一、论文
本文介绍被计算机视觉顶级国际会议ICCV 2023接收的论文 “TransFace: Calibrating Transformer Training for Face Recognition from a Data-Centric Perspective”
论文链接:https://arxiv.org/abs/2308.10133
开源代码:https://anonymous.4open.science/r/ TransFace-294C
二、背景
1. Vision Transformer (ViT)
Vision Transformer (ViT) 已经在计算机视觉社区多项视觉任务上展现出其强大的表征能力和拟合能力。相比于卷积神经网络 Convolutional Neural Networks (CNNs),ViT缺少了归纳偏置,因此很容易过拟合小规模数据集上。在实际的应用中,ViT的训练通常需要大规模的数据集来做支撑,并配合相应的data augmentation技术,才能保证其有效地收敛。
2. 人脸识别
随着深度学习的发展,基于CNNs的人脸识别技术已经取得了巨大的成功。训练基于CNNs人脸识别模型的损失函数主要分为以下两种类型:(1)Metric-based loss functions, e.g., Triplet loss, Tuplet loss and Center loss. (2) Margin-based loss functions, e.g., ArcFace, CosFace, CurricularFace and AdaFace. 相比于Metric-based loss functions, Margin-based loss functions 能够鼓励模型执行更加高效的sample-to-class的比较,因此能够促进人脸识别模型取得更好的识别精度。其中,ArcFace成为业界训练人脸识别模型首选的损失函数。
现存的人脸识别模型几乎都基于CNNs来构建。考虑到ViT在各项视觉任务上都展现出了一流的性能(远超于CNNs的性能),并且人脸识别任务天然拥有着大规模的训练集,因此我们探索了ViT在人脸识别任务上的性能表现。我们意外地发现,ViT的性能跟CNNs的性能几乎不相上下。
本文旨在探索ViT在人脸识别任务上表现不佳的原因,并从data-centric的角度去提升ViT在人脸识别任务上的性能。
三、方法
1. Motivation
1.1 改进方向
