Inpainting论文阅读2020-2023
- Rethinking Image Inpainting via a Mutual Encoder-Decoder with Feature Equalizations (2020 ECCV)
解决问题:之前方法通常使用两个编码器-解码器来进行单独的恢复。学习每个编码器的CNN特征以捕获缺失的结构或纹理,而不将它们作为整体来考虑。并且在第二个阶段进行细节修复是基于image level上。
方法:在单阶段网络中并且在feature层级上修复图像的纹理和结构,并且将修复好的纹理和结构组成一张完整的特征图从而达到修复的效果。
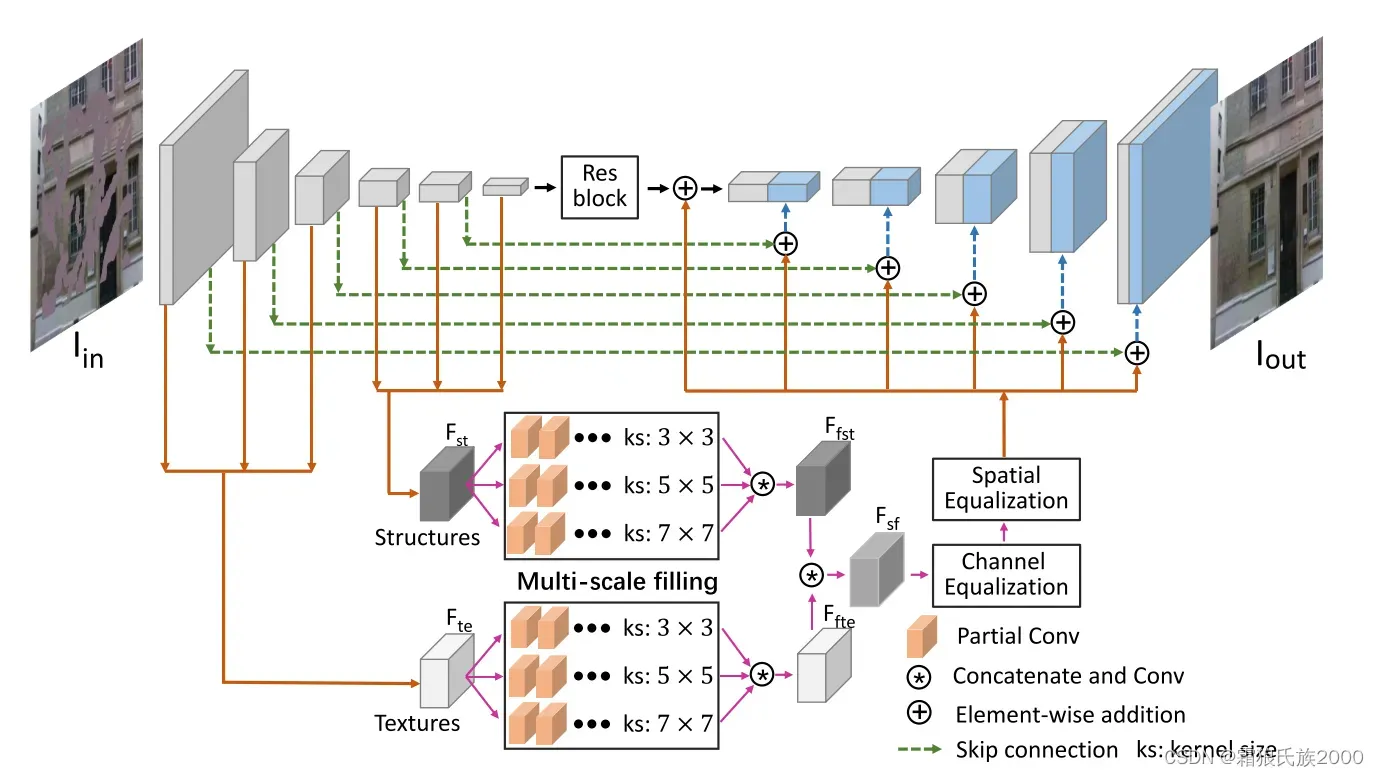
2.Region Normalization for Image Inpainting (2020 AAAI)(即插即用的方法)
解决问题:将损坏的图像输入到神经网络中可能会产生问题,例如无效像素的卷积以及归一化的均值和方差。但是,当前方法无法解决网络中的均值和方差偏移问题。当前方法大多采用 feature normalization(FN) 进行训练,这些FN方法大多在空间维度上进行归一化,忽略了损坏区域对归一化的影响。
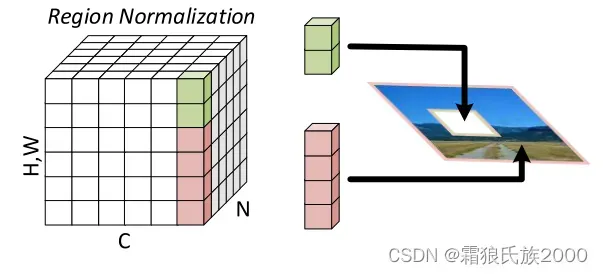
方法:在这篇论文中,作者提出Region normalization(RN)来解决上述问题。根据输入的mask将像素划分为不同的区域,并计算每个区域的均值和方差来实现归一化。
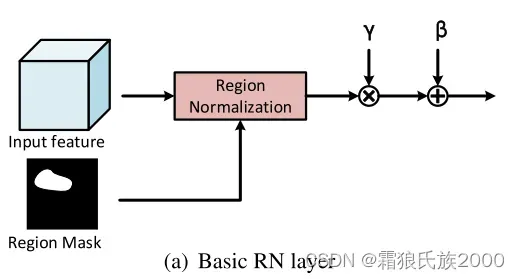
在实现细节上,作者提出两种RN,一个是basic RN,另一个是learnable RN。basic RN如下图所示。对未损坏区域、损坏区域分别归一化,然后会有两组affine transformation参数。在网络的前面几层中,输入图像具有较大的损坏区域,会导致严重的均值和方差漂移。因此,使用RN-B通过分区域归一化来解决这一问题。
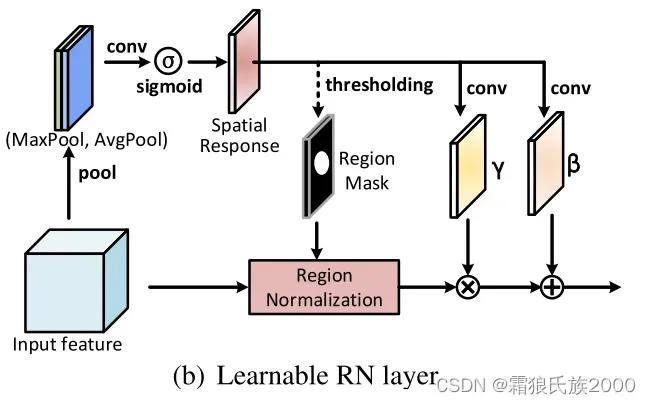
经过多个卷积层以后,未损坏区域和损坏区域会融合在一起,这时仍然使用region mask就不可靠了。这个时候,使用RN-L,利用输入特征的空间关系来检测损坏区域,为RN生成region mask。RN-L如下图所示,首先使用 maxpool和 avgpool 得到两个feature map并拼接在一起。然后使用sigmoid函数得到一个spatial response map。最后,通过阈值得到 region mask。在论文里,t=0.8。
作者使用了 EdgeConnect 方法的架构。(EdgeConnect包括一个 edge generator 和一个 image generator),在本文中,作者使用了 image generator 做为基础网络。同时,作者把 instance normalization 替换为 RN, RN-B, RN-L. 整体架构如下图所示。
贡献:提出了两种即插即用的RN模块,可以方便地应用到其他图像修复网络。
3.LARGE SCALE IMAGE COMPLETION VIA CO-MODULATED GENERATIVE ADVERSARIAL NETWORKS (2021 ICLR)
