目录
前言
一、启动Neo4j
二、安装py2neo库
三、Python连接Neo4j
四、Pycharm中搭建医药知识图谱
1、读取文件
2、建立节点
3、创建知识图谱中心疾病的节点
4、创建知识图谱实体节点类型
5、创建实体关系边
6、创建实体关联边
7、导出数据
8、运行程序
9、运行结果
五、Pycharm中实现自动问答系统
1、模型初始化
2、问答主函数
3、运行程序
4、运行结果
六、其他(问答子函数)
1、问句类型分类脚本
2、问句解析脚本
3、问答程序脚本
总结
前言
本案例用Pycharm编写Python程序操作Neo4j搭建知识图谱医药问答系统实战练习
本案例借鉴刘焕勇老师个人项目
一、启动Neo4j
如何启动Neo4j,请参考此教程
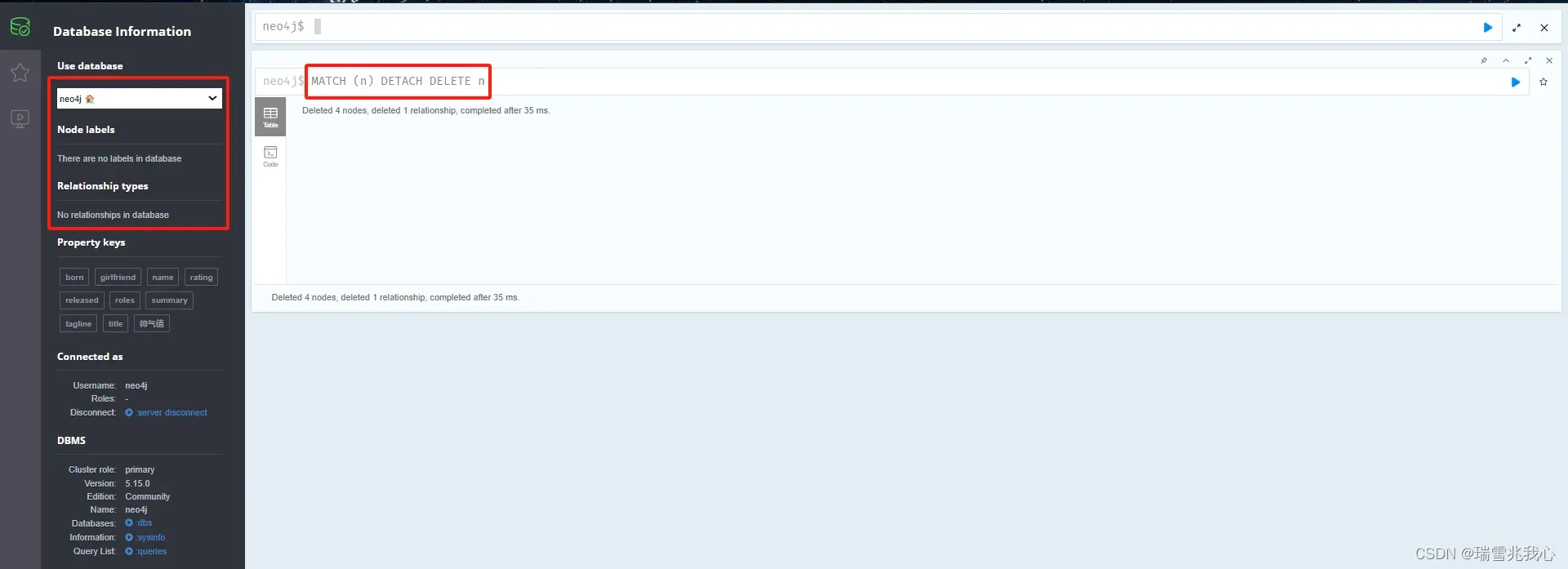
运行项目前,先清空Neo4j数据库
MATCH (n) DETACH DELETE n
二、安装py2neo库
代码学习参考py2neo官网文档
pip install py2neo

三、Python连接Neo4j
链接Neo4j的地址为:”bolt://localhost:7687″
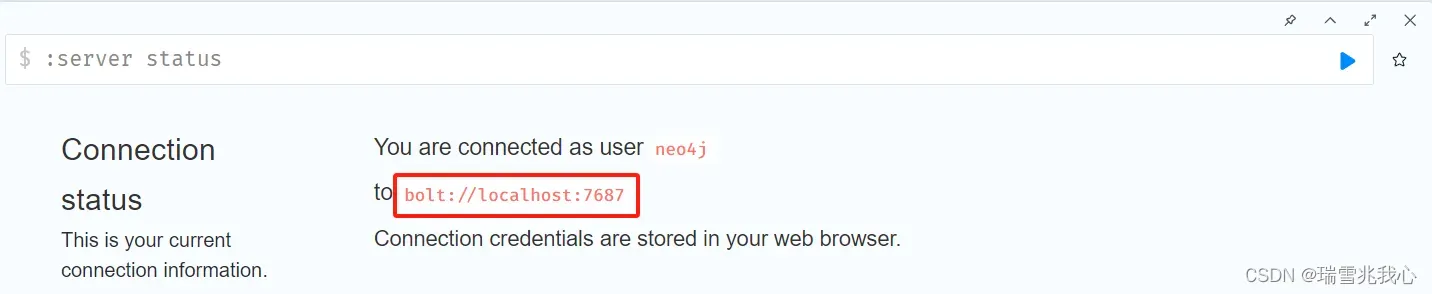
在本章中最开始的部分已经更改用户名默认为neo4j,密码在本章中最开始的部分已经更改
import json
import os
from py2neo import Graph, Node
class MedicalGraph:
def __init__(self):
cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])
self.data_path = os.path.join(cur_dir, 'data/medical.json')
self.g = Graph("bolt://localhost:7687", auth=("neo4j", "tang2001"))注意:build_medicalgraph.py 和 answer_search.py两个原文件中的self.g = Graph()的链接格式都更改为上述代码中的格式。
参考py2neo官网文档—Python连接Neo4j
四、Pycharm中搭建医药知识图谱
1、读取文件
代码如下:
def read_nodes(self):
# 共7类节点
drugs = [] # 药品
foods = [] # 食物
checks = [] # 检查
departments = [] # 科室
producers = [] # 药品大类
diseases = [] # 疾病
symptoms = [] # 症状
disease_infos = [] # 疾病信息
# 构建节点实体关系
rels_department = [] # 科室-科室关系
rels_noteat = [] # 疾病-忌吃食物关系
rels_doeat = [] # 疾病-宜吃食物关系
rels_recommandeat = [] # 疾病-推荐吃食物关系
rels_commonddrug = [] # 疾病-通用药品关系
rels_recommanddrug = [] # 疾病-热门药品关系
rels_check = [] # 疾病-检查关系
rels_drug_producer = [] # 厂商-药物关系
rels_symptom = [] # 疾病症状关系
rels_acompany = [] # 疾病并发关系
rels_category = [] # 疾病与科室之间的关系
count = 0
for data in open(self.data_path, encoding='utf8', mode='r'):
disease_dict = {}
count += 1
print(count)
data_json = json.loads(data)
disease = data_json['name']
disease_dict['name'] = disease
diseases.append(disease)
disease_dict['desc'] = ''
disease_dict['prevent'] = ''
disease_dict['cause'] = ''
disease_dict['easy_get'] = ''
disease_dict['cure_department'] = ''
disease_dict['cure_way'] = ''
disease_dict['cure_lasttime'] = ''
disease_dict['symptom'] = ''
disease_dict['cured_prob'] = ''
if 'symptom' in data_json:
symptoms += data_json['symptom']
for symptom in data_json['symptom']:
rels_symptom.append([disease, symptom])
if 'acompany' in data_json:
for acompany in data_json['acompany']:
rels_acompany.append([disease, acompany])
if 'desc' in data_json:
disease_dict['desc'] = data_json['desc']
if 'prevent' in data_json:
disease_dict['prevent'] = data_json['prevent']
if 'cause' in data_json:
disease_dict['cause'] = data_json['cause']
if 'get_prob' in data_json:
disease_dict['get_prob'] = data_json['get_prob']
if 'easy_get' in data_json:
disease_dict['easy_get'] = data_json['easy_get']
if 'cure_department' in data_json:
cure_department = data_json['cure_department']
if len(cure_department) == 1:
rels_category.append([disease, cure_department[0]])
if len(cure_department) == 2:
big = cure_department[0]
small = cure_department[1]
rels_department.append([small, big])
rels_category.append([disease, small])
disease_dict['cure_department'] = cure_department
departments += cure_department
if 'cure_way' in data_json:
