(该文为个人的一个记录,也许有错,可以参考下)
决策树模型建立
1.点击源、Excel,在空白处得到一个Excel

点击生成的Excel,导入要处理的数据,再点确定
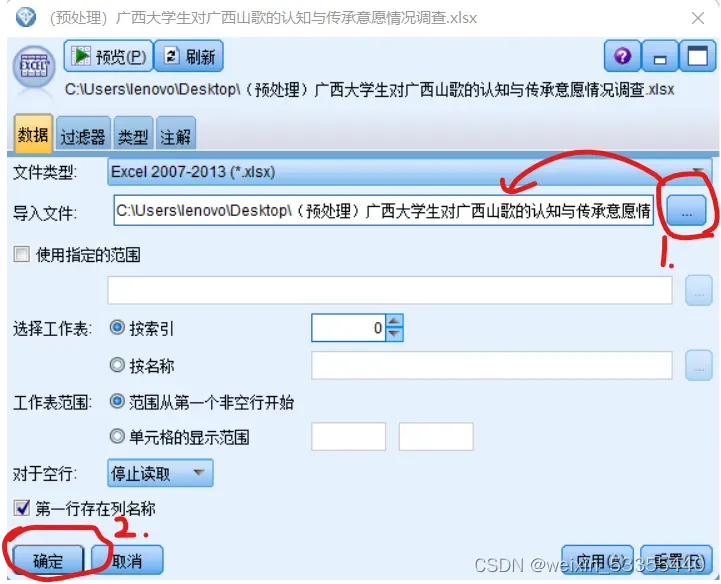
PS:点击上图中的预览可以查看表格数据
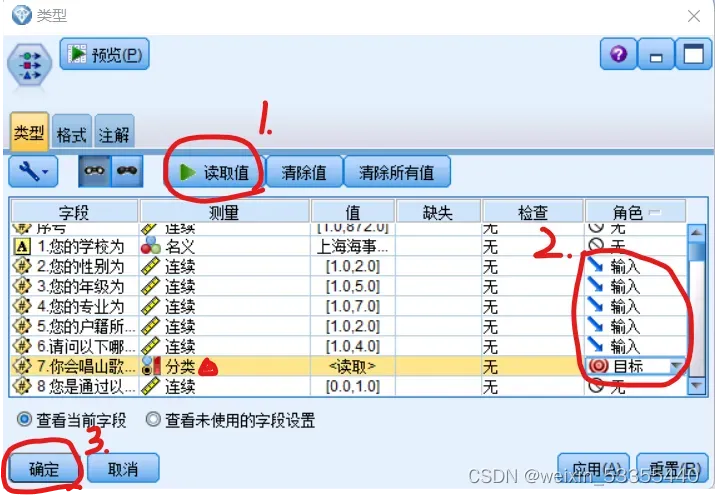
2.点击字段选项、类型,在空白得到一个类型图标

点生成的类型图标,点选取值,选择输入的数据和要预测的目标(目标测量要为分类,不能是连续),最后点确定即可。