解决问题:由于当前模型缺乏潜在的生成能力,它们处理存在大范围缺失区域图像时效果会不理想;无条件的GAN网络随机性的缺乏使得它们很难推广到只有有限的条件信息可用的环境中;现有的图像评价指标不能很好的体现随机生成并且不适合GAN。
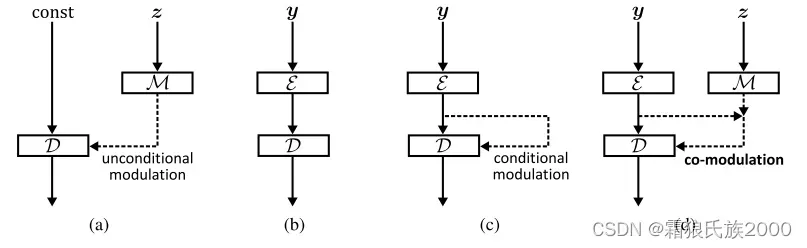
方法:通过协同调制方法让调制无条件生成器的生成能力媲美条件生成器。通过引入P-IDS和U-IDS指标提升对生成图像的评估能力。
贡献:弥合了条件和无条件调制生成架构之间差距,显着提高了不规则掩膜的大规模图像完成,并且很容易推广到图像到图像的转换。
4.Contextual Residual Aggregation for Ultra High-Resolution Image Inpainting (2020 CVPR)
解决问题:由于内存的限制,当前修复方法只能处理低分辨率的输入。
方法:受到将高频残差图像添加到大的模糊图像上可以产生清晰的结果且具有丰富的细节和纹理这一原理的启发,本文提出了一种上下文残差聚合(CRA)机制,该机制可以通过对来自上下文补丁的残差进行加权聚合来为丢失的内容产生高频残差,从而仅需要来自网络的低分辨率预测。具体来说,我们使用神经网络来预测低分辨率的修复结果,并对其进行上采样,以产生一个大的模糊图像。然后,我们产生的高频残差孔补丁聚合加权高频残差的上下文补丁。最后,我们将聚合残差添加到大的模糊图像中以获得清晰的结果。
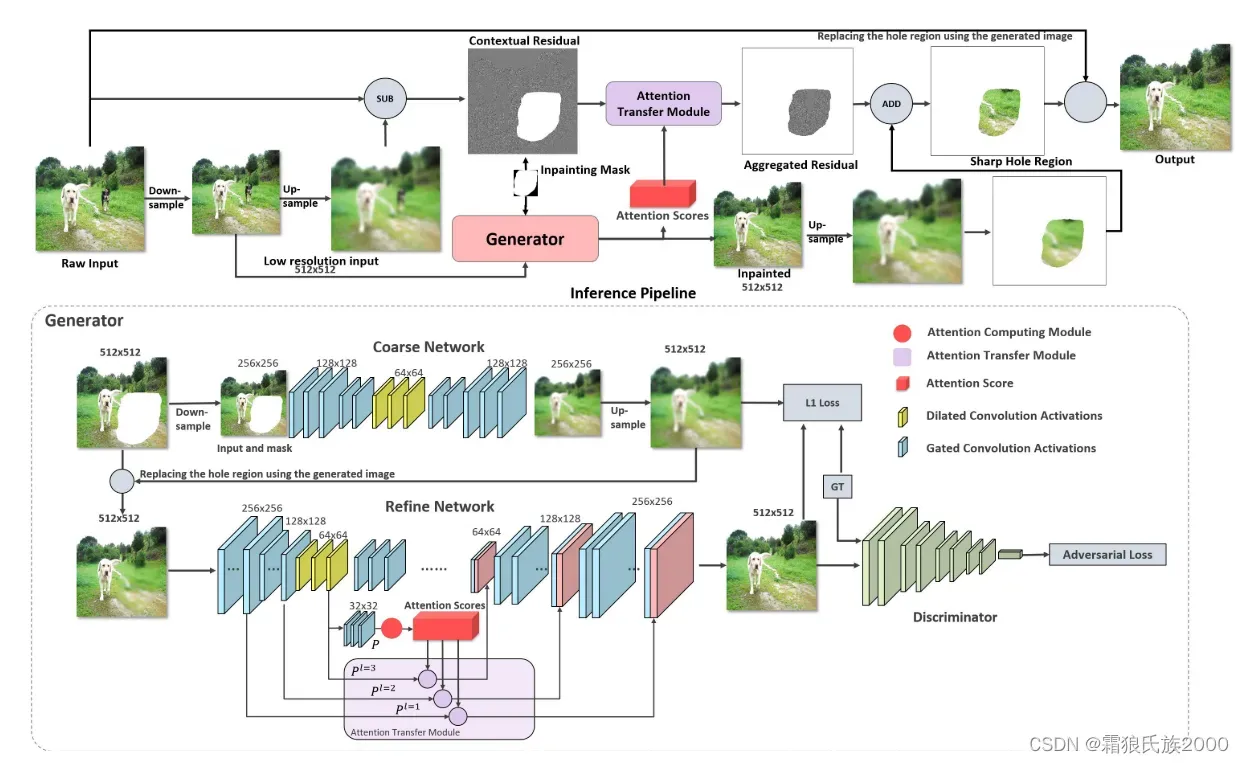
步骤:首先,将图像下采样,然后对其进行上采样,以获得与原始输入相同大小的模糊大图像。生成器获取低分辨率图像并填充孔洞,注意力计算模块(ACM)进行注意力分数的计算。此外,通过从原始输入中减去大的模糊图像来计算上下文残差,然后通过注意力转移模块(ATM)从上下文残差和注意力分数计算掩模区域中的聚合残差。最后,将聚合的残差添加到上采样的经修复的结果在掩模区域中生成大的尖锐输出,而掩模外部的区域仅仅是原始原始输入的副本。
上下文残差聚合模块(CRA):包含注意力计算模块(ACM)和注意力转移模块(ATM)
总结:本文提出了一种新的上下文残差聚合技术,实现更有效和高质量的超高分辨率图像修复,运用于超高分辨率图像时十分高效。
5.Resolution-robust Large Mask Inpainting with Fourier Convolutions (2022 WACV) (SOTA)
解决问题:当前图像修复技术,尽管取得了显著的进步,面对大的丢失区域,复杂的几何结构,和高分辨率的图像往往会比较棘手。我们发现其中一个主要原因是修复网络和损失函数都缺乏有效的感受野。
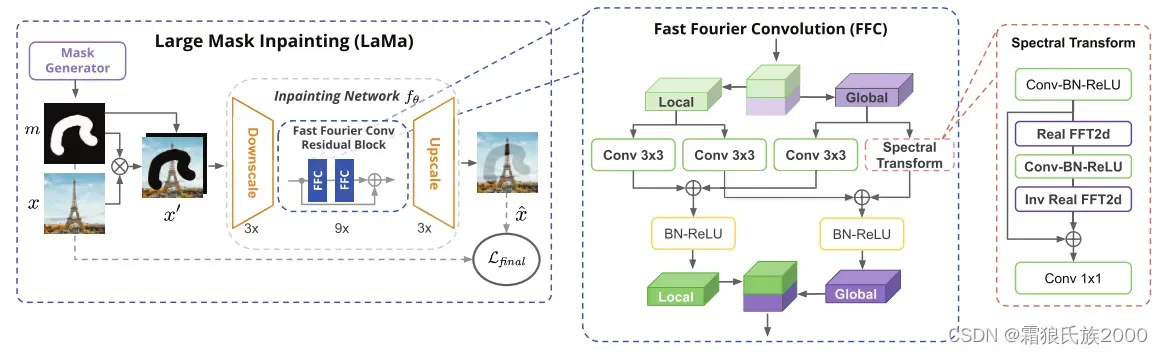
方法:图像与掩膜组成pair对输入网络并经过下采样后,进入FFC残差块。在FFC块中,输入tensor被划分为两个分支进行运算。Local分支使用常规卷积;Global分支使用Real FFT进行全局上下文关注。
损失函数:首先需要明确的是,对一个被掩膜遮盖的区域其实可以有多种合理的填充结果,就像口罩下的长相谁也无法准确预测。所以一旦掩膜变大,那么loss就必须被更加合理地设置以避免不符合事物逻辑的生成。