disease_dict['cure_way'] = data_json['cure_way']
if 'cure_lasttime' in data_json:
disease_dict['cure_lasttime'] = data_json['cure_lasttime']
if 'cured_prob' in data_json:
disease_dict['cured_prob'] = data_json['cured_prob']
if 'common_drug' in data_json:
common_drug = data_json['common_drug']
for drug in common_drug:
rels_commonddrug.append([disease, drug])
drugs += common_drug
if 'recommand_drug' in data_json:
recommand_drug = data_json['recommand_drug']
drugs += recommand_drug
for drug in recommand_drug:
rels_recommanddrug.append([disease, drug])
if 'not_eat' in data_json:
not_eat = data_json['not_eat']
for _not in not_eat:
rels_noteat.append([disease, _not])
foods += not_eat
do_eat = data_json['do_eat']
for _do in do_eat:
rels_doeat.append([disease, _do])
foods += do_eat
recommand_eat = data_json['recommand_eat']
for _recommand in recommand_eat:
rels_recommandeat.append([disease, _recommand])
foods += recommand_eat
if 'check' in data_json:
check = data_json['check']
for _check in check:
rels_check.append([disease, _check])
checks += check
if 'drug_detail' in data_json:
drug_detail = data_json['drug_detail']
producer = [i.split('(')[0] for i in drug_detail]
rels_drug_producer += [[i.split('(')[0], i.split('(')[-1].replace(')', '')] for i in drug_detail]
producers += producer
disease_infos.append(disease_dict)
return set(drugs), set(foods), set(checks), set(departments), set(producers), set(symptoms), set(diseases), disease_infos, \
rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug, \
rels_symptom, rels_acompany, rels_category2、建立节点
代码如下:
def create_node(self, label, nodes):
count = 0
for node_name in nodes:
node = Node(label, name=node_name)
self.g.create(node)
count += 1
print(count, len(nodes))
return3、创建知识图谱中心疾病的节点
代码如下:
def create_diseases_nodes(self, disease_infos):
count = 0
for disease_dict in disease_infos:
node = Node("Disease", name=disease_dict['name'], desc=disease_dict['desc'],
prevent=disease_dict['prevent'], cause=disease_dict['cause'],
easy_get=disease_dict['easy_get'], cure_lasttime=disease_dict['cure_lasttime'],
cure_department=disease_dict['cure_department']
, cure_way=disease_dict['cure_way'], cured_prob=disease_dict['cured_prob'])
self.g.create(node)
count += 1
print(count)
return4、创建知识图谱实体节点类型
代码如下:
def create_graphnodes(self):
Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos, rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug, rels_symptom, rels_acompany, rels_category = self.read_nodes()
self.create_diseases_nodes(disease_infos)
self.create_node('Drug', Drugs)
print(len(Drugs))
self.create_node('Food', Foods)
print(len(Foods))
self.create_node('Check', Checks)
print(len(Checks))
self.create_node('Department', Departments)
print(len(Departments))
self.create_node('Producer', Producers)
print(len(Producers))
self.create_node('Symptom', Symptoms)
return
5、创建实体关系边
代码如下:
def create_graphrels(self):
Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos, rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug, rels_symptom, rels_acompany, rels_category = self.read_nodes()
self.create_relationship('Disease', 'Food', rels_recommandeat, 'recommand_eat', '推荐食谱')
