目录
- 1- 单播模式,只有一个消费者组
- 2- 广播模式,多个消费者组
- 3- Java实践
kafka是由Apache软件基金会开发的一个开源流处理平台。kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
kafka中partition类似数据库中的分表数据,可以起到水平扩展数据的目的,比如有a,b,c,d,e,f 6个数据,某个topic有两个partition,一般情况下partition-0存储a,c,e3个数据,partition-1存储b,d,f另外3个数据。
1- 单播模式,只有一个消费者组
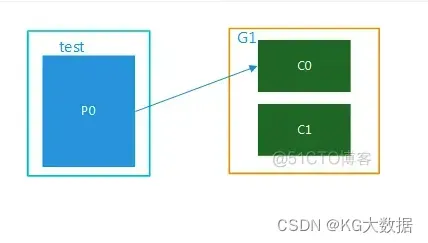
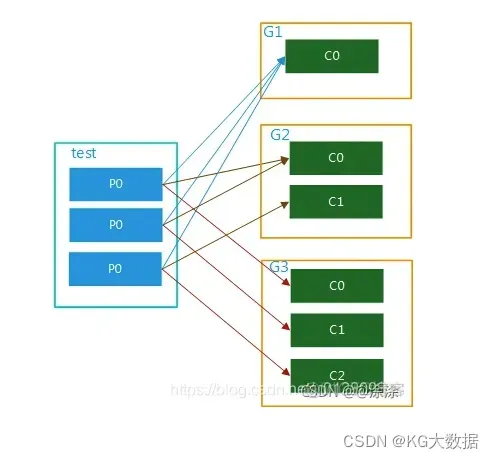
topic只有1个partition,该组内有多个消费者时,此时同一个partition内的消息只能被该组中的一个consumer消费。当消费者数量多于partition数量时,多余的消费者是处于空闲状态的,如图1所示。topic,test只有一个partition,并且只有1个group,G1,该group内有多个consumer,只能被其中一个消费者消费,其他的处于空闲状态。
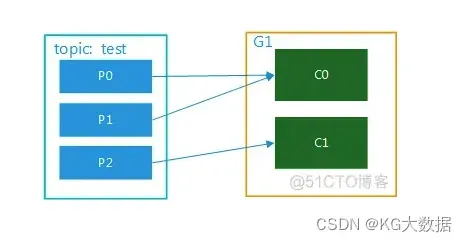
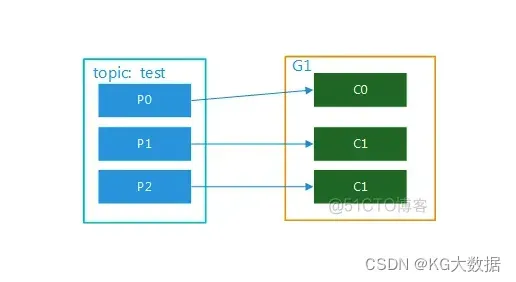
该topic有多个partition,该组内有多个消费者,比如test 有3个partition,该组内有2个消费者,那么可能就是C0对应消费p0,p1内的数据,c1对应消费p2的数据;如果有3个消费者,就是一个消费者对应消费一个partition内的数据了。图解分别如图2,图3.这种模式在集群模式下使用是非常普遍的,比如我们可以起3个服务,对应的topic设置3个partiition,这样就可以实现并行消费,大大提高处理消息的效率。
2- 广播模式,多个消费者组
如果想实现广播的模式就需要设置多个消费者组,这样当一个消费者组消费完这个消息后,丝毫不影响其他组内的消费者进行消费,这就是广播的概念。
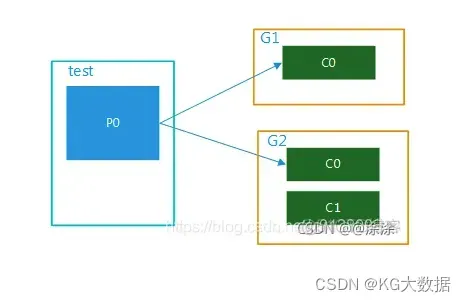
多个消费者组,1个partition;
该topic内的数据被多个消费者组同时消费,当某个消费者组有多个消费者时也只能被一个消费者消费.
