LLaMA 入门指南
- LLaMA 入门指南
-
- LLaMA的简介
- LLaMA模型的主要结构
-
- Transformer架构
- 多层自注意力层
- 前馈神经网络
- Layer Normalization和残差连接
- LLaMA模型的变体
-
- Base版本
- Large版本
- Extra-Large版本
- LLaMA模型的特点
-
- 大规模数据训练
- LLaMA模型常用数据集介绍
-
- 公共数据来源
- 已知的数据集案例
-
- 1. PubMedQA
- 2. MedMCQA
- 3. USMLE
- 4. RedPajama
- 强大的通用性
- 优化的模型结构
- 如何快速入门LLaMA
-
- 环境搭建
- Hugging Face中Llama模型的快速入门
-
- 准备工作
- 安装`transformers`库
- 使用Llama模型
-
- 环境设置
- 模型加载
- 文本生成
LLaMA 入门指南
在近年来,随着人工智能领域的飞速发展,我们见证了深度学习技术的多变和突破,尤其是在自然语言处理(NLP)领域。LLaMA,作为最新的NLP模型之一,引起了广泛的关注。本文意在深入浅出地介绍LLaMA模型的基本概念、架构以及如何快速开始实验。

LLaMA的简介
LLaMA(Large Language Model – Meta AI)是一种由Facebook母公司Meta AI提出的大型语言模型。它是设计用来理解和生成自然语言文本的模型。LLaMA通过大规模数据集训练,可以在多种任务中表现出色,包括文本分类、文本生成、问答等。
LLaMA模型的主要结构
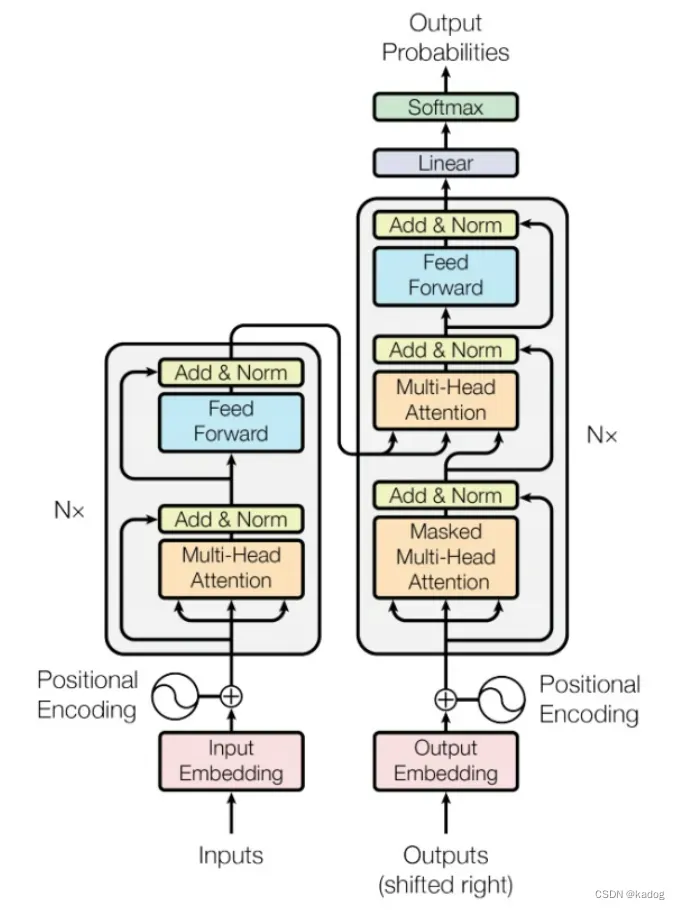
Transformer架构
LLaMA模型是基于Transformer架构构建的,这是一种被广泛使用在大多数现代NLP任务中的模型结构。它依赖于自注意力机制来捕获输入序列不同部分之间的关系。
多层自注意力层
LLaMA模型包括多个自注意力层,每一层都提取输入文本的不同特征。通过这些层的堆叠,模型能够学习到深层的语言表示。
前馈神经网络
除了自注意力层,LLaMA模型还包含前馈神经网络(FFNN),它们负责在每个自注意力层之后处理信息,增强模型的表达力。
Layer Normalization和残差连接
Layer Normalization和残差连接是Transformer架构的重要组成部分,LLaMA模型也在每个自注意力层和FFNN后使用了这些技巧,以稳定训练过程并加速收敛。
LLaMA模型的变体
LLaMA模型具有不同大小的变体,从小型模型到大型模型,它们拥有不同数量的参数,以满足不同计算能力和任务需求。
Base版本
Base版本适合大多数标准计算资源,提供了良好的性能和相对较低的资源需求。
Large版本
Large版本提供了更多的参数,适用于需要更深层次语言理解的复杂任务。
Extra-Large版本
Extra-Large版本是目前LLaMA最大的模型,它具有最高的参数数量,提供了最优秀的性能,但同时需要非常强大的计算资源。
LLaMA模型的特点
大规模数据训练
LLaMA在数十亿级别的数据集上进行训练,能够捕捉语言深层的语义和句法规律。
LLaMA模型常用数据集介绍
LLaMA(Large Language Model Meta AI)是近年来在自然语言处理和机器学习领域引起广泛关注的模型。其背后的数据集是模型训练成功的关键。以下是LLaMA模型训练中可能涉及到的一些常见数据集类型。
公共数据来源
- 网页内容: 从各大门户网站、论坛和博客等网页上抓取的文本内容。