![]()
损失函数包括:高感受野知觉损失 HRFPL,对抗损失,鉴别器网络LDiscPL特征的感知损失,和R1梯度惩罚
6.Recurrent Feature Reasoning for Image Inpainting(2020 CVPR)
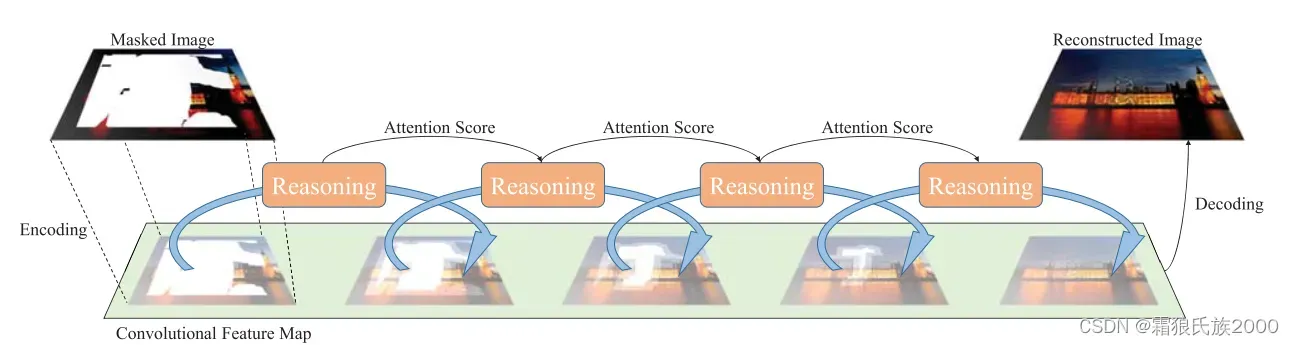
解决问题:
1.由于缺乏对孔中心的约束,填充大而连续的孔洞仍然是困难的。
2.当前的渐进式修复方法因不使用循环设计而造成模型冗余。此外,因为渐进式修复是在图像级执行的,所以计算成本使得这些方法不太实用。并且网络的输入和输出需要在同一空间中表示,反复地在特征图和RGB图之间转化可能导致信息失真。
作者把循环渐进的机制放在了特征图层面上进行,就能缓解问题2
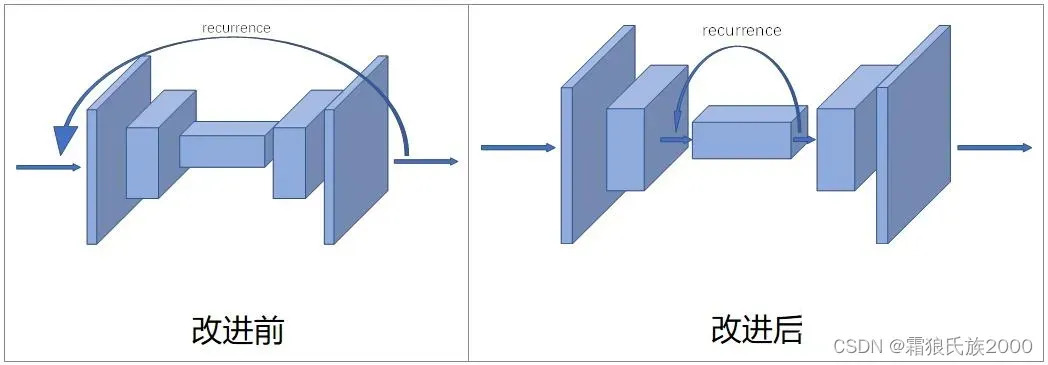
3.当前的运用注意力机制的修复方法所使用的注意力模块(CA,Deepfill v1,Deepfill v2,CSA等)没有考虑不同递归中的特征图之间的一致性要求。这可能导致恢复区域的纹理模糊。
方法:
1.本文设计了一个即插即用的循环特征推理(RFR)模块,以循环地推断和收集的编码特征图的孔边界。
2.与现有的渐进方法不同,RFR模块在特征图空间中执行这种渐进过程,这不仅确保了高层级性能,而且解决了网络的输入和输出需要在同一空间中表示的限制。循环设计重用这些参数,以提供更轻量的模型。此外,通过在网络中上下移动模块,可以灵活地控制计算成本。这对于构建高分辨率修复网络至关重要,因为避免第一层和最后几层的计算可以消除大部分计算负担。
3.本文提出了一个认知连贯注意力机制(KCA),融合了相邻两次循环中的信息来计算attention socre来控制特征图的不连续性。作者的KCA约等于传统的attetion外加了相邻两次循环的信息融合。
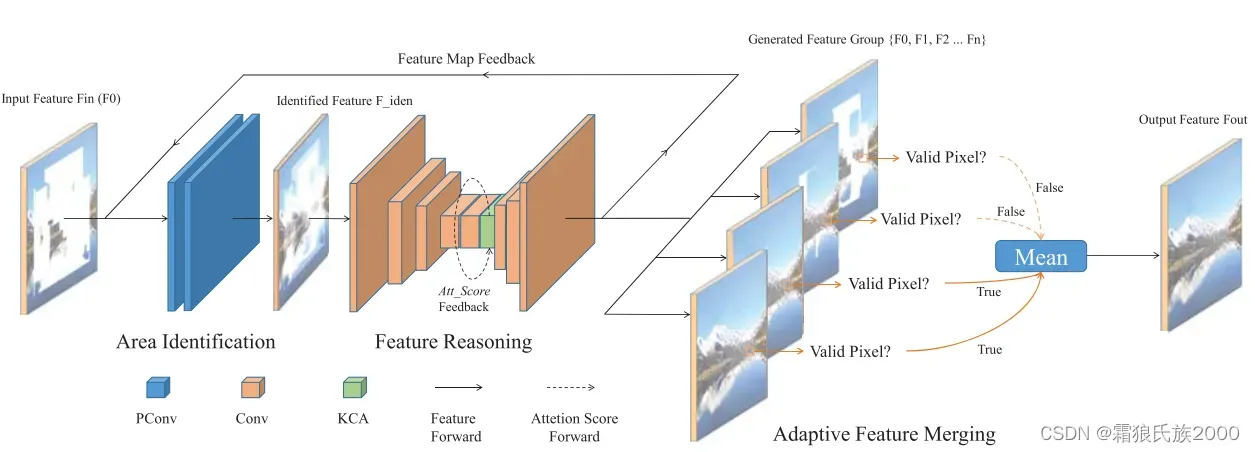
RFR模块:包含三个模块,即区域识别模块,特征推理模块,特征融合模块。
区域识别模块:运用部分卷积生成特征图和待推断区域(更新后的掩码与初始掩码之间的区域),特征图在被发送到特征推理模块之前由归一化层和激活函数处理。
特征推理模块:在推断出特征值之后,特征图将被发送到下一次循环,生成多张特征图,这里整合了KCA模块。
特征融合模块:将多次循环输出的多个特征图融合成一个特征图。这会在特征图的空洞已经被完全填充,或者循环次数达到了上限(比如作者在代码里设置的是6次)时发生。融合的过程是,把这6次循环在输出层的有效的结果拿出来计算平均值,就得到融合后的特征图。
有效的含义:即特征图对应的二值掩模值是1,也就是被填充过的部位方为有效。例如,特征图在(x,y)位置在6次循环中的值是A,B,C,D,E,F(注意它们都是带有通道数的向量),而对应的掩模值是0,0,1,1,1,1,这意味着前两次循环该位置没有被填充,直到第3次开始,该位置被填入值。那么(x,y)位置融合后的特征值是(C+D+E+F)/4。对此作者的原文表述是:The values in the output feature map are only calculated from the feature maps whose corresponding locations have been filled.