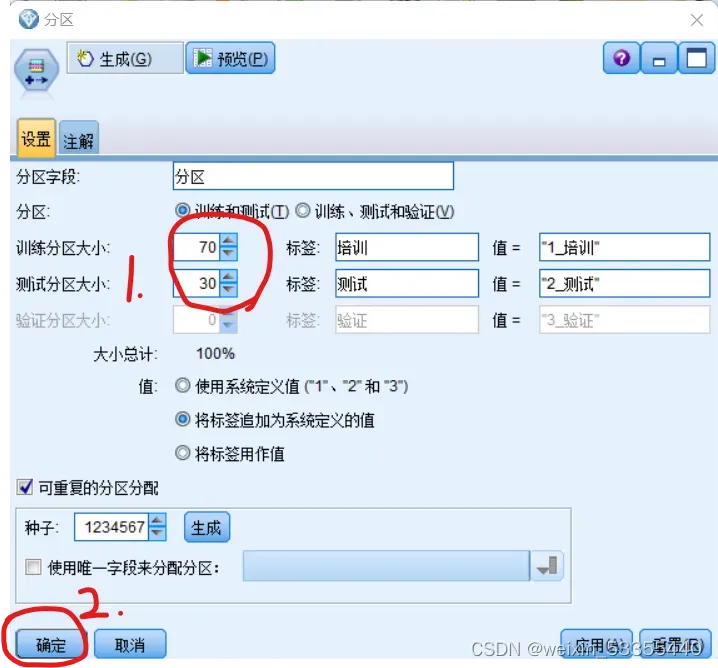
3.点击 分区,在空白处得到分区图标

点生成的分区图标,一般训练、测试分区设为70:30,之后可以根据所需调整比例,最后点确定
 4.点 建模、C 5.0,
4.点 建模、C 5.0,
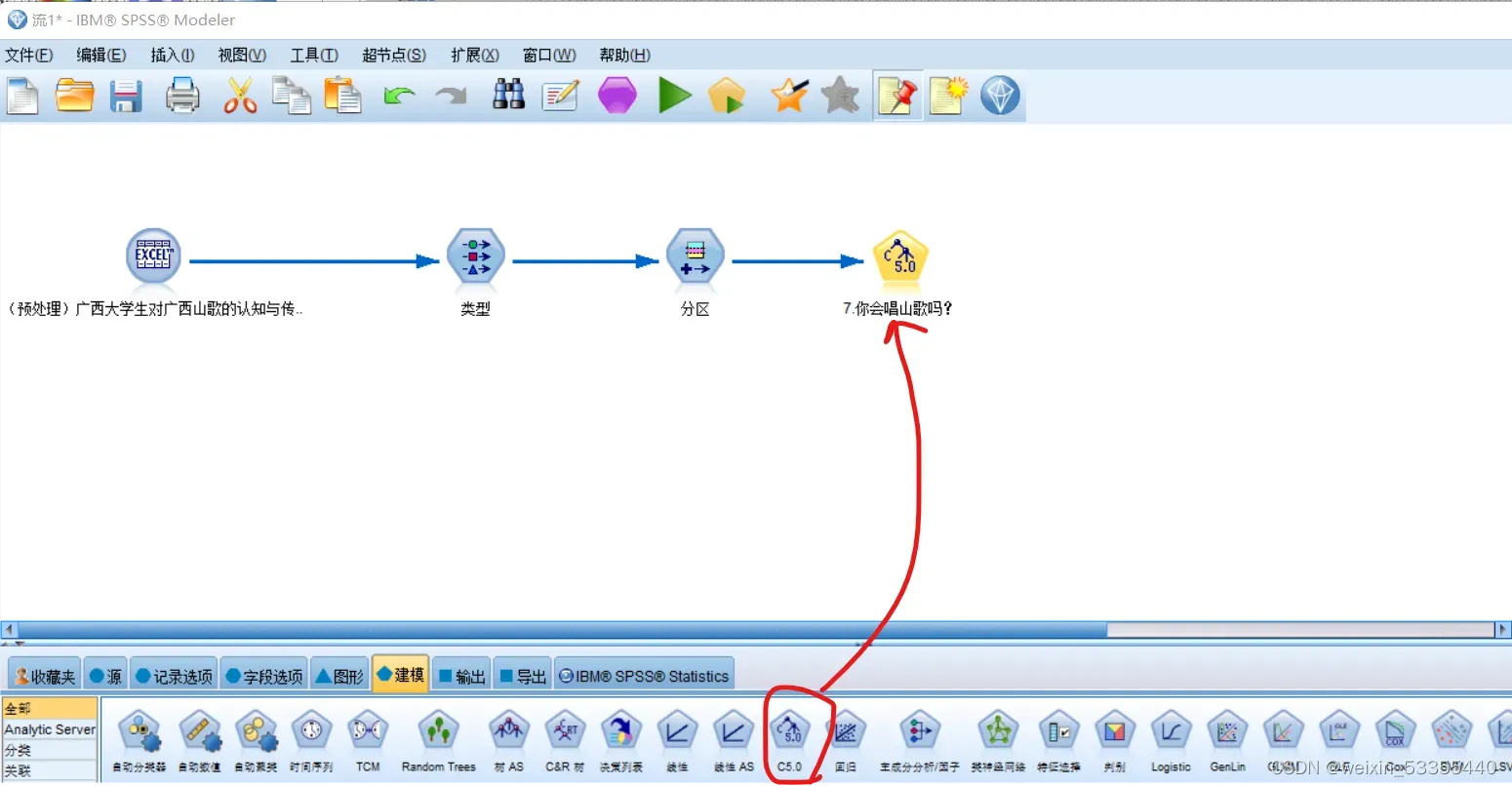
点得到的 C 5.0,点击 运行,得到结果

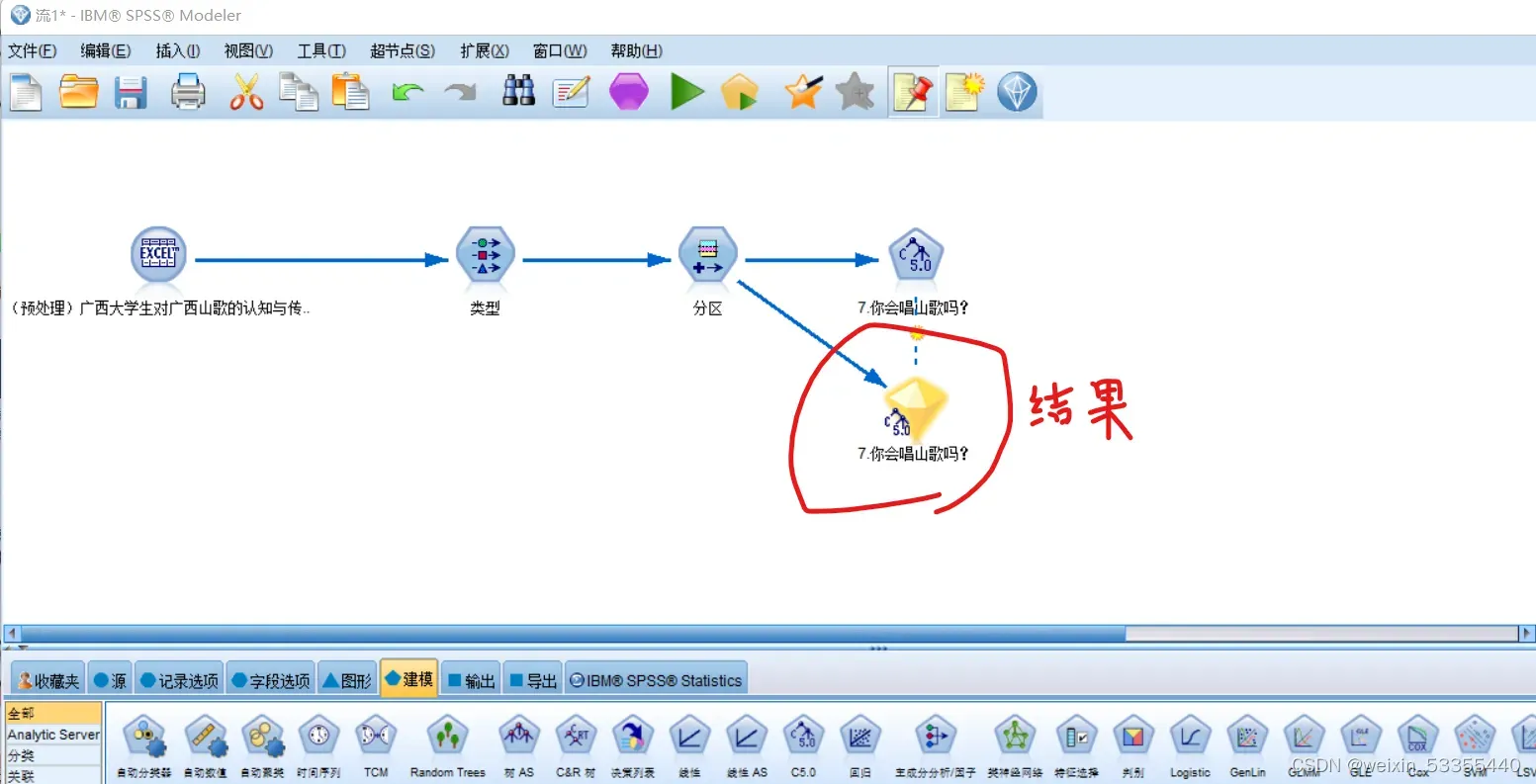