- 社交媒体: 社交平台上用户生成的文本信息,如推文和状态更新。
- 公开论文与书籍: 科研文献、专业书籍等提供的数据。
- 多语言文本: 多语言版的论坛帖子、新闻报道、维基百科文章等。
已知的数据集案例
基于Google Scholar和其他来源的信息整合,以下列表是LLaMA培训中可能用到的一些具体数据集案例。
1. PubMedQA
LLaMA模型可以在医疗专业QA(问题回答)数据集,如PubMedQA上进行微调以提高其在医学领域内容的理解和生成能力。
2. MedMCQA
这是一个医学多选择问答数据集,PMC-LLaMA的微调在包括MedMCQA在内的生物医学QA数据集上进行,以测试其在特定领域的性能。
3. USMLE
美国医学执照考试(USMLE)的数据集,也用于PMC-LLaMA的预训练,可能增强了模型在医学知识方面的表现。
4. RedPajama
RedPajama是LLaMA’s模型的预训练数据集,用于支持模型在各个领域中性能的差异化减损。
强大的通用性
由于其训练数据的多样性,LLaMA能够处理多种语言和任务,展现出良好的通用性。
优化的模型结构
LLaMA在传统的Transformer模型基础上进行了优化,进一步提升了模型的效率和效果。
如何快速入门LLaMA
环境搭建
为了运行LLaMA模型,首先需要准备一个合适的硬件和软件环境。建议的最低要求包括有足够内存的GPU,以及安装有Python、PyTorch等基础库。
Hugging Face中Llama模型的快速入门
准备工作
在开始之前,需要确保满足以下条件:
- 拥有一个Hugging Face账户
- 安装了Python环境
- 安装了
transformers库和其他相关依赖
安装transformers库
使用pip或conda来安装Hugging Face的transformers库。
pip install transformers
或者
conda install -c huggingface transformers
使用Llama模型
环境设置
首先,要导入transformers库中相关的模块,以便加载和使用Llama模型。
from transformers import AutoModelForCausalLM, AutoTokenizer
模型加载
使用AutoModelForCausalLM和AutoTokenizer来分别加载Llama模型及其对应的分词器。
tokenizer = AutoTokenizer.from_pretrained("allenai/llama")
model = AutoModelForCausalLM.from_pretrained("allenai/llama")
文本生成
通过提供一个提示文本(prompt),Llama模型可以生成接续的文本。这里举一个例子:
prompt_text = "The capital of France is"
inputs = tokenizer.encode(prompt_text, return_tensors="pt")
# 生成文本
outputs = model.generate(inputs, max_length=50, num_return_sequences=1)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
版权声明:本文为博主作者:kadog原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_28247201/article/details/136080048