KCA模块:与传统的注意力机制大体类似,但是每一轮计算的注意力分数都会与上一次循环的分数进行加权融合。
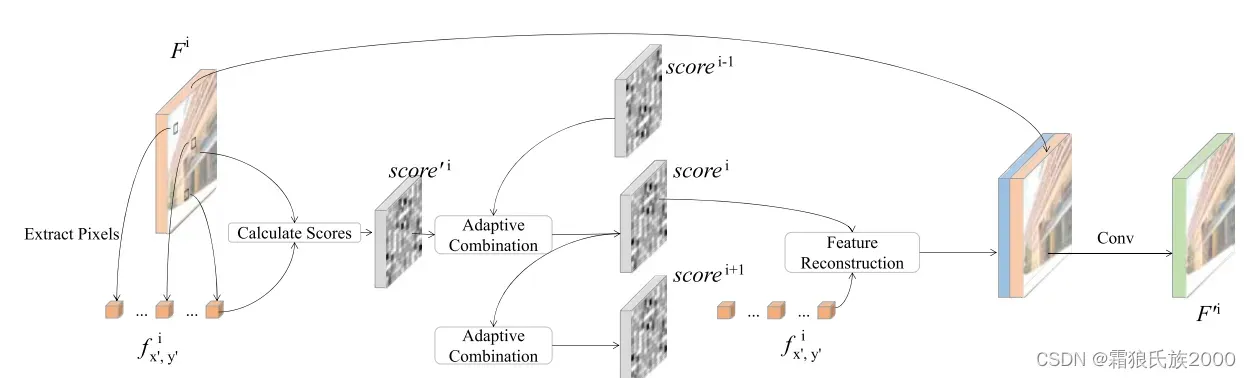
贡献&创新点:1.循环推理模块
2.KCA机制
7.Generative Memory-Guided Semantic ReasoningModel for Image Inpainting(TCSVT 2022)
解决问题:用于语义图像修复的典型方法通过学习从受损图像到修复版本的一对一映射来训练编码器-解码器网络。虽然这样的方法在具有小损坏区域的图像上表现良好,但是由于两个潜在的限制,这些方法在损坏区域比较大的图像中表现欠佳。
1.这种一对一映射范例倾向于过拟合每个单个训练图像对。
2.关于视觉语义的一般分布模式的图像间先验知识(其可以在共享相似语义的图像之间传递)没有被明确地利用。
通过预训练的GAN作为先验来重建图像也存在三个主要问题:
1.预先训练好的解码器仅凭语义推理很难合成精美的细节
2.语义查询的方式仅依赖于一个高度耦合的嵌入来控制不同特征尺度的所有类型的语义
3.Vanilla GAN具有有限的生成性能来为大部分损坏的区域提供复杂的语义。因此,该方法仅对具有小损坏区域的图像显示有效性,但不能处理具有大损坏区域的情况。
方法:本文提出生成记忆引导的语义推理模型(GM-SRM),不仅基于完好区域进行推断,并且也借助了表征相似图像之间的可泛化语义分布模式的图像间推理先验。具体地说,就是先从整个训练数据中获取语义分布的先验知识。
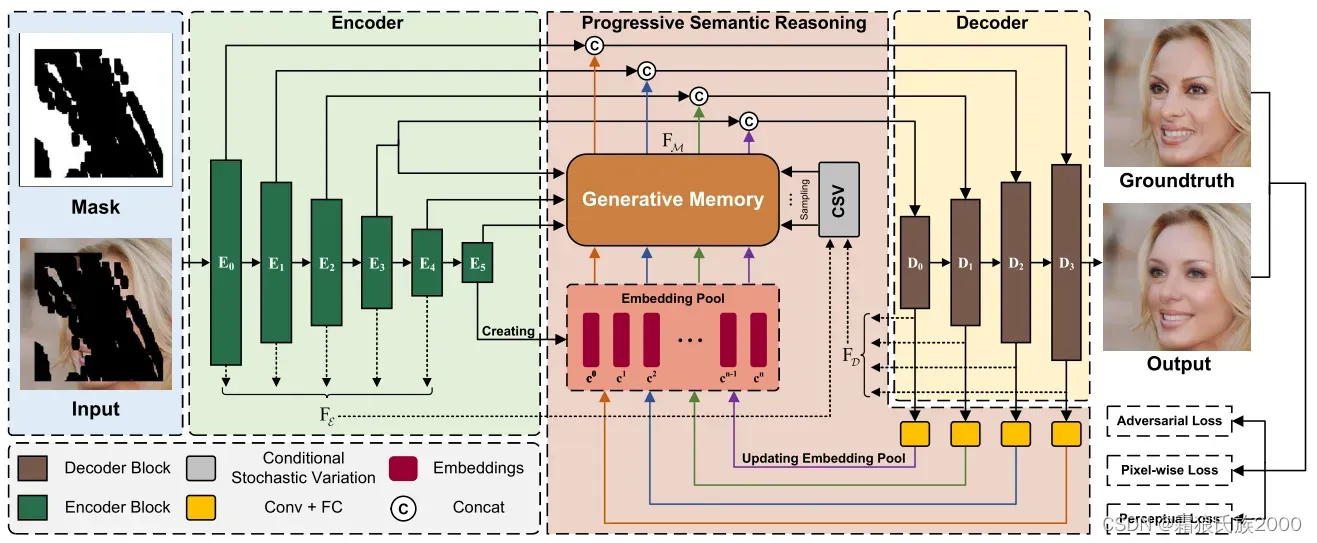
生成存储器(Generative Memory):是一个基于StyleGAN的生成网络的分布学习器,从训练数据学习视觉语义的一般分布模式,并指导推断与输入图像中的已知区域语义一致的缺失区域的内容。
条件随机变分器(Conditional Stochastic Variation):引入噪声条件下的已知区域的语义到生成存储器的合成过程中,以丰富合成图像的外观细节,同时保持语义正确。和典型的StyleGAN不一样,CSV对相邻的编码特征和解码特征进行采样。
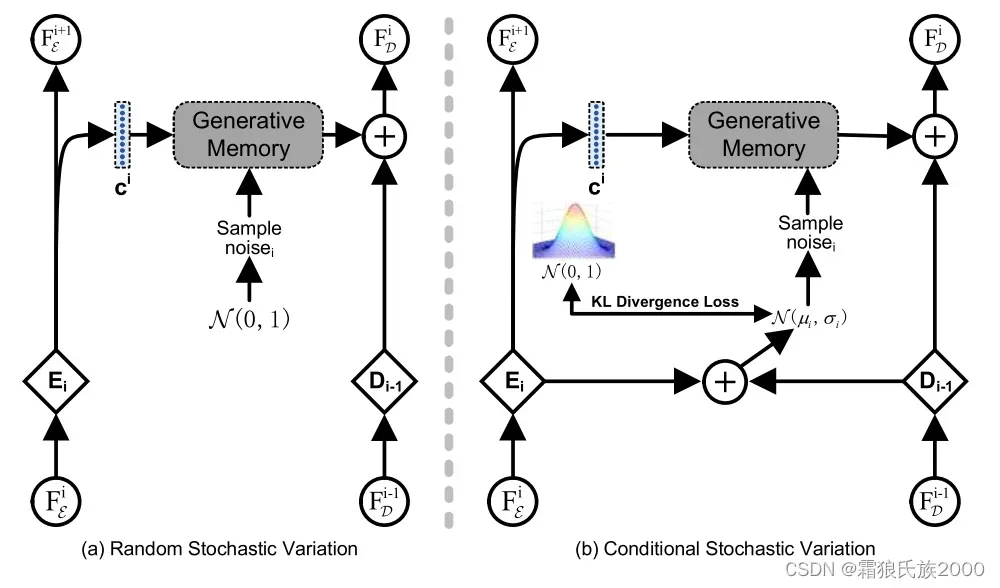
渐进式语义推理(Progressive Semantic Reasoning): 存储器M和解码器D能够以迭代的方式协作地执行图像修补:将M推断的语义特征馈送到D中,以提供用于解码相同分辨率的特征图的高级语义线索,而解码的特征图又被提供给M以更新嵌入池以用于更大规模的先验知识推断的下一尺度。