我们发现ViT在人脸识别任务上表现不佳的原因是:ViT的预测很容易过拟合到人脸图像某几个patches上 (e.g., eyes, forehead and hair), 而忽略了一些包含重要人脸线索的patches (e.g., nose, mouth, ears and jaw). 在测试场景,一旦人脸上半部分被干扰 (e.g., a superstar wearing sunglasses or hat), ViT就容易做出错误的预测。我们将这个过拟合问题称作为 Patch-level overfitting issue.
1.2 数据增强
现存的有关ViT研究通过采用一些data augmentation技术,(e.g., Mixup, CutMix and Random Erasing),来缓解ViT过拟合问题。但这些Instance-level data augmentation技术并不适用于人脸识别任务,因为它们不可避免地破坏了人脸的结构信息和保真性,如下图所示。因此如何在充分保留人脸关键信息的基础上精准地解决Patch-level overfitting issue是值得深入研究的。

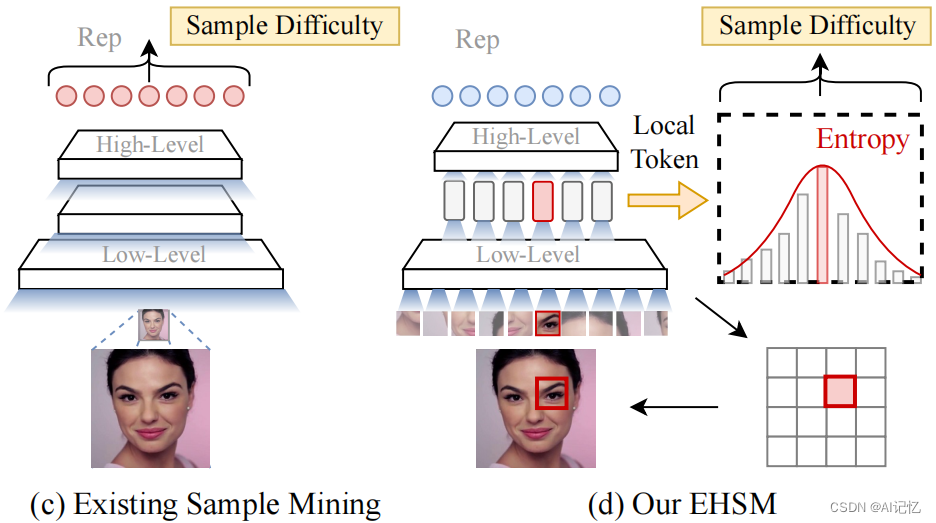
1.3 难样本挖掘
难样本挖掘技术(e.g., Focal loss, MV-Softmax, OHEM and ATk)在提升模型最终的精度中往往起到了重要的作用。现存的大部分难样本挖掘策略都是为CNNs设计的,它们通常采用instance-level indicators of the sample,(e.g., prediction probability, prediction loss and latent features),来挖掘难样本。然而,由于ViT的预测主要由几个patches所决定, 我们可以推断出其用于分类的global token将被几个local tokens所主导。因此,直接利用ViT的global token或者prediction information来挖掘难样本是一个有偏的行为,如下图所示。如何充分利用所有patches information来更精准地挖掘难样本是值得深入思考的。
2. Method
2.1 概览
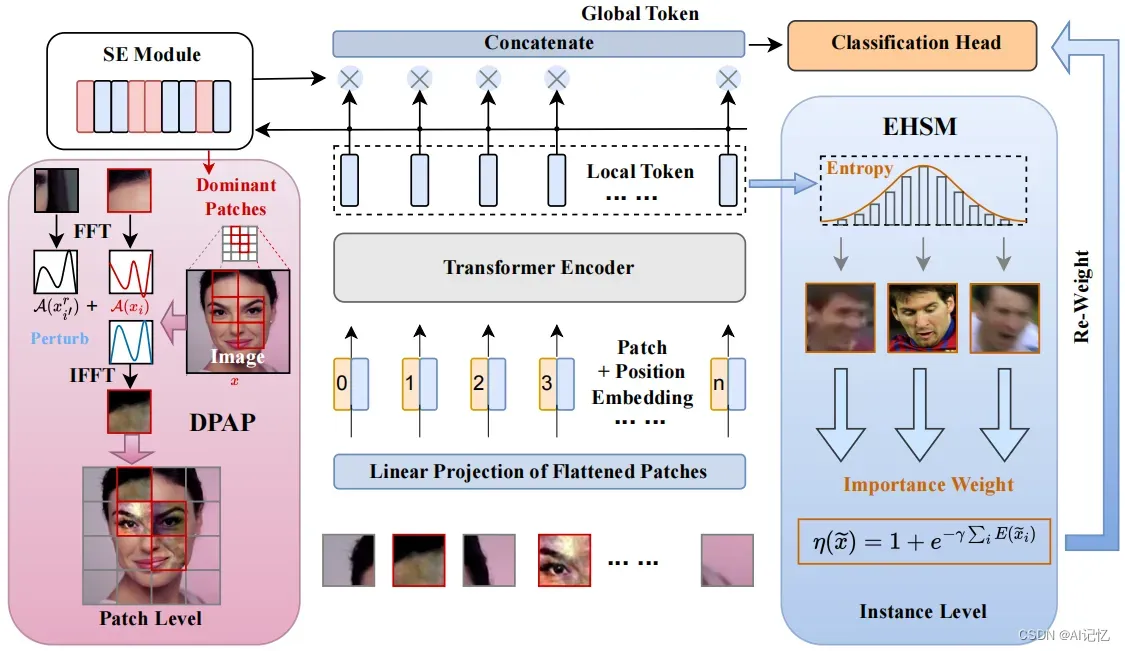
针对上述问题,本文从data-centric角度出发,提出了基于ViT的人脸识别新框架TransFace,如下图所示。
2.2 Patch级数据增强
为精准地解决Patch-level overfittting issue, 本文提出了一个Patch-level Data augmentation策略DPAP, 其专为基于ViT的人脸识别框架所设计。