self.create_relationship('Disease', 'Food', rels_noteat, 'no_eat', '忌吃')
self.create_relationship('Disease', 'Food', rels_doeat, 'do_eat', '宜吃')
self.create_relationship('Department', 'Department', rels_department, 'belongs_to', '属于')
self.create_relationship('Disease', 'Drug', rels_commonddrug, 'common_drug', '常用药品')
self.create_relationship('Producer', 'Drug', rels_drug_producer, 'drugs_of', '生产药品')
self.create_relationship('Disease', 'Drug', rels_recommanddrug, 'recommand_drug', '好评药品')
self.create_relationship('Disease', 'Check', rels_check, 'need_check', '诊断检查')
self.create_relationship('Disease', 'Symptom', rels_symptom, 'has_symptom', '症状')
self.create_relationship('Disease', 'Disease', rels_acompany, 'acompany_with', '并发症')
self.create_relationship('Disease', 'Department', rels_category, 'belongs_to', '所属科室')6、创建实体关联边
代码如下:
def create_relationship(self, start_node, end_node, edges, rel_type, rel_name):
count = 0
# 去重处理
set_edges = []
for edge in edges:
set_edges.append('###'.join(edge))
all = len(set(set_edges))
for edge in set(set_edges):
edge = edge.split('###')
p = edge[0]
q = edge[1]
query = "match(p:%s),(q:%s) where p.name='%s'and q.name='%s' create (p)-[rel:%s{name:'%s'}]->(q)" % (
start_node, end_node, p, q, rel_type, rel_name)
try:
self.g.run(query)
count += 1
print(rel_type, count, all)
except Exception as e:
print(e)
return7、导出数据
代码如下:
def export_data(self):
Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos, rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug, rels_symptom, rels_acompany, rels_category = self.read_nodes()
f_drug = open('drug.txt', 'w+')
f_food = open('food.txt', 'w+')
f_check = open('check.txt', 'w+')
f_department = open('department.txt', 'w+')
f_producer = open('producer.txt', 'w+')
f_symptom = open('symptoms.txt', 'w+')
f_disease = open('disease.txt', 'w+')
f_drug.write('\n'.join(list(Drugs)))
f_food.write('\n'.join(list(Foods)))
f_check.write('\n'.join(list(Checks)))
f_department.write('\n'.join(list(Departments)))
f_producer.write('\n'.join(list(Producers)))
f_symptom.write('\n'.join(list(Symptoms)))
f_disease.write('\n'.join(list(Diseases)))
f_drug.close()
f_food.close()
f_check.close()
f_department.close()
f_producer.close()
f_symptom.close()
f_disease.close()
return8、运行程序
代码如下:运行 build_medicalgraph.py 文件(导入的数据较多,估计需要1个多小时)
if __name__ == '__main__':
handler = MedicalGraph()
print("step1:导入图谱节点中")
handler.create_graphnodes()
print("step2:导入图谱边中")
handler.create_graphrels()直接运行刘老师的代码时,会出现如下错误:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xaf in position 81: illegal multibyte sequence解决方法:按Ctrl+F,输入open,在第一个open函数后加入下述代码即可
for data in open(self.data_path, encoding='utf8', mode='r'):9、运行结果
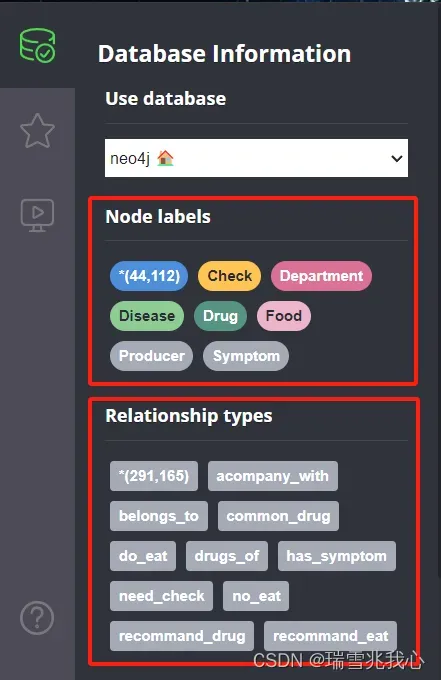
五、Pycharm中实现自动问答系统
1、模型初始化
代码如下:
from answer_search import *
from question_classifier import *
from question_parser import *
class ChatBotGraph:
def __init__(self):
self.classifier = QuestionClassifier()
self.parser = QuestionPaser()
self.searcher = AnswerSearcher()2、问答主函数
代码如下:
def chat_main(self, sent):
answer = '您好,我是医药智能助理,希望可以帮到您。祝您身体棒棒!'