5.点击 结果,得到下图

预测变量重要性图
(个人感觉就是一些变量对目标的重要性,重要性越大,对目标影响越大)

决策树模型
(点击那个按钮可以复制这个模型)
(那个按钮右边为放大、缩小按钮,再右边三个按钮为展现数据的形式,再右边三个按钮为展现 竖立、右横着、左横着 的模型形式,可以自己试试,描述不是很清楚)
6.点 输出、分析
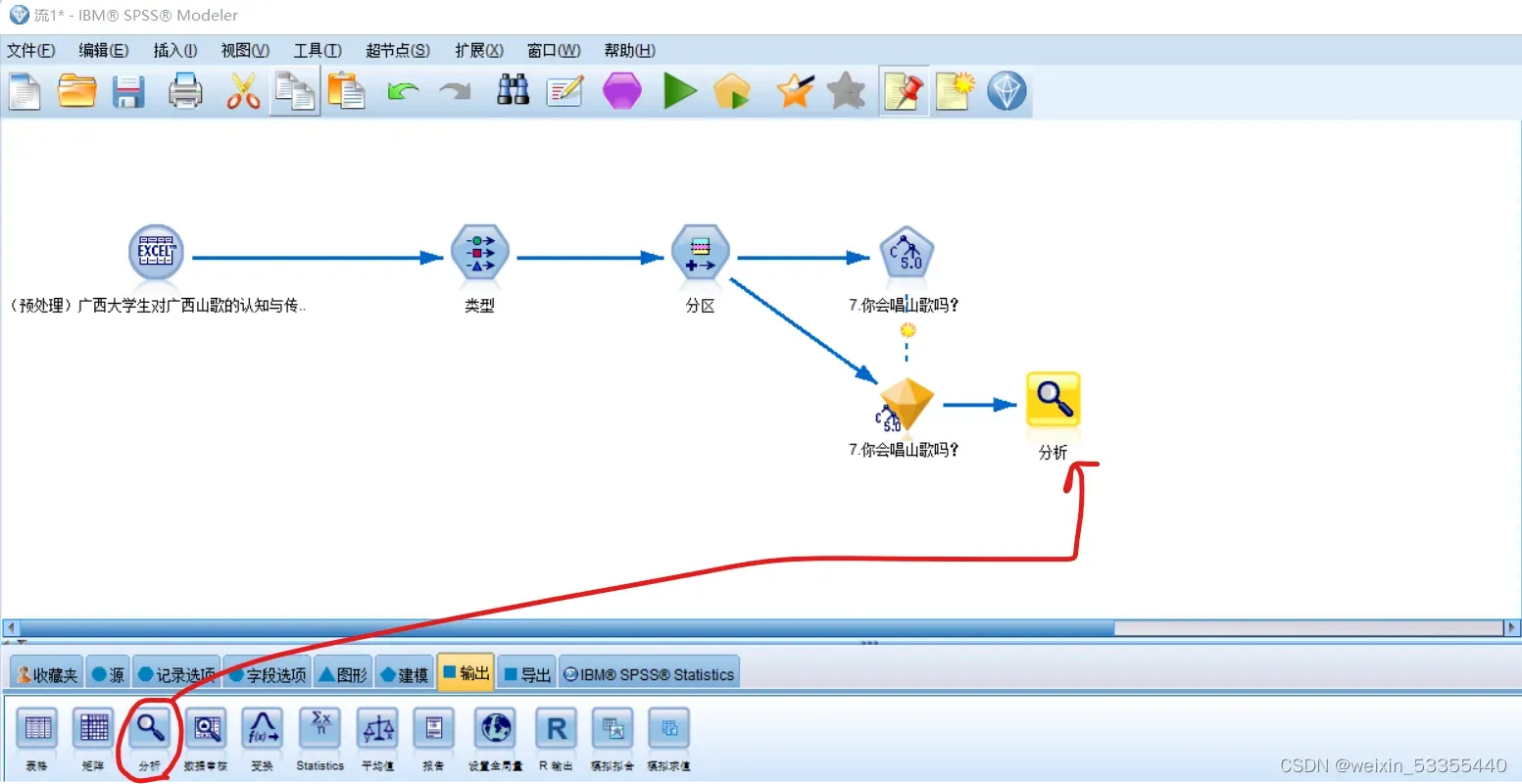
点击 分析,勾选你想要的数据(我举例子就不勾选数据了,直接默认输出),再点 运行,得到结果如下下图