我们将人脸图像![]() 送入网络进行前向传播,DPAP首先利用SE Module筛选出对ViT预测影响最大的top-K dominant patches:
送入网络进行前向传播,DPAP首先利用SE Module筛选出对ViT预测影响最大的top-K dominant patches:
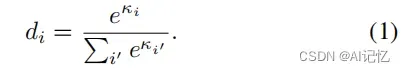
其次,对这些top-K dominant patches执行Fourier Transform, 并分别提取其幅度谱信息和相位谱信息:
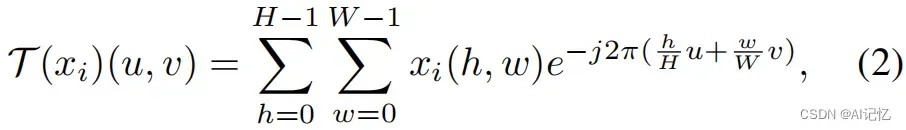
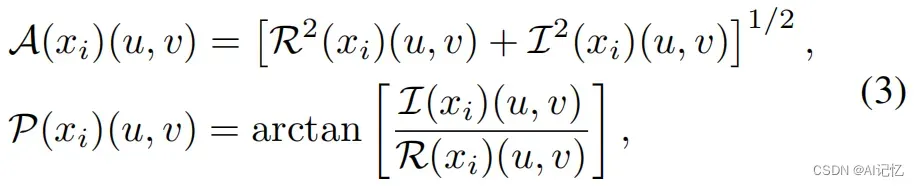
为了在不破坏人脸结构信息和保真性的基础上构建多样化的训练样本,我们利用了一个类似于Mixup的机制来线性混合domaint patch与random patch的幅度谱信息:
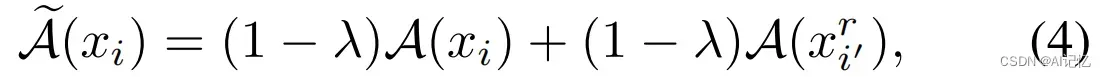
其中,混合强度系数λ从均匀分布中采样 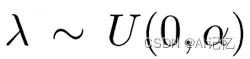 . 然后,我们将混合后的幅度谱信息与原始的相位谱信息重新组合并执行傅里叶逆变换,以此得到重建的new style patch:
. 然后,我们将混合后的幅度谱信息与原始的相位谱信息重新组合并执行傅里叶逆变换,以此得到重建的new style patch:
![]()
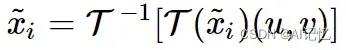
最后,我们将扩增后的图像![]() 正式送入网络中执行有监督训练,并采用ArcFace loss作为基础分类损失:
正式送入网络中执行有监督训练,并采用ArcFace loss作为基础分类损失: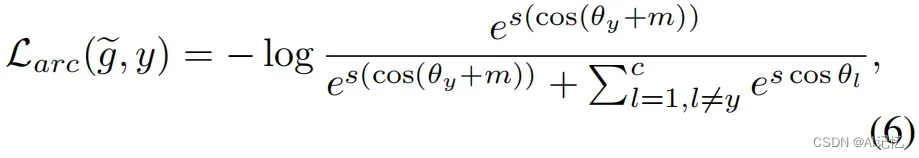
2.3 基于熵的难样本挖掘
信息论已经表明信息熵可以用于衡量图像所包含信息量的丰富度。对于人脸图像来说,高质量的人脸图像(easy sample)通常包含了更丰富的信息(高信息熵),因此更容易被网络学习。而低质量的人脸图像(hard sample),例如一些模糊人脸、低质量人脸等,通常包含较少的有用信息(低信息熵),因此很难被网络所学习。

为了更精确地挖掘难样本,受信息熵启发,我们提出根据人脸样本local tokens所包含信息量的多少来衡量样本的困难性。由于在深度神经网络中,each local token都服从一个未知的复杂分布,因此直接计算each local token的信息熵是非常困难的。受Maximum Entropy Principle的启发,我们转而去估计each local token的信息熵的高斯上界:

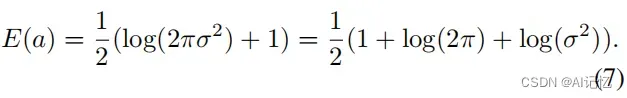
其次,我们利用一个entropy-aware weight mechansim将each local token的信息熵聚合在一起,以此来自适应地为每个样本分配一个重要性权重:
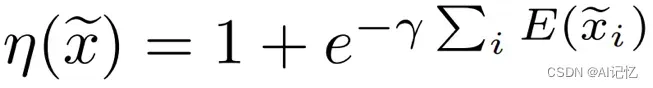
最后,我们将这个重要性权重加权至ArcFace loss前面,以此来有效地鼓励模型在优化过程中重点关注信息量较少的困难样本:
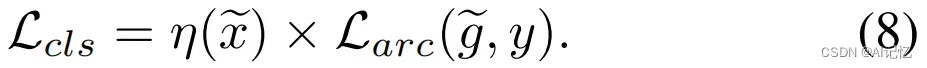
在训练过程中,最小化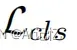 将带来两个好处:
将带来两个好处:
(i)最小化 将鼓励模型从多样化的训练样本中更好地学习出人脸特征
将鼓励模型从多样化的训练样本中更好地学习出人脸特征
(ii)最小化重要性权重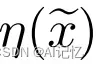 ,相当于最大化local tokens的总体信息
,相当于最大化local tokens的总体信息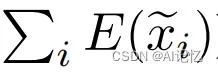 ,这将促进模型充分挖掘each face patch中所包含的人脸线索(e.g., nose, lip and jaw),并极大地提升each local token的表征能力。在一些极端情况下,即使人脸上半部分特征信息被破坏,模型也能充分利用剩余的人脸线索来做出稳定的预测。
,这将促进模型充分挖掘each face patch中所包含的人脸线索(e.g., nose, lip and jaw),并极大地提升each local token的表征能力。在一些极端情况下,即使人脸上半部分特征信息被破坏,模型也能充分利用剩余的人脸线索来做出稳定的预测。
四、实验及结果
1.1 数据集
我们分别采用MS1MV2 (5.8 Mimages, 85K identities)与Glint360K (17M images, 360K identities) 作为我们模型的训练集。并利用LFW, AgeDB-30, CFP-FP和IJB-C来作为benchmarks评估我们模型的识别性能。
1.2 小数据集实验
我们可以观察到,TransFace在这些easy benchmarks上的性能几乎达到了饱和。
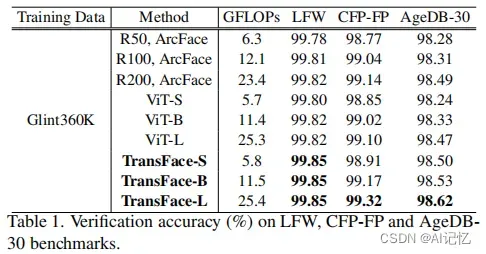
1.3 大数据集实验