res_classify = self.classifier.classify(sent)
if not res_classify:
return answer
res_sql = self.parser.parser_main(res_classify)
final_answers = self.searcher.search_main(res_sql)
if not final_answers:
return answer
else:
return '\n'.join(final_answers)3、运行程序
代码如下:运行 chatbot_graph.py 文件
if __name__ == '__main__':
handler = ChatBotGraph()
while 1:
question = input('用户:')
answer = handler.chat_main(question)
print('医药智能助理:', answer)
4、运行结果
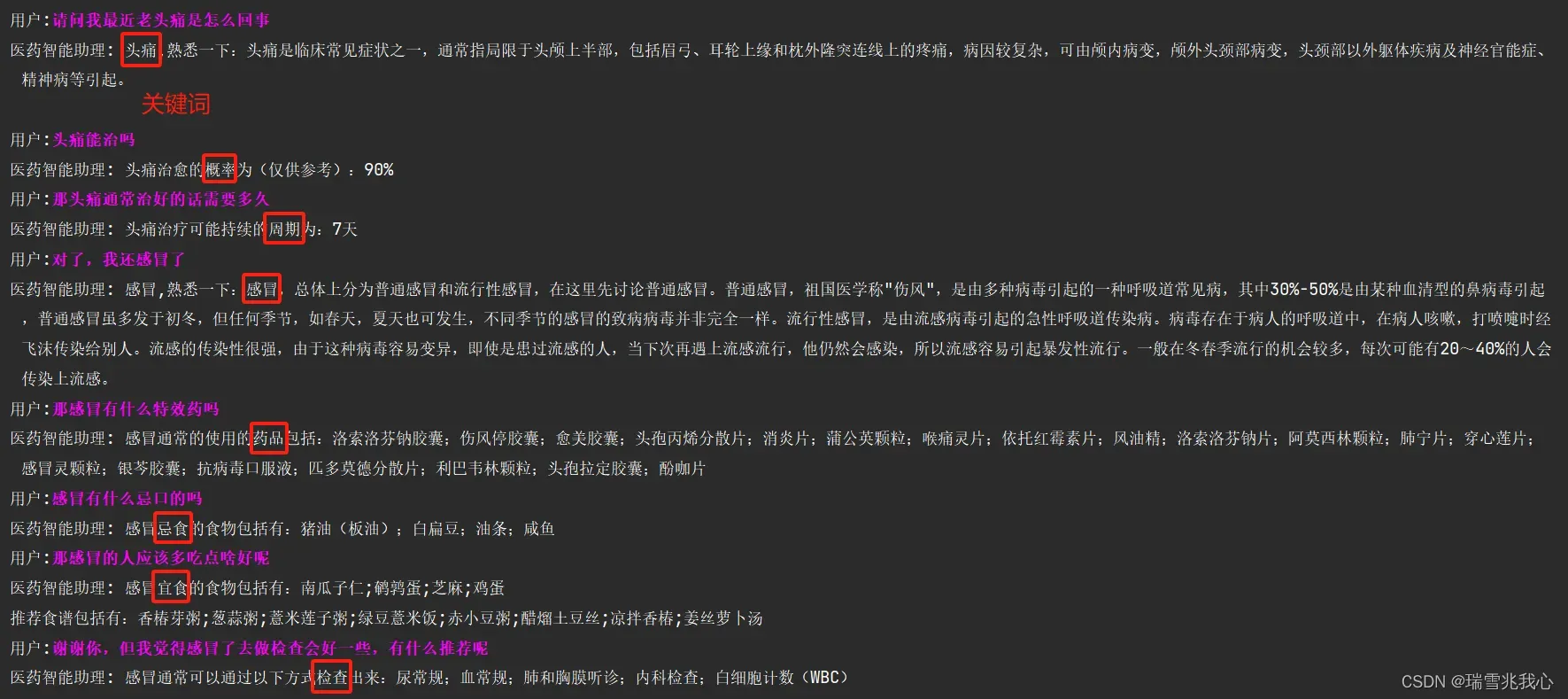

六、其他(问答子函数)
1、问句类型分类脚本
代码如下:运行 question_classifier 文件
import os
import ahocorasick
class QuestionClassifier:
def __init__(self):
cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])
# 特征词路径
self.disease_path = os.path.join(cur_dir, 'dict/disease.txt')
self.department_path = os.path.join(cur_dir, 'dict/department.txt')
self.check_path = os.path.join(cur_dir, 'dict/check.txt')
self.drug_path = os.path.join(cur_dir, 'dict/drug.txt')
self.food_path = os.path.join(cur_dir, 'dict/food.txt')
self.producer_path = os.path.join(cur_dir, 'dict/producer.txt')
self.symptom_path = os.path.join(cur_dir, 'dict/symptom.txt')
self.deny_path = os.path.join(cur_dir, 'dict/deny.txt')
# 加载特征词
self.disease_wds= [i.strip() for i in open(self.disease_path, encoding='utf8') if i.strip()]
self.department_wds= [i.strip() for i in open(self.department_path, encoding='utf8') if i.strip()]
self.check_wds= [i.strip() for i in open(self.check_path, encoding='utf8') if i.strip()]
self.drug_wds= [i.strip() for i in open(self.drug_path, encoding='utf8') if i.strip()]
self.food_wds= [i.strip() for i in open(self.food_path, encoding='utf8') if i.strip()]
self.producer_wds= [i.strip() for i in open(self.producer_path, encoding='utf8') if i.strip()]
self.symptom_wds= [i.strip() for i in open(self.symptom_path, encoding='utf8') if i.strip()]