8.Perceptual Artifacts Localization for Inpainting(ECCV 2022)
解决问题:图像修复往往会产生伪影,用户倾向于通过这些伪影来判断修复性能。虽然这些修复伪影很容易被人类识别,但很少有研究开发了模型来自动检测和定位修复结果中的这些伪影。
在许多情况下,图像修复用于前景对象去除。用户更喜欢视觉上合理的背景生成,而不是忠实的前景重建。当前缺乏一个定量的指标来度量修复效果。
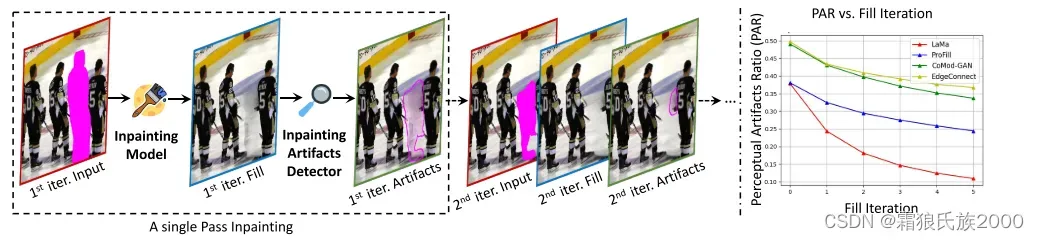
方法:首先将具有mask的输入图像馈送到修复模型中以生成填充图像。然后,填充后的图像被馈送到我们的感知伪影分割模型中,以检测伪影区域,伪影区域将被转换为孔掩模用于下一次迭代修复。
细节:1.不同于传统的mask,本文选择图像分割领域的Mask R-CNN生成目标去除的mask。
2.本文使用Lama作为基础inpainting模型
3.与洋葱式修复(由外及内逐步填充mask)不同,该方法是在填充完毕后,定位到伪影区域作为新的待填充区域。
9.High-Resolution Image Inpainting with Iterative Confidence Feedback and Guided Upsampling(ECCV 2020)
解决问题:现有的图像修复方法在处理真实的应用中的大面积mask时往往会产生伪影。在修复失败的案例中,尽管存在伪影,但是也同时存在良好的子区域。
方法:本文提出了一种新的迭代修复方法与反馈机制,运用了扩展上下文注意力模块,在生成修复结果时,联合预测置信度图作为下一次迭代修复的反馈,实现渐进性修复。本文的方法包含两个模型:含置信度反馈的迭代修复模型和引导式上采样网络。
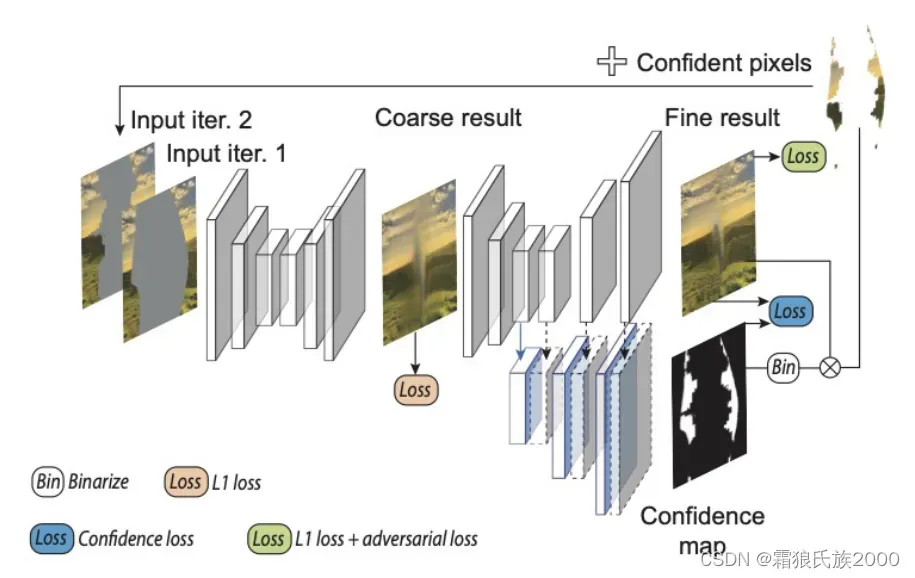
**含置信度反馈的迭代修复模型:**两项损失,分别是对抗损失和置信预测损失
**置信预测损失:**置信图C会尽可能地覆盖具有最小局部损失值(重建损失)的像素集合。
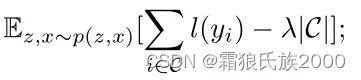
上式中的前一项就是对置信的pixel计算loss,后一项是正则-希望多置信点pixel(不加这项网络就选择全都不置信让loss小了),C代表置信的pixel集合。
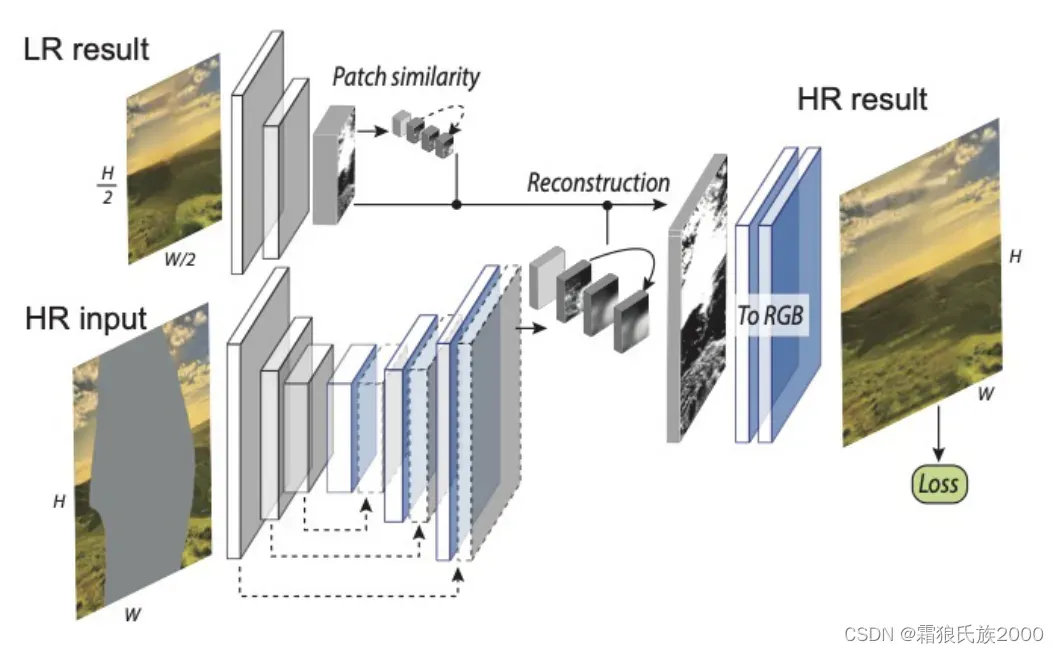
引导式上采样网络:因为训练过程是在低像素图像中进行的,因此需要该网络将任务迁移至高像素图像,类似于超分重建任务。具体地说,就是给定低分辨率图像及其修复结果,运用上下文注意力模块来引导其对应的高分辨率图像的修复。
