作者介绍:10年大厂数据\经营分析经验,现任大厂数据部门负责人。
会一些的技术:数据分析、算法、SQL、大数据相关、python
欢迎加入社区:码上找工作
作者专栏每日更新:
LeetCode解锁1000题: 打怪升级之旅
python数据分析可视化:企业实战案例
备注说明:方便大家阅读,统一使用python,带必要注释,公众号 数据分析螺丝钉 一起打怪升级
1. 问题介绍和应用场景
最长公共子序列(LCS)问题是在信息学、生物学以及在日常软件开发中,特别是在版本控制系统的开发中广泛应用的一类问题。LCS可以用来比较两个序列(通常是字符串)的相似度,它寻找在两个序列中都出现过并且所有字符都以相同顺序排列,但不必连续的最长序列。
2. 问题定义和示例
定义: 给定两个字符串 s1 和 s2,找出这两个字符串的最长公共子序列的长度。公共子序列是指在两个字符串中都能找到的序列,其字符顺序与原始字符串中的顺序相同但不必连续。
示例:
s1 = "abcde"s2 = "ace"
最长公共子序列是 "ace",长度为3。
3. 状态定义
在动态规划中,状态的选择是解题的关键。在本问题中,我们定义 dp[i][j] 为考虑 s1 的前 i 个字符和 s2 的前 j 个字符时的最长公共子序列的长度。
4. 状态转移方程
要构建状态转移方程,考虑以下情况:
- 如果当前字符
s1[i-1]和s2[j-1]相等,那么这个字符一定在LCS中。因此,dp[i][j] = dp[i-1][j-1] + 1。 - 如果不相等,那么LCS可能是
s1的前i-1个字符和s2的前j个字符的LCS,或者是s1的前i个字符和s2的前j-1个字符的LCS。因此,dp[i][j] = max(dp[i-1][j], dp[i][j-1])。
结合上述两点,状态转移方程可以表示为:
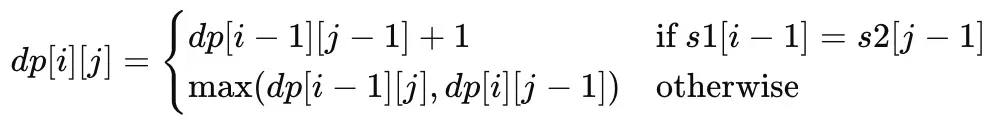
5. 初始化和边界情况
初始化对于动态规划问题至关重要,它可以确保状态转移正确进行。对于任何LCS问题:
- 当
i = 0或j = 0时,即考虑s1或s2的前0个字符,最长公共子序列长度自然为0。因此,dp[0][j] = 0和dp[i][0] = 0对所有的i和j。
6. 算法实现
以下是使用Python语言实现的LCS问题的动态规划算法:
def longest_common_subsequence(s1: str, s2: str) -> int:
"""
计算两个字符串之间的最长公共子序列的长度。
:param s1: 第一个字符串
:param s2: 第二个字符串
:return: 最长公共子序列的长度
"""
m, n = len(s1), len(s2)
# 创建一个二维数组来存储最长公共子序列的长度。
dp = [[0] * (n + 1) for _ in range(m + 1)]
# 自底向上地构建dp数组
for i in range(1, m + 1):
for j in range(1, n + 1):
if s1[i-1] == s2[j-1]:
dp[i][j] = dp[i-1][j-1] + 1 # 若当前字符相同,则将这一对字符加入到LCS中
else:
dp[i][j] = max(dp[i-1][j], dp[i][j-1]) # 否则,考虑不包括s1[i-1]或s2[j-1]的情况
# dp[m][n] 包含了s1[0..m-1]和s2[0..n-1]的最长公共子序列的长度
return dp[m][n]
# 示例使用
s1 = "abcde"
s2 = "ace"
print("最长公共子序列的长度:", longest_common_subsequence(s1, s2))
动态规划逻辑:
- 初始化一个
(m+1) x (n+1)的二维列表dp,其中dp[i][j]存储s1前i个字符和s2前j个字符的最长公共子序列的长度。 - 遍历字符串
s1和s2,通过比较字符确定是否将字符加入到子序列中,或者决定忽略哪个字符以保持子序列尽可能长。
复杂度分析
- 时间复杂度:O(mn) – 因为需要填充一个
m x n的矩阵。 - 空间复杂度:O(mn) – 用于存储每对索引的LCS长度。可以优化到 O(min(m, n)) 通过只保留当前和前一行的状态。
算法图解
图解示例
假设我们有两个字符串:
s1 = "abcde"s2 = "ace"
我们需要找到它们的最长公共子序列。
动态规划表初始化
创建一个表格,其中行表示字符串 s1,列表示字符串 s2。我们使用一个 (m+1) x (n+1) 的表格,m 和 n 分别是两个字符串的长度。
初始表格:
| - | a | c | e |
-----------------------
- | 0 | 0 | 0 | 0 |
a | 0 | | | |
b | 0 | | | |
c | 0 | | | |
d | 0 | | | |
e | 0 | | | |
填充表格
- 当我们比较两个字符且它们相同时,我们在左上角的值基础上加一(因为发现了一个新的公共元素)。
- 当字符不同时,我们取左边和上边值中的最大值。
1.a vs a:
dp[1][1]:s1的a与s2的a相同,所以dp[1][1] = dp[0][0] + 1 = 1.
| - | a | c | e |
-----------------------
- | 0 | 0 | 0 | 0 |
a | 0 | 1 | | |
b | 0 | | | |
c | 0 | | | |
d | 0 | | | |
e | 0 | | | |
2.a vs c, a vs e:
dp[1][2]: 取dp[1][1]和dp[0][2]的最大值,即dp[1][2] = max(1, 0) = 1.dp[1][3]: 取dp[1][2]和dp[0][3]的最大值,即dp[1][3] = max(1, 0) = 1.
3.b vs a, c, e:
- 使用与第一行相同的逻辑,
dp[2][1] = 1,dp[2][2] = 1,dp[2][3] = 1.
4.c vs a, c, e:
dp[3][1] = 1: 使用上一行的结果。dp[3][2] = 2:c与c匹配,dp[3][2] = dp[2][1] + 1 = 2.dp[3][3] = 2: 取dp[3][2]和dp[2][3]的最大值,即dp[3][3] = max(2, 1) = 2.
5.d vs a, c, e:
- 同上,结果与第三行相同。
6.e vs a, c, e:
dp[5][1] = 1,dp[5][2] = 2,dp[5][3] = 3:e与e匹配,dp[5][3] = dp[4][2] + 1 = 3.
| - | a | c | e |
-----------------------
- | 0 | 0 | 0 | 0 |
a | 0 | 1 | 1 | 1 |
b | 0 | 1 | 1 | 1 |
c | 0 | 1 | 2 | 2 |
d | 0 | 1 | 2 | 2 |
e | 0 | 1 | 2 | 3 |
8. 总结
最长公共子序列问题不仅是一个理论上的问题,而且在实际应用中非常重要,比如在生物信息学中比较DNA序列,在软件工程中比较文件版本等。通过动态规划,我们能够有效地解决这个问题,即使在面对大规模数据时也能保持良好的性能。
版权声明:本文为博主作者:数据分析螺丝钉原创文章,版权归属原作者,如果侵权,请联系我们删除!