self.region_words = set(self.department_wds + self.disease_wds + self.check_wds + self.drug_wds + self.food_wds + self.producer_wds + self.symptom_wds)
self.deny_words = [i.strip() for i in open(self.deny_path, encoding='utf8') if i.strip()]
# 构造领域actree
self.region_tree = self.build_actree(list(self.region_words))
# 构建词典
self.wdtype_dict = self.build_wdtype_dict()
# 问句疑问词
self.symptom_qwds = ['症状', '表征', '现象', '症候', '表现']
self.cause_qwds = ['原因','成因', '为什么', '怎么会', '怎样才', '咋样才', '怎样会', '如何会', '为啥', '为何', '如何才会', '怎么才会', '会导致', '会造成']
self.acompany_qwds = ['并发症', '并发', '一起发生', '一并发生', '一起出现', '一并出现', '一同发生', '一同出现', '伴随发生', '伴随', '共现']
self.food_qwds = ['饮食', '饮用', '吃', '食', '伙食', '膳食', '喝', '菜' ,'忌口', '补品', '保健品', '食谱', '菜谱', '食用', '食物','补品']
self.drug_qwds = ['药', '药品', '用药', '胶囊', '口服液', '炎片']
self.prevent_qwds = ['预防', '防范', '抵制', '抵御', '防止','躲避','逃避','避开','免得','逃开','避开','避掉','躲开','躲掉','绕开',
'怎样才能不', '怎么才能不', '咋样才能不','咋才能不', '如何才能不',
'怎样才不', '怎么才不', '咋样才不','咋才不', '如何才不',
'怎样才可以不', '怎么才可以不', '咋样才可以不', '咋才可以不', '如何可以不',
'怎样才可不', '怎么才可不', '咋样才可不', '咋才可不', '如何可不']
self.lasttime_qwds = ['周期', '多久', '多长时间', '多少时间', '几天', '几年', '多少天', '多少小时', '几个小时', '多少年']
self.cureway_qwds = ['怎么治疗', '如何医治', '怎么医治', '怎么治', '怎么医', '如何治', '医治方式', '疗法', '咋治', '怎么办', '咋办', '咋治']
self.cureprob_qwds = ['多大概率能治好', '多大几率能治好', '治好希望大么', '几率', '几成', '比例', '可能性', '能治', '可治', '可以治', '可以医']
self.easyget_qwds = ['易感人群', '容易感染', '易发人群', '什么人', '哪些人', '感染', '染上', '得上']
self.check_qwds = ['检查', '检查项目', '查出', '检查', '测出', '试出']
self.belong_qwds = ['属于什么科', '属于', '什么科', '科室']
self.cure_qwds = ['治疗什么', '治啥', '治疗啥', '医治啥', '治愈啥', '主治啥', '主治什么', '有什么用', '有何用', '用处', '用途',
'有什么好处', '有什么益处', '有何益处', '用来', '用来做啥', '用来作甚', '需要', '要']
print('model init finished ......')