**总结:**1.这是首次尝试在修复中对预测的置信度进行建模,也是首次使用置信度驱动的反馈循环来填充漏洞的迭代修复方法。
10.CR-Fill: Generative Image Inpainting with Auxiliary Contextual Reconstruction(ICCV 2021)

解决问题:传统的上下文注意力机制(Deepfillv1,Deepfillv2),由于缺少用于缺失区域和已知区域之间的对应关系的监督信号,可能无法找到适当的参考特征,这通常导致结果中的伪影。此外,在推理期间计算整个特征图的成对相似性,带来了显着的计算开销。
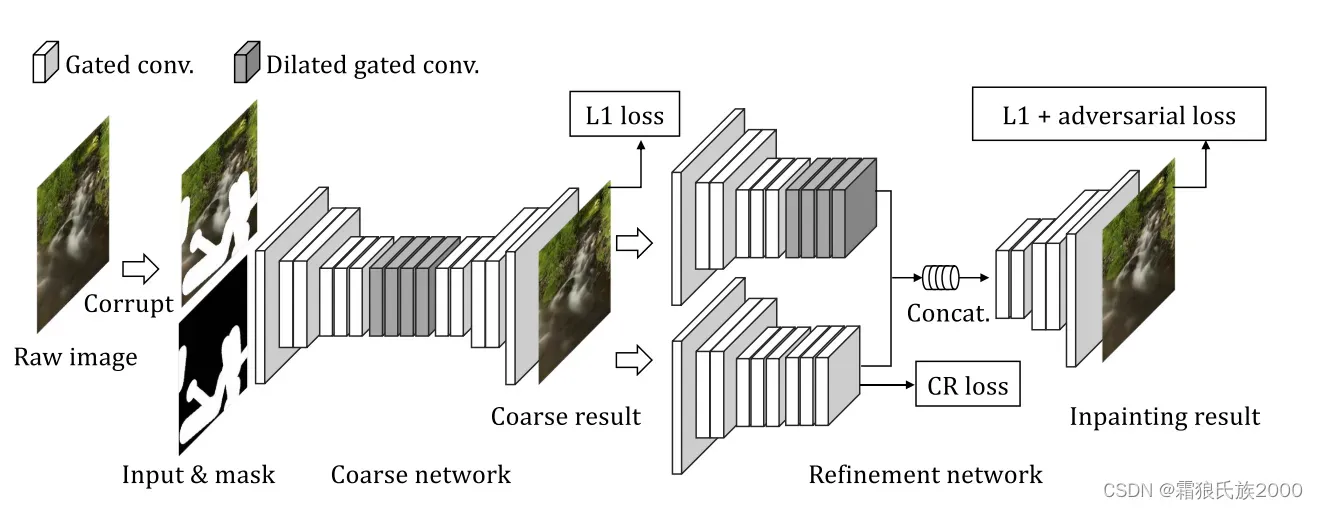
方法:避免显式地使用上下文注意力模块,即依据余弦相似度选取补丁块作为缺失区域地填充。在二阶段网络中添加一个辅助网络分支,在模型训练时优化上下文注意力模块的补丁选择。具体地讲,上分支负责计算相似度,作为下分支待修复区域的素材,下分支保留原始区域,通过CR loss来约束修复效果,即,选取的补丁块能够使得CR loss尽可能的小,将上下文注意力模块变成一个可学习的模块。
**贡献:**优化了传统的上下文注意力机制,提升了其可控性。
11.Aggregated Contextual Transformations for High-Resolution Image Inpainting(TVCG 2021)
解决问题:
1.为了推断缺失区域的合理内容,深度图像修复模型常常利用图像上下文的特征。但是由于图案重复的问题,逐块匹配经常导致扭曲的结构。
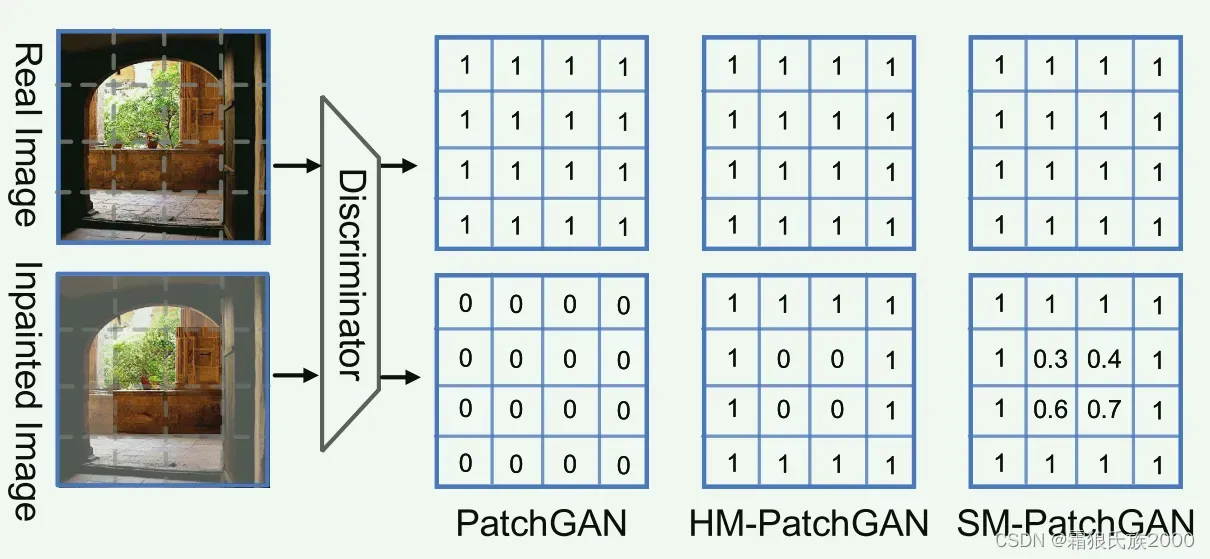
2.为了合成更具备细粒度的纹理结构,大多方法都采用了PatchGAN。PatchGAN的补丁旨在区分真实的图像的补丁和修复结果的补丁。然而事实上,缺损区域外的真实图像补丁和修复图像补丁是一致的。
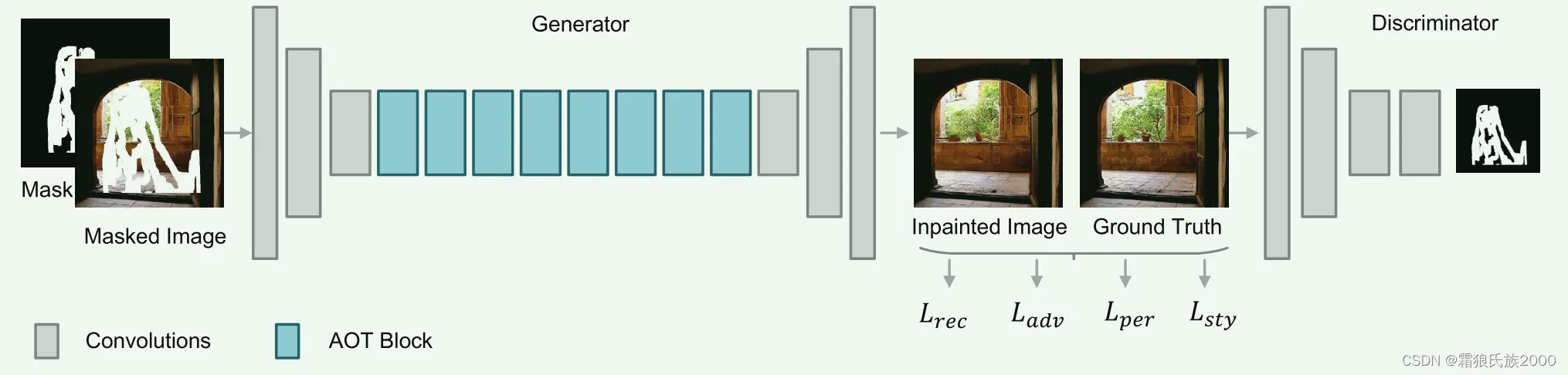
**方法:**提出了一个基于GAN的上下文聚合网络AOT-GAN,它增强了高分辨率图像修复的上下文推理和纹理合成。该网络由生成器网络和生成器网络组成。
1.生成器是通过堆叠多层精心设计的构建块(即AOT块)来构建的。AOT块能够捕获信息丰富的远距离上下文和丰富的感兴趣的模式,以增强上下文推理。
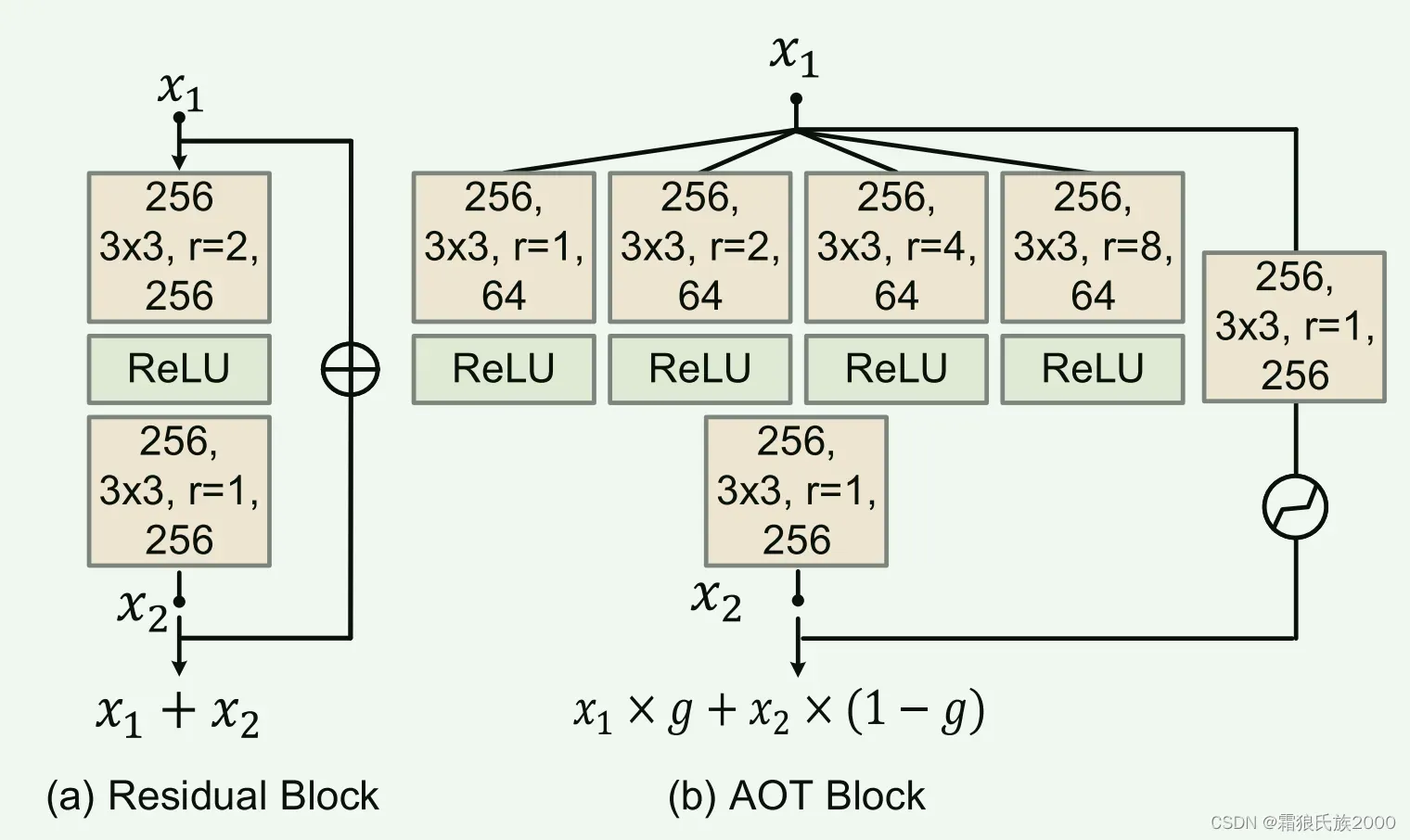
