要实现额外接口和方法 | 1. 底层实现复杂 2. 需要引入Gson第三方JAR包 3. 序列化与反序列化存在一定的系统开销 |
| Jackson序列化 | 1. 可用性强,新增成员变量不需要修改拷贝方法 | 1. 底层实现复杂 2. 需要引入Jackson第三方JAR包 3. 拷贝类(包括其成员变量)需要实现默认的无参构造函数 4. 序列化与反序列化存在一定的系统开销 |
版权声明:本文为博主作者:睡竹原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_42675423/article/details/128260074