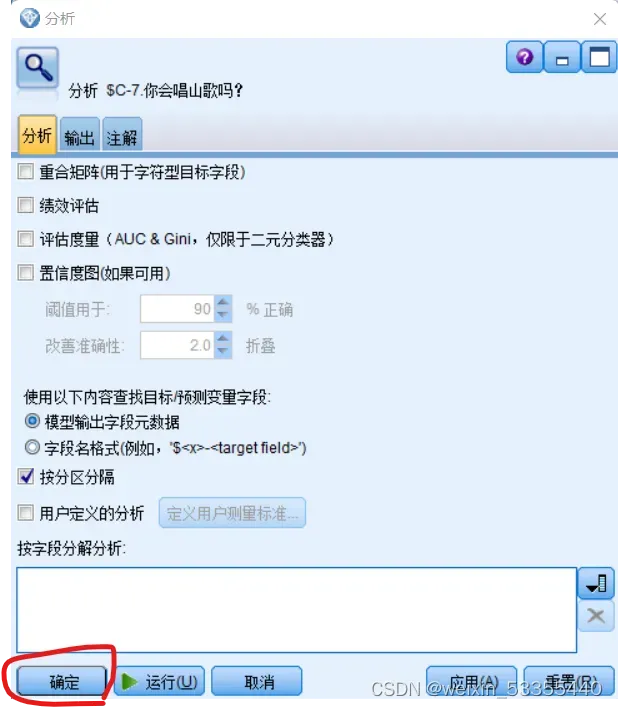

(这个结果说明 训练集预测正确率、错误率为65.31%、34.69%,预测集预测正确率、错误率为53.1%、46.9%)
(预测集正确性越高,模型准确率越高,80%以上好些)
(要提高模型准确率,可以调整训练集测试集比例、调整输入的数据)
7.结果分析(可以参考下)
比如:评估度量

(1)AUC值
AUC值一般在[0.5,1]中,0.5代表模型没有分类效果,小于0.5表示不如随机预测,大于0.5表示得到的模型比随机猜测好,AUC值越高越好。此外,AUC比准确率在对数据不平衡的数据集构建的模型有更好的评价意义。
(2)Gnini(基尼指数)
基尼指数表示在样本集合中一个随机选中的样本被分错的概率。Gini越小,表示集合中被选错的样本被参错的概率越小,也可以说是集合的纯度越高,特征越好,反之则纯度不高。
版权声明:本文为博主作者:weixin_53355440原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_53355440/article/details/129766282