较大的r使子核能够感受野更大,而使用较小r的子核则专注于较小感受野的局部图案。
2.改进传统的Patch-GAN,提出了一种新的软门控Patch-GAN(SM-PatchGAN),一定程度上解决了PatchGAN“一刀切”的不足。
总结:
1.实现了高分辨率的修复(512*512)。
2.将残差块进行了优化,提升了网络的感受野,增强了上下文推理能力。
3.改进了Patch-GAN,使其更符合inpainting的任务需求。
12.Image Inpainting With Local and Global Refinement(TIP 2022)
解决问题:
1.对于图像修复任务,修复不同类型的缺失区域所需的周围区域的大小是不同的,并且非常大的感受野并不总是最佳的,特别是对于局部结构和纹理。大的感受野往往涵盖更多非期望值的修复结果,这将干扰修补过程。
2.之前的双阶段修复方法往往在两个阶段的网络设计近似,因此它们的感受野也十分接近,并且它们很少关注到精化网络中感受野大小的影响。
方法:
首先类比了三种不同的网络结构:1)具有大感受野的U-Net网络(大于输入图像分辨率),表示为“C”;(2)一个U-Net网络加上一个具有小感受野的浅网络(大约是输入分辨率的四分之一),表示为“C+F_S”;(3)一个U-Net网络加上另一个具有大感受野(大于输入图像分辨率)的U-Net网络,表示为“C+F_L”。
得出结论:具有小感受野的网络对于修复局部结构和纹理更有效,而具有大感受野的网络对于修复长距离细节和大结构更有用。

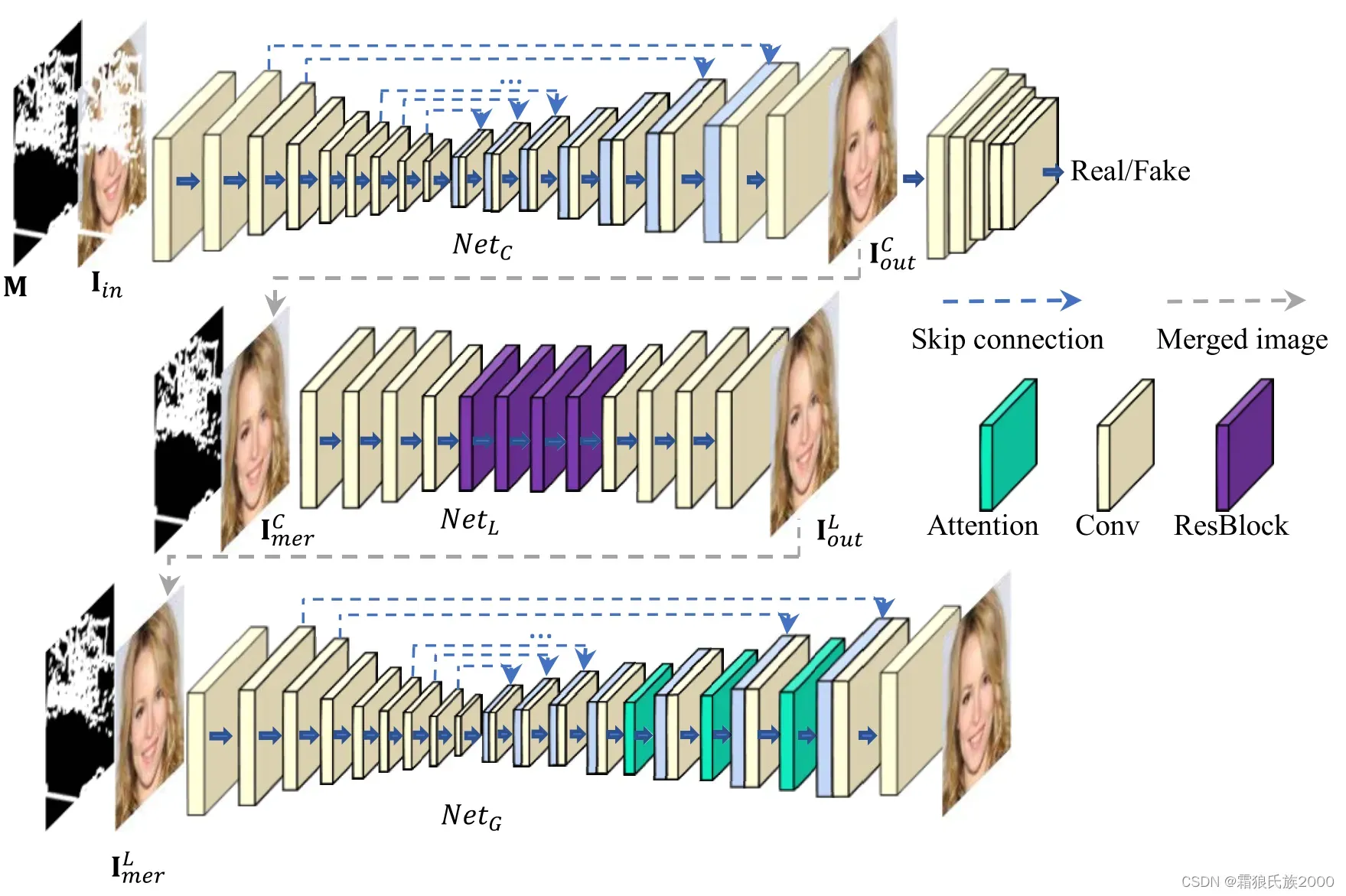
本文提出了三阶段修复网络,将具有不同感受野的网络结合起来。包括:具有较大感受野的粗修复网络,具有较小感受野的局部精化网络,基于注意力的全局精化网络(具有较大感受野)。
**具有较大感受野的粗修复网络:**采用含跳跃连接的编解码器网络结构,具有较大感受野,有利于整体结构的生成。
**局部精化网络:**具有较小的感受野,有利于局部结构和纹理的修复。
**基于注意力的全局精化网络:**引入了一个基于注意力的全局精化网络,通过两种方式来扩大神经元捕获信息的范围,即,较大的感受野和注意力机制。
**总结:**1.不同于以往的多阶段网络设计,该方法更加精确了每个阶段网络的职能,采用了不同的架构来达到特定的目的。
2.考虑到了不同的场景,并剖析了不同网络结构之于这些场景的优劣之处。
3.三阶段网络资源开销可能会比较大,训练难度较高。
13.Keys to Better Image Inpainting: Structure and Texture Go Hand in Hand(WACV 2023)