多个消费者组,多个partition
该topic内的数据可被多个消费者组多次消费,在一个消费者组内,每个消费者又可对应该topic内的一个或者多个partition并行消费,如图
3- Java实践
这里使用Java服务进行实践,模拟2个parition,然后同一个组内有2个消费者的情况:
首先创建一个发送消息的controller方法:
@ApiOperation(value = "向具有kafka-2个partition的topic发送信息")
@RequestMapping(value = "/testSendMessage2", method = RequestMethod.POST)
public String testSendMessage(@RequestParam("msg") String msg) {
KafkaTemplate.send(KafkaTopicEnum.TEST_TWO_PARTITION_MSG.code,msg);
System.out.println("发送的消息是:"+msg);
return "2个partition的topic数据!--ok";
}
然后再创建一个监听类监听该topic,这里的监听类即为消费者。
/**
* @date 2020-09-24
* 两个partition的topic,同一个组的两个消费者就可以并行的消费了,需要kafka也是集群才行,单机版并不支持
* @param consumerRecord
* @param acknowledgment
*/
@KafkaListener(topics = "two-partition-msg",groupId ="serverGroup1",containerFactory = "ackContainerFactory")
public void receiveKafkaTwoParMsg(ConsumerRecord<?,?> consumerRecord, Acknowledgment acknowledgment){
InetAddress address = null;
try {
address = InetAddress.getLocalHost();
} catch (UnknownHostException e) {
e.printStackTrace();
}
System.out.println("当前的IP地址是:"+address.getHostAddress());
System.out.println("监听服务A-收到的消息是::");
System.out.println(consumerRecord.value().toString());
System.out.println("=================== end =================");
// ack 提交掉,避免服务重启再次拉取到消息
acknowledgment.acknowledge();
}
然后我们给该服务起2个实例,即模拟该组内serverGroup1内的2个消费者,然后我们使用测试方法进行测试,向该topic内发送多个消息,观察2个实例的输出日志:
实例1:
发送的消息是:111
当前的IP地址是:10.244.3.114
监听服务A-收到的消息是::
“111”
=================== end =================
发送的消息是:222
发送的消息是:333
当前的IP地址是:10.244.3.114
监听服务A-收到的消息是::
“333”
=================== end =================
发送的消息是:444
发送的消息是:555
当前的IP地址是:10.244.3.114
监听服务A-收到的消息是::
“555”
=================== end =================
发送的消息是:666
发送的消息是:777
当前的IP地址是:10.244.3.114
监听服务A-收到的消息是::
“777”
=================== end =================
发送的消息是:888
发送的消息是:999
当前的IP地址是:10.244.3.114
监听服务A-收到的消息是::
“999”
-----------------------------------
实例2:
当前的IP地址是:10.244.0.237
监听服务A-收到的消息是::
“222”
=================== end =================
当前的IP地址是:10.244.0.237
监听服务A-收到的消息是::
“444”
=================== end =================
当前的IP地址是:10.244.0.237
监听服务A-收到的消息是::
“666”
=================== end =================
当前的IP地址是:10.244.0.237
监听服务A-收到的消息是::
“888”
发现该组内的一个消费者消费到了111,333,555,777,999 ,另外一个消费者消费到了222,444,666,888,起到了均衡消费的效果。
所以在微服务的集群中,我们可以通过给topic设置多个partition,然后让每一个实例对应消费1个partition的数据,从而实现并行的处理数据,可以显著地提高处理消息的速度。
版权声明:本文为博主作者:KG大数据原创文章,版权归属原作者,如果侵权,请联系我们删除!