我们可以看到,原始ViT的性能跟ResNet-based ArcFace模型的性能不相上下。我们提出的TransFace极大地提升了ViT的在各项评估指标上性能。此外,相比于原始ViT,TransFace仅引入了较小的计算复杂度,而取得了明显的性能增益。
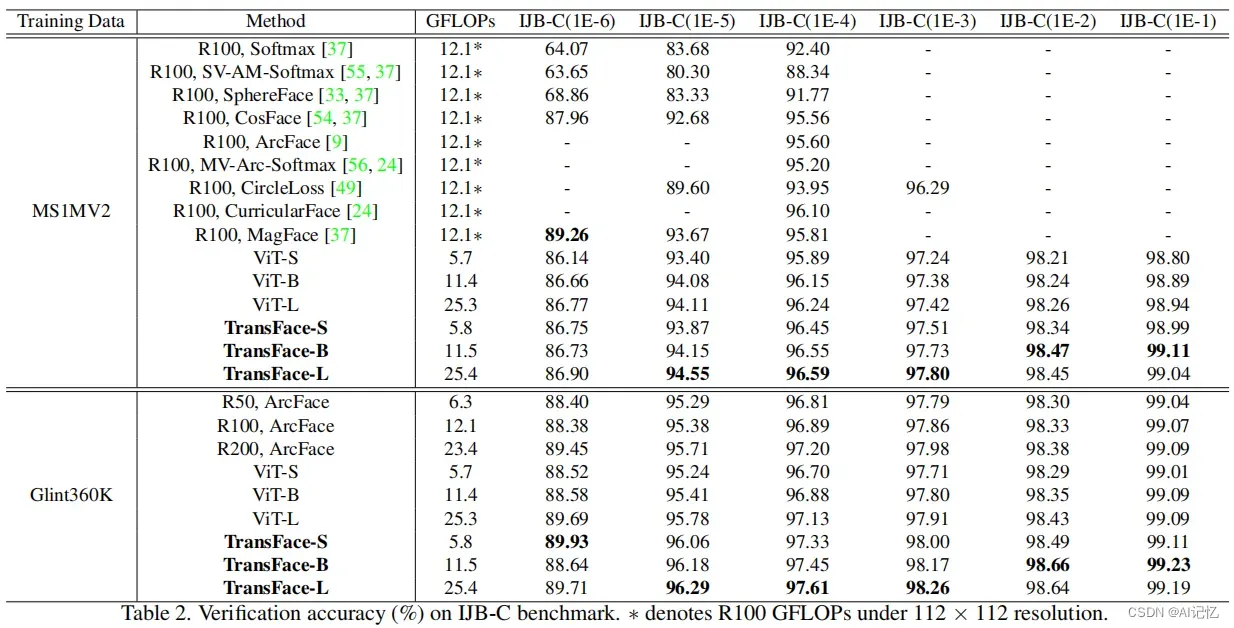
1.4 数据增强对比
相比于以前的data augmentation技术,我们提出的patch-level DPAP策略可以在充分保留人脸结构信息的基础上更精准地解决ViT所面临的Patch-level overfitting issue,因此也获得了更高的性能增益。
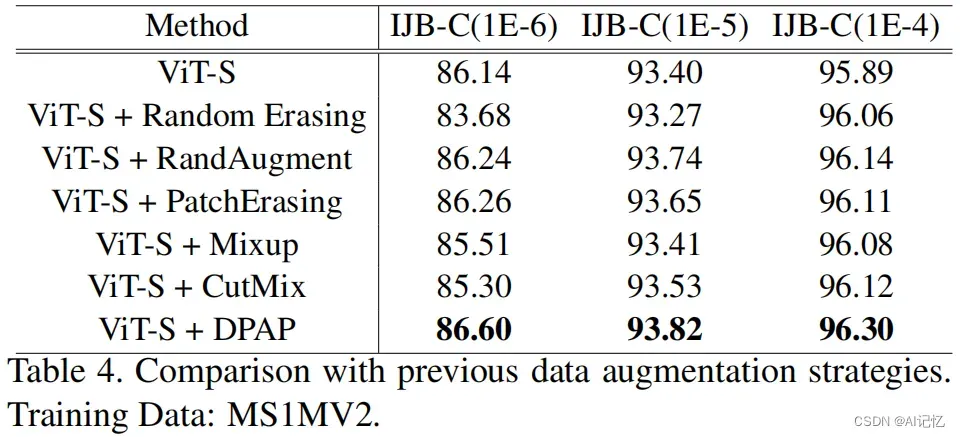
1.5 难样本挖掘对比
相比于以前专为CNNs所设计的难样本挖掘策略,我们为ViT所设计的EHSM可以更好地衡量样本的困难性并提升模型的识别性能。
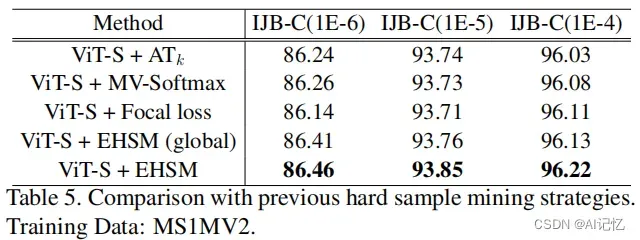
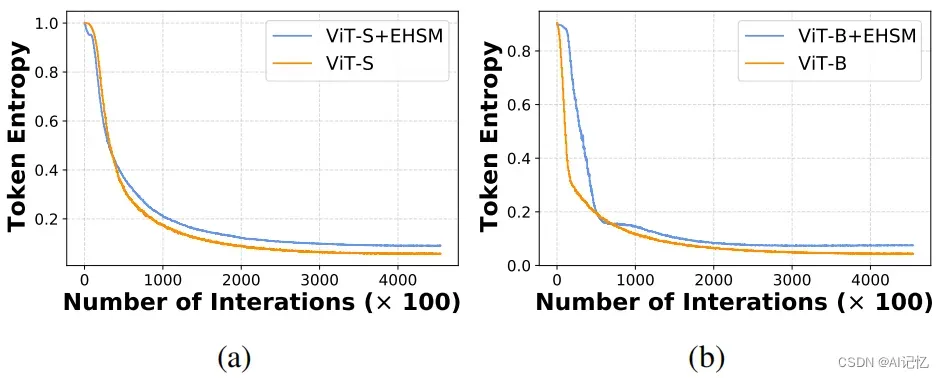
1.6 难样本挖掘有效性
我们调查了训练过程中local token所包含的平均信息熵的变化趋势,发现当ViT收敛时,ESHM能够明显地提升each local token的信息量,这有效地提升了each local token的表征能力。
1.7 DPAP可视化
我们可视化了原始训练样本和DPAP(K=15)所扩增的训练样本。我们可以明显观察到dominant patch主要分布于人脸的hard, forehead and eyes周围,这也充分印证了patch-level overfitting issue的存在。DPAP被提出从dominant patch角度来扩增样本,有效地缓解ViT对dominant patch的过拟合,这也间接地鼓励了ViT充分利用其余人脸线索(e.g., nose, mouth, ears and jaw)来辅助最后的预测,提升了网络的泛化能力。

五、结论
本文提出了一种基于ViT的人脸识别新框架。我们并没有为ViT引入任何较大的结构改进,而是从data-centric角度提出了两个学习策略:DPAP和EHSM,这确保了两个策略的通用性和灵活性。一系列在popular face benchmarks上的实验结果表明了我们TransFace模型的优越性。
版权声明:本文为博主作者:AI记忆原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/sunbaigui/article/details/136556006