**解决问题:**当前的图像修复算法对于结构和纹理的生成能力不足,而这是判断修复算法性能的重要依据。
方法:
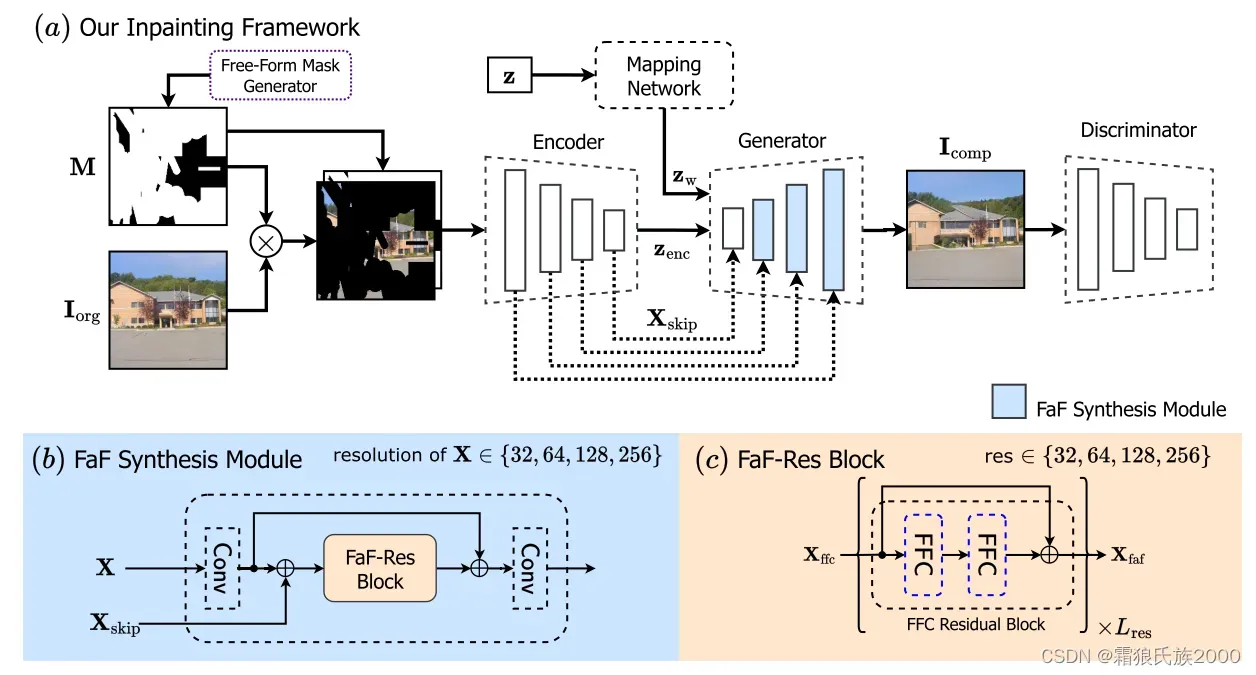
目标是将LaMa(WACV 2022)的想法,快速傅立叶卷积残差块,整合到一个基于StyleGAN2的共调制(ICLR 2021)由粗到精的生成器中。这个想法是通过一个快速傅立叶合成(FaF-Syn)模块实现的,该模块由一个快速傅立叶残差(FaF-Res)模块组成.
Fast Fourier Convolutional Residual Blocks (FaF-Res)模块:
FaF残差块由两个快速傅立叶卷积(FFC)层组成,FFC 层基于通道快速傅里叶变换(FFT)。它将通道分为两个分支:a)局部分支使用传统的卷积来捕获空间细节,b)全局分支使用频谱变换模块来考虑全局结构并捕获长程上下文。最后,局部分支和全局分支的输出堆叠在一起。
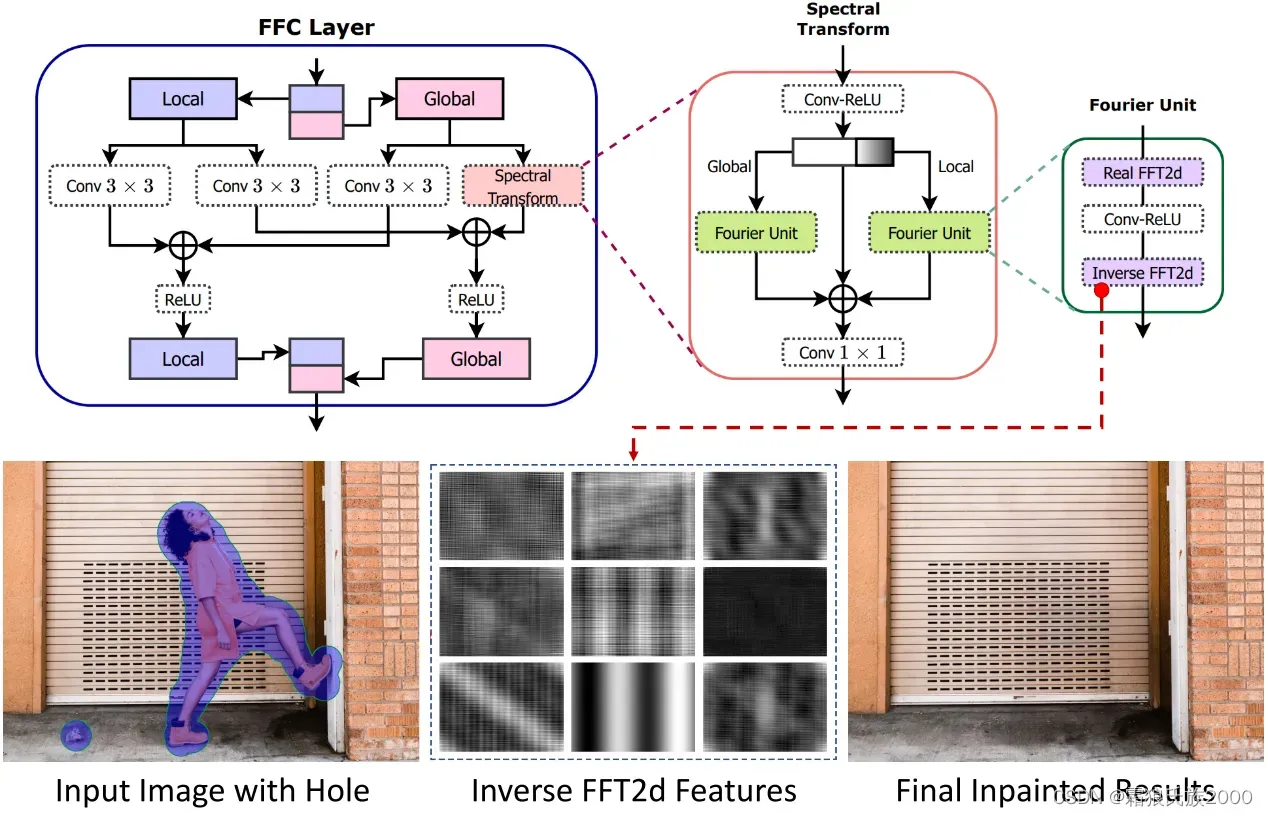
左傅立叶单元(FU)对全局上下文进行建模。另一方面,右侧的局部傅立叶单元(LFU)接收四分之一的通道,并专注于图像中的半全局信息。傅立叶单元主要使用真实的FFT 2D操作、频域中的卷积操作将空间结构分解成图像频率,并且最后使用逆FFT 2D操作来恢复结构。
**FFC成功实现生成重复图案的原因:**在傅立叶单元内的逆FFT 2D层之后,学习的特征并不直接表示和重建复杂的图像内容,而是生成多个全局重复模式。
引入FFC之前需要考虑的两个问题:
1.应该将FFC块嵌入到编码器还是生成器中?通过可视化和分析的FFC功能,答案是在生成器中。
2.假设我们将FFC块集成到生成器中,FFC层可能会放大非常粗糙的层次中的噪声生成结构,哪一级特征更适合引入FFC层?
Fast Fourier Synthesis (FaF-Syn) 模块:
FaF-Syn显式地集成了来自编码器(即现有图像纹理)和生成器(即从先前层生成的纹理)的特征,以合成全局重复纹理特征。
总结:
1.成功的解释了FFC对于inpainting任务的优越性所在。
2.将快速傅立叶卷积的网络感受能力与共调制粗到细生成器结合起来,以捕获全局重复纹理,得以逼真的图像结构。
版权声明:本文为博主作者:霜狼氏族2000原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_46119062/article/details/136347832