return
'''分类主函数'''
def classify(self, question):
data = {}
medical_dict = self.check_medical(question)
if not medical_dict:
return {}
data['args'] = medical_dict
#收集问句当中所涉及到的实体类型
types = []
for type_ in medical_dict.values():
types += type_
question_type = 'others'
question_types = []
# 症状
if self.check_words(self.symptom_qwds, question) and ('disease' in types):
question_type = 'disease_symptom'
question_types.append(question_type)
if self.check_words(self.symptom_qwds, question) and ('symptom' in types):
question_type = 'symptom_disease'
question_types.append(question_type)
# 原因
if self.check_words(self.cause_qwds, question) and ('disease' in types):
question_type = 'disease_cause'
question_types.append(question_type)
# 并发症
if self.check_words(self.acompany_qwds, question) and ('disease' in types):
question_type = 'disease_acompany'
question_types.append(question_type)
# 推荐食品
if self.check_words(self.food_qwds, question) and 'disease' in types:
deny_status = self.check_words(self.deny_words, question)
if deny_status:
question_type = 'disease_not_food'
else:
question_type = 'disease_do_food'
question_types.append(question_type)
#已知食物找疾病
if self.check_words(self.food_qwds+self.cure_qwds, question) and 'food' in types:
deny_status = self.check_words(self.deny_words, question)
if deny_status:
question_type = 'food_not_disease'
else:
question_type = 'food_do_disease'
question_types.append(question_type)
# 推荐药品
if self.check_words(self.drug_qwds, question) and 'disease' in types:
question_type = 'disease_drug'
question_types.append(question_type)
# 药品治啥病
if self.check_words(self.cure_qwds, question) and 'drug' in types:
question_type = 'drug_disease'
question_types.append(question_type)
# 疾病接受检查项目
if self.check_words(self.check_qwds, question) and 'disease' in types:
question_type = 'disease_check'
question_types.append(question_type)
# 已知检查项目查相应疾病
if self.check_words(self.check_qwds+self.cure_qwds, question) and 'check' in types:
question_type = 'check_disease'
question_types.append(question_type)
# 症状防御
if self.check_words(self.prevent_qwds, question) and 'disease' in types:
question_type = 'disease_prevent'
question_types.append(question_type)
# 疾病医疗周期
if self.check_words(self.lasttime_qwds, question) and 'disease' in types:
question_type = 'disease_lasttime'
question_types.append(question_type)
# 疾病治疗方式
if self.check_words(self.cureway_qwds, question) and 'disease' in types:
question_type = 'disease_cureway'
question_types.append(question_type)
# 疾病治愈可能性
if self.check_words(self.cureprob_qwds, question) and 'disease' in types:
question_type = 'disease_cureprob'
question_types.append(question_type)
# 疾病易感染人群
if self.check_words(self.easyget_qwds, question) and 'disease' in types :
question_type = 'disease_easyget'
question_types.append(question_type)
# 若没有查到相关的外部查询信息,那么则将该疾病的描述信息返回
if question_types == [] and 'disease' in types:
question_types = ['disease_desc']
# 若没有查到相关的外部查询信息,那么则将该疾病的描述信息返回
if question_types == [] and 'symptom' in types:
question_types = ['symptom_disease']
# 将多个分类结果进行合并处理,组装成一个字典
data['question_types'] = question_types
return data
'''构造词对应的类型'''
def build_wdtype_dict(self):
wd_dict = dict()
for wd in self.region_words:
wd_dict[wd] = []
if wd in self.disease_wds:
wd_dict[wd].append('disease')
if wd in self.department_wds:
wd_dict[wd].append('department')
if wd in self.check_wds:
wd_dict[wd].append('check')
if wd in self.drug_wds:
wd_dict[wd].append('drug')
if wd in self.food_wds:
wd_dict[wd].append('food')
if wd in self.symptom_wds:
wd_dict[wd].append('symptom')
if wd in self.producer_wds:
wd_dict[wd].append('producer')
return wd_dict
'''构造actree,加速过滤'''
def build_actree(self, wordlist):
actree = ahocorasick.Automaton()
for index, word in enumerate(wordlist):
actree.add_word(word, (index, word))
actree.make_automaton()
return actree
'''问句过滤'''
def check_medical(self, question):
region_wds = []
for i in self.region_tree.iter(question):
wd = i[1][1]
region_wds.append(wd)
stop_wds = []
for wd1 in region_wds:
for wd2 in region_wds:
if wd1 in wd2 and wd1 != wd2:
stop_wds.append(wd1)
final_wds = [i for i in region_wds if i not in stop_wds]
final_dict = {i:self.wdtype_dict.get(i) for i in final_wds}
return final_dict
'''基于特征词进行分类'''
def check_words(self, wds, sent):
for wd in wds:
if wd in sent:
return True
return False
if __name__ == '__main__':
handler = QuestionClassifier()
while 1:
question = input('input an question:')
data = handler.classify(question)
print(data)2、问句解析脚本
代码如下:运行 question_parser.py 文件
class QuestionPaser:
'''构建实体节点'''
def build_entitydict(self, args):
entity_dict = {}
for arg, types in args.items():
for type in types:
if type not in entity_dict:
entity_dict[type] = [arg]
else:
entity_dict[type].append(arg)
return entity_dict
'''解析主函数'''
def parser_main(self, res_classify):
args = res_classify['args']
entity_dict = self.build_entitydict(args)
question_types = res_classify['question_types']
sqls = []
for question_type in question_types:
sql_ = {}
sql_['question_type'] = question_type
sql = []
if question_type == 'disease_symptom':
sql = self.sql_transfer(question_type, entity_dict.get('disease'))
elif question_type == 'symptom_disease':
sql = self.sql_transfer(question_type, entity_dict.get('symptom'))
elif question_type == 'disease_cause':
sql = self.sql_transfer(question_type, entity_dict.get('disease'))
elif question_type == 'disease_acompany':
sql = self.sql_transfer(question_type, entity_dict.get('disease'))
elif question_type == 'disease_not_food':
sql = self.sql_transfer(question_type, entity_dict.get('disease'))
elif question_type == 'disease_do_food':
sql = self.sql_transfer(question_type, entity_dict.get('disease'))
elif question_type == 'food_not_disease':
sql = self.sql_transfer(question_type, entity_dict.get('food'))
elif question_type == 'food_do_disease':
sql = self.sql_transfer(question_type, entity_dict.get('food'))
elif question_type == 'disease_drug':
sql = self.sql_transfer(question_type, entity_dict.get('disease'))
elif question_type == 'drug_disease':
sql = self.sql_transfer(question_type, entity_dict.get('drug'))
elif question_type == 'disease_check':
sql = self.sql_transfer(question_type, entity_dict.get('disease'))
elif question_type == 'check_disease':
sql = self.sql_transfer(question_type, entity_dict.get('check'))
elif question_type == 'disease_prevent':
sql = self.sql_transfer(question_type, entity_dict.get('disease'))
elif question_type == 'disease_lasttime':
sql = self.sql_transfer(question_type, entity_dict.get('disease'))
elif question_type == 'disease_cureway':
sql = self.sql_transfer(question_type, entity_dict.get('disease'))
elif question_type == 'disease_cureprob':
sql = self.sql_transfer(question_type, entity_dict.get('disease'))
elif question_type == 'disease_easyget':
sql = self.sql_transfer(question_type, entity_dict.get('disease'))
elif question_type == 'disease_desc':
sql = self.sql_transfer(question_type, entity_dict.get('disease'))
if sql:
sql_['sql'] = sql
sqls.append(sql_)
return sqls
'''针对不同的问题,分开进行处理'''
def sql_transfer(self, question_type, entities):
if not entities:
return []
# 查询语句
sql = []
# 查询疾病的原因
if question_type == 'disease_cause':
sql = ["MATCH (m:Disease) where m.name = '{0}' return m.name, m.cause".format(i) for i in entities]
# 查询疾病的防御措施
elif question_type == 'disease_prevent':
sql = ["MATCH (m:Disease) where m.name = '{0}' return m.name, m.prevent".format(i) for i in entities]
# 查询疾病的持续时间
elif question_type == 'disease_lasttime':
sql = ["MATCH (m:Disease) where m.name = '{0}' return m.name, m.cure_lasttime".format(i) for i in entities]
# 查询疾病的治愈概率
elif question_type == 'disease_cureprob':
sql = ["MATCH (m:Disease) where m.name = '{0}' return m.name, m.cured_prob".format(i) for i in entities]
# 查询疾病的治疗方式
elif question_type == 'disease_cureway':
sql = ["MATCH (m:Disease) where m.name = '{0}' return m.name, m.cure_way".format(i) for i in entities]
# 查询疾病的易发人群
elif question_type == 'disease_easyget':
sql = ["MATCH (m:Disease) where m.name = '{0}' return m.name, m.easy_get".format(i) for i in entities]
# 查询疾病的相关介绍
elif question_type == 'disease_desc':
sql = ["MATCH (m:Disease) where m.name = '{0}' return m.name, m.desc".format(i) for i in entities]
# 查询疾病有哪些症状
elif question_type == 'disease_symptom':
sql = ["MATCH (m:Disease)-[r:has_symptom]->(n:Symptom) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
# 查询症状会导致哪些疾病
elif question_type == 'symptom_disease':
sql = ["MATCH (m:Disease)-[r:has_symptom]->(n:Symptom) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
# 查询疾病的并发症
elif question_type == 'disease_acompany':
sql1 = ["MATCH (m:Disease)-[r:acompany_with]->(n:Disease) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
sql2 = ["MATCH (m:Disease)-[r:acompany_with]->(n:Disease) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
sql = sql1 + sql2
# 查询疾病的忌口
elif question_type == 'disease_not_food':
sql = ["MATCH (m:Disease)-[r:no_eat]->(n:Food) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
# 查询疾病建议吃的东西
elif question_type == 'disease_do_food':
sql1 = ["MATCH (m:Disease)-[r:do_eat]->(n:Food) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
sql2 = ["MATCH (m:Disease)-[r:recommand_eat]->(n:Food) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
sql = sql1 + sql2
# 已知忌口查疾病
elif question_type == 'food_not_disease':
sql = ["MATCH (m:Disease)-[r:no_eat]->(n:Food) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
# 已知推荐查疾病
elif question_type == 'food_do_disease':
sql1 = ["MATCH (m:Disease)-[r:do_eat]->(n:Food) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
sql2 = ["MATCH (m:Disease)-[r:recommand_eat]->(n:Food) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
sql = sql1 + sql2
# 查询疾病常用药品-药品别名记得扩充
elif question_type == 'disease_drug':
sql1 = ["MATCH (m:Disease)-[r:common_drug]->(n:Drug) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
sql2 = ["MATCH (m:Disease)-[r:recommand_drug]->(n:Drug) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
sql = sql1 + sql2
# 已知药品查询能够治疗的疾病
elif question_type == 'drug_disease':
sql1 = ["MATCH (m:Disease)-[r:common_drug]->(n:Drug) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
sql2 = ["MATCH (m:Disease)-[r:recommand_drug]->(n:Drug) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
sql = sql1 + sql2
# 查询疾病应该进行的检查
elif question_type == 'disease_check':
sql = ["MATCH (m:Disease)-[r:need_check]->(n:Check) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
# 已知检查查询疾病
elif question_type == 'check_disease':
sql = ["MATCH (m:Disease)-[r:need_check]->(n:Check) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
return sql
if __name__ == '__main__':
handler = QuestionPaser()
3、问答程序脚本
代码如下:运行 answer_search.py 文件
from py2neo import Graph
class AnswerSearcher:
def __init__(self):
self.g = Graph("bolt://localhost:7687", auth=("neo4j", "tang2001"))
self.num_limit = 20
'''执行cypher查询,并返回相应结果'''
def search_main(self, sqls):
final_answers = []
for sql_ in sqls:
question_type = sql_['question_type']
queries = sql_['sql']
answers = []
for query in queries:
ress = self.g.run(query).data()
answers += ress
final_answer = self.answer_prettify(question_type, answers)
if final_answer:
final_answers.append(final_answer)
return final_answers
'''根据对应的qustion_type,调用相应的回复模板'''
def answer_prettify(self, question_type, answers):
final_answer = []
if not answers:
return ''
if question_type == 'disease_symptom':
desc = [i['n.name'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}的症状包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'symptom_disease':
desc = [i['m.name'] for i in answers]
subject = answers[0]['n.name']
final_answer = '症状{0}可能染上的疾病有:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_cause':
desc = [i['m.cause'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}可能的成因有:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_prevent':
desc = [i['m.prevent'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}的预防措施包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_lasttime':
desc = [i['m.cure_lasttime'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}治疗可能持续的周期为:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_cureway':
desc = [';'.join(i['m.cure_way']) for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}可以尝试如下治疗:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_cureprob':
desc = [i['m.cured_prob'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}治愈的概率为(仅供参考):{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_easyget':
desc = [i['m.easy_get'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}的易感人群包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_desc':
desc = [i['m.desc'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0},熟悉一下:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_acompany':
desc1 = [i['n.name'] for i in answers]
desc2 = [i['m.name'] for i in answers]
subject = answers[0]['m.name']
desc = [i for i in desc1 + desc2 if i != subject]
final_answer = '{0}的症状包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_not_food':
desc = [i['n.name'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}忌食的食物包括有:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_do_food':
do_desc = [i['n.name'] for i in answers if i['r.name'] == '宜吃']
recommand_desc = [i['n.name'] for i in answers if i['r.name'] == '推荐食谱']
subject = answers[0]['m.name']
final_answer = '{0}宜食的食物包括有:{1}\n推荐食谱包括有:{2}'.format(subject, ';'.join(list(set(do_desc))[:self.num_limit]), ';'.join(list(set(recommand_desc))[:self.num_limit]))
elif question_type == 'food_not_disease':
desc = [i['m.name'] for i in answers]
subject = answers[0]['n.name']
final_answer = '患有{0}的人最好不要吃{1}'.format(';'.join(list(set(desc))[:self.num_limit]), subject)
elif question_type == 'food_do_disease':
desc = [i['m.name'] for i in answers]
subject = answers[0]['n.name']
final_answer = '患有{0}的人建议多试试{1}'.format(';'.join(list(set(desc))[:self.num_limit]), subject)
elif question_type == 'disease_drug':
desc = [i['n.name'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}通常的使用的药品包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'drug_disease':
desc = [i['m.name'] for i in answers]
subject = answers[0]['n.name']
final_answer = '{0}主治的疾病有{1},可以试试'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'disease_check':
desc = [i['n.name'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}通常可以通过以下方式检查出来:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
elif question_type == 'check_disease':
desc = [i['m.name'] for i in answers]
subject = answers[0]['n.name']
final_answer = '通常可以通过{0}检查出来的疾病有{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
return final_answer
if __name__ == '__main__':
searcher = AnswerSearcher()总结
本项目立足医药领域,以垂直型医药网站为数据来源,以疾病为核心,构建起一个包含7类规模为4.4万的知识实体,11类规模约30万实体关系的知识图谱。
如需要项目代码自取:李焕勇老师个人项目百度网盘下载链接
版权声明:本文为博主作者:瑞雪兆我心原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/contributed_l/